本篇学习报告的内容为2020年发表在《Neural Networks》的一篇基于深度卷积神经网络实例迁移的运动想象信号分类的一区文章《Instance Transfer Subject-Dependent Strategy for Motor Imagery Signal Classification Using Deep Convolutional Neural Networks》。其影响因子为8.0505。作者提出了一个基于实例迁移的受试者独立框架(instance transfer subject-dependent,ITSD),并且结合卷积神经网络(convolutional neural network,CNN)来提高模型在运动想象任务中的分类精度。为了验证算法的有效性,作者在脑机接口竞赛数据集IV-2b上进行了评估。实验表明,使用CNN分类模型,该实例迁移学习可以实现正实例迁移。并且在三种不同的训练方法中,ITSD-CNN的平均分类准确率可以达到94.7%。原文链接见文末。
研究背景和内容
脑-机接口(brain-computer interface,BCI)是用户和计算机之间的一种通信方法,它不依赖于大脑和肌肉的正常神经通路。BCI范式之一的运动想象(motor imagery,MI)是一种在没有真实运动输出的情况下模仿运动意图的思维方式。研究表明,MI可以产生与真实运动相同的感觉运动节律变化。然而,由于受试者之间的生理结构和条件的差异,脑电信号的特征分布会有明显的变化。特别是MI作为一种自发电位活动,信号极其微弱,且总是伴随着非线性和非平稳性,这给MI的解码模型带来了巨大的挑战。随着机器学习和深度学习技术的发展,更多的分类模型被广泛用于脑电解码中。在分类模型的训练阶段,可以分为两种方式:受试者依赖(subject-dependent,SD)和受试者独立(subject-independent,SI)。
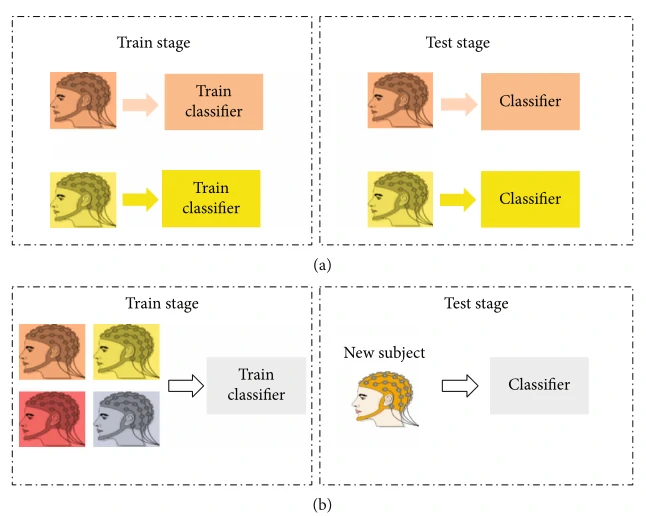
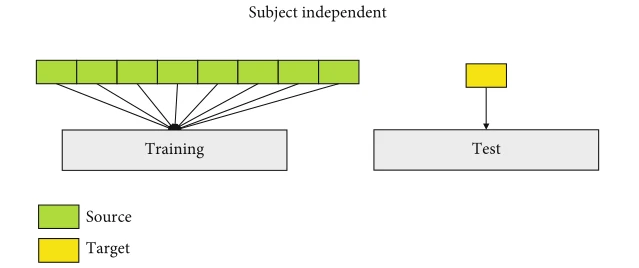
如图 1 所示,SD旨在使用自己的数据训练特定于受试者的模型。相比之下,SI 则是利用来自其他受试者的数据来训练一个适应于新受试者的广义解码模型。机器学习和深度学习的主要假设之一是训练数据和测试数据属于相同的特征空间并服从相同的概率分布。但它在脑电信号处理领域并非如此。换句话说,由于受试者之间的个体差异,SI无法满足准确性和概括性的性能。 SD提供了一种有效的方法来优化这个问题。然而,它需要长时间的校准session来收集高质量和大量的 EEG 数据集。所有这些极大地限制了 BCI 在实践中的应用。解决这一问题的另一个途径是进行实例迁移学习(instance transfer learning,ITL),它结合了SI和SD的训练方法的优点,即训练具有足够数据的分类模型。所以基于以上问题,作者提出了实例迁移受试者依赖与卷积神经网络结合框架(instance transfer subject-dependent with with a convolutional neural network, ITSD-CNN)。
研究方法
ITL的本质并不改变MI任务中信号的特征空间或性质,而是通过相似性度量找到源数据的最优迁移加权系数。然后用来自源域的相应数据的数量对迁移加权系数进行加权。如图2所示
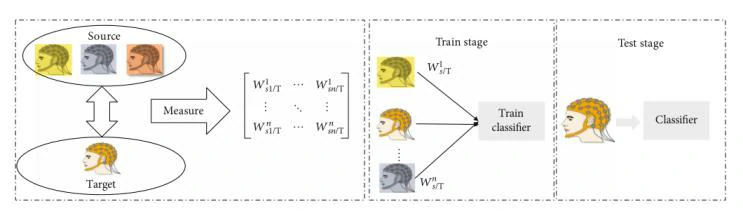
wkSi/T 是数据的传输加权系数。也有不少学者对加权系数方式进行过研究。例如,Azab等人提出了一种改进MI任务的加权迁移学习,他们使用Kulback-Leibler散度来度量信号的两个特征空间之间的相似性[1]。而该文采用感知哈希(pHash)算法通过将不同图像转换为感知哈希码并测量其距离来判断这些图像之间的相似性,获得的相似性被转换成实例迁移系数,该系数被输入到与相应数据相结合的分类器中。也就是输入到构建好的一个卷积神经网络对迁移学习后的MI数据进行分类。该神经网络架构如图3所示
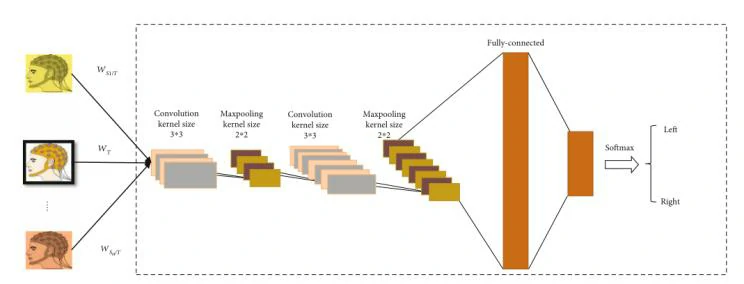
该CNN网络总共有8层。第一层为输入层,第二层为核大小为3× 3的卷积层;下一层是内核大小为2 × 2的最大池化层。再下面的两层是一样核大小和功能的卷积层和池化层。两个完全连接的层用于计算预测标签。
所提出的算法ITSD-CNN的步骤总结可以分为以下几个步骤:
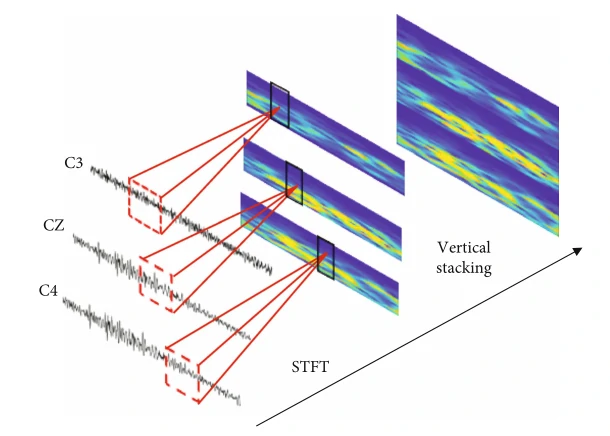
(1)首先,是对运动想象脑电信号进行预处理,并采用短时傅里叶变换(short-time Fourier transform,STFT)将原始运动想象脑电信号转换为二维谱图信号,如图4所示
(2)然后,作者提出了一种基于感知哈希算法的实例迁移算法来度量源域和目标域之间的相似性;
(3)接下来,获得的相似性被转换成实例迁移系数,该系数被输入到与相应数据相结合的分类器中。也就是放入到构建一个卷积神经网络对迁移学习后的MI数据进行分类。
实验
数据集:
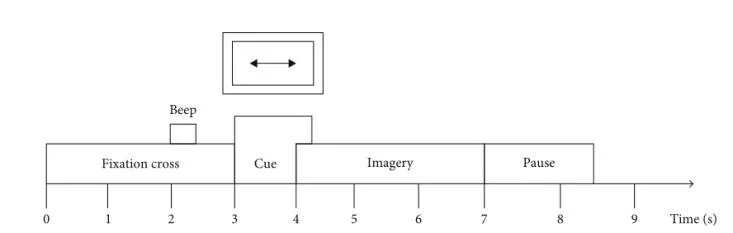
在该文中,作者采用了BCI竞赛数据集IV-2b。该数据集由柏林的BCI研究所提供,包含两个部分:标准集和评估集。9名受试者参与了该实验,并使用三个通道(C3、C4和CZ)以250 Hz的采样率记录脑电图。实验中要求每个受试者根据提示想象左手和右手的运动。实验过程如图5所示
实验方式:
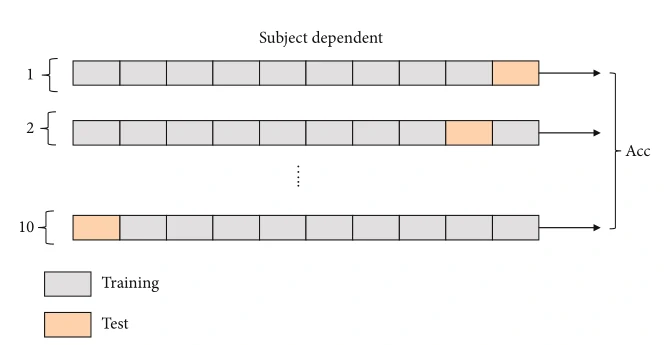
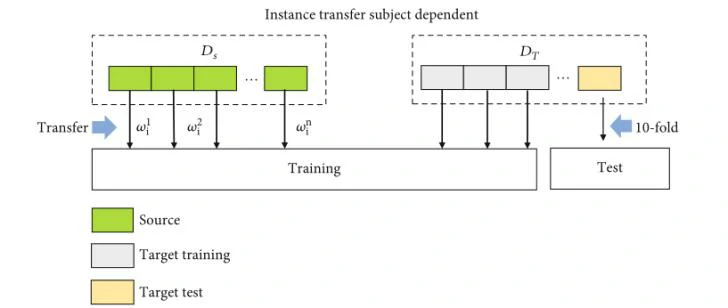
为了评估实例迁移学习的有效性,比较了三种实验训练方式。分别是(1)SD训练方法(图6),使用10折交叉验证将一个受试者的总共720次trail分为训练数据和测试数据;(2)SI训练方法(图7),使用来自源受试者的数据训练通用模型;(3)ITSD训练方法(图8),来自源域的加权数据与目标数据一起输入到训练集中。剩下的目标域数据用于测试模型性能。
实验结果:
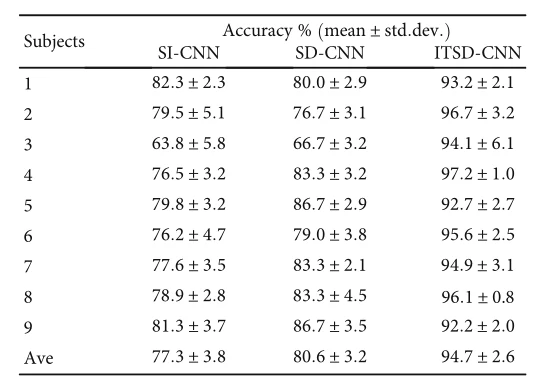
从表1可以看到这三种训练方式在9个受试者上的准确率,尤其是作者所提算法的准确率基本都可以达到90%以上,平均准确率有94.7%,可以说是取得了比较满意的结果。
总结和思考
(1)该文所提出的一种新的基于深度神经网络的实例迁移学习方法,应用于BCI系统中运动学习的受试者依赖分类。在这篇文章中,由于运动想象谱图图像中包含丰富的频率和能量特征信息,非常适合提取运动意图特征,所以作者利用基于感知哈希算法的实例迁移学习来度量源域和目标域数据之间的相似性。然后将相似度转化为迁移权重系数,实现单次试验在不同受试者之间的数据迁移,成功优化分类模型训练中的小样本问题。同时,该算法可以有效地提供基于受试者依赖训练方法的数据增广,提高分类器的性能,文章中的实验证明了该训练方法的优越性能和潜力。
(2)与传统方法相比,深度学习在脑电分类中的应用提高了性能。然而,它在实际应用中仍存在一些限制。脑电的特征分布在同一任务中总是表现出跨被试/会话的差异,这可能会导致网络训练中的过度匹配。而迁移学习被证明有助于受试者/会话分类的表现。它可以用来初始化BCI的一个受试者知识迁移到另一个新的受试者上。同时,这种方法可以帮助分类器从所有受试者中学习全局特征,而不会陷入局部最优。因此,迁移学习结合了SI和SD方法的优点,并优于它们。
(3)另一个限制是用于分类器训练的小规模样本。对脑电数据质量和采集的严格要求使得实际中很难获得大数据集。基于深度卷积网络的脑电解码性能与训练数据量直接相关,数据增强是解决这个问题的一种很有前途的方法。传统的增强方法包含几何变换和模型生成,但这需要很长时间来准备和选择合适的生成数据,它占用了 BCI 系统中的大量计算资源。因此,从可用数据库中进行数据扩充可能提供一种可能的方法。正如该研究所提出的,ITL可以很容易地从其他受试者中获取数据并自适应地为迁移数据分配权重,从而实现跨被试数据的利用率最大化。我认为将来可以进一步研究跨被试可变性的细节,从而实现更有效的迁移学习。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10257
[1] A. M. Azab, L. Mihaylova, K. K. Ang, and M. Arvaneh,“Weighted transfer learning for improving motor imagery based brain–computer interface,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 27, no. 7,pp. 1352–1359, 2019.