中山大学和微软亚洲研究所团队提出了一种高质量的视频修复方法,可以填补视频帧中的缺失内容。相关论文于2020年10月发表在计算机视觉顶级会议之一的欧洲计算机视觉国际会议European Conference on Computer Vision (ECCV)。论文题目为《Learning Joint Spatial-Temporal Transformations for Video Inpainting》,本文将会对论文中的方法进行介绍。

视频修复可以帮助许多视频编辑和恢复任务,例如不需要的对象移除,刮擦或损坏恢复以及重新定位[1]。 而这种功能在步态识别研究领域中的遮挡问题具有重大启示意义,在很多步态识别的场景中,例如:车站,广场和学校等人流量较大的场景中,进行步态识别的时候受试者的步态很容易被人或者物体遮挡,导致识别失败。所以视频修复领域的技术对于被遮挡的步态的恢复具有重大的借鉴意义。
研究背景及意义
视频修复是一项旨在视频帧中缺失区域填补合理内容的任务,一种有效的视频修复算法应该具有多种实用的应用场景,例如对损坏的视频进行修复、对不需要的对象移除、视频重定位和曝光不足的图像修复[2]。然而保证画面内容的时间逻辑性一致一直是一个难题。
在最先进的方法中,为了解决内容的逻辑一致性问题,加入了attention机制用于保持对长时间的视频帧的关注。这其中又分为两种解决思路,第一种是使用帧注意力机制对相邻帧的加权和合成缺失内容。另一种方法提出了一种逐步的方式,它通过像素级注意力机制逐渐用相似像素从边界到内部的相似像素填充缺失区域。但这些方法具有两种限制,第一种是这类方法通常假设全局仿射变化或者齐次运动,这使得它们很难建模复杂的运动,并经常导致在每一帧或者每一步中的不一致匹配。另一种局限性是所有视频都是逐帧处理的,而没有专门设计的时间一致性优化。并且在有大量内容需要处理的情况下,后处理可能会失败。
为了解决这些问题,作者提出了Spatial-Temporal Transformer Network(STTN)用于视频修复的深度网络。作者将视频修复描述为一个“多到多”的映射问题,它以相邻帧和远帧作为输入,同时填充所有输入帧中的缺失内容。为了填补每个帧中的缺失区域,Transformer通过一个基于多尺度块的注意力模块搜索相关内容,包括时间维度和空间维度。
具体的说,从所有帧中提取不同尺度的块,以覆盖由复杂运动引起的不同外观变化,Transformer的不同头部计算不同尺度上空间块的相似性。通过这种设计,聚合不同头部的注意力结果,可以检测和为缺失区域转换最相似的块。此外通过堆叠多层,可以充分利用STTN网络根据更新的区域特征来改善对缺失区域的注意力结果。进一步利用时空对抗损失的加入用于联合域的优化。这样的损失设计可以优化STTN,以学习感知良好和连贯的视频内容。
总结,作者的主要贡献具体分为一下几点:
- 通过深度生成模型和联合时间和空间维度的对抗训练,学习时空域的转换完成视频修复。
- 所提出的基于多尺度块的视频帧表示可以实现快速训练和推理,这对于视频内容的理解非常重要。
- 使用固定掩码和移动掩码进行定量和定性评估以模拟现实世界的应用(例如水印去除和对象去除)。实验表明本文提出的模型在峰值信噪比 (Peak Signal to Noise Ratio ,PSNR)方面的性能优于现有技术。
论文方法介绍
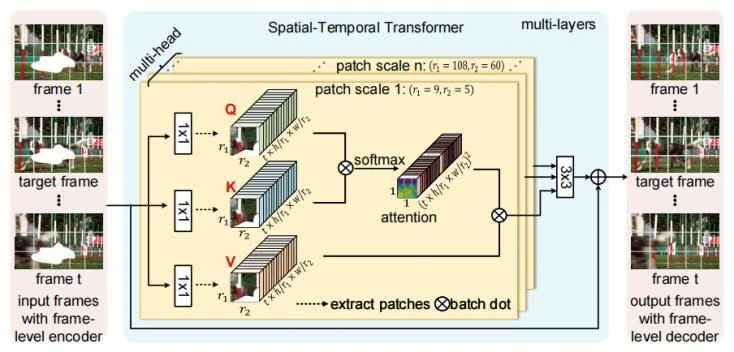
为了填补每个帧中的缺失区域,Transformer设计为从所有输入帧中搜索相关内容,作者提出通过使用一个基于multi-head multi-patch的注意力模块沿着空间和时间维度进行搜索。不同Transformer的头部计算不同尺度的空间块块,这种设计使得网络能够处理由复杂运动引起的外观变化。例如大尺寸的块块关注于完成修复不变的背景,小尺寸的块块完成对移动的前景的修复。
Multi-head 结构能够针对不同块大小的情况同时对输入的图像序列中所有图像同时进行“编码-匹配-注意力”。在编码过程中,每一帧的特征被映射为query和memory(即key-value对)以供进一步检索。在匹配过程中通过匹配从所有帧中提取的空间块块之间的query和key计算区域相似性。最后在注意力过程中检测并转换每帧中缺失区域的最相关区域。我们将介绍每个步骤的更多详细信息,如下所示:
嵌入(embedding):使用 = {, , …, },其中∈ 表示从帧级编码器或者之前的Transformer编码的特征,也是图2中Transformer的输入,其中h、w分别为输入图像的高和宽,c代表通道数。与许多序列建模模型相似,将特征映射为key和memory嵌入到Transformer中是至关重要的一步。这样的步骤能够建模出不同语义空间中每个区域的对于关系。
匹配(matching):在不同的头部进行基于块的匹配。在实际应用中,首先从每帧的query特征中提取形状为R1R2c的空间块,得到N=Th/r1w/r2块。进行类似的操作来提取memory中的块(即key-value对)。这种有效的基于多尺度块的视频帧表示可以避免冗余的块匹配,并实现快速训练和推理。具体来说,我们将query块和key块分别重塑为一维向量,这样就可以通过矩阵乘法来计算块的相似性。
注意力(attending):对所有空间块的对应关系建模之后,可以通过相关块值的加权总和获得每个块的query值。
实验结果展示
为了评估所提出的模型并与最先进的方法进行比较,采用了视频修复最常用的两种数据库——-YouTube-VOS和DAVIS数据库。YouTube-VOS数据库包含4453个各种场景的视频,包括卧室、街道等等。YouTube-VOS视频的平均长度为150帧,拆分为训练集、验证集、测试机。(3471/474/508)并按照测试集展示结果。此外还展示了DAVIS数据集的不同方法,因为该数据集由150个具有挑战性的摄像机运动和前景运动的高质量视频组成,并遵循以往方法的工作设置,安装训练集/测试集分为60/90个视频。
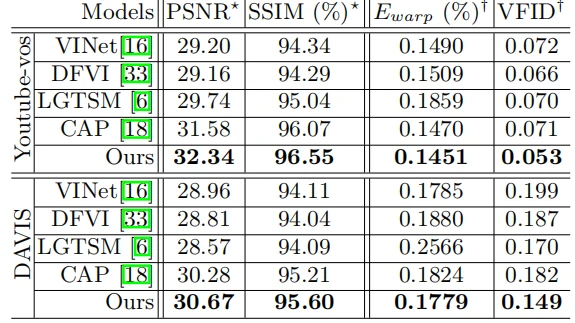
定量评估:在图3中报告了在YouTube-VOS和DAVIS上添加固定掩膜的定量结果。由于固定掩膜通常会部分遮挡前景对象,因此重建视频对象是一项具有挑战性的工作,特别是具有复杂的外观和物体运动。图3显示与最先进的模型[3]相比,作者所提出的方法具有更好的视频重建质量,包括每像素和整体感知。具体来说,STTN模型在很大程度上由于最先进的模型,特别是在PSNR、光流翘曲误差和VFID方面,具体领先分别为:2.4%、1.3%、19.7。结果表明,所提出的时空Transformer与对抗误差优化在STTN模型中的有效性。

定性评估:对于测试集的每个视频,采用所有帧进行测试,为了比较不同模型的视觉效果,遵循大多数视频插图作品使用的设置,并随即采样三帧进行研究,最终选择了最具竞争力的模型DFVI,LGTSM和CAP来比较途中固定掩膜的结果。还展示了添加移动掩膜的例子,进行成对比较和分析,如图5所示。

总结与思考
该论文就Transformer在视频修复领域展开研究。而之前的方法很难对复杂运动进行处理恢复,作者将网络结构以不同大小块的注意力机制堆叠为基础并添加多头以计算不同尺度的块。对于之前方法只能对图像序列进行逐帧处理的缺陷,作者所提出的网络同时接受序列中所有图片,并以相邻帧和远帧为依据修复当前帧。
作者发现,在连续快速的运动时,STTN可能会产生大面积的模糊块,如图6所示。STTN没有产生连续的舞蹈动作,在第一帧重建正在舞蹈的女生的时候产生模糊。是因为STTN只计算空间块之间的注意力,如果没有三维表示,很难捕捉到复杂运动的短期时间连续性。

参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=9483
[1] Lee, S., et al., Copy-and-Paste Networks for Deep Video Inpainting. IEEE, 2019.
[2] Wu, Y., V. Singh and A. Kapoor.,From Image to Video Face Inpainting: Spatial-Temporal Nested GAN (STN-GAN) for Usability Recovery. in 2020 Winter Conference on Applications of Computer Vision (WACV ’20). 2020.
[3] Xu, R., et al., Deep Flow-Guided Video Inpainting. IEEE, 2019.