VGGFace是牛津大学视觉组于2015年发表,VGGNet也是他们提出的,基于VGGNet的人脸识别,Deep Face Recognition,官网
主要思想
- 目标:构建最少的人为干预大规模人脸数据集,使训练的卷积神经网络进行人脸识别,可以与谷歌和Facebook等互联网巨头竞争。并不是用FaceNet那种端到端系统。
- 人脸分类器:VGGNet+Softmax loss,输出2622个类别概率
- 三元组学习人脸嵌入:VGGNet+Triplet loss,输出1024维的人脸表示
- 在人脸分类器基础上,用目标数据集只fine-tuning学习了映射层
- 人脸验证:通过比较两个人脸嵌入的欧式距离来验证同种人。
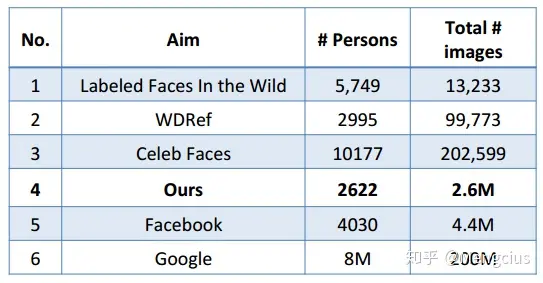
- 构建新的人脸数据集:2622个人,每人1000张,共260万个人脸。
- 在LFW上的准确率为98.95%,YTF上准确率是97.3%
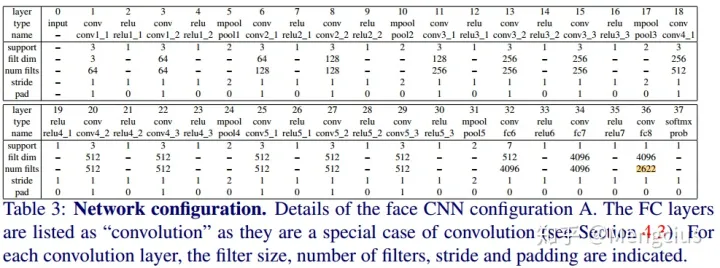
VGGNet网络架构
- 网络比较深,基本和VGGNet一样,又改进了:
- 3x3卷积核,卷积步长为1
- ReLU激活
- 有3个全连接层
- 没有用local contrast normalization

人脸分类器
- 使用如下VGGNet,训练一个n=2622路的Softmax loss人脸分类器。使用随机高斯初始化,随机梯度下降(批量较大时用Accumulator Descent),Batch Size=256
- 学习完成后,去除分类器层(W,b),利用欧氏距离比较得分向量,进行人脸识别验证。
- 然而,我们而是通过使用“三元组损失”训练方案对它们进行调优,以便在欧几里德空间中进行验证,可以显著提高分数,下一节将对此进行说明。为了获得良好的整体性能,必须将网络引导为分类器。
三元组学习人脸嵌入
- 三元组损失训练的目的是学习在最终应用中表现良好的分数向量,即通过比较欧几里德空间中的人脸描述符来验证身份。这在本质上类似于“度量学习(metric learning)”,并且像许多度量学习方法一样,它用于学习同时具有独特性和紧凑性的映射,同时实现降维。
- 在进行验证时,分类器在最后一层FC层输出了2622维的特征(即对应每一类的概率),而这里还会被用来以Triplet loss做一个度量学习。度量学习是一个全连接层,使用目标数据集(如LFW和YTF)的训练集部分训练映射函数W’,获得1024维的人脸特征表达(人脸嵌入)。(基于神经网络的人脸验证)
- 同样的网络输入为大小为224×224的人脸图像,后面前两个FC层的输出是4096维的,最后一个FC层后的输出是N=2622维或L=1024维,这取决于用于优化的损失函数是Softmax还是Triplet loss。
- 注意,与前一节不同的是,这里没有学习到任何偏差,因为三元组损失函数中的差异会抵消它
训练流程如下:
- 将分类器最后输出的4096维特征进行L2归一化,得到
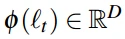
并将其映射到另一空间
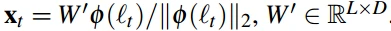
- 通过最小化三元组损失函数训练一个从4096到1024维的映射函数W’,得到一个1024维的人脸嵌入。Triplet loss损失函数如下:
- a≥0是一个表示边界间隔,T是训练三元组的集合,每次迭代开始时在线形成三元组。
- 对目标数据集进行fine-tuning,只学习映射层
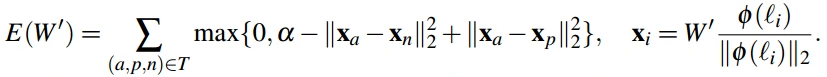
人脸验证
- 通过比较两个1024维人脸特征的欧式距离是否小于阈值来验证身份
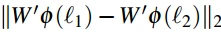
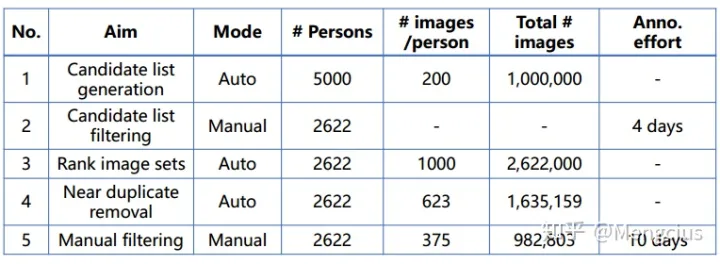
构建数据集
- 先在Freebase和IMDb网站上搜集5000个名人,每人200张图。
- 再手动用谷歌搜索去掉不太受欢迎的名人,去掉与公共基准重叠的人,最终数据集有2622个名人。
- 对图像集排序,每个身份对应2000张图片,通过添加关键字“actor”进行搜索,对2000张图片进行排名,选择前1000张,最终约260万张2622位名人的照片。文中训练用这步的数据,性能最好
- 删除重复的VLAD描述符,2622人,每人623张,总共163万张.
- 最终手动检查数据集,2622人,每人375张,总共98万张。

数据集大小比较:
用第3步整个数据集训练效果比较好,说明使用更大但是有更多错误的数据集对网络能力有提高作用,原因一是因为数据量更大,二是因为小的数据集可能被清除了一些hard positive的数据,使得网络无法从这些数据里受益。
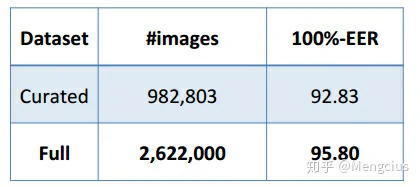
测试结果
LFW上VGGFace用VGGNet的B形式性能最好。等错误率(EER)作为一个评估度量指标,定义为假阳性(TP)和假阴性(FN)率相等的ROC操作点的错误率。
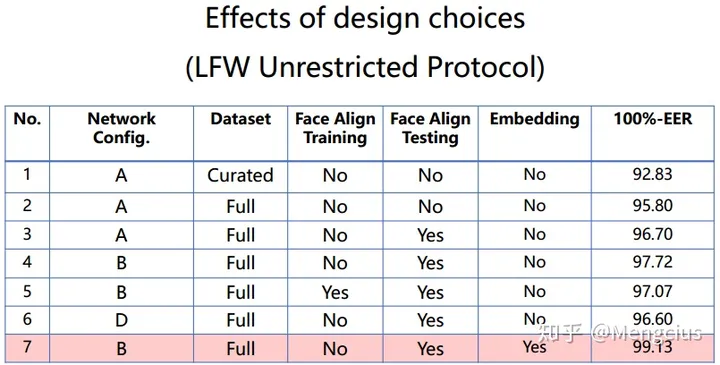
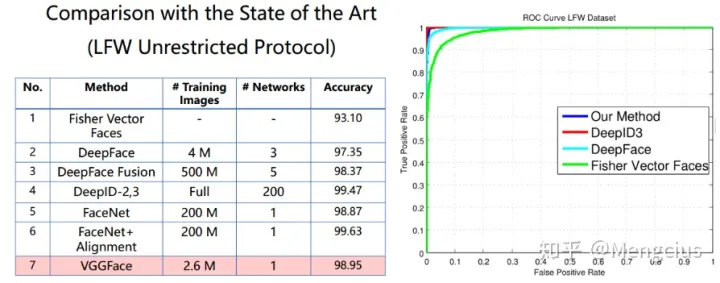
VGGFace使用了较少的数据集在LFW上的准确率为98.95%,和普通版的FaceNet相当,比DeepFace要好,不如DeepID2,3和对齐版的FaceNet。
ROC上比DeepFace要好,和DeepID3相当。
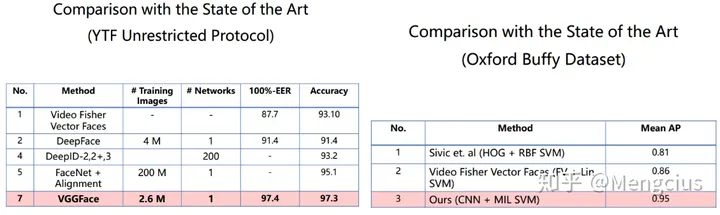
YTF上准确率是97.3%,比他们都要好。给定一对指定的视频,验证是否属于同一个人。
Oxford Buffy Dataset(一种电视剧数据集),探测了正面和侧面,Mean AP达到0.95。
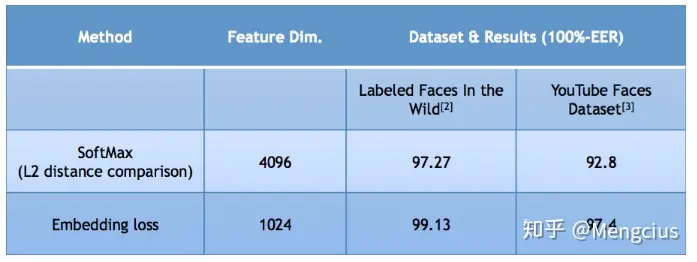
学习的嵌入比分类模型要好:
参考资料
https://zhuanlan.zhihu.com/p/76538698
https://www.robots.ox.ac.uk/~vgg/software/vgg_face/
https://blog.csdn.net/Fire_Light_/article/details/79593778
https://github.com/rcmalli/keras-vggface