今天来看一篇工程优化文章,关于如何在多块GPU上训练大模型,作者Lilian Weng现为OpenAI应用人工智能研究负责人,主要从事机器学习、深度学习和网络科学研究。
原文链接:How to Train Really Large Models on Many GPUs?
Training Parallelism
Data Parallelism
DP最朴素的方法是复制相同的模型权重参数到多个workers上,给每个worker一部分数据来同时处理。
如果模型size大于单个GPU节点内存时,这种方法是不能work的。GeePS (Cui et al. 2016) 提出了将暂时不用的模型参数卸载回CPU上。这种数据交换传输通常在后端进行,不会干扰训练。
在每个minibatch结束后,workers需要同步梯度或参数,以保证学习效率,有两种主流的同步方法,包括它们的优缺点:
- 批量同步并行 Bulk synchronous parallels (BSP): worker在每个Mini-batch结束时同步数据,这种方法保证了模型权重传递的及时性,但每台机器都必须排队等待其他机器发送梯度。
- 异步并行 Asynchronous parallel (ASP): 每个GPU采用异步方式处理数据,这种方法避免了不同机器之间的相互等待或暂停,但影响了权重传递的时效,降低了统计学习效率。而且即使增加计算时长,也不会加快训练的收敛速度。
在每一次迭代(x >1)的中间某些地方都需要同步全局梯度,该特征在分布式数据并行(Distribution Data Parallel,DDP)中被称为“梯度累积(gradient accumulation)”。分桶梯度(bucketing gradients)避免立即执行AllReduce操作,而是将多个梯度存储到一个AllReduce中以提高吞吐量,并基于计算图优化计算和通信调度。

Model Parallelism
模型并行(Model parallelism,MP)用于解决模型权重不能放在单个节点的情况,计算和模型参数被分片到多台机器进行处理。和DP不同的是,DP中每个worker都有一个模型的完整副本,而MP只在一个worker上分配部分模型参数,因此对内存和计算的需求要小很多。
深度神经网络通常包含一个堆叠层,如果逐层拆分将连续的小层分配到工作层分区,操作起来并不难,但通过大量具有顺序依赖性的Workers来运行每个数据batch会花费大量的等待时间,计算资源的利用率也严重不足。
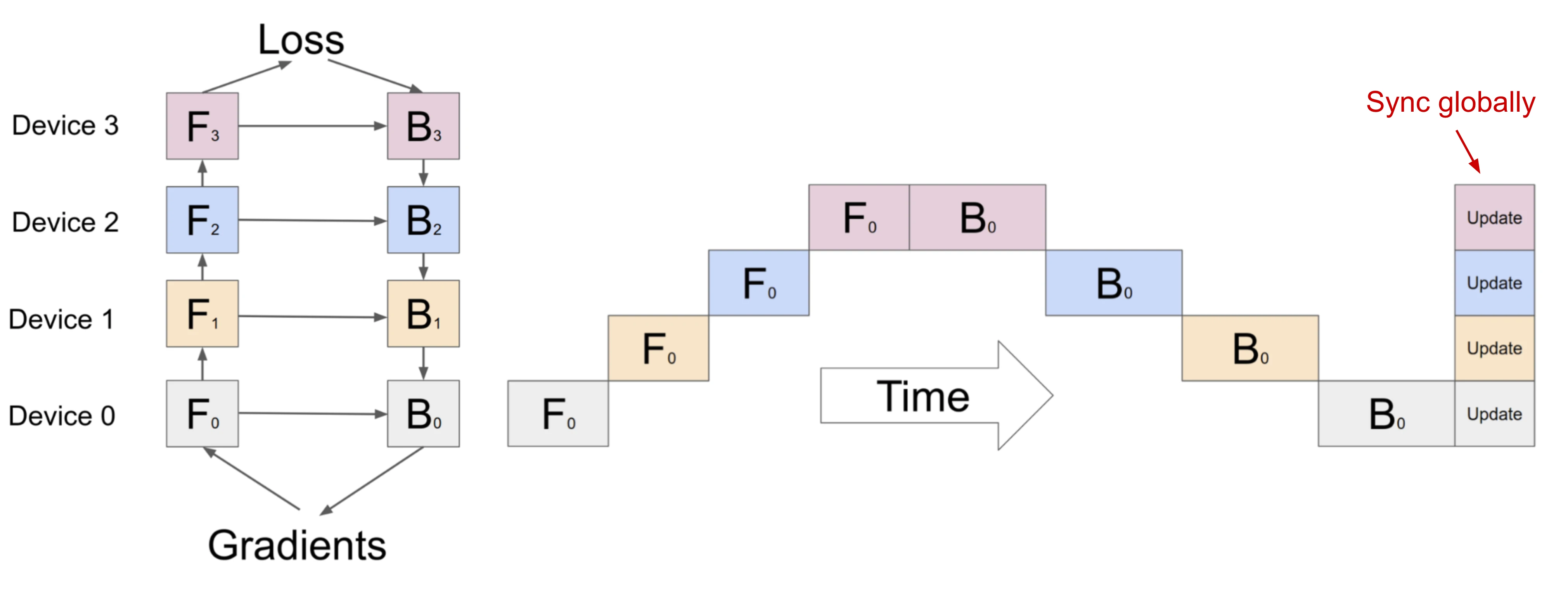
Pipeline Parallelism
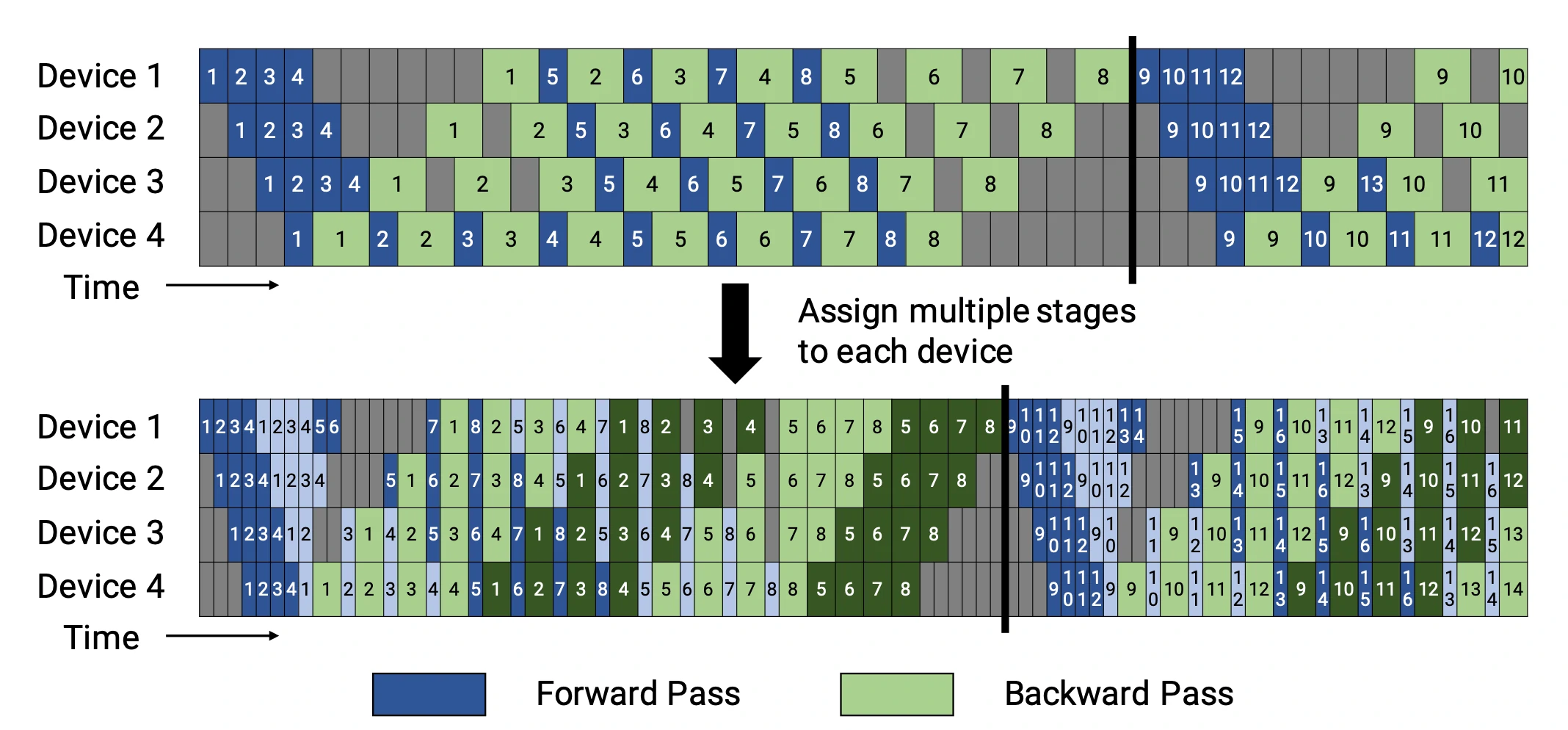
PP结合了MP和DP,来减少无效的时间。主要的思路是:将minibatch分割成多个microbatches,每个相同stage的worker同时处理一个microbatches。注意,每个microbatch包含两次传递,前后和后向。内部worker通信只传输激活(前向)和梯度(后向)。这种传输的调度方式和梯度被聚合的方式在不同的方法中又有区别。workers的数量,也被称为“pipeline depth”。
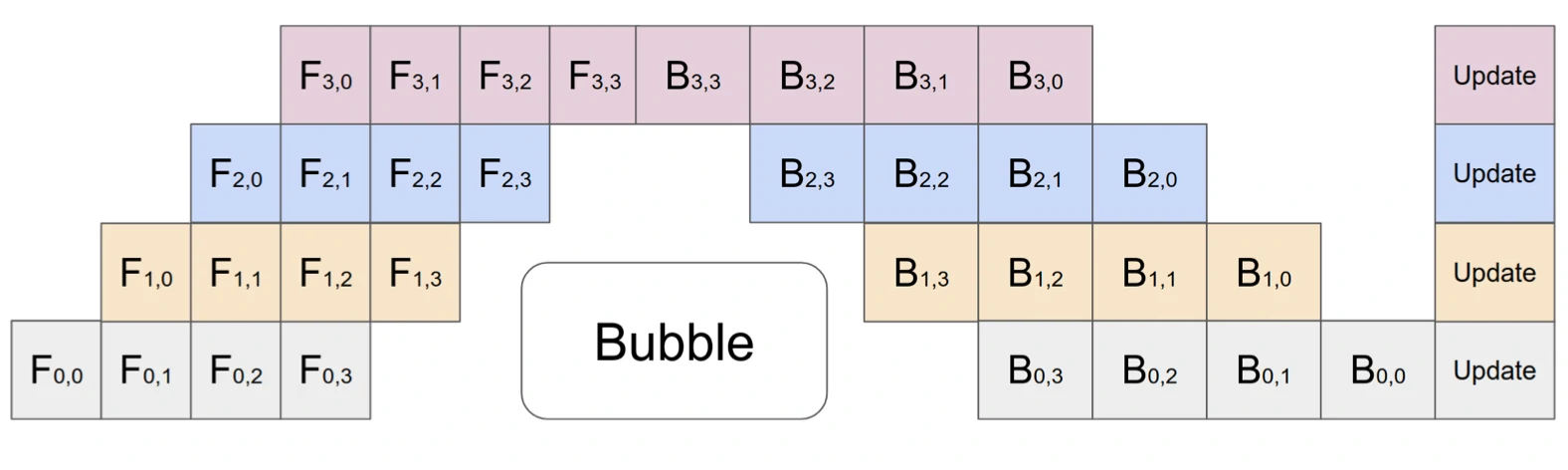
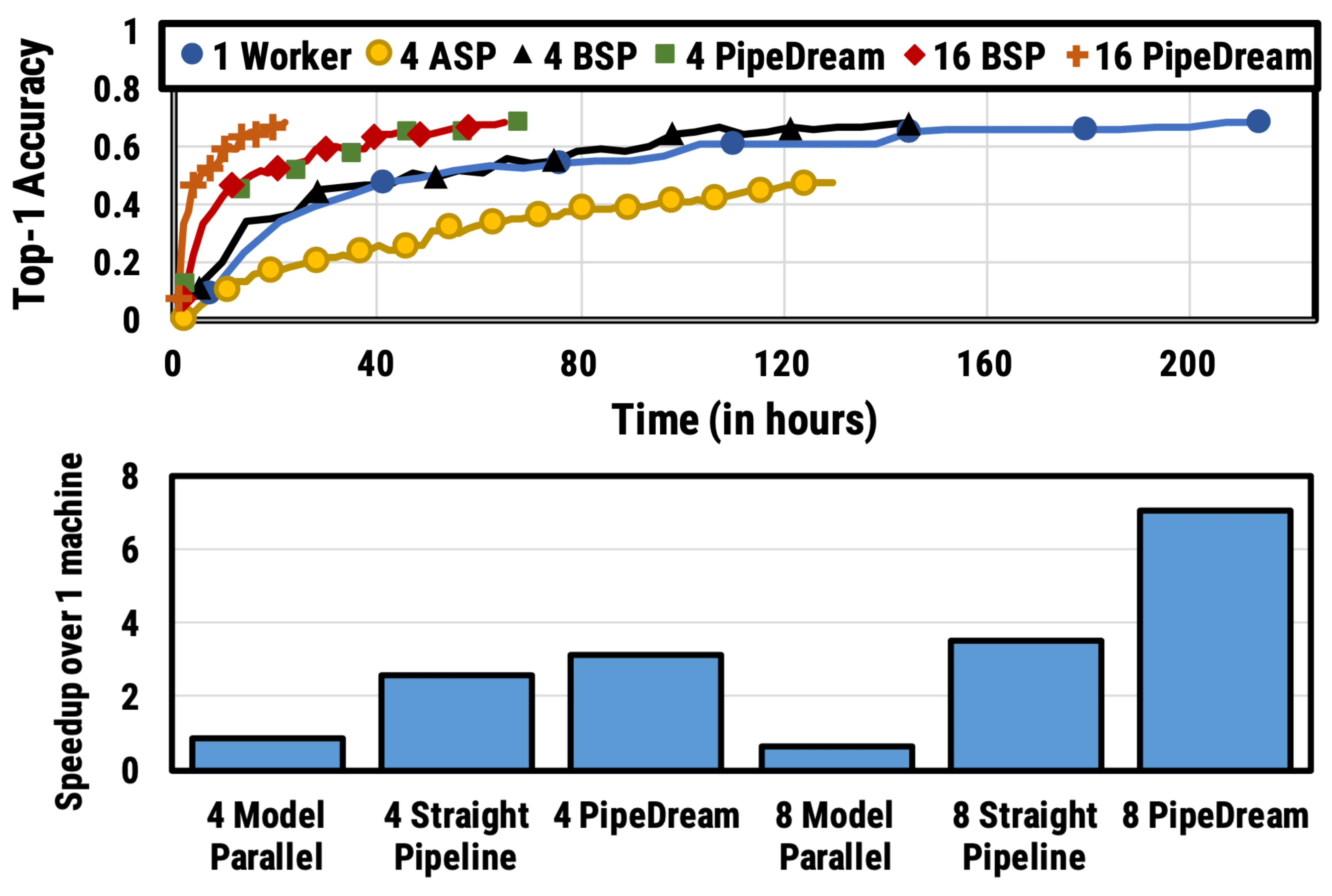
在 GPipe (Huang et al. 2019) 方法中,多个微批次处理结束时会同时聚合梯度和应用。同步梯度下降保证了学习的一致性和效率,与worker数量无关。如图3所示,“Bubble”仍然存在,但比图2少了很多。给定m个均匀分割的微批次和d个分区,假设每个微批次向前和向后都需要一个时间单位,则Bubble的占比为:
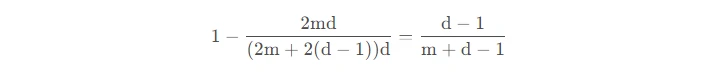
GPipe论文表明,如果微批次的数量超过分区数量4倍(m>4d),则“Bubble”开销几乎可以忽略不计。
GPipe在吞吐量上可以取得和设备数量相近的线性加速,尽管它并不能总是保证模型参数被均匀地分布在不同的worke节点上。
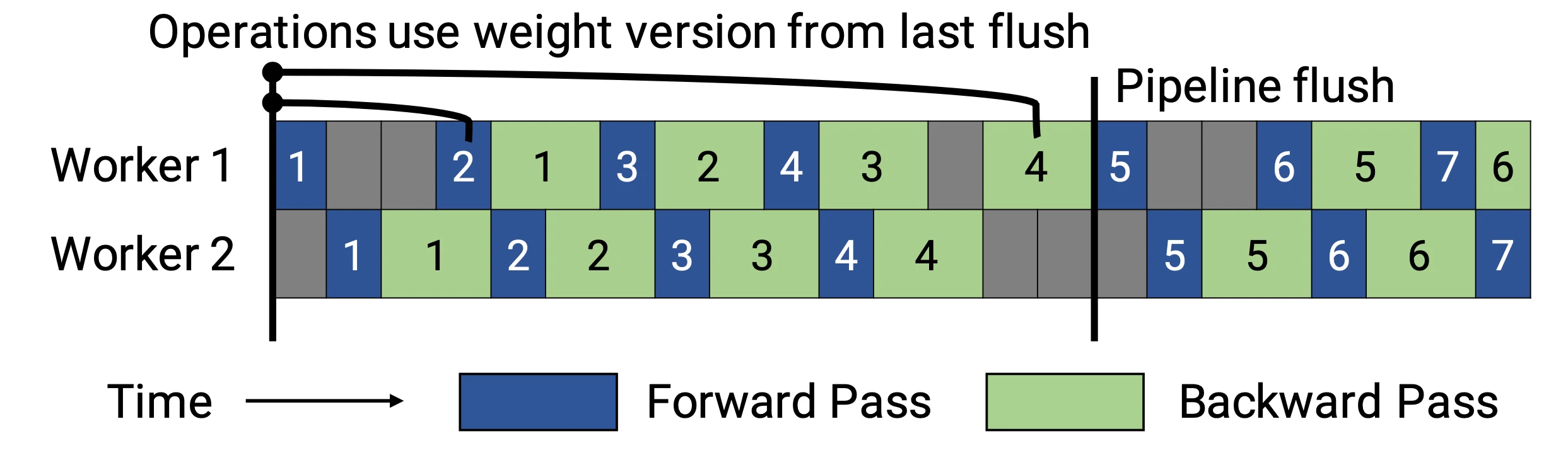
PipeDream (Narayanan et al. 2019)方法要求每个worker交替处理向前和向后传递的消息(1F1B)。它将每个模型分区命名为“stage”,每个stage worker可以有多个副本来并行运行数据。这个过程使用循环负载均衡策略在多个副本之间分配工作,以确保相同minibatch 向前和向后的传递发生在同一副本上。
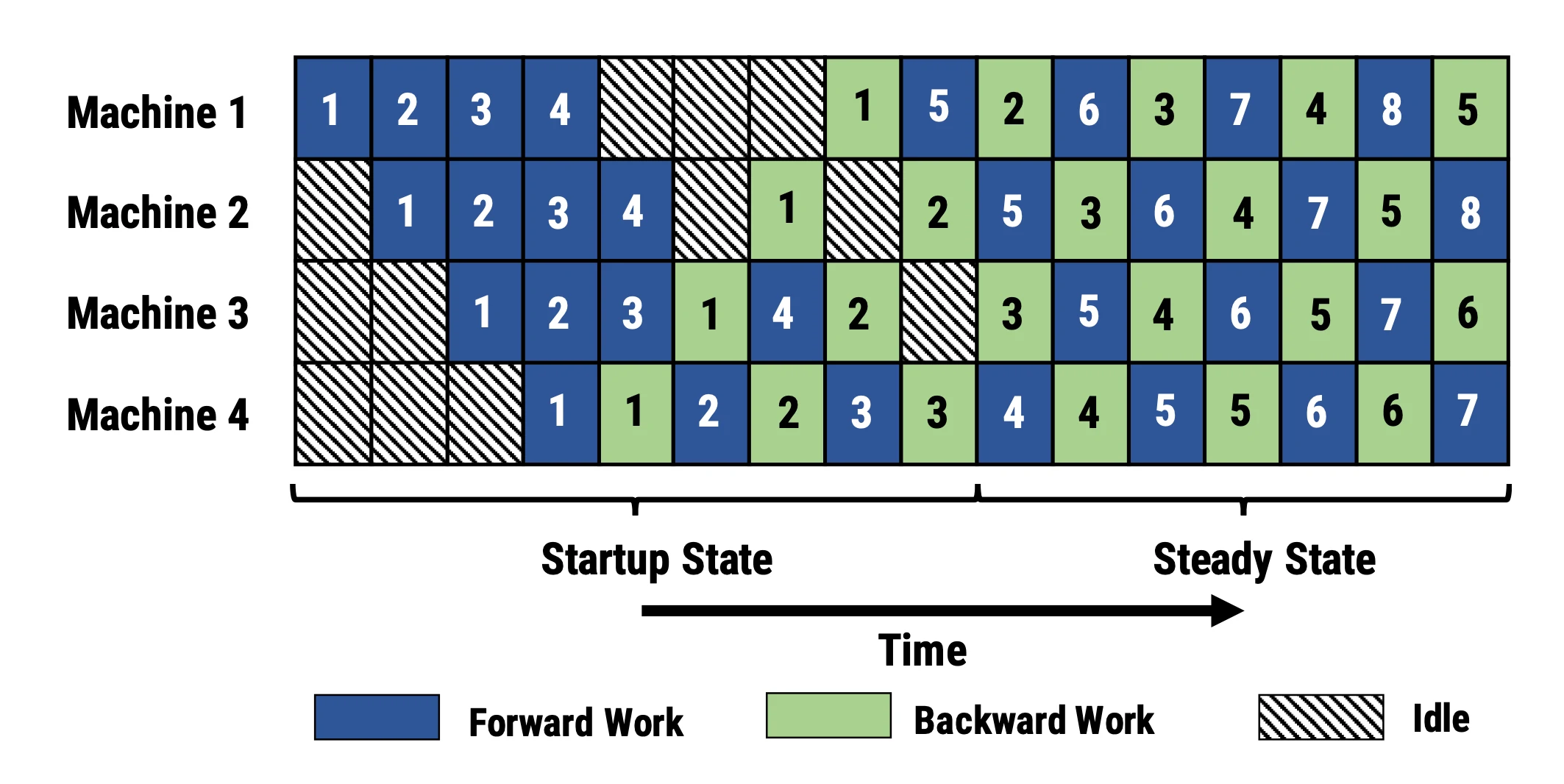
由于PipeDream没有在所有worker batch结束时同步全局梯度,1F1B 很容易导致微批次向前和向后传递中使用了不同的权重,降低学习效率。对此,PipeDream提供了一些解决的思路:
缓存权重【Weight stashing】:每个worker跟踪多个模型版本,给定数据 batch 的向前和向后传递相同版本的权重。
垂直同步【Vertical sync】:不同模型权重版本与激活和梯度一起在全局worker之间传递,计算采用上一个worker传播的相对应的缓存版本。这个过程确保了worker之间的版本一致性(不同于GPipe,采用异步计算)。
在训练开始时,PipeDream会先分析模型每一层的计算内存和时间成本,然后将层划分为不同的stage进行优化,这是个动态规划问题。
随后,有两个PipeDream的变体被提出来,以节省由模型缓存所带来的内存占用。
PipeDream-flush增加了定期刷新全局同步管道的功能,就像GPipe一样,这种方式虽然牺牲了一点吞吐量,但显著减少了内存占用(仅需要维护单一版本的模型权重)。
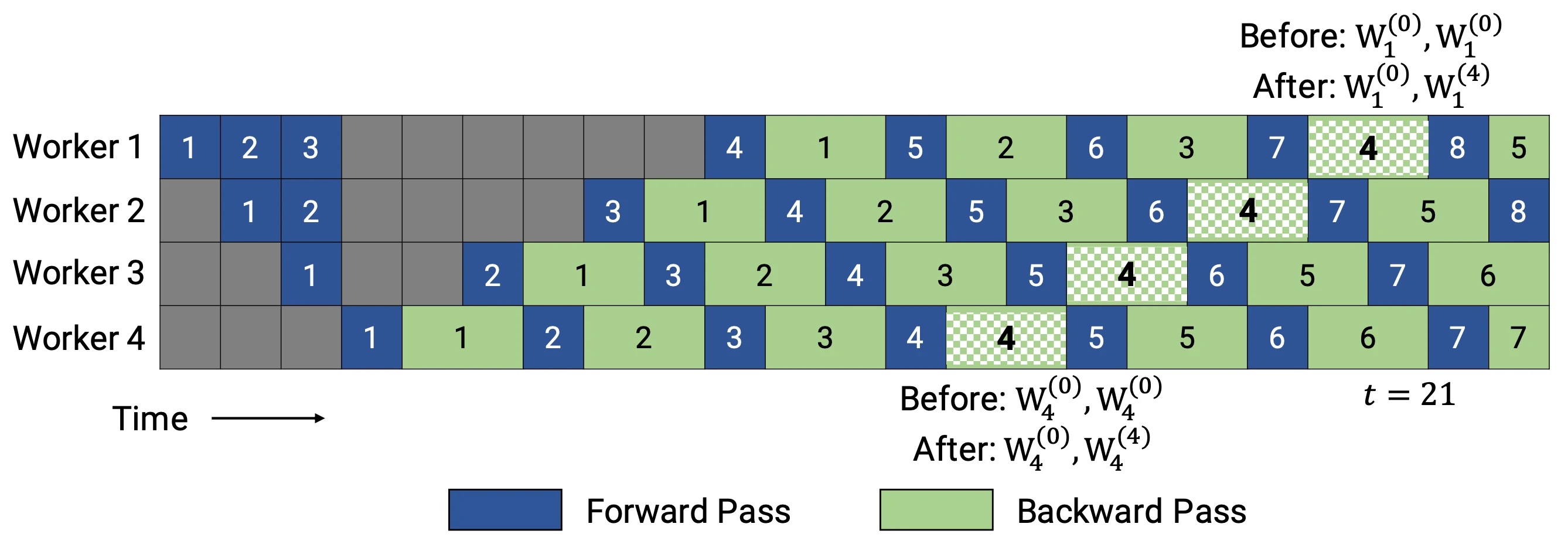
PipeDream-2BW维护了两套模型权重参数。“2BW”代表“双缓冲权重(double-buffered weights)”,它会在每个微批次生成一个新的模型版本K(K>d)。由于一些剩余的向后传递仍然依赖于旧版本,新的模型版本无法立即取代旧版本,但因为只保存了两个版本,内存占用的也被大大降低了。
Tensor Parallelism
模型并行和管道并行都会垂直拆分模型,而张量并行(Tensor Parallelism,TP)是将张量运算的计算水平划分到多个设备上。
以Transformer为例。Transformer架构主要由多层MLP和自注意力块组成。Megatron-LM(Shoeybi et al.2020)采用了一种简单的方法来并行计算层内MLP和自注意力。
MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输。如果按列拆分权重矩阵A,可以得到:

注意力块根据上述分区并行运行GEMM的 查询(Q)、键(K)和 权重(V),然后与另一个GEMM组合以生成头注意力结果。
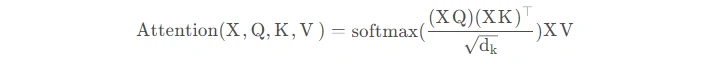
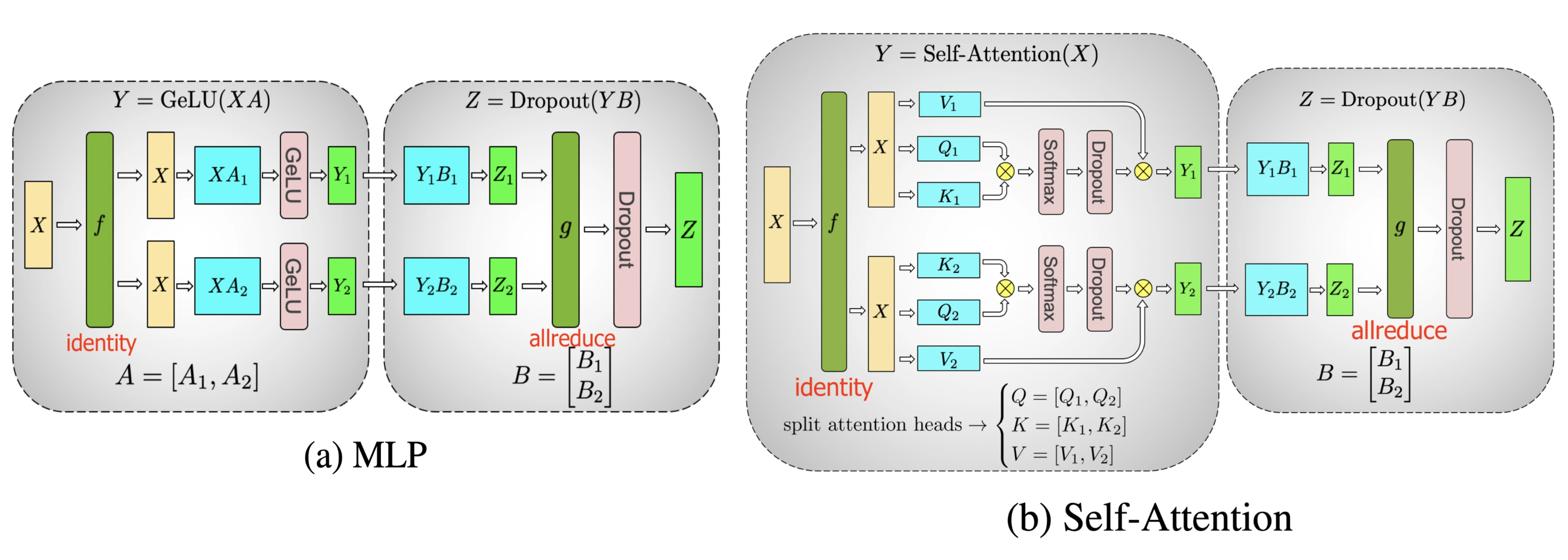
Narayanan et al. (2021)提出将管道、张量和数据并行与新的管道调度策略相结合,提出了一种名为PTD-P的新方法。该方法不仅在设备上能够定位一组连续的层(“模型块”),还可以为每个wokers分配多个较小的连续层子集块(例如,设备1具有第1、2、9、10层;设备2具有第3、4、11、12层;每个具有两个模型块)
每个batch中,微批次的数量应精确除以wokers数量(m)。如果每个worker有v个模型块,那么与GPipe调度相比,管道的“bubble”时间可以减少 v 倍。
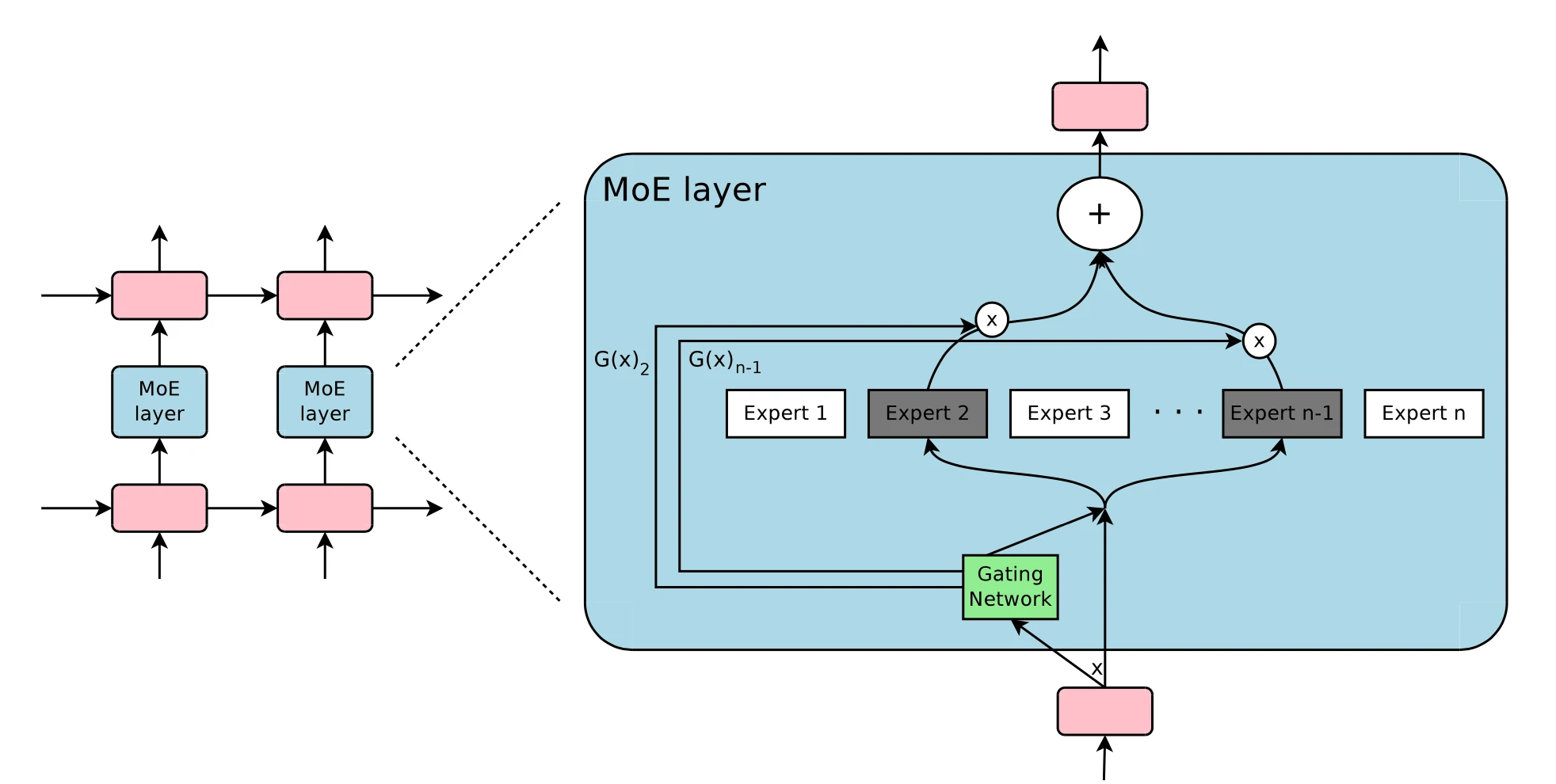
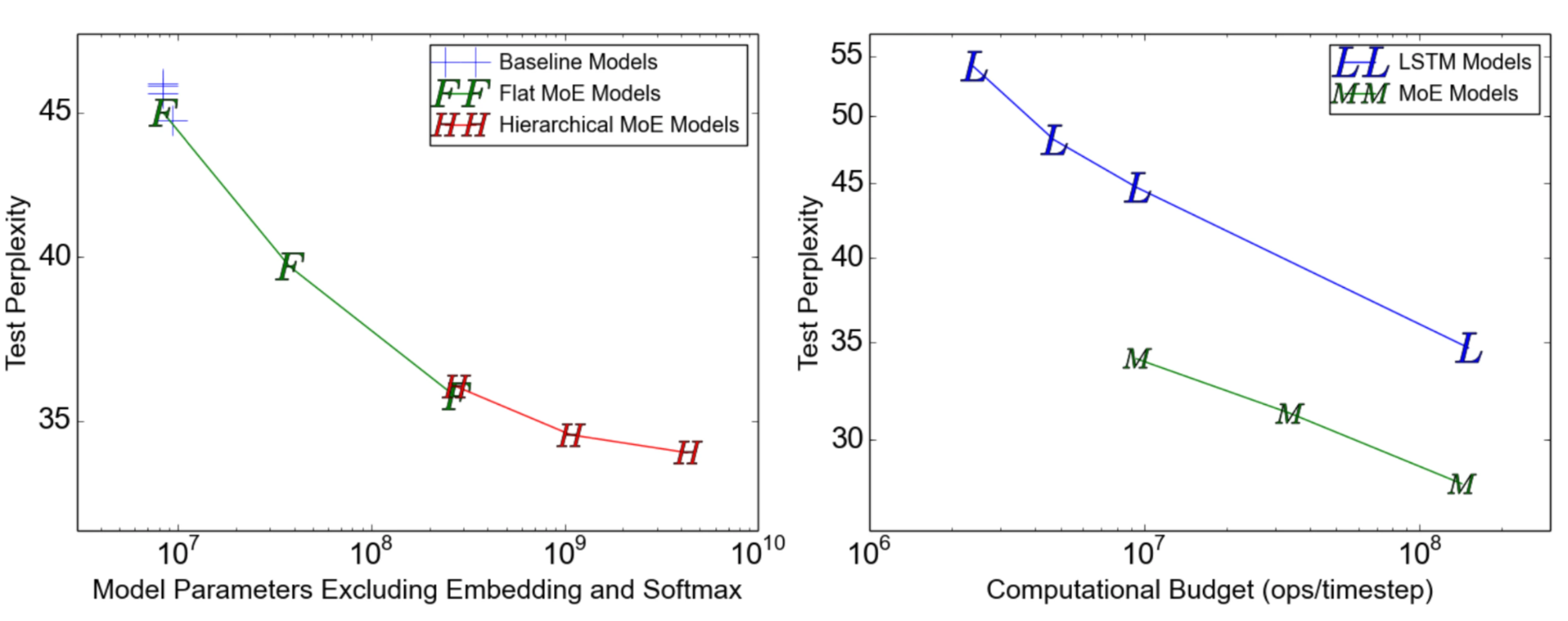
Mixture-of-Experts (MoE)
为了突破模型大小的限制,谷歌后来提出一种混合专家(MoE)方法,其核心理念是:集成学习,它假设集成多个弱学习器就会拥有一个强学习器。
在深度神经网络中,混合专家(MoE)通过连接多个专家的门机制(gating mechanism)实现集成(Shazeer等人,2017)。门机制激活不同网络的专家以产生不同的输出。作者在论文将其命名为“稀疏门控专家混合层(sparsely gated MoE)”。
仅一个MoE层包含:
- 前馈网络专家n;
- 可训练的门控网络G,通过学习n个专家的概率分布,将流量路由到几个特定的专家。
根据门控输出,并非每个专家都必须进行评估。当专家的数量太大时,可以考虑使用两层MoE。
G将输入与可训练权重矩阵Gg相乘,然后执行softmax:
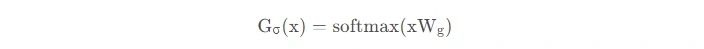
由于这个过程会产生密集的门控制向量,不利于节省计算资源,而且
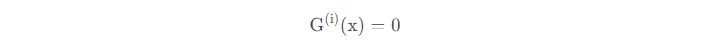
时也不需要评估专家。所以,MoE层仅保留了顶部k值,并通过向G中添加高斯噪声改进负载平衡,这种机制被称为噪声top-k门。

为了避免门控网络可能始终偏向少数强势专家的自我强化效应,Shazeer等人(2017)提出了通过额外重要损失的软约束,以鼓励所有专家拥有相同的权重。其数值相当于每个专家的分批平均值变异系数的平方:
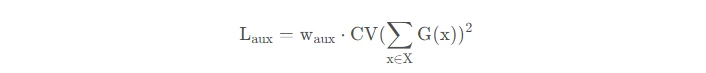
其中,CV是变异系数,失重的w_aux是可调节的超参数。由于每个专家网络只能获得小部分训练样本(“收缩批次问题”),所以在MoE中应该尽可能使用大batch,但这又会受到GPU内存的限制。数据并行和模型并行的应用可以提高模型的吞吐量。
Other Memory Saving Designs
CPU Offloading
如果GPU内存已满,可以将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。不过,这种方法近年来并不太流行,因为它会延长模型训练的时间。
Actiavation Recomputation
激活重新计算,也称“激活检查点”或“梯度检查点”(Chen et al,2016),其核心思路是牺牲计算时间来换取内存空间。它减少了训练 ℓ 层深层神经网络到 O(sqrt(ℓ)) 的内存开销,每个batch只消耗额外的前向传递计算。
具体来说,该方法将层网络平均划分为d个分区,仅保存分区边界的激活,并在workers之间进行通信。计算梯度仍然需要在分区内层进行中间激活,以便在向后过程中重新计算梯度。在激活重新计算的情况下,用于训练 M(l) 是:
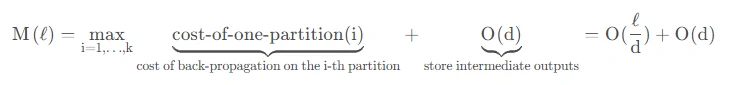
它的最低成本是:O(sqrt(ℓ))当d=sqrt(ℓ)时。
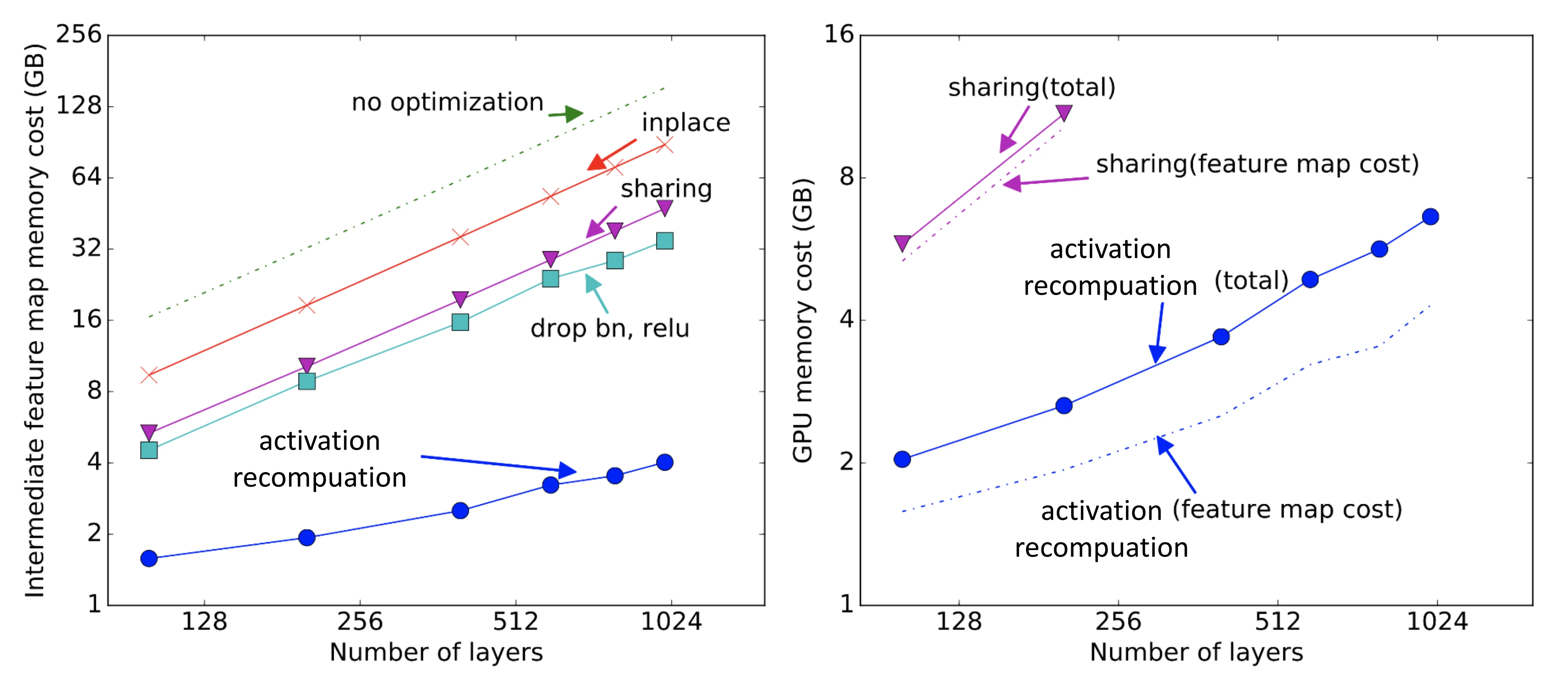
激活重新计算的方法可以得出与模型大小有关次线性内存开销,如下图:
Mixed Precision Training
Narang & Micikevicius et al. (2018)介绍了一种使用半精度浮点(FP16)数训练模型而不损失模型精度的方法。
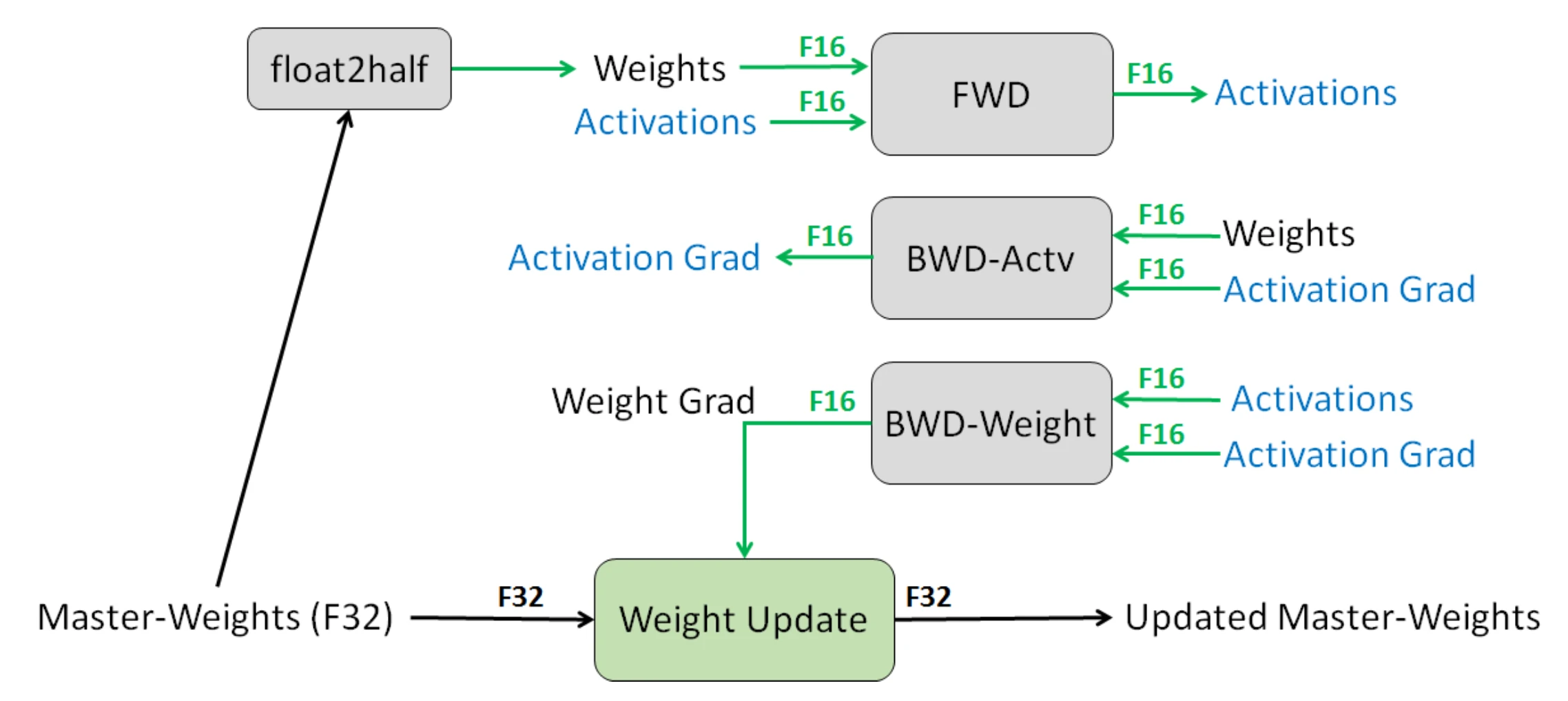
其中涉及三种关键技术:
- 全精度权重复制:保持累积梯度的模型权重的全精度(FP32)复制。对于向前和向后的传递的信息做四舍五入至半精度处理,因为每次梯度更新(即梯度X学习率)太小,可能无法完全包含在FP16范围内。
- 缩放损失:放大损失以更好地处理小幅度的梯度(见图16),放大梯度以使其向可表示范围的右侧部分(包含较大的值)移动,从而保留可能丢失的值。
- 算术精度:对于常见的网络算法(如矢量点积、矢量元素求和归约),将部分结果累加到FP32中,然后输出保存为FP16。逐点操作可以在FP16或FP32中执行。
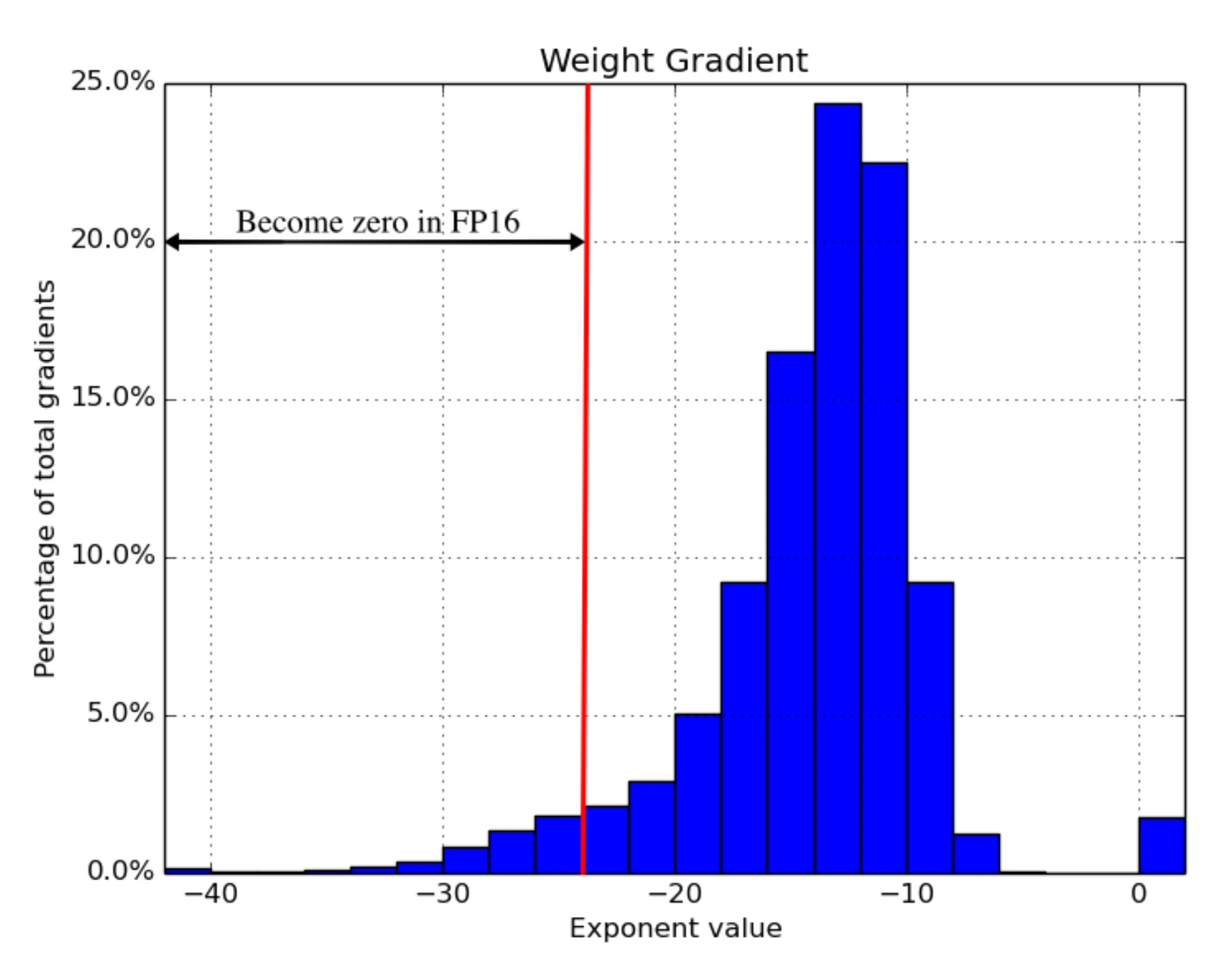
在这项实验中,图像分类、更快的R-CNN等不需要损失缩放,但其他网络,如多盒SSD、大LSTM语言模型是需要损失缩放的。
Compression
模型权重在向前和向后传递的过程中会消耗大量内存。考虑到这两种传递方式会花费大量时间,Jain(Jain et al,2018)提出了一种数据编码策略,即在第一次传递后压缩中间结果,然后将其解码用于反向传播。
Jain和团队研发的Gist系统包含两种编码方案:一是特定于层的无损编码,包括 ReLU-Pool和 ReLU-Conv模式;二是有攻击性的有损编码,主要使用延迟精度缩减(DPR)。需要注意的是,第一次使用特征图时应保持高精度,第二次使用时要适度降低精度。这项实验表明,Gist可以在5个最佳图像分类DNN上减少2倍的内存开销,平均减少1.8倍,性能开销仅为4%。
Memory Efficient Optimizer
优化器也会消耗内存。以主流的Adam优化器为例,其内部需要维护动量和方差,这两者与梯度和模型参数比例基本相同。这意味着,我们需要节省4倍模型权重的内存。
为了减少内存消耗,学术界已经提出了几款主流优化器。与Adam相比,Adafactor(Shazeer et al.2018)优化器没有存储全部动量和变化,只跟踪移动平均数的每行和每列总和,然后根据这些总和估计二阶矩。
SM3(Anil et al.2019)优化器采用了一种不同的自适应优化方法。
ZeRO(Rajbhandari et al.2019)零冗余优化器节省了大型模型训练在两方面的内存消耗:
- 大多数内存由模型状态消耗,包括优化器状态(例如Adam动量和方差)、梯度和参数。混合精度训练也需要大量内存,因为除了FP16版本之外,优化器还需要保存FP32参数和其他优化器状态的副本。
- 剩余部分被激活、临时缓冲区以及不可用的碎片内存消耗。
ZeRO结合了ZeRO-DP和ZeRO-R两种方法。ZeRO-DP是一种增强的数据并行,避免了模型状态的简单冗余。它以动态的方式跨多个并行数据划分优化器状态、梯度和参数,以最小化通信量。ZeRO-R使用分区激活二次计算、恒定缓冲区大小和动态内存碎片,以优化剩余状态的内存消耗。
参考资料
https://blog.csdn.net/qq_32275289/article/details/124377578
https://lilianweng.github.io/posts/2021-09-25-train-large/