本篇学习报告的内容为“一种基于视觉和听觉相结合的深度跨域情绪识别网络”,选自论文《Joint Deep Cross-Domain Transfer Learning for Emotion Recognition》。该论文提出了一种基于视觉和听觉相结合的深度跨域情绪识别网络,来解决因为情绪识别数据集匮乏而导致识别效果较差的问题。
研究背景
由于收集和准确地对情感数据打上标签并形成大规模对数据集不仅需要耗费大量的金钱和时间,还需要有对应专业知识的技术人员才能完成,导致现在研究者们普遍面临缺乏足够的带有标签的数据的情况,进而无法训练模型去进行准确的情绪分类。
为了解决上面的问题,研究者们开始广泛使用迁移学习这个方法,并且都在一定程度上取得了较好的效果。但是目前大部分情况都只适用于单一领域(比如视觉迁移到视觉)。Hu[1], Ji[2], Zhang[3]等人的研究表明,不同领域可以提供互补的信息以提升情绪识别模型的识别能力。因此如何科学利用跨域信息去进行跨域情绪识别,是当今一个有待解决的问题。
研究目的
为了在不受分布变化影响的情况下,完成在多个数据集和多个资源贫乏的数据集上传递情感知识的任务,作者提出了一种联合的深度跨域学习方法,旨在学习跨域知识,并将学习到的知识从庞大的数据集中联合转移到数据量贫乏的数据集中,提高了情感识别的性能。作者提出的算法旨在学习跨越视觉和听觉领域的情感知识,并将跨领域的知识转移到多个缺乏源的数据集。
研究方法和模型
(1)方法概述
用DSv表示视觉数据的源数据集,DSa 表示音频数据的源数据集,N个视觉目标数据集表示为,所有目标数据集内数据较少,且包含少量带标记的数据。如图1所示,作者首先使用可视化数据集DSv 训练一个初始模型Pv,该初始模型也被认为是预训练模型,然后使用视觉目标数据集进行微调,得到一个跨视觉数据域的模型Fv. 为了合并音频特征,Fv在音频源数据集DSa 继续训练,然后得到一个跨域模型Gv,a。最后用目标数据集通过联合学习算法去训练跨域模型Gv,a 。
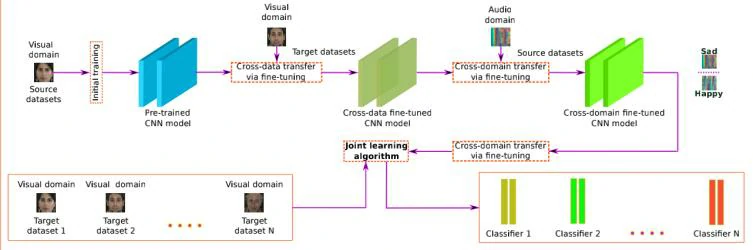
简单来说,作者训练的思路就是让模型从视觉和听觉源数据集上学习,然后在新的视觉数据集进行情绪识别。预训练时使用到的数据集取决于数据集的可靠性,比如数据集数据越多,或者内部带标注的数据越多等。通常而言,视觉数据带标签的情况要比听觉数据多,意味着更加可靠。理论上来说,模型从可靠数据集学习得越好,跨域识别效果就越好。
(2)数据预处理
对于视觉数据,从视频中提取帧画面,在帧画面中利用Nguyen[4]等人提出的改进Viola-Jones算法去提取画面中的人脸,并将人脸区域大小缩放成64×64×3.
对于音频数据,作者受到Zhang[5]等人的启发,从一维的语音信号中提取64×64×3的Mel-spectrogram片段(F=64, T=64, C=3),其中F,T,C分别表示Mel滤波器的数量,与帧窗口中的帧号相对应的段长以及Mel频谱的通道数。这样设置的主要原因是与视觉数据的大小一致(两种数据的大小都是64×64×3)。值得注意的是Mel通道中,指的是static,delta,以及delta-delta系数(和Zhang[5]等人的一致)
(3)联合学习策略
进行联合学习的核心思路是让模型从已知的视音频数据中学习情绪特征,并将学习到的情绪特征作为初始知识,在新的视觉数据上进行识别。(有点类似人的“类比”)作者提出,他们先在视觉源数据集上预训练卷积神经网络CNN,然后将模型迁移到目标视觉数据集上进行情绪识别,之后再将它迁移到音频数据集中去进行特征提取和不断地fine-tuning(核心意思就是基于一个训练好的模型使用自己的数据,利用训练好的模型的权重参数值,通过修改最后一层的参数和输出类别,训练出一个适合自己数据的模型)。在预训练和fine-tuning[11]过程中,模型学习的原则是“最大化带标签数据的后验概率以及从不同的类别中分离特征”。给定输入特征向量以及对应的标签c,交叉熵损失公式时如下:
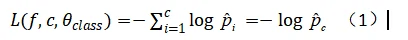
经过在最终域上fine-tuning之后,模型已经学习到了许多情绪特征。然后,以这些情绪特征为基础,通过同时优化两个交叉熵损失函数(公式1)和一个对比损失函数(公式2),使它们达到收敛,在新的两个不同的视觉数据集上进行联合学习。对比损失函数定义如下:
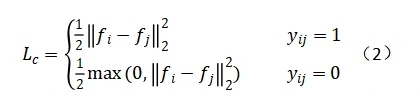
上面提到联合学习的核心思路是让模型从已知的视音频数据中学习情绪特征,并将学习到的情绪特征作为初始知识,在新的视觉数据上进行识别。在这个过程中必然涉及到分类与匹配的问题。分类的目的是通过最大限度地提高类间的方差,将来自多个领域的每个样本划分为不同类型的情绪,而匹配的目标是通过减少类内的方差来预测一对样本是否属于同一情绪。

实验及结果
数据集
论文中的数据集主要涉及以下3个:
(1)eNTERFACE2005数据集[6]
eNTERFACE2005数据集[6]是一个音视频数据集,其中包含44为受试者,1293个视频片段,其中23%s 是女性,77%是男性,涉及6类情绪:生气anger,厌恶disgust,害怕fear,开心happiness,难过sadness和惊喜surprise。
(2)SAVEE数据集[7]
SAVEE数据集[7]由萨里大学(University of Surrey)制作并发布。该数据集包含由4位母语为英语的男性在7种不同的情绪下的录音,总共480个英式英语句子。情感在心理上被分为不同的类别:中性,愤怒,厌恶,恐惧,幸福,悲伤和惊奇。句子是从标准的TIMIT语料库(这是由德州仪器、麻省理工学院和SRI International合作构建的声学-音素连续语音语料库)中选取的组成,每种情感对应的材料包含15个句子:3个普通句子,2个特定于情感的句子和10个通用句子,每种句子都进行过语音平衡。将3个普通句子和2×6 = 12个特定于情感的句子记录为中性,以给出30个中性句子。
(3)EMO-DB数据集[8]
EMO-DB数据集[8]是由柏林工业大学录制的德语情感语音库,由10位演员(5男5女)对10个语句(5长5短)进行7种情感(中性/nertral、生气/anger、害怕/fear、高兴/joy、悲伤/sadness、厌恶/disgust、无聊/boredom)的模拟得到,共包含800句语料,采样率48kHz(后压缩到16kHz),16bit量化。语料文本的选取遵从语义中性、无情感倾向的原则,且为日常口语化风格,无过多的书面语修饰。语音的录制在专业录音室中完成,要求演员在演绎某个特定情感前通过回忆自身真实经历或体验进行情绪的酝酿,来增强情绪的真实感。经过20个参与者(10男10女)的听辨实验,得到84.3%的听辨识别率。
实验结果
实验一共分为8部分,每一部分及其描述如表1所示

(1)视觉情绪识别结果
在视觉数据集上的实验结果如表2和表4所示。从表2中数据可以看出,与其他方法相比,作者提出的方法在eNTERFACE数据集[6]上视觉情绪识别率高达93%。;从表4中的数据可以看出,与其他方法相比,经过在eNTERFACE学习之后的模型Venter在SAVEE数据集[7]上进行学习后得到的模型VSAV视觉情绪识别准确率为96%~99%。这说明,在同一类型的数据中进行迁移,对模型性能有一定程度的提高。
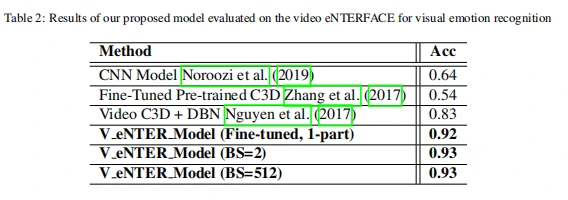
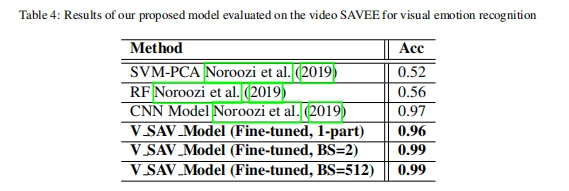
(2)从视觉跨域到音频情绪识别结果
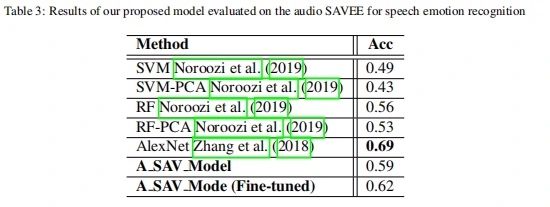
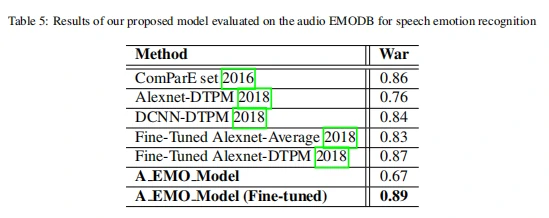
从表3中的数据可以看出,与其他方法相比,作者提出的模型经过视觉数据学习之后再学习音频数据,在SAVEE数据集[7]进行音频情绪识别上准确率为62%。从表5中可以看出。相比其他方法,作者提出的模型在经过前面的视觉数据(eNTERFACE,SAVEE)和音频数据(SAVEE)学习之后,在EMODB数据集[8]中进行音频情绪识别准确率高达89%。这说明从视觉跨域到音频数据上进行情绪识别,能够有效利用它们之间的互补关系。
(3)联合学习结果
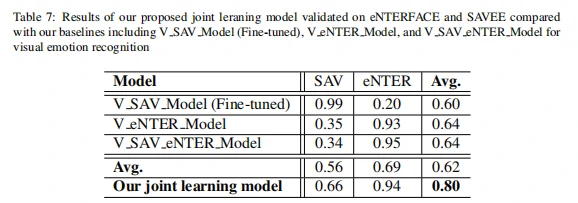
从表7中可以看出,在单一数据集上训练得到的模型,应用到其他数据集上,模型在不同的数据集以及平均的性能会有较大程度的下降,而经过作者提出的联合学习算法之后的模型在eNTERFACE[6]和SAVEE数据集[7]上,由于目标域是视觉数据并非音频数据,尽管联合学习之后在音频数据上准确率不高,但是在目标视觉数据和平均性能上,准确率非常高,分别为94%和80%。这说明模型可以很好地泛化多个数据集,从而成功地解决了数据集之间的分布移位问题。
启发
我们也可以利用这种方法,进行利用已有的视觉、听觉、以及EEG信号情感数据集作为源数据集,比如SEED以及DEAP数据集之间进行跨域情绪识别,目标数据集可以是我们进行实际应用时采集到的数据。比如针对意识障碍患者的情绪识别,我们可以利用已有的数据集进行学习以及Fine-tuning,最后利用从患者身上采集到的数据作为目标域,让我们的模型学习以及Fine-tuning,进行意识障碍患者的情绪识别。当然,如何获取目标域也很有讲究,毕竟意识障碍患者与普通患者不一样。如何选取适合的实验范式,有效刺激意识障碍患者以获得数据,也是一个可以研究的方向。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10308
[1] Hu G, Liu L, Yuan Y, et al. Deep multi-task learning to recognise subtle facial Expressions of mental states[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 103-119.
[2] Ji Y, Hu Y, Yang Y, et al. Cross-domain facial Expression recognition via an intra-category common feature and inter-category distinction feature fusion network[J]. Neurocomputing, 2019, 333: 231-239.
[3] Zhang S, Zhang S, Huang T, et al. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching[J]. IEEE Transactions on Multimedia, 2017, 20(6): 1576-1590.
[4] Nguyen D, Nguyen K, Sridharan S, et al. Deep spatio-temporal feature fusion with compact bilinear pooling for multimodal emotion recognition[J]. Computer Vision and Image Understanding, 2018, 174: 33-42.
[5] Zhang S, Zhang S, Huang T, et al. Learning affective features with a hybrid deep model for audio–visual emotion recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 28(10): 3030-3043.
[6] Martin O, Kotsia I, Macq B, et al. The eNTERFACE’05 audio-visual emotion database[C]//22nd International Conference on Data Engineering Workshops (ICDEW’06). IEEE, 2006: 8-8.
[7] Haq S, Jackson P J B, Edge J. Speaker-dependent audio-visual emotion recognition[C]//AVSP. 2009: 53-58.
[8] Burkhardt F, Paeschke A, Rolfes M, et al. A database of German emotional speech[C]//Ninth european conference on speech communication and technology. 2005.
[9] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models[C]//Proc. icml. 2013, 30(1): 3.
[10] Wu Y, He K. Group normalization[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.
[11] Nagrani A, Albanie S, Zisserman A. Learnable pins: Cross-modal embeddings for person identity[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 71-88.
[12] Sun Y. Deep learning face representation by joint identification-verification[M]. The Chinese University of Hong Kong (Hong Kong), 2015.
原文链接:https://arxiv.org/abs/2003.11136
源代码:作者未公布源代码