原文题目为A Novel Graph-TCN with a Graph Structured Representation for Micro-Expression Recognition,收录于2020年ACM International Conference on Multimedia (ACM MM)。本文将会对论文中所提出的方法进行讲解,以及分享自己对于这篇论文的思考与感悟。

研究背景与内容
微表情是一种自发的面部动作,这一组动作仅涉及面部局部区域且区域内的肌肉运动强度极低。微表情识别方法与一般的视频分析方法工作流程类似,需要对视频序列进行预处理、特征提取,并最终完成识别分类工作。然而,微表情面部肌肉运动强度低的特性会影响到微表情识别算法的实现效果。
为了解决该问题,一般会在预处理工作中加入视频动作放大的方法。视频动作放大方法顾名思义,就是将视频中的动作增强到更明显的效果。当前,最常被使用的动作放大方法有欧拉视频放大、基于相位的放大和全局拉格朗日运动放大等。但是,上述方法都是使用手工设计进行实现的,以致这些方法的适应性很差,例如欧拉视频放大就只是单纯的对像素进行线性修改,这个过程甚至还增大了图像的模糊度。
其次,另外一种解决方案就是在特征提取工作上进行改进,使特征的关注点尽量集中在面部的关键位置。在该方案里,如果使用的是传统机器学习的方法,则侧重于使用手工特征方法将人脸按照器官划分为多个子区域,但是微表情只涉及到部分器官区域,因此该类方法会包含很多冗余信息。如果使用深度学习方法来对特征进行学习,则主要集中在对微表情的空间与时序特征进行学习,这类方法同样也规避不了图像噪声或冗余信息所带来的影响。
而近期,Zhong等人[1]将图结构用在了静态人脸情绪识别上,即使用图结构表示不同情绪下的表情特征。图结构将人脸上的相关标志位相互连接起来,不仅能避免很多冗余信息和不相关噪声的影响,而且还能表达出复杂的面部结构信息,与其他方法比具有更强的判别性。
本文作者借鉴了图结构在表示面部特征上的优势将其应用在微表情识别当中,同时,考虑到文献[1]中使用的图结构依旧需要人工设置中节点信息和边信息的缺陷,作者提出了可以自动学习图结构特征的时序卷积网络(Temporal Convolutional Network,TCN)——基于图结构表示的新型“图-时序卷积网络(Graph-TCN)”。作者提出的方法主要做出以下几点贡献:
- 为解决微表情面部肌肉运动强度低带来的影响,利用迁移学习技术实现视频动作放大来增强低强度的面部运动,并且解决了基于手工设计的动作放大方法所带来的适应性限制;
- 基于统计分析提出了一种基于形状表征融合的微表情人脸图结构;
- 设计了一种新型的Graph-TCN网络来提取微表情局部肌肉运动的特征,实现了对图结构的自主学习而不需要手工设计。
方法的整体框架
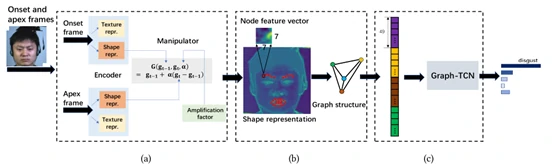
文章提出方法的整体设计框架如图2所示。框架的大致过程如下:
- 将微表情序列中的起始帧(即视频中微表情开始发生时对应的帧,Onset frame)和峰值帧(即视频中微表情达到最显著时对应的帧,Apex frame)图像作为输入;
- 紧接着,通过图2(a)所示的基于迁移学习的视频动作放大方法提取到以形状特征表示的放大图像;
- 然后对图像中的人脸区域进行标点,将眉毛和嘴部区域制成图结构(Graph structure),如图2(b)所示;
- 最后将图结构输入到Graph-TCN网络,对图结构中的边和节点特征进行提取,如图2(c)所示,完成识别和分类任务。
具体方法的实现
基于迁移学习的视频动作放大
前面我们有提到,现在大多使用的动作放大方法都是通过手工设计实现的。为了解决这一限制,文章中引用了Oh等人[2]所提出的基于迁移学习的视频动作放大方法。这一方法不再需要人工去设计,而是通过模型自动学习微表情从起始帧到峰值帧的运动规律来进行放大。但是,文章作者并不是直接使用文献[2]中的方法,而是根据微表情的特点对结构进行了部分修改,并且还运用了迁移学习的方法来进一步改进效果,具体步骤如图3所示。
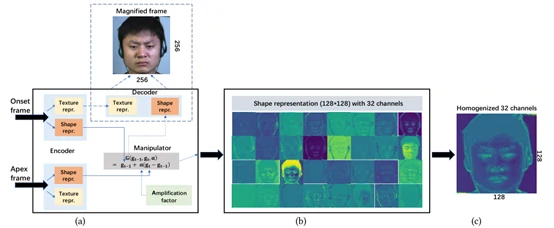
图3(a)所示是文献[2]中提供的基本结构,包含编码器(Encoder)、解码器(Decoder)和控制器(Manipulator)。该模型的输入是两张图像,文章所选择的图像是微表情的起始帧和峰值帧(选择这两帧的原因是文献[3]中证明微表情的峰值帧所体现出来的表情特征最为明显,且足以超过使用整个序列进行特征提取的效果),具体的工作流程如下:
- 首先,编码器会提取起始帧和峰值帧的形状表征和纹理表征,控制器通过计算两张图像在形状表征上的变化,乘上放大因子(Amplification factor)来达到对形状表征进行放大的目的,解码器则是要将起始帧的纹理表征和放大后的形状表征进行解码生成完整放大后的图像。
但是,在这个步骤里有一个关键的信息——已有相关文献证明了形状表征对表现肌肉运动关系的贡献更大,纹理表征为微表情提供的有用信息非常少,甚至比噪声的影响还小,因此文章在使用到该模型时摒弃了解码器的工作(也就是图3(a)中的虚线部分未使用)。
紧接着,从控制器输出的放大后的形状表征由32个通道进行表示(图3(b)所示的就是将32个通道可视化后的效果)。
最后,对32个通道进行均质化得到放大的形状表征(如图3(c)所示),并把其作为构建人脸图结构的原始特征输入。
构建面部图结构
要构建一个可以适用于微表情的面部图结构,就要首先找到合适的面部区域。文章为了找到一个判别性更高、受噪声影响更低的区域,使用统计分析的方法——皮尔逊相关系数(皮尔逊相关系数是为了计算两个事物的相关性,如果相关系数的绝对值越大,则两者相关性越大;如果越接近0,那么两者的相关性越低)。
在选择特征点区域的实验上,文章首先在起始帧和峰值帧上设定大小为64*64的疑似特征区域,然后将每个区域级联成一个特征向量,计算每个对应区域在起始帧和峰值帧上的皮尔逊相关系数。图4所示的是每类微表情上排名Top13的特征点区域,也就是面部肌肉运动强度最大的13个区域(皮尔逊相关系数越小排名越高,意味着起始帧和峰值帧之间的差异越大,代表该区域的肌肉运动强度越大)。实验统计结果表明,微表情所涉及的面部肌肉主要集中在眉毛和嘴部区域。
在确定过微表情的面部肌肉运动位置后,就要构建这些区域之间的面部图结构。面部图结构中的每个节点代表一个肌肉群的内部运动关系,而连接节点之间的边则代表两个肌肉群之间的运动关系。对于不同情绪类型的微表情序列,面部肌肉组也具有不同的运动模式,基于此理论基础可以得知使用面部图结构是可以适用于微表情识别的。
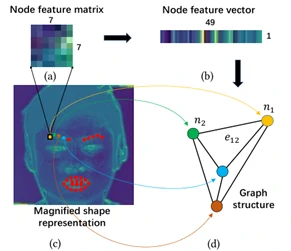
文章在构造面部图结构时,在眉毛和嘴部区域一共选择了28个节点来定位特征,如图5(c)中标记的红点所示,每个节点都是7*7大小的特征矩阵(如图5(a)所示),随后要将节点特征矩阵压缩成长度为49的节点特征向量(如图5(b)所示),以方便之后用于学习和构造节点之间的边特征。
Graph-TCN
Graph-TCN的本质就是将上述所构建的图结构输入到TCN网络当中,通过TCN网络来对图结构中节点和边的特征分别进行学习。
文章考虑到眉毛和嘴部两个区域是相对独立的两个肌肉群,因此面部图结构也被分为两部分,每个部分都会使用一个双通道的TCN网络来训练各自的图结构特征,如图6所示。
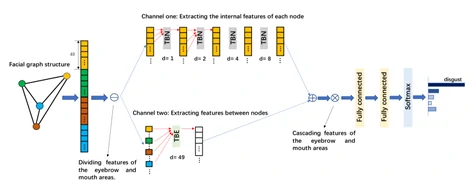
双通道TCN网络的输入是由所有节点特征向量级联而成的向量。紧接着,网络设置了两个通道:通道1中所使用的TCN残差块称为TBN,用来卷积一个节点特征向量内的元素,提取该节点的特征;通道2中所使用到的TCN残差块称为TBE,对来自多个节点序列的元素进行卷积,提取边的特征。
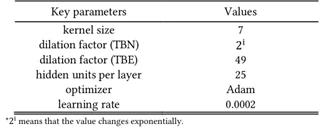
图6中举的例子是一个拥有4个节点的图结构,那么在该案例中为了提取节点的特征,就应该对应设置4个TBN。而每个节点的长度都是长度为49的一维向量,那么为了探究节点与节点之间的关系,TBE所使用的膨胀系数(膨胀系数的概念是TCN网络中的膨胀卷积结构中的参数)也设为49。
最后,网络将两个通道的特征叠加在一起,并将眉毛和嘴部这两部分的图特征进行级联后放入两个全连接层、BatchNorm层、Dropout层和ReLU层中进行进一步的特征训练,最终使用一个softmax层来进行分类。
相关实验
数据集及预处理
文献使用了CASMEⅡ和SAMM两个微表情数据集,原因在于这两个数据集中的视频样本帧率都比较高(200fds)并且都标记了微表情的起始帧和峰值帧。但是值得注意的是,CASMEⅡ数据集的受试者都是中国人,因此具有同质性,而SAMM数据集的受试者则包含了多种族人群。文献的相关实验在CASMEⅡ数据集中选择了五个类别,分别是快乐(32个样本)、厌恶(63个样本)、压抑(27个样本)、惊讶(25个样本)和其他(99个样本),总共246个样本。在SAMM数据集中同样选择了五个类别,分别是愤怒(57个样本)、快乐(26个样本)、轻视(12个样本)、惊讶(15个样本)和其他(26个样本),共136个样本。
在预处理工作上,文献在对样本进行人脸对齐后将图像调整为256*256大小,该尺寸满足了基于迁移学习的视频动作放大的输入要求。由于样本存在类别不平衡和数量太小的问题,文献作者对两个数据集进行了数据增强。数据增强的策略是使用固定剪裁的方法,即以图像的四角和中心为中心按照一定比例进行剪裁来达到数据的扩充,并使每个类别的样本量扩充到相同。
放大因子的相关实验
在3.1节中介绍的基于迁移学习的视频动作放大网络里有一个关键参数——放大因子(Amplification factor),这个参数影响到视频动作放大的效果。为了评估放大因子对视频动作放大网络效果的影响,作者在CASME II数据集上进行了视觉对比实验。
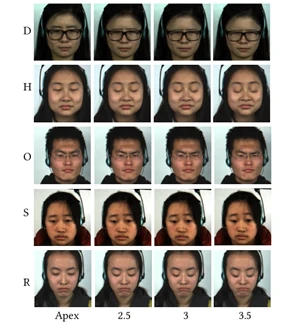
为了使得更明显地看出动作放大后的效果,实验直接使用了重建后的放大图像(如图7所示),而不再是像图3那样只展示形状表征。图7中每一行代表的是一种微表情(D、H、O、S、R分别表示厌恶、快乐、其他、惊讶和压抑),每一列表示图像在放大因子分别设置为2.5、3、3.5上的放大效果。由图7展示的结果可以很清晰地观察到随着放大因子的增加,微表情的肌肉运动强度也逐渐增大。其中,眉毛和嘴部区域的放大效果更明显,但是当放大因子大于3时面部肌肉运动开始过度变形。因此,实验在之后使用时会选择小于等于3的放大因子。
Graph-TCN的相关实验
在评估文献提出的Graph-TCN方法效果的实验上,作者使用到CASME II和SAMM两个数据集,使用了最常用的跨数据集评估方法——leave-one-subject-out (LOSO)协议,同时采用的评估指标有两个,一个是分类的准确率(Accuracy),另一个是F1-Score(该评估指标本质上是对分类的精确率与召回率进行平均的一个结果)。
表1展示了Graph-TCN网络其它参数的设置情况,在3.3节我们介绍到Graph-TCN网络包含了TBN和TBE两种TCN残差块,而这两种残差块层数的设置会影响到网络的效果,因此表2展示了网络在两种残差块不同设置情况下的对比实验,并选择准确率最佳的设置——TBN层数为4,TBE层数为1的情况下来与其它方法做对比。

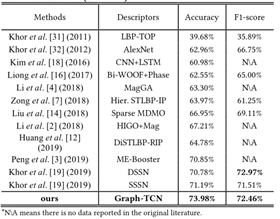
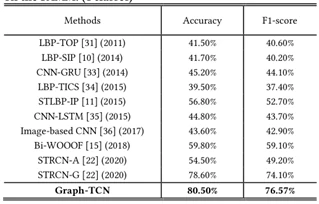
在与其它方法的比较实验中,首先作者与对CASME II和SAMM两个微表情数据被分为5类情况下的一些重要研究进行对比(如表3、表4所示)。在表中,MDMO、Bi+WOOF+Phase、DSSN三种方法是基于光流的改进方法,STLBP-IP是基于LBP改进的方法,HIGO+Mag、ME-Booster、MagGA是使用欧拉运动放大法对低强度的面部动作进行放大,MagGA,DSSN、CNN+LSTM是使用卷积神经网络识别微表情。
从图表中展示的结果来看,文献提出的方法在CASMEⅡ数据集上的准确率是明显高于其它方法的,比SSSN方法提升了2.79%,在F1-Score指标下效果虽然不是最好,但是也名列前茅。在SAMM数据集上的效果,无论是在准确率上还是F1-Score上都优于其它方法。
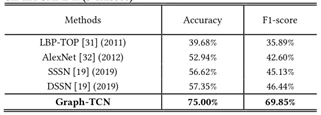
同时,对比实验考虑到其他方法将SAMM划分为5类时的情况比较少,所以实验又增加了SAMM在4类情况下的比较实验。实验根据文献[4]中的分类设计将数据集分为四类,仍然使用LOSO协议。比较结果如表5所示,本文献提出的方法在准确率和F1-Score两个指标下都优于其他方法。
综上所述,文献提出的方法目前在这两个数据库中具有最高的准确率。
总结与思考
在学习完整篇文章后,最大的感受是作者所提出的方法都是尽可能使用深度学习的方法去取代人工设计所带来的限制和麻烦。在数据预处理部分,作者所使用到的基于迁移学习的视频动作放大方法虽然不是创新,但是其结合了当前流行的迁移学习方法实现了该方法效果的增强。同时,作者在运用TCN网络的部分也充分考虑了所选取面部位置的特点,实验设计完整,作者对其所提出的方法总结出了以下优点:
- 提出的网络是基于TCN结构的改进,因此可以借助TCN中的膨胀卷积结构,通过修改膨胀系数来使网络具备灵活的感受野;
- 由于TCN残差块可以跨层共享卷积滤波器,训练所需的内存比基于RNN的网络少;
- 由于TCN残差块的反向传播路径与序列的时间方向不同,因此不会发生RNN中的爆炸梯度问题。
但本人在阅读这篇论文时,也产生了一些疑惑及思考:
- 数据集的选择问题。作者在构建人脸图结构时所做的统计实验只使用了CASMEⅡ数据集,该数据集只包含中国人的数据,人脸肌肉的运动规律会不会受到不同种族的行为习惯不一样的影响而导致不严谨?是否会影响算法的泛化性?
- 人脸区域的选择问题。作者仅选择了眉毛和嘴部区域构建人脸图结构,是否有其他区域对微表情局部肌肉运动的表征也具有较大贡献?
- Graph-TCN网络的输入问题。除了图结构,是否还有其他更鲁棒的结构用于网络的输入?
以上问题还有待进一步研究。
参考资料
https://www.scholat.com/teamwork/showPostMessage.html?id=9236
[1]Lei Zhong, Changmin Bai, Jianfeng Li, Tong Chen, Shigang Li, and Yiguang Liu. 2019. A Graph-Structured Representation with BRNN for Static-based Facial Expression Recognition. In Proceedings of IEEE International Conference on Automatic Face & Gesture Recognition. 1-5.
[2] Tae-Hyun Oh, Ronnachai Jaroensri, Changil Kim, Mohamed Elgharib, Fr’edo Durand, William T. Freeman, and Wojciech Matusik. 2018. Learning-Based Video Motion Magnification. In ECCV. 663–679.
[3] Yante Li, Xiaohua Huang, Guoying Zhao. 2018. Can Micro-Expression be Recognized Based on Single Apex Frame? In Proceedings of IEEE International Conference on Image Processing. 3094-3098.
[4] Zhaoqiang Xia, Xiaopeng Hong, Xingyu Gao, Xiaoyi Feng, and Guoying Zhao. 2020. Spatiotemporal Recurrent Convolutional Networks for Recognizing Spontaneous Micro-Expressions. IEEE Transactions on Multimedia. 22, 3 (2020), 626-640.