背景和动机
ShuffleNetV2是轻量级模型领域中的一个经典案例, 提供了许多实用的轻量化设计指导原则和分析方法。此外,它创造了一种新的轻量级模块设计范式,使得模型能够不依赖“残差连接”训练深度网络,也能达到高效和高性能的效果。
本文主要介绍 ShuffeNetV2 的加强版本 - AugShuffleNet
内容包括:
- 分析ShuffleNetv2模型的基本模块Shuffle Block 的设计优点: partial computation和 efficient short paths。
- 分析Shuffle Block设计的局限性:a.计算开销和冗余控制能力弱;b.模块中间层的信息浪费。
AugShuffleNet继承了 ShuffleNetV2的设计优点,通过分析后者的设计缺陷并提出了非常简单的改良方案:
- 通过引入split ratio控制计算开销和冗余:压缩Shuffle Block模块前两层卷积的宽度以提高模型效率(计算开销和访存)。
- 将第二层的输出通道特征和模块的保留特征进行交换:充分利用中间层的信息避免浪费的可能性,并促进跨层信息混合以提高模型性能。
在cifar10和cifar100的数据集上,AugShuffleNet可以在不改变网络架构的情况下,在计算量、参数量、推理延时和分类准确率方面都超过ShuffleNetV2。并且,在网络宽度因子为1.5时,AugShuffleNet可以将split ratio降到0.125(降低局部网络宽度), 即高度压榨模型效率的情况下,仍然能保持对ShuffleNetV2的性能优势。
方法
本节主要分析:
- 通道全连接结构和通道冗余问题
- Shuffle Block的设计优点和缺陷,并理论解释了缺陷来源
- 提出Shuffle Block改良版本, Augmented Shuffle Block
通道全连接和通道冗余
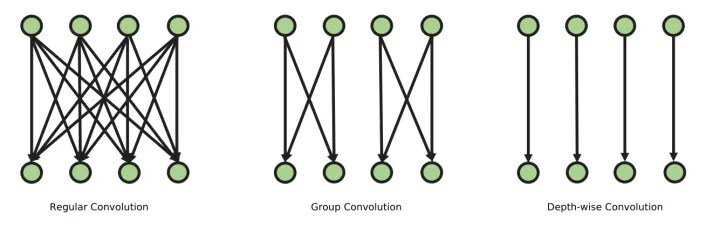
如图1左所示,标准卷积在通道维度上存在全连接结构(channel-wise fully connected structure),在网络较宽时容易造成通道冗余(channel-wise redundancy),进而带来不必要的计算开销,拖慢模型训练和推理速度。
而许多稀疏化设计方法和压缩算法之所以奏效,本质还是缓解了高维度下(网络太宽,通道数太多)通道全连接结构带来的通道冗余。即使是先进的SOTA大模型都存在相同的问题,在加宽网络时也忽略了通道冗余的存在,因而只能做到部分指标的trade-off,而无法做到全部指标的提升。
Shuffle Block
由于实验设备资源限制,本文将聚焦轻量化模型ShuffleNetV2,借此揭示通道冗余带来的问题。
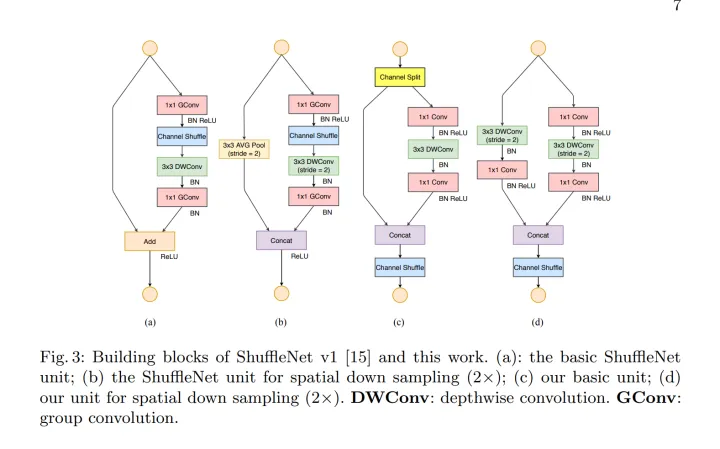
如图2, 在模块设计方面来看,ShuffleNetV2的模块Shuffle Block可以看作是ShuffleNetV1模块的一种特殊情况:即进行分组卷积(分组数为2)时,一组保留特征不做计算,另一组进行卷积,并改变了channnel shuffle的位置。
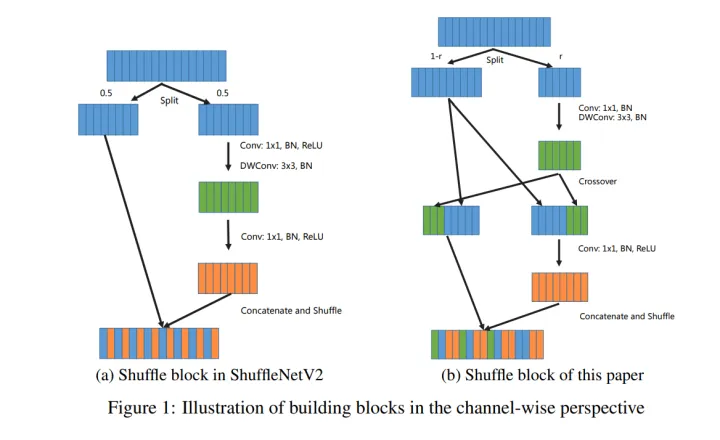
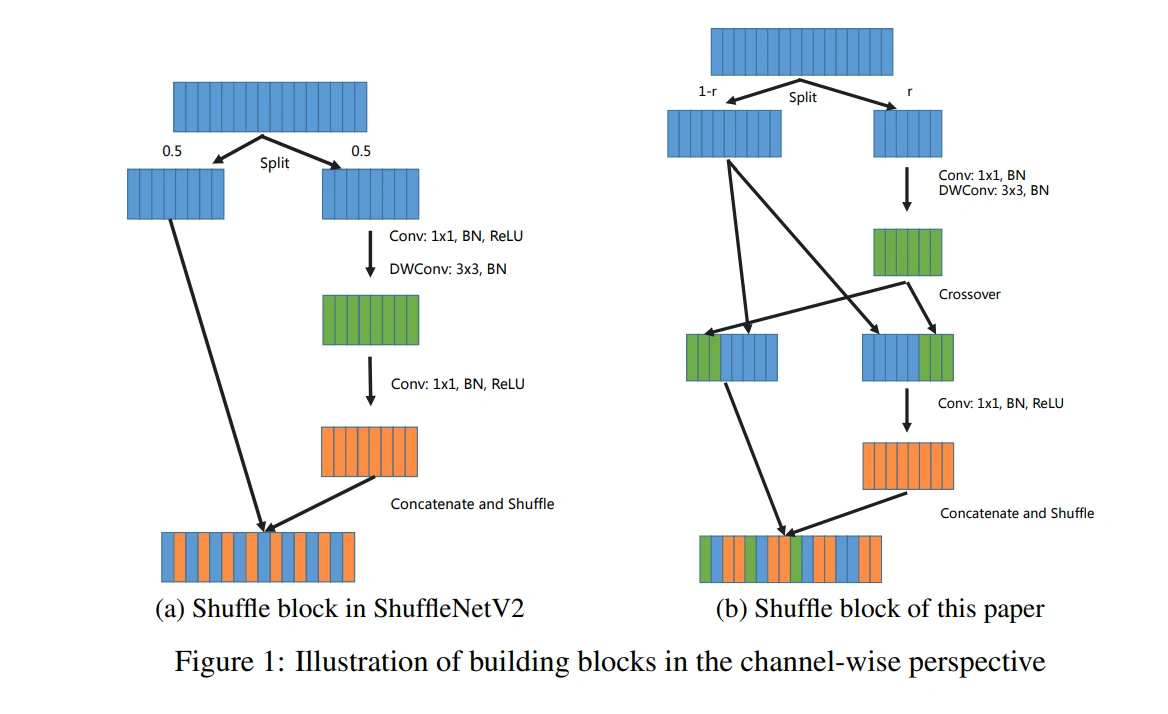
图3左展示了ShuffleNetV2模块的通道示意图,该模块的优点是:
- Partial computation: 采用了 channel spit ,只对输入通道进行部分计算, 可以节省计算开销和访存。
- Short Paths:利用 Partial computation的结构特点,使用 channel split 和 channel shuffle 操作相互配合,使得浅层的特征能够有周期规律地混入网络的更深层(ShuffleNetV2原文提到这是特征重用,类似DenseNet. 我更倾向于叫它特征延迟使用,因为它实际上并没有真正地重复使用浅层特征)。与UNET、ResNet和DenseNet等模型类似,这可以保证模型能够不依赖残差连接,也能为网络引入优化过程中的短路径(short paths),降低优化难度,并提升模型性性能。顺便一提,残差的输入是2个张量,输出是一个张量,条件相同情况下其访存成本比卷积层还高,残差连接数量过多会影响模型推理延时。
下面分析其模块缺点:
- 计算开销和冗余的控制能力很弱。因为模块中3层卷积都要求保持输入输出通道数量相等。用宽度因子粗暴地加宽网络时,Shuffle Block模块计算分支容易产生通道冗余。
- 中间信息层信息没有被有效利用。后一层如果只需要少许中间层的通道信息,那么其他通道可能就被浪费。尽管模块只有3层,但是整个网络有十几个模块,浪费是相当可观的。此外,万一在反向传播中梯度陷入了中间某一层,就相当于无效学习了。这可以看作是沿着网络深度方向的“冗余风险”。
下面会更加详细地理论分析Shuffle Block的通道冗余。冗余来自于不合理的计算分支的设计。
如图4,其计算分支有3个卷积:1×1 regular convolution, 3×3 depth-wise convolution, 1×1 regualr convolution。 而且,三层卷积的输入和输出通道数量被强制要保持相当。这实际上是不合理的设计原则,也是ShuffleNetV2冗余的导火索。如图4,由于模块中首尾两个标准卷积存在通道全连接结构(depth-wise convolution相当于通道上一对一的scale因子,可忽略),这个规定会放大整个模块的通道冗余,在加宽网络时尤为严重。
Augmented Shuffle Block
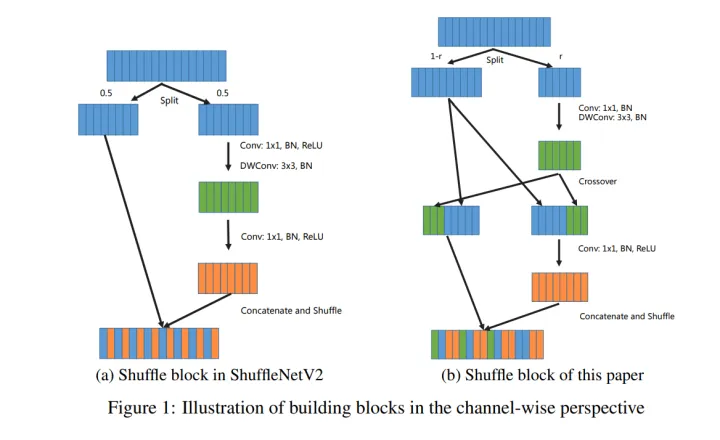
为解决上述问题,AugShufleNet提出了改良版本的Shuffle Block,如上图右(免得翻页,文章重复插入图片一遍,其改进点如下:
- 将channel split 的分割率split ratio(小于0.5)设置为变量而不是0.5,这可以灵活调整模块的计算开销,控制计算冗余。具体地,split ratio控制模块前两层卷积( 1×1 convolution 和 3×3 depth-wise convolution)的宽度,前两层的输入和输出通道数量保持相等。减少 r 值,可以按照比例减少整整两层的计算开销和访存成本,用来提升模型效率(包括计算量参数量,计算量,训练和推理延时)。
- 在depth-wise convolution之后引入channel crossover, 将输出特征和模块输入保留的特征通道交叉互换一半。这样一来,第三层 1×1 convolution的输入通道其实正好等于整个模块输入通道数量的一半。因此,改良的模块就不需要修改架构参数来构建模型,从而和原始ShuffleNetV2模型进行公平的比较。
- 去除第一层卷积的激活函数,节省了整整一层的计算时间和访存时间,这可以进一步加速训练和推理。
可以看到,该模块通过调整 split ratio可以控制冗余(起到”通道降维”作用),配合channel crossover(起到”通道升维”和交换信息的作用),整个模块计算分支呈现BottleNeck结构。
值得一提的是,这种通道维度的“升降”不像其他BottleNeck变种一样依赖两个 1×1 convolution。如上文所述,连续的 1×1 convolution在通道上是全连接结构,前一层的输出通道数量等于后一层的输入数量,网络达到一定宽度时,不可避免产生通道冗余,这不利于灵活控制计算开销和冗余。
本文的模块中所谓的“升维”其实和特征重用Concat没什么区别,只是顺便交换了信息, 和channel-split配合之下(只取局部通道进行计算)产生的BottleNeck结构是可以比其他BottleNeck结构更能灵活控制计算开销和冗余。此外,channel crossover也充分利用了中间层的信息,使其部分特征也能流入到更深层的网络。
因此在各种操作配合下,该模块能更加灵活控制地控制计算开销,提升模型效率,并利用特征跨层混合的优势提高模型性能。
模块理论效率分析

图5分析了改良模块相对于原始 Shuffle Block 的效率(计算量和参数量)。总而言之,channel split 的通道分割率 r,决定了效率, r 越小,其效率就比原始 Shuffle Block 更高。
文中暂时没有给出延时的分析,实际上也是差不多的。由于split ratio小于0.5(本文实验默认是0.375,也做了split ratio为0.25和0.125的实验), 改良模块前两层卷积 1×1 convolution 和 3×3 depth-wise convolution输入和输出通道数量保持相等,同时受到split ratio控制,再加上额外消除了一个ReLU激活函数。这些都是对推理速度的正面作用。而channel crossover作为负面作用会增加一点延时,但是相比于节省下来的两层卷积和一层激活函数的计算时间和访存时间是更小的,所以绝大多数情况下可以保证改良模块的训练和推理速度更快。(之所以不能绝对保证是因为可以设定一些极端的条件,比如模型宽度本身很小,只有几个通道,而计算单元性能又超级高,那就有可能导致channel crossover引入的延时高于节省下来的延时)。
网络架构和实验结果
上文分析了效率优势,那么模型性能又如何呢?
在修改的模块中其实存在两种设计因素的博弈。split ratio的引入迫使模块中前两层卷积比原始Shuffle Block更窄,虽然能提升效率但也会造成性能损失(在冗余比较大的情况下,性能损失可能比较小)。channel crossover交换信息,能提升模型性能。因此,模型最终效果还取决于网络宽度因子和通道分割率(split ratio)。
实验表明,Cifar10和Cifar100上,AugShuffleNet模型性能和效率都优于ShuffleNetV2。
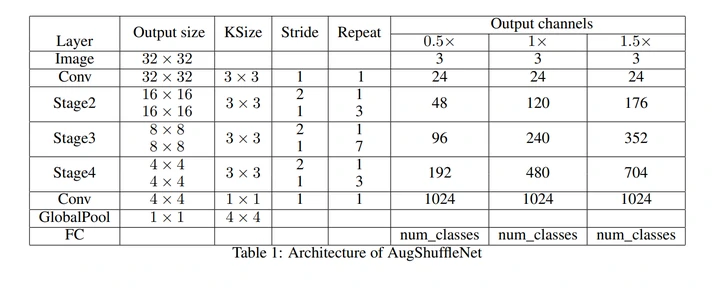
其架构参数参照了ShuffleNetV2。如图6,0.5和1.5宽度因子下,通道数量和ShuffleNetV2相等,这是指整个模块的输入输出相等,而模块内部我们实际使用了更窄的网络。1.0宽度因子的网络通道数量比ShuffleNetV2增加了一点,这是考虑到shufflenetv2原始的通道数量乘以通道分割率不是整数。
默认情况下,分割率为0.375,改良模块会代替原始ShuffleNetV2中Stage3和Stage4中不包括下采样的Shuffle Block,替代了10个模块,所以在计算量,参数量和延时方面的改善是相当可观的。Stage2不替换是因为浅层通道特征很重要,破坏了伤害模型表现,通道数量太少,替换了又提升不了多少效率,换了得不偿失。
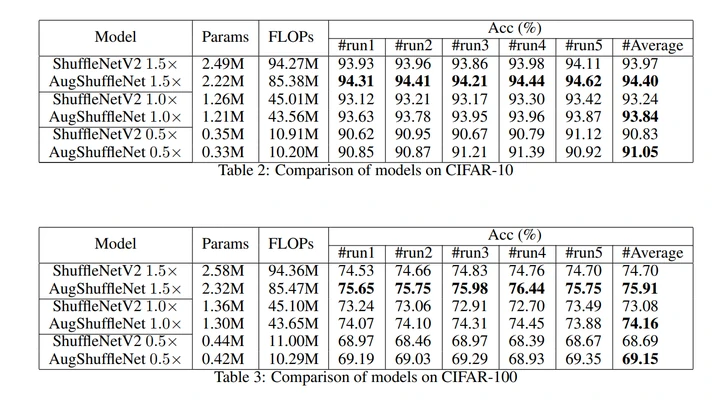
AugShuffleNet各种指标都超过ShuffleNetV2, 延时暂时没给结果,笔记本电脑上实际测试还是更快的。
测试Split ratio对模型的影响
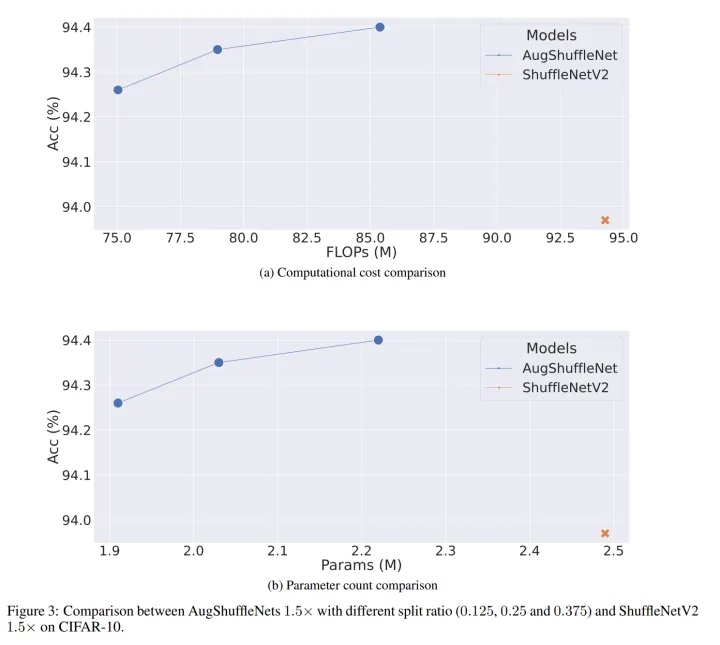
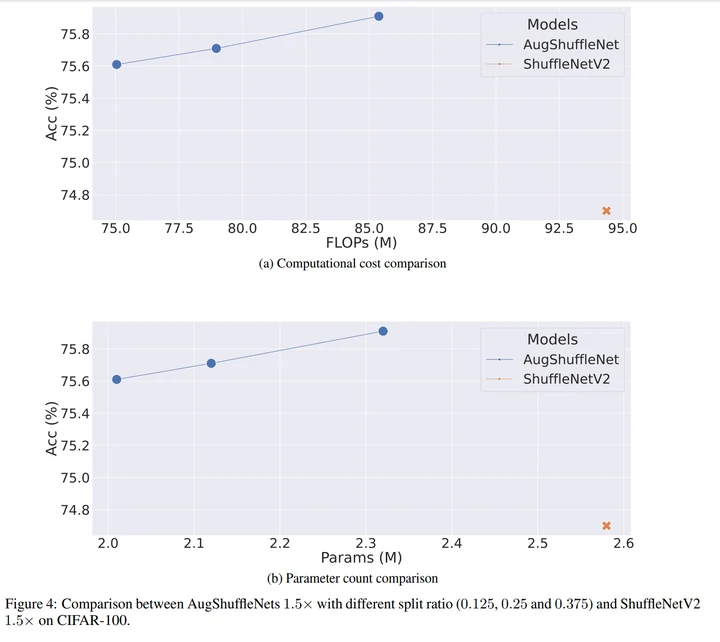
如图8和9所示, 我们基于AugShuffleNet 1.5x 继续降低split ratio和ShuffleNetV2进行比较。这本质是在证明ShuffleNetV2的冗余性。实验设置了0.375, 0.25, 0.125三种slit ratio参数,数值越小,AugShuffleNet就被压缩得越狠 。
可以看到,在通过split ratio压缩模型的情况下,AugShuffleNet的效率和性能优势仍在,这说明ShufffleNetV2 1.5x 确实存在比较多的冗余。
即使在分割率最小为0.125(蓝线最左边那个数据点)的情况下,AugShuffleNet 1.5x cifar10和cifar100上准确率仍能领先ShuffleNetV2 1.5x 0.29%和0.91%。cifar10上,前者的计算量和参数量仅为后者的79.6%和76.7%;cifar100上,前者的计算量和参数量则是后者的79.6%和77.9%。
还没测延时,因为AugShuffleNet 1.5x分割率0.125很低,相对于0.5分割率 的ShuffleNetV2 1.5x,可以改善20多层卷积的计算时间和访存时间,外加10层激活函数的时间。所以可以肯定, AugShuffleNet训练和推理速度会更快。
结论和思考
本文的设计策略很简单,即通过通道分割率 r 调节计算开销和控制冗余,提升模型效率;中间层信息的交换促进了跨层信息的混合,提升模型性能。总的来说,AugShuffleNet 改良的模块可以比 ShuffleNetV2 的 Shuffle Block 更具有优势。
但是这种优势是在特殊的情况下才成立的,即模型规模相对于数据任务一定要达到一定程度的“大”。这种大不是指模型相对于数据集达到了过拟合的那种,而是“大”到模型达到能产生“冗余”和浪费的程度。即使看上去很小的模型也能达到这种冗余程度,这取决于模型规模和数据集规模(或者任务难度)的相对程度。这种相对程度更“大”则 AugShuffleNet 的优势会更加明显,反之优势则不明显,极端情况下优势甚至不存在。
举个例子,我在 imagenet 上实现了 AugShuffleNet 1.0x 和 ShuffleNetV2 1.0x 的比较(由于 batch size 不同,没有 复现好 shuffleNetV2 的准确率,但是不影响推断),由于模型宽度很小,表示能力相对大规模数据集非常有限。AugShuffleNet 只能在分割率为 0.45 的情况下,在推理速度和准确率有一点优势,计算量和参数量则会超出少许(计算量貌似是 5M 以下,参数量也比较少),但是相对于 ShuffleNetV2 的优势就没这么明显了。而且,这种情况下 ShuffleNetV2 自身微调一下宽度和深度也是大概率能改善一点点指标的,毕竟 random seed 的影响是如此之大。
如果增加模型宽度,优势大概率会显现出来。上述观点也能从 cifar10 和 cifar100 的实验中得到支持:
- 网络宽度因子从 1.5, 1.0 和 0.5 依次下降的时候,AugShuffleNet 相对于 ShuffleNetV2 的优势差距在逐渐下降。如果宽度因子继续减少,例如变成 0.125(这个数字不太合理,导致分割通道很难是整数,但是只是用来代表很窄的网络),很有可能就不能保持全面的效率和性能优势了。
- 在网络宽度因子设置为 1.5x 时候,两个网络都足够宽,对 cifar10 和 cifar100 都达到了前面所说的“模型相对数据集足够的大”。split ratio 为 0.125 的时候,可以把 AugShuffleNet 1.5x 的计算开销大幅度压缩,在准确率上却仍然能保持对 ShufflenetV2 的些微优势。由于两个模型架构相同,这也侧面说明 ShuffleNetV2 1.5x 已经产生了冗余,这个冗余来自不合理的结构设计和不灵活的开销控制。
设计原则总结
除了工程trick,本文大概也暗示了一些通用的设计原则(同时适用CPU和GPU上的模型设计):
- 加宽网络(高维度)时,标准卷积的通道全连接结构会容易造成通道冗余,尽可能规避这种情况。
- 鼓励用split ratio灵活控制计算开销和冗余。前一层的输出通道数量等于后一层的输入通道数量,这种规定限制了设计的灵活性。另外尽可能在网络深层(通道数量较多)使用。通道数量很少时,split ratio不但节省不了多少开销,还会伤害模型性能。
- 合理利用跨层信息的混合来提升模型性能。
- 重视残差的访存开销,有两种比较高效率的方案:
- 和ShuffleNtV2一样利用channel split 和shuffle, shuffle可以考虑换成channel shift
- 利用dirac conv, 把残差藏进卷积核中
代码实现
改良的 Shuffle Block 代码如下(代码不太规范,推理速度可能可以继续优化,pytorch 现在自带 channel shuffle 了):
1 | import torch |