原文
论文:Facial Expression Recognition with Two-branch Disentangled Generative Adversarial Network
代码:TDGAN
本文贡献
提出一种利用双分支的分离GAN(TDGAN)进行表情识别。
面部表情识别任务与人脸检测任务不同。
当前工业上常用的人脸检测模型例如MTCNN,提出利用面部额外的属性信息例如表情、年龄等作为辅助任务,可以增强面部人脸识别(人脸ID)的表征能力,并且通过自监督的方式监督模型的训练过程,提高模型的泛化能力和性能,也取得了很好的效果。
然而,对于表情识别任务来说,核心是为了识别面部的表情,最理想的情况是相同的表情在不同的脸上都能完美识别。与个人信息有强关联的面部特征会对识别模型误导,也就是说,模型需要能够忽略面部与个人身份信息有强关联的特征。
2中的内容也就是提出本文方法的初衷:通过对抗学习的方式,同时学习面部表情特征和面部ID属性特征,通过表情迁移的方式把表情从一个脸上迁移到另一个脸上(图片生成),让模型能够更好的分离面部ID信息和面部表情信息。
本文提出了自监督方式提升表征学习能力,增强特征分离能力。
本文提出的方法的定性和定量分析在实验室数据集和自然场景数据集上都获得了SOTA的效果。
本文内容
表情只在面部的特定区域内运动,但是全脸作为输入的模型会学习与表情导致的面部运动区域无关的特征,这些学习到的特征不仅是多余的,对于模型的全局识别能力也是有害的。另一方面,观测对象的姿态或者对象的外观变化也会不利于特征提取的质量,最终导致模型学习到的不同面部表情的特征的辨别能力不足。
本文提出的TDGAN模型,具有两个独立的分支:表情分支用于表情信息的处理,面部分支负责其他面部属性信息的编码。如Fig.1所示。模型以一对图片作为输入,图片对包括一个表情图片和一个面部图片(分别来自不同的数据集)。TDGAN的生成器分别学习两张图片的表情表征和面部表征后使用一个解码器融合,然后通过迁移表情图片中表情到面部面部图片的方式生成一张图片。最后,通过两个分支,一个用来判断面部信息,一个同来判断表情信息。
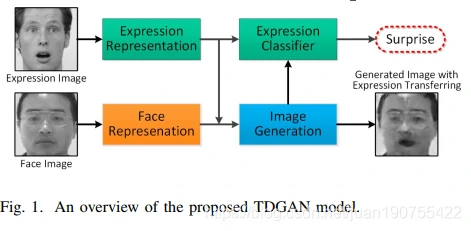
TDGAN的框架如下:
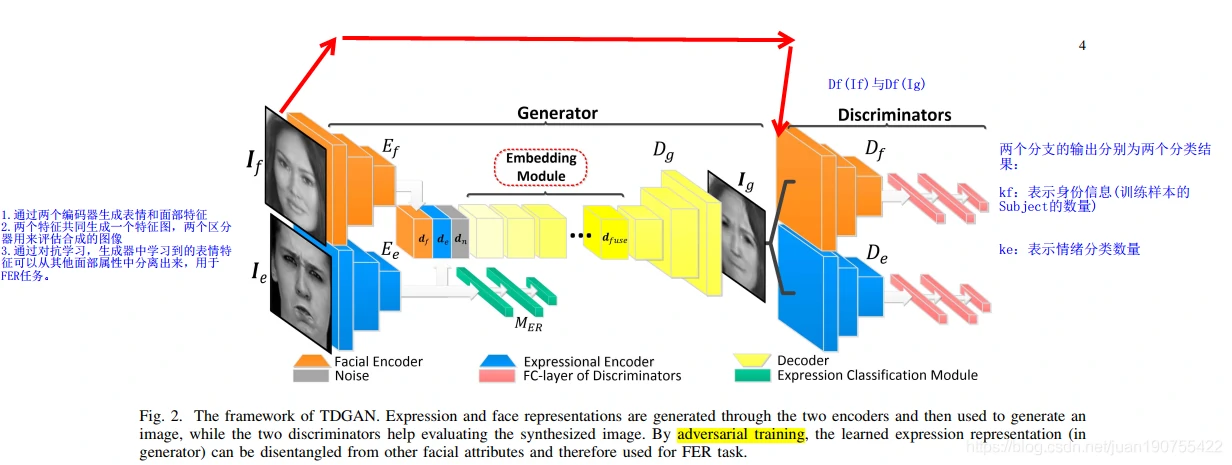
TDGAN首先通过两个编码器生成表情和面部特征,然后将两个特征融合并引入噪声(三块内容通过信道级拼接合成)。
通过一个嵌入层对融合的特征进行编码,并通过上采样方式生成Ig(模型生成的图片)。最后通过两个分支,对生成的图片进行分辨,两个辨别器分支分别为面部ID辨别器分支和表情辨别器分支。两个辨别器用来评估合成的图像的效果。如果合成的图像能够欺骗辨别器,说明模型学习到的特征已经很好。
另外,表情编码器分支还有一个FC层分支用于判别表情编码器分支学习到的特征。
通过对抗学习,生成器中学习到的表情特征可以从其他面部属性中分离出来,用于FER任务。
模型学习
使用对抗学习进行表情迁移
学习过程中,TDGAN只更新输入面部图片的表情,也就是说生成的图片应该基于输入的面部图片而不是表情图片。额外加的fake class只配置到面部分辨器。生成的图片会作为面部图片输入分支的输入(伪样本),用于训练输入面部图片分辨器;用于学习面部数据集的分布;
表情迁移分类的loss为LC:
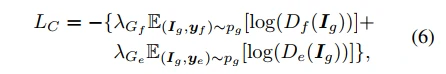
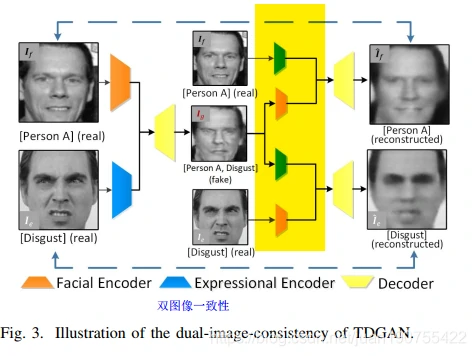
双图片一致性
使用图片的ground-truth进行训练。也就是如下图所示,训练过程中,Ig作为模型生成结果,分别与If(输入的面部图片)和Ie(输入的表情图片)编码后融合重建图片,其Loss为LD。
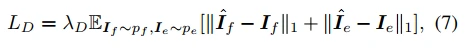
语义内容一致性
本文采用额外感知loss(additionally perceptual loss)来评估生成面部图片的差距。df是由面部编码器对面部图片编码后生成的高级语义特征,d(g,f)是生成的图片输入到面部编码器生成的高层语义特征。LP用于计算两个图片的差距。
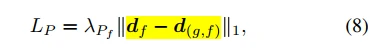
因此,本文提出方法的生成器的loss最终计算为:
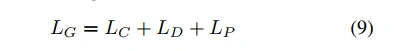
表情识别分支的loss:
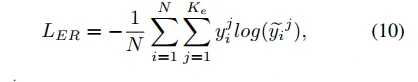
使用方法:J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for realtime style transfer and super-resolution,” in European Conference on Computer Vision, ECCV, 2016, pp. 694–711.
实验
实验细节
表情数据集的处理
本论文使用数据集分别为CK+、TFEID、RaFD、BAUM-2i,RAF-DB
CK+:选择序列的最后三帧来构建训练集和测试集;序列的第一帧作为平静脸;因此,实验中一共有1236张图片
TFEID:数据集包括8中表情(6种基本表情+neutral+contempt),本文只选取6种基本表情+neutral,一共选取580张图片
RaFD:数据标签包括表情标签和身份标签。本文只选取7种表情(6种基本表情+neutral)的数据集,共1407张图片
BAUM-2i:选取7种表情(6种基本表情+neutral),共998张图片
RAF-DB:数据集是大尺度面部表情数据集。只选取7种表情(6种基本表情+neutral)的数据集;共计12271个训练样本和3608个测试样本
试验设置
面部数据集使用CASIA-WebFace。CASIA-WebFace只选取20个Subject作为训练数据,共计2894张面部图片。因为本方法是为了学习表情特征,而增加不同面部ID的图片,会干扰模型(让模型学习太多不同面部ID的特征信息,造成干扰)
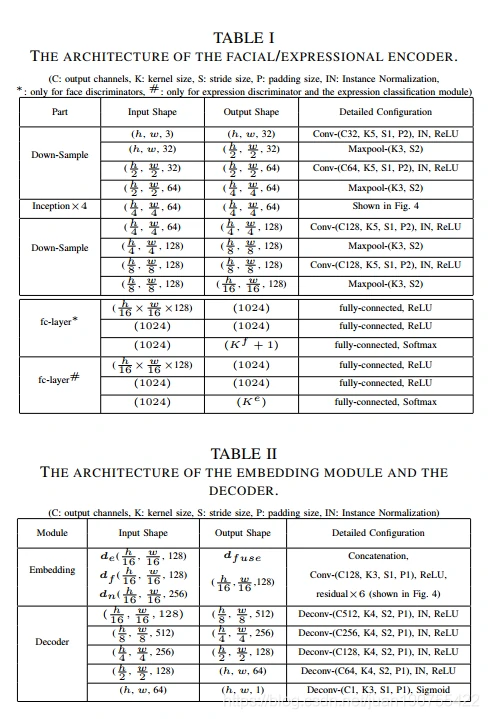
网络结构如表所示:
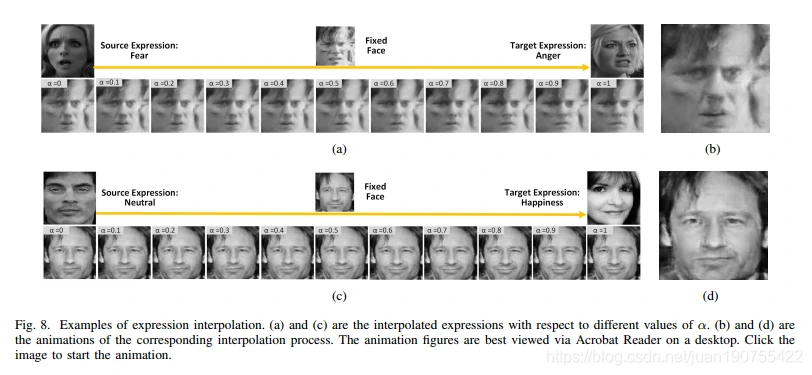
本实验验证,改变表情的特征会影响生成图片的表情,而不影响面部的其他属性信息。
- 固定面部图片,不同表情插帧
- 固定表情图片
并不同面部插帧通过插帧方法查看生成图片的过程图片。
模型分析
本文最后讨论了模型性能的问题
识别任务问题
- 双分支模型,双分支的收敛速度不一致
- 双分支模型,表情分支学习的效果比面部特征学习效果好
作者给出解决方案:面部分支使用更深/更加精细的模型进行训练;或者使用与训练模型
迁移性能问题
有些图片的迁移效果较差的原因:
- 识别对象极端姿势
- 识别对象有大面积的遮挡
- 数据集分布不均匀,例如惊讶表情较少
原文链接
https://blog.csdn.net/juan190755422/article/details/115430204