FaceNet
FaceNet 是一种通用于人脸识别和聚类的嵌入方法,该方法使用深度卷积网络,其最重要的部分在于整个系统的端到端学习。
简介
FaceNet使用深度卷积网络进行人脸识别,该方法中最重要的部分在于整个系统的端到端学习。为此,论文中采用三元组损失(Triplet Loss)/三重损失,直接反映了作者想要在面部验证,识别和聚类中实现的目标。即,他们努力嵌入能够从图像x映射到特征空间R^d的f(x)。使得相同身份的所有面部之间的平方距离(与成像条件无关)很小,而来自不同身份的一对面部图像之间的平方距离很大。
三元组损失的思想也很简单,输入是三张图片(Triplet),分别为 固定影像 A(Anchor Face),反例图像 N(Negative Face )和 正例图像 P(Positive Face)。A与 P为同一人,与 N 为不同人。那么 Triplet Loss 的损失即可表示为:
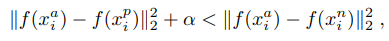
也就是说,我们要让同一个人的图片更加相互接近,而不同人的照片要互相远离。三重损失将固定影像 A 与正例 P 之间的距离最小化了,这两者具有同样的身份,同时将固定影像 A 与反例 N 之间的距离最大化了。如下图所示:
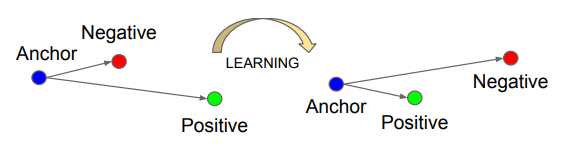
这里的问题是,模型可能学习给不同的图片做出相同的编码,这意味着距离会成为 0,不幸的是,这仍然满足三重损失函数。因为这个原因,需要加入了边际α(一个超参数)来避免这种情况的发生。让 d(A,P) 与 d(N,P) 之间总存在一个差距,这即是我们在上式所看到的\alpha。
除此之外,只要对深度神经网络有一定了解就能够很快的了解Facenet的结构,该网络由批量输入层和深度CNN组成,然后进行L2归一化,从而实现面部数据嵌入。如下图所示:

接下来是训练期间的三联体损失。
(描述来源:单样本学习:使用孪生神经网络进行人脸识别|机器之心)
(图片及描述来源:Schroff, F.; Kalenichenko, D.; Philbin, J. (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv:1503.03832v3)
发展历史
人脸识别问题宏观上分为两类:1. 人脸验证(又叫人脸比对)2. 人脸识别。人脸验证做的是 1 比 1 的比对,即判断两张图片里的人是否为同一人;人脸识别做的是 1 比 N 的比对,即判断系统当前见到的人,为事先见过的众多人中的哪一个。
两者在早期(2012年~2015年)是通过不同的算法框架来实现的,想同时拥有人脸验证和人脸识别系统,需要分开训练两个神经网络。而 2015 年 Google 的 FaceNet 论文的发表改变了这一现状,将两者统一到一个框架里。
DeepID2 在 14 年是人脸领域非常有影响力的工作,也掀起了在人脸领域引进 Metric Learning 的浪潮。“特征”在这篇文章中被称为“DeepID Vector”。
DeepID2 在同一个网络同时训练 Verification 和 Classification(即有两个监督信号)。其中 Verification Loss 便在特征层引入了 Contrastive Loss。Contrastive Loss 本质上是使同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值 m(听起来和 Triplet Loss 很像)。
15 年,Google 提出了FaceNet,同样是人脸识别领域的分水岭性工作。不仅仅因为他们成功应用了 Triplet Loss 在 benchmark 上取得 state-of-the-art 的结果,更因为他们提出了一个绝大部分人脸问题的统一解决框架,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。
为此,Google 在 DeepID2 的基础上,抛弃了分类层即 Classification Loss,将 Contrastive Loss 改进为 Triplet Loss,只为了一个目的:学到更好的 feature。
同年,Parkhi, O. M.等人提出了Deep Face Recognition,为了加速 Triplet Loss 的训练,这篇文章先用传统的 softmax 训练人脸识别模型,因为 Classficiation 信号的强监督特性,模型会很快拟合(通常小于 2 天,快的话几个小时)。之后移除顶层的 Classificiation Layer,用 Triplet Loss 对模型进行特征层 finetune,取得了不错的效果。
2017年,A. Hermans, L. Beyer, and B. Leibe发表了文章,提出了 Soft-Margin 损失公式替代原始的 Triplet Loss 表达式,并引进了 Batch Hard Sampling。在此基础上,Wu, C. Manmatha, R. Smola, A. J. and Krahenb uhl发表论文,从导函数角度解释了为什么 Non-squared Distance 比 Squared-distance 好,并在这个 insight 基础上提出了 Margin Based Loss。此外,他们还提出了 Distance Weighted Sampling。文章认为 FaceNet 中的 Semi-hard Sampling,Deep Face Recognition 中的 Random Hard 和 上文提到的 Batch Hard 都不能轻易取到会产生大梯度(大 loss,即对模型训练有帮助的 triplets),然后从统计学的视角使用了 Distance Weighted Sampling Method。
2018年,Pavel Korshunov 和 Sebastien Marcel使用基于 GAN 的开源软件创建 Deepfakes,并强调训练和混合参数可极大影响视频的质量。为了检测人脸识别系统能否检测出 DeepFakes 视频,研究者评估了两个顶尖的系统(基于 VGG 和 Facenet 的神经网络)在原始视频和换脸后视频上的性能。为此,研究者使用不同的参数生成了低视觉质量和高视觉质量的视频(每类包含 320 个视频)。研究表明当前最优的基于 VGG 和 Facenet 神经网络的人脸识别系统无法抵御 Deepfakes 视频的「攻击」,这两个模型在高质量视频上的误识率(FAR)分别为 85.62% 和 95.00%,这表明开发检测 Deepfakes 视频方法的必要性。考虑了多个基线方法之后,该研究发现基于音画不同步的视听方法无法分辨 Deepfakes 视频。性能最好的方法基于视觉质量度量,通常用于 presentation attack 检测领域,该方法在高质量 Deepfakes 视频上的错误率(EER)为 8.97%。
主要事件
| 年份 | 事件 | 相关论文/Reference |
|---|---|---|
| 2014 | DeepID2基于深度学习的人脸识别领域是最先应用 Metric Learning 思想的模型之一 | Sun, Y.; Wang, X.; Tang, X. (2014). Deep learning face representation by joint identification-verification. CoRR. |
| 2015 | Google 提出了FaceNet,同样是人脸识别领域的分水岭性工作 | Schroff, F.; Kalenichenko, D.; Philbin, J. (2015). FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv:1503.03832v3 |
| 2015 | Parkhi, O. M.等人提出了Deep Face Recognition | Parkhi, O. M.; Vedaldi, A. and Zisserman, A. (2015). Deep face recognition. BMVC. |
| 2017 | A. Hermans, L. Beyer, and B. Leibe发表了文章,提出了 Soft-Margin 损失公式替代原始的 Triplet Loss 表达式,并引进了引进了 Batch Hard Sampling | Hermans, A.; Beyer, L.; Leibe, B. (2017). In defense of the triplet loss for person re-identification. arXiv:1703.07737. |
| 2017 | Wu, C. Manmatha, R. Smola, A. J. and Krahenb uhl发表论文,从导函数角度解释了为什么 Non-squared Distance 比 Squared-distance 好,并在这个 insight 基础上提出了 Margin Based Loss | Wu, C.; Manmatha, R; Smola, A. J.; Krahenbuhl, P. (2017). Sampling matters in deep embedding learning. arXiv:1706.07567. |
| 2018 | Pavel Korshunov 和 Sebastien Marcel使用基于 GAN 的开源软件创建 Deepfakes,并强调训练和混合参数可极大影响生成视频的质量 | Korshunov, P.; Marcel, S.(2018). DeepFakes: a New Threat to Face Recognition? Assessment and Detection. arXiv:1812.08685v1 |
发展分析
瓶颈
- 模型的拟合时间非常长。 Triplet Loss 的训练样本都基于 triplet 的,可能的样本数是 O (N3) 的。当训练集很大时,基本不可能遍历到所有可能的样本(或能提供足够梯度额的样本),所以一般来说需要很长时间拟合。
- 模型好坏很依赖训练数据的 Sample 方式,理想的 Sample 方式不仅能提升算法最后的性能,更能略微加快训练速度。
未来发展方向
对triplet loss函数进行改进或对sampling方式进行改进,如Wu, C.等人提出的Margin Based Loss和Distance Weighted Sampling。
参考资料
https://www.jiqizhixin.com/graph/technologies/cd523caf-c196-4418-b561-c1f7e3e3bc61
Contributor: Yuanyuan Li