DeepID2(Deep IDentification-verification features, 深度身份验证特征)是Yi Sun,Xiaoou Tang等在NIPS 2014.06发表,提出联合识别信号和验证信号的深度学习人脸表示方法,Deep Learning Face Representation by Joint Identification-Verification
主要思想
- 人脸识别的关键挑战是开发有效的特征表示,以减少类内差异,同时扩大类间差异。本文提出通过深度卷积网络并同时使用识别信号和验证信号作为监督来很好地解决。
- 它和DeepID大概框架一样,但CNN loss添加了验证信号。DeepID原本的卷积神经网络用的是softmax loss,也就是识别信号;但在DeepID2中,损失函数上添加了验证信号,两个信号使用加权的方式进行了组合。
- 人脸表示(人脸识别):用CelebFaces+A训练ConvNets
- 识别信号:形成有辨识度的身份特征,160维,增加类间差异,Softmax损失函数(n分类)
- 验证信号:把同一身份提取的DeepID2特征聚到一起来减少类内差异,基于L2范数的损失函数(类似对比损失)
- 关键点检测:SDM算法检测21个点
- 人脸对齐:相似变换全局对齐
- 对齐图片的数据增广:根据全局对齐的人脸和人脸标志点的位置,裁剪了400个patch,每个160维
- 特征提取:一张人脸图用200个ConvNets提取200个patch,最终形成200x2x160维的向量。
- 前向-后向贪心算法:来选择有效和互补的25个patch的DeepID2特征向量(大量patch更准),减少冗余
- 人脸验证:先用PCA将25*160维降维到180维,再用它学习联合贝叶斯模型
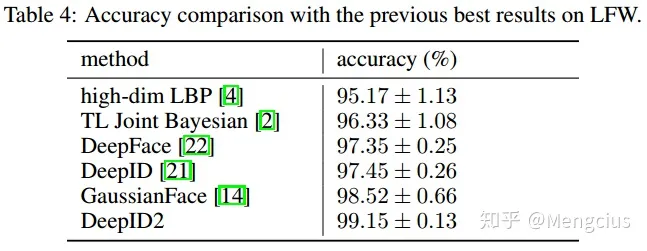
- LWF上99.15%
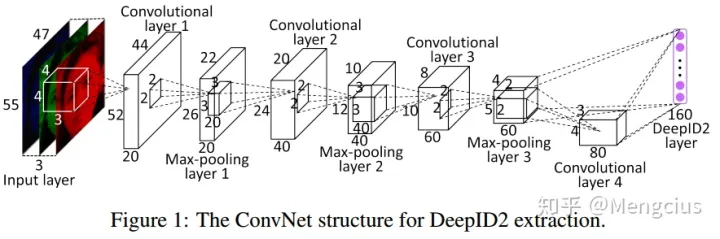
卷积网络结构(特征学习,人脸表示)
- DeepID2的结构与DeepID类似。它包含4个卷积层,在第3和第4卷积层中具有局部权重共享。ConvNet在特征提取级联的最后一层(DeepID2层)提取160维DeepID2特征向量。DeepID2层全连接到第3和第4卷积层。
- DeepID2特征提取过程可表示为f=Conv(x,o),其中Conv(·)是由ConvNet定义的特征提取函数,x是输入人脸块,f是提取的DeepID2特征向量, θ_c表示要学习的ConvNet参数。
两个监督信号用于DeepID2学习特征
人脸识别信号
- face identification signal:其将每个人脸图像分类为n个不同身份中的一个(如n=8192);然后,通过具有n路softmax层的DeepID2层来实现识别,其在n个类别上输出概率分布。
- 为了同时正确地对所有类别进行分类,DeepID2层必须形成有辨识度的身份相关特征,即增大类间差异(inter-personal differences)的特征
- DeepID相当于只有这种识别信号。
- 网络训练目标是最小化交叉熵损失,将其称为identification loss :
- f是DeepID2向量,t是目标类,θ_id表示将softmax层参数,pi是目标概率分布,pi^是预测概率分布
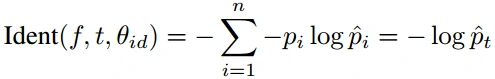
人脸验证信号
- face verification signal:提升相同身份人脸提取的DeepID2特征间的相似性,即减少类内差异(intra-personal variations),它直接正则化了DeepID2特征。
- 采用约束来正则化,常用的约束包括L1/L2范数和余弦相似性。这里采用以下基于L2范数的损失函数,最初由Hadsell等人为降低维度提出来,它和对比损失非常相似。
- fi和fj为两幅人脸特征向量,yij=1表示fi和fj来自相同身份,即最小化了两个向量之间的L2距离;yij−1是不同的身份,两距离需要大于m,θ_ve是用验证损失函数学到的参数。
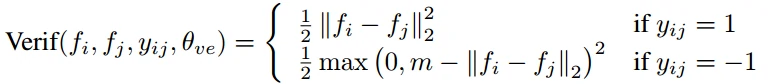
- 另外还有基于L1范数的损失函数、余弦相似度的验证信号等,后面分析,L2是最好的
DeepID2特征学习算法步骤
- 使用两种监督信号来联合训练。identification和verification的梯度由超参数λ加权。
- 训练目标是在特征提取函数Conv(·)中学习参数θ_c,而θ_id和θ_ve仅是在训练期间传播identification和verification信号的参数。参数通过随机梯度下降来更新。
- 在测试阶段,只有θ_c用于特征提取。
- 由于验证信号的计算需要2个样本,之前的CNN是将全部数据切分为小批量来进行训练,现在则是每次迭代时随机抽取2个样本,然后进行训练。

人脸验证
将DeepID2特征嵌入到人脸对齐、特征提取和人脸验证的传统人脸验证流水线中。
- 首先使用当时提出的SDM算法来检测21个人脸标志点。 然后,根据检测到的标志点,通过相似变换全局对齐人脸图像。根据全局对齐的人脸和人脸标志点的位置,裁剪了400个人脸块,其位置、比例、颜色通道和水平翻转都有所不同。(训练的时候不用)
- 用200个ConvNets提取400个特征向量,即每个ConvNet提取的2个特征向量是每个块和水平翻转的,最终形成400x160维的向量。(400个patch中含有水平翻转)
- 为了减少大量DeepID2特征之间的冗余,使用forward-backward greedy algorithm(前向-后向贪心算法)来选择少量有效和互补的DeepID2特征向量(在实验中为25),这可以节省大部分测试期间的特征提取时间。下图显示了用于特征提取的所选定的25个块,从中提取了25个160维(4000)DeepID2特征向量。
- 通过PCA将4000维矢量进一步压缩到180维以进行人脸验证。
- 最后基于DeepID2特征,学习用于人脸验证的联合贝叶斯模型,实现人脸验证。(和DeepID一样)
- 它将人脸的特征表示形式f建模为类内和类外差异的总和 f = µ + ε,µ和ε采用高斯分布模型,并根据训练数据进行估计。
- 通过对数似然比实现人脸检验,其中分子和分母分别为假设类内和类间差异的联合概率。
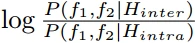
- 使用从每个块中提取特征的联合贝叶斯人脸验证准确度如图所示,可以看到放大的完整的人脸对齐图片准确率最高。

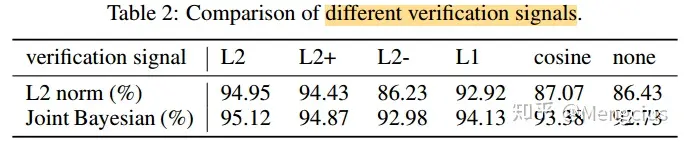
不同验证信号的损失函数比较
- 对不同的验证信号,包括L2、L2+、L2-、L1、余弦验证信号cosine、无验证信号(none)等分别进行了比较,发现L2范数最好。用它们所学到的DeepID2在测试集中的人脸验证精度分别用L2Norm和联合贝叶斯进行测量,识别信号是相同的(对8192个身份进行分类)。
- 只要在识别信号的基础上加入验证信号,人脸的验证精度一般都会提高。而且L2比其他验证信号都好。这可能是因为所有其他的约束条件都比L2弱,并且在减少个人内部变量方面效果也较差。例如,余弦相似性只限制角度,而不限制大小。
- 为了进一步证明验证信号主要起到减小内部差异的作用,我们将所有样本对上的L2范数验证信号,与那些仅约束正或负样本对(分别表示为L2+和L2-)的样本对进行比较。L2+只会减小相同身份的DeepID2之间的距离,而L2-只会增加不同身份间的距离(如果它们小于边界的话)。
- 使用L2+验证信号学习的DeepID2特性只比使用L2学习的稍差。但L2-验证信号对特征学习的帮助很小,几乎与不使用验证信号的结果相同。这就证明了验证信号主要是减少类内差异。
实验数据集
- LFW数据集是在无约束条件下进行人脸验证的事实上的标准测试集。它包含13,233张5749个身份的人脸图像。但它不适合训练,因为LFW中的大多数身份只有一个人脸图像。
- 使用CelebFaces+做训练集,有10,177个名人身份的202,599张人脸图像。把CelebFaces+进行了切分,切分的CelebFaces+A(8192个人)用在DeepID2特征训练,CelebFaces+B(1985个人)用于随后的特征选择和用联合贝叶斯人脸验证模型。在CelebFaces+A上学习DeepID2特征时,CelebFaces+B用作验证集来决定学习率、训练epochs和超参数λ。
- 其次,CelebFaces+B再切分为1485人的训练集和500人的交叉验证集两个部分,用于特征选择,选择25个patch。最后在CelebFaces+B整个数据集上进行联合贝叶斯模型训练。然后使用所选的25个patch的DeepID2特征在LFW上进行测试。
测试结果
使用越来越多的人脸块中提取的DeepID2进行人脸验证的准确性也会越高,但速度会变慢。选择效果25个patches和180维DeepID2特征,在LFW上得到的最终准确率是98.97%,35ms(单颗Titan GPU)。

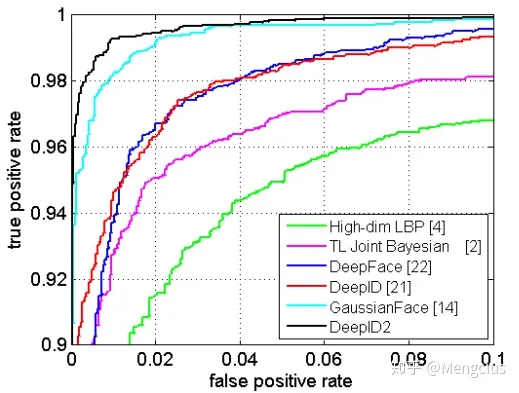
又进一步利用了大量patches的特征,进行了组合模型的加强,即在选取特征时进行了7次,第一次选效果最好的25个patch,第二次从剩余的patch中再选25个,以此类推;然后分别学习了7组特征的联合贝叶斯模型;最后通过进一步学习SVM融合了每对比较人脸的七个联合贝叶斯评分。通过这种方法实现了更高的99.15%的LFW人脸验证精度。LFW的ROC比较中DeepID2也最好。
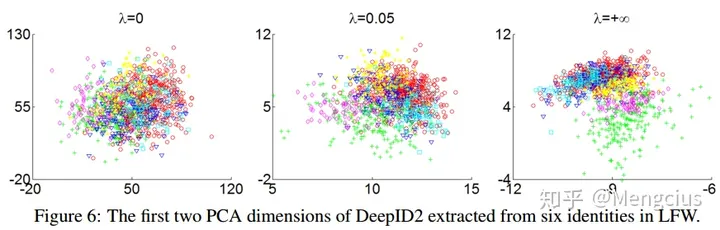
在λ=0.05时,与只用识别信号相比类间方差几乎不变,类内方差下降了很多,此时识别信号和验证信号的平衡最好
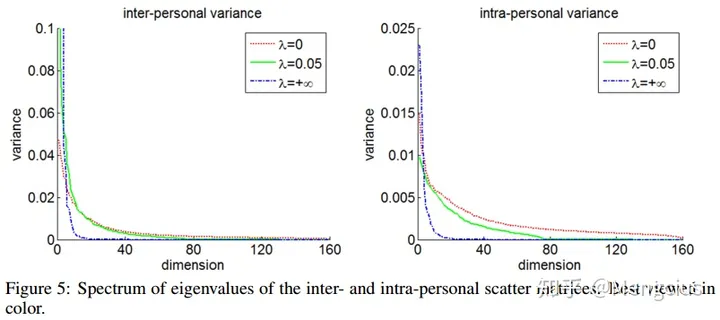
图6显示了前两个主成分分析维度的特性在λ下的变化,这些特征来自六个身份。当λ=0不同集群混合在一起;当λ=0.05类内差异显著降低和集群有了区分;当λ=无穷,虽然内在变化进一步减少,但集群明显重叠很难区分。
参考资料
https://zhuanlan.zhihu.com/p/76534842
https://blog.csdn.net/Fire_Light_/article/details/79559051
https://blog.csdn.net/stdcoutzyx/article/details/41497545