本工作已入选 ICLR 2023 Spotlight,也是 GFlowNets 领域第一篇 Spotlight 文章。
本文介绍关于生成流网络 (Generative Flow Networks) 的一个近期研究工作。在生成流网络 (Generative Flow Networks, GFlowNet) 中,智能体学习一个随机策略进行目标生成,使得生成目标的概率正比于一个奖励函数。然而,GFlowNets 只能依赖于最终状态的奖励信号进行学习,无法考虑中间步骤的奖励,可能对适用性和高效性造成一定的局限。为此,来自 Mila 的图灵奖得主 Yoshua Bengio 教授团队创新得提出了生成拓展流网络,在 GFlowNets 中引入中间奖励信号,以实现更高效的探索和学习。生成拓展流网络在分子生成等任务生展现了巨大的潜力。本工作已入选 ICLR 2023 Spotlight,也是 GFlowNets 领域第一篇 Spotlight 文章。

- 作者:Ling Pan, Dinghuai Zhang, Aaron Courville, Longbo Huang, Yoshua Bengio
- 论文链接:https://openreview.net/pdf?id=urF_CBK5XC0
简介
在生成流网络 (Generative Flow Networks, GFlowNet) 中,智能体学习一个随机策略进行目标生成,使得生成目标的概率正比于一个奖励函数。相比于最大化奖励函数的强化学习方法相比,GFlowNets 在生成高质量且多样性的目标中尤为有效。然而,GFlowNets 只能从最终状态的奖励进行学习,可能会限制其适用性。中间奖励信号在学习中非常重要 —— 例如,可以通过内在激励来产生中间信号使得智能体即使在稀疏奖励的任务中仍然能进行高效的学习。
受此启发,我们提出了生成拓展流网络 (GAFlowNets),创新性得提出了一个新的 GFlowNets 学习框架,将中间奖励信号以拓展流的方式引入其中。并且我们以内在动机作为中间奖励信号以解决稀疏奖励环境中的探索问题。GAFlowNets 以基于边和基于节点的内在奖励联合的方式来提升探索。我们首先在 GridWorld 中进行了广泛的实验,证明了 GAFlowNet 在收敛性、性能和多样性方面的有效性。实验结果进一步表明 GAFlowNet 可以扩展到更复杂和高维的分子生成任务中,并同样带来显著的性能增益。
动机与背景
近年来,深度强化学习取得了重大进展,尤其是在游戏领域。深度强化学习方法通常旨在最大化奖励函数以学习最优策略。然而,生成目标的多样性在广泛的实际场景中是非常重要的,包括分子生成、生物序列设计、推荐系统、 对话系统等。例如,在分子生成中,计算机模拟中使用的奖励函数本身可能不确定且不完善(与更昂贵的体内实验相比)。因此,仅搜索最大化回报的解决方案往往是不足的。因此我们希望对许多具有高奖励的候选结果进行采样,这可以通过以对每个最终状态的回报成比例地对它们进行采样来实现。
图灵奖得主 Yoshua Bengio 教授在 2021 年提出了生成流网络 (Generative Flow Networks, GFlowNets) 以学习一种随机策略来对目标 图片进行采样,其采样概率与奖励函数图片成正比。GFlowNets 的学习范式不同于其他强化学习方法 —— 它明确旨在对目标分布的多样性进行建模。因此,该学习框架对于很多兼顾性能及多样性的实际应用问题非常通用,例如分子生成、生物序列设计等。
然而,GFlowNets 仅能基于最终状态的奖励来学习,而无法考虑中间奖励信号,这会限制其适用性,尤其是在更通用的强化学习问题中。事实上,中间奖励信号在学习中起着至关重要的作用。强化学习的巨大成功也在很大程度上取决于提供了中间反馈的奖励信号。即使在外部奖励信号稀疏的环境中,强化学习智能体也可以通过内在动机激励自己进行有效探索(即每一步在稀疏的外在学习信号上同时考虑密集的内在奖励信号)。
我们在本文中提出了一个新的 GFlowNet 学习框架,该框架能够将中间反馈信号以拓展流的方式考虑在内,以在训练期间提供探索激励。我们首先创新性得提出了基于边的拓展流,在每次状态转移时考虑内在中间奖励。然而,我们发现虽然这种方法提高了学习效率,但是它只进行局部探索,仍然缺乏足够的探索能力。另一方面,我们发现基于节点的拓展流可以进行更广泛的探索,但却可能会导致收敛速度变慢并带来较大的误差。
因此,我们提出了一种联合方法来同时考虑基于边和基于节点的拓展流,同时提升多样性和学习效率。我们在常用的 GridWorld 任务和和分子生成任务中进行了广泛的实验以证实我们提出的框架的有效性。
方法介绍
基于边的拓展流

拓展流语义
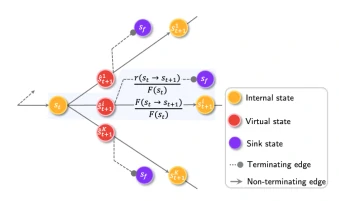
基于边的拓展流可以看作是在每个状态转换步骤中引入一个流向伪终止状态的额外的流r(s_t→s_t+1)

联合拓展流
与基于边的拓展流不同,Yoshua Bengio 教授等人在 2021 年提出可以将轨迹回报定义为基于状态的中间奖励之和,如下公式所示
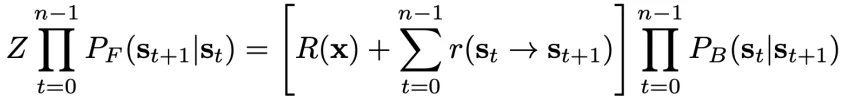
然而,它明确地改变了潜在的目标概率分布,并且会被轨迹长度影响。因此,这会导致收敛速度变慢。
如上所述,基于节点的拓展流在提高多样性方面是非常有效的,但不能有效地适应目标分布。另一方面,基于边的拓展流方式的收敛性更好,但缺乏充分的探索能力,无法挖掘所有可能的 modes。因此,我们在本文中提出了一种联合方法,将基于节点和基于边的拓展流考虑在内,以实现最佳平衡及效果,如下公式所示
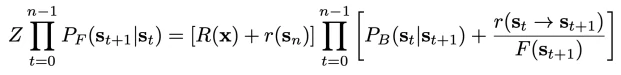
具体来说,我们将轨迹回报重新定义为最终奖励和最终状态的内在奖励之和。另一方面,我们根据基于边的拓展流考虑内部状态的内在奖励。这种联合的方式继承了基于节点和基于边的拓展流的优点,使其在更有效地学习的同时以更全局的方式改进探索。
理论分析
在定理 1 中,我们理论证明我们提出的方式能够渐近地保证解是无偏的。
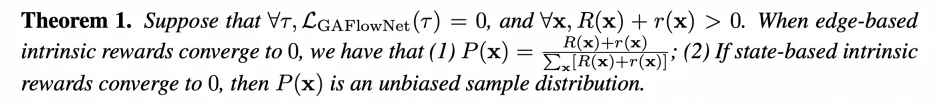
实验
我们进行了充分的实验以分析我们方法的有效性,并研究了以下关键问题:i)GAFlowNet 与以前的基线算法相比效果如何?ii)基于节点和边的拓展流、内在奖励机制的形式和关键超参数的影响是什么?iii)我们的方法可以扩展到更大规模和更复杂的任务吗?
GridWorld
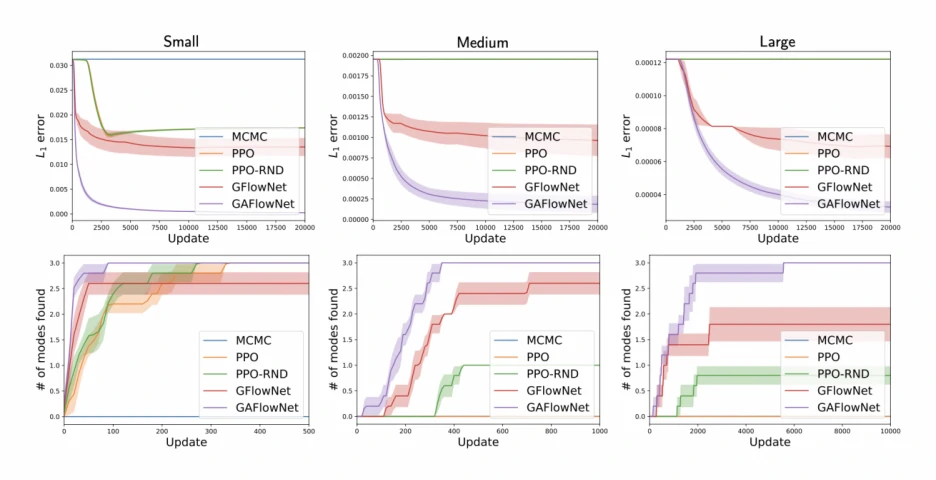
如下图所示,我们的方法(GAFlowNet)在不同规模的 GridWorld 任务中相比于基线算法 GFlowNet, MCMC, PPO 都有显著的提升,包括 L1 误差以及找到的 mode 的个数。
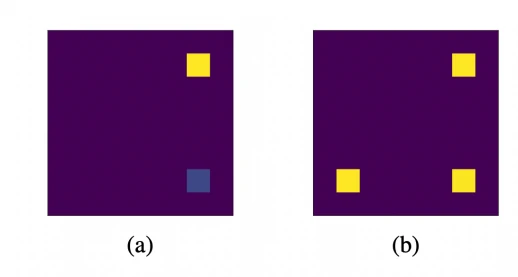
下图展示了我们的方法能够找到该任务的奖励函数中的所有 modes,而原始的 GFlowNet(基于 trajectory balance 的方式)会陷入局部最优。
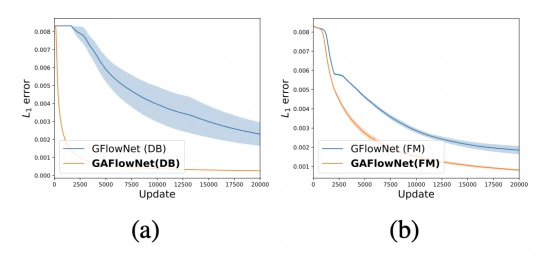
我们提出的方法论是通用的,可以用于不同的 GFlowNet 目标中(包括 Flow Matching 和通用且高效的 Detailed Balance 中)。
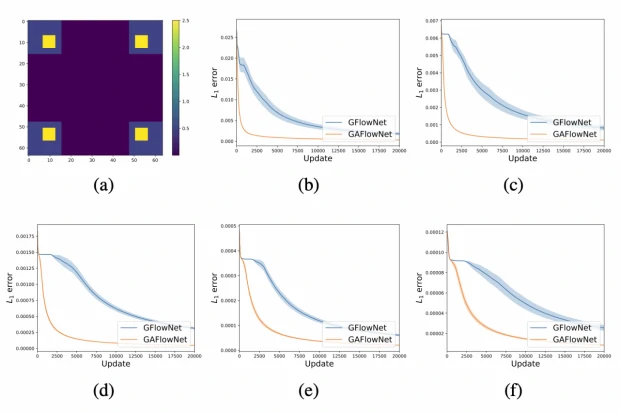
值得注意的是,我们的方法在密集奖励函数的情况下仍然非常有效。
分子生成
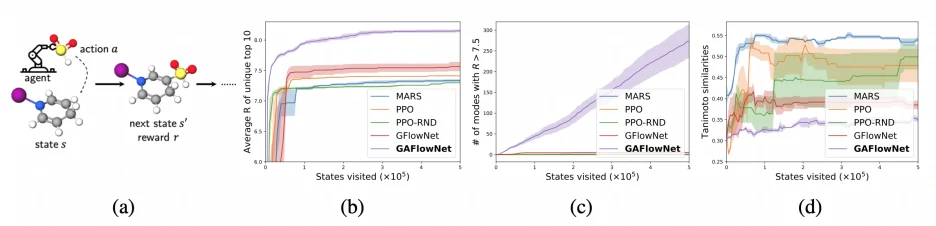
我们考虑了更具有挑战性且更高维的分子生成任务,并在性能和多样性方面研究我们的方法。下图 (b) 展示了每种方法生成的前 10 个分数最高的分子的平均奖励。下图 (c) 总结了每种方法发现的奖励高于 7.5 的模式数量。我们下图 (d) 中对前 10 个样本计算平均 Tanimoto 相似度。
如图所示,MARS 在给定稀疏奖励的情况下表现不佳,因为大多数奖励信号都没有提供有效的信息。另一方面,PPO 相比 MARS 更善于找到更高质量的解决方案,但两者都受到结果高度相似性的影响。GFlowNet 更擅长发现更多样化的分子,但在解决方案质量方面表现不佳。GAFlowNet 在性能和多样性方面明显优于基线方法,并能够有效地生成多样化和高质量的分子,这证明了一致且显着的性能改进。
总结
在本文中,我们提出了一个新的学习框架 GAFlowNet,在 GFlowNet 中纳入中间奖励信号。我们通过内在动机指定中间奖励,以解决 GFlowNets 的高效探索及学习问题。我们进行了广泛的实验来评估 GAFlowNets 的有效性,它在多样性、收敛性和性能方面明显优于基线算法,并可以扩展到分子生成等复杂任务。
参考资料
https://mp.weixin.qq.com/s?__biz=MjM5MzU2NzM5MA==&mid=2649674905&idx=1&sn=341e468514c44531bbadd19effd1e610
[1] Bengio, E., Jain, M., Korablyov, M., Precup, D., & Bengio, Y. (2021). Flow network based generative models for non-iterative diverse candidate generation. NeurIPS 2021.
[2] Bengio, Y., Lahlou, S., Deleu, T., Hu, E. J., Tiwari, M., & Bengio, E. (2021). GFlowNet foundations. arXiv preprint arXiv:2111.09266.
[3] Pan, L., Zhang, D., Courville, A., Huang, L., & Bengio, Y. (2023). Generative Augmented Flow Networks. ICLR 2023.
[4] Pan, L., Malkin, N., Zhang, D., & Bengio, Y. (2023). Better training of gflownets with local credit and incomplete trajectories. ICML 2023.