- CS231n - Image Classification
cs231n课程指引
- 作业1:KNN;线性分类器,SVM、Softmax;两层神经网络;图像特征
- Python + Numpy教程:http://cs231n.github.io/python-numpy-tutorial/
- Google Cloud教程:http://cs231n.github.io/gce-tutorial/
图像分类–CV核心问题
- 分类识别,种类太多,{狗,猫,飞机……}
- 数据量太庞大,1080p = 1920 * 1080 * 3 *(255,8bit)
- 挑战:观测点变化;光照&明暗;变形和姿势;隐藏&遮挡;背景&分辨;种类种族。
- 图像分类器,没有图示的分类器能够解决这个问题。
- 特征提取,通过提取猫耳朵的形状特征来分类
- 数据驱动方法:(1)收集数据和标签;(2)使用ML训练分类器;(3)在新图像上进行测试评估性能

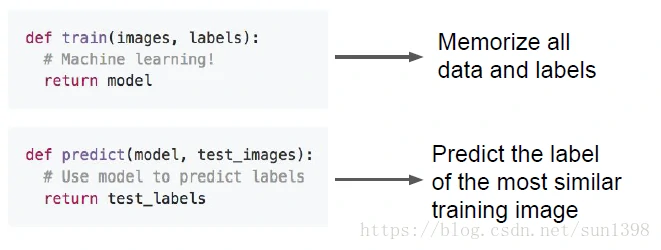
分类器1:最近邻算法–KNN
- 算法的流程:train function 用来记录所有数据及标签;predict寻找最相似训练图片的标签
- 数据集:采用CIFAR10,10类问题,50000张带标签训练图片,10000张带标签测试图片
- 使用距离度量来衡量图片相似度
- 曼哈特距离,L1范数
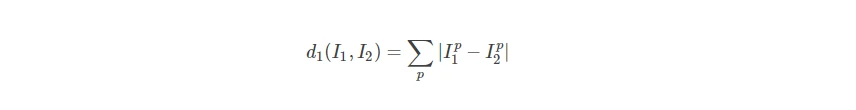
- 欧式距离,L2范数
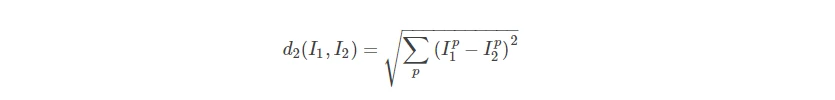
- L1与L2的比较:http://vision.stanford.edu/teaching/cs231n-demos/knn/
- 曼哈特距离,L1范数
- 存在的问题1,训练时间O(1),预测时间O(n)。训练数据集越大,预测时间越长。
- 存在的问题2:容易出现过拟合情况,如下图:
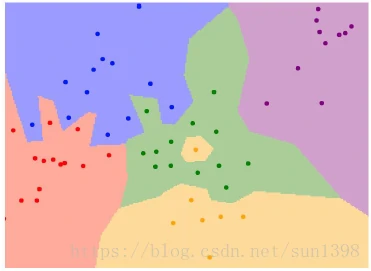
- 优化的NN算法–KNN:预测时选择距离最近的K个标签,选择出现最多的标签。在作业中使用np.bicount快速查找。

- hyperparameters 超参数调试
- 遍历k值和距离度量——选择合适的超参数
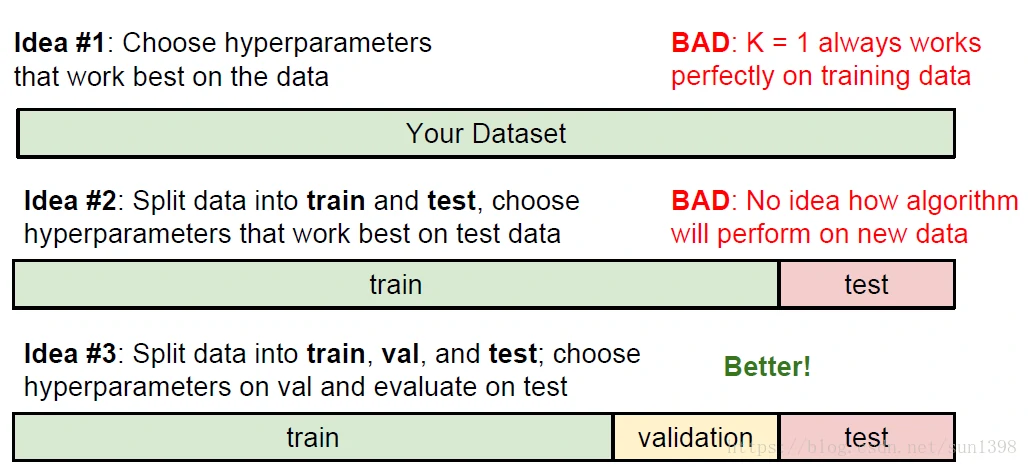
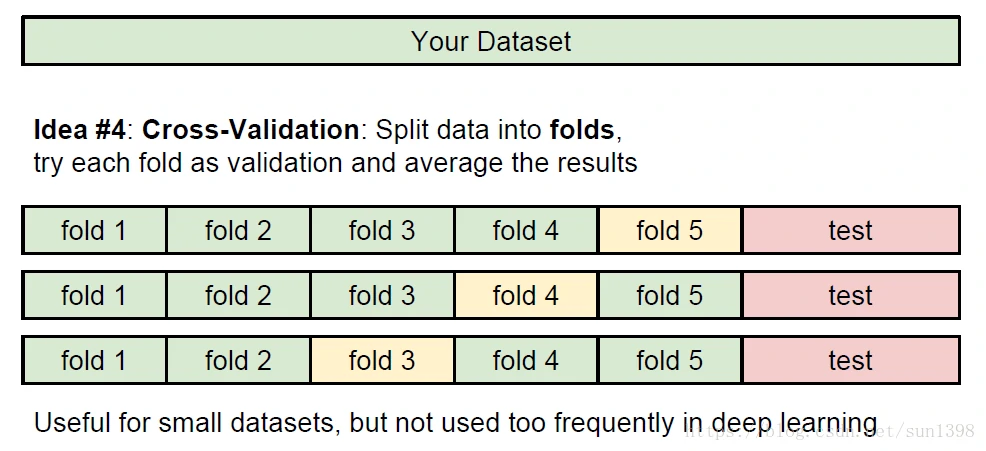
- 合理划分数据集进行超参数调试:交叉验证,将数据集划分N段,选择一段作为验证,其他作为训练集,取多段均值及均方根,寻找最合适参数
- 可能的想法:
- 交叉验证法:
- KNN的缺陷:
- 测试速度太慢,尤其是训练集比较大的时候
- 像素距离度量不是有益的:加BOX;平移;改变色彩还能保持距离一样
- 维数灾难,多维距离受多参数影响,距离结果易混淆,准确率下降。
KNN总结:
- 图像分类使用带标签的训练集开始,在测试集中预测可能的标签
- KNN算法预测标签依赖最近的K个训练样本
- K值和距离度量方法属于超参数-hyperparameters
- 使用交叉验证分段式来调试超参数,测试集只用来最后的评估
- KNN的使用需要选择合适的环境,限制较大
分类器2:线性分类器
- 神经网络就像搭积木,线性分类器就是积木的每一层
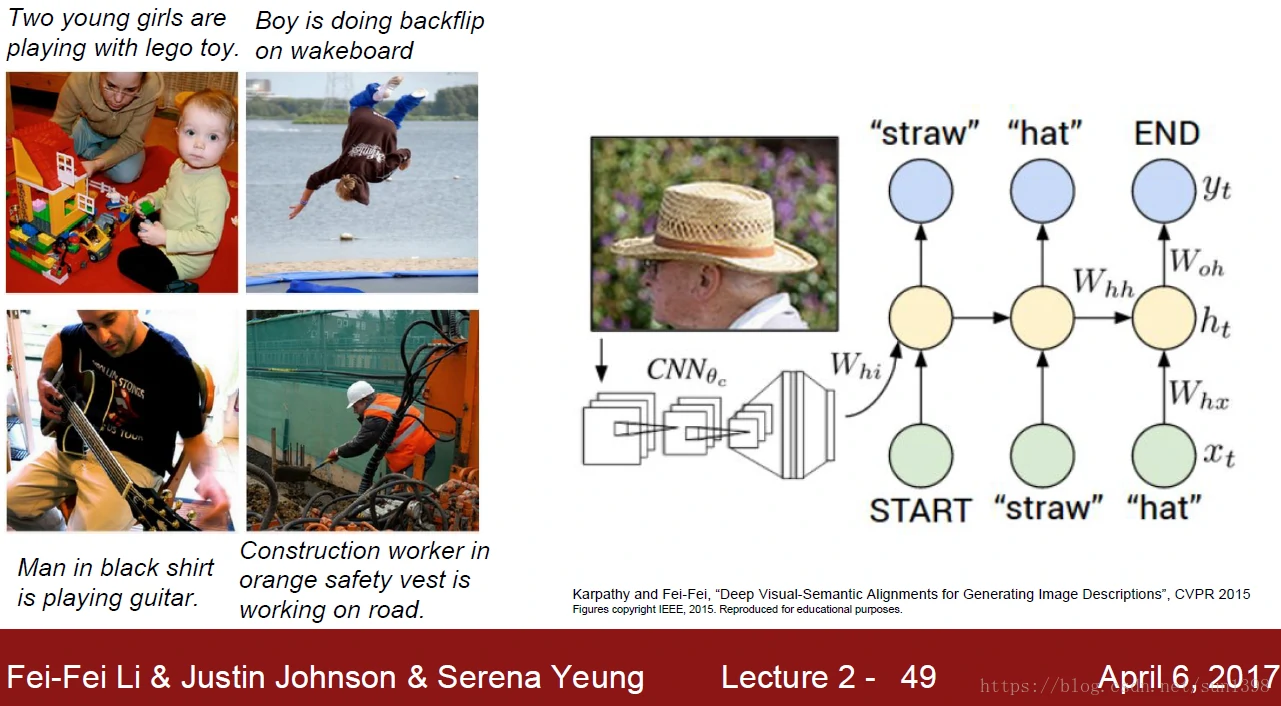
- 图像的内容识别及描述使用的结构是CNN+RNN,如下图:
- 线性分类器通过对图像与标签进行映射 f(x,W) = W ∗ x + b,通过训练使得参数逼近真实模型,如下图讲解
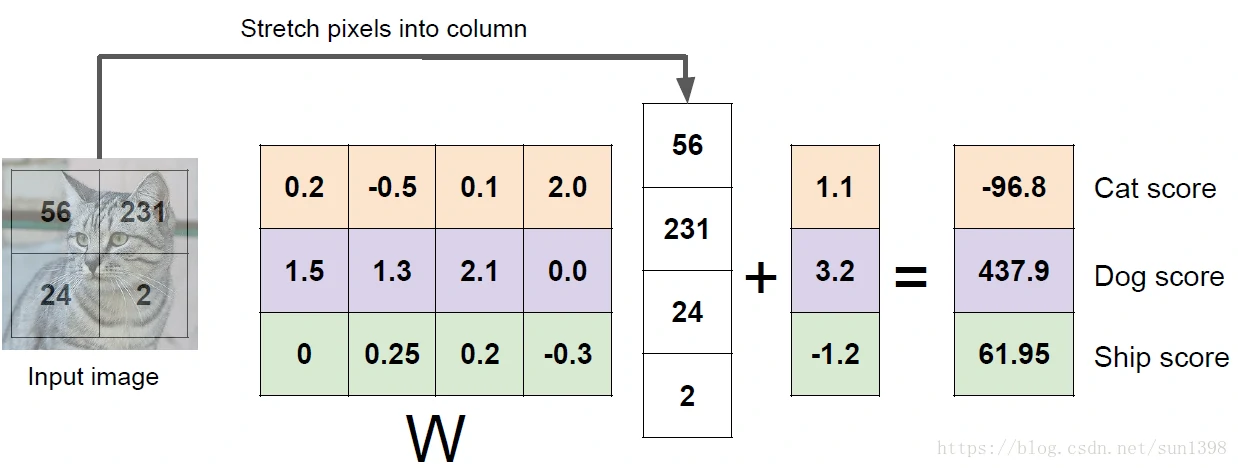
- 线性分类器的最终训练参数W,显示为图片格式如下,隐约可以看出图像的轮廓,个人理解:滤波作用:

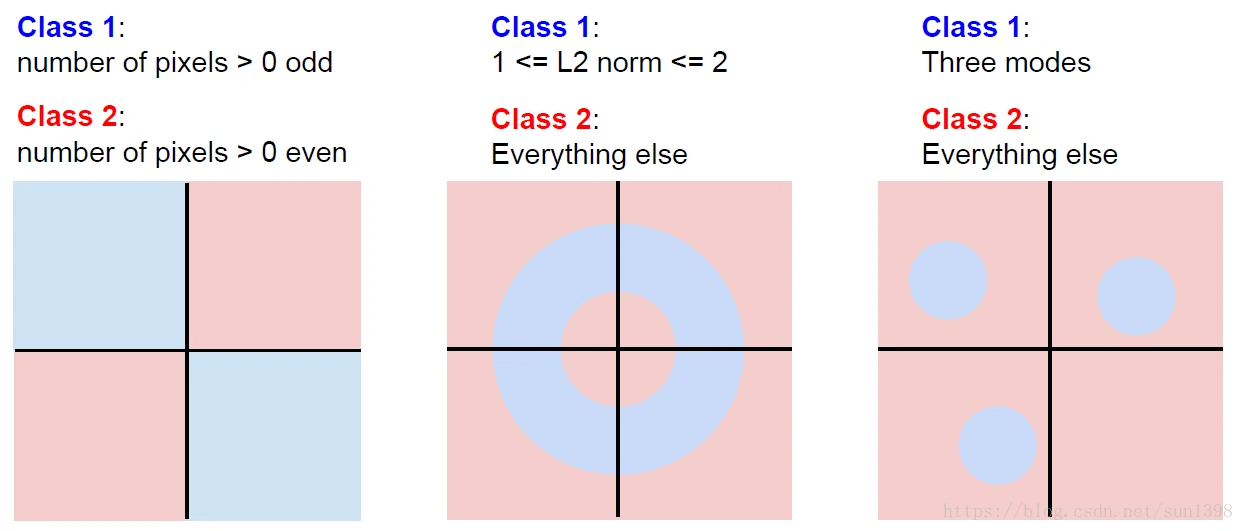
- 线性分类器相当于在M唯空间中使用超平面来分割不同的类
- 当出现以下情况时,线性分类器将降低效果:类处于相同空间;类所有空间都存在,不具备线性。
- 线性分类器f(x,W)=W∗x+bf(x,W)=W∗x+b的工作原理:
- 相当于在每一个图像的每一个类都给了一个得分系统,计算出对应的值,但是值得准确率与实际可能存在偏差,衡量不准确
- 根据平分系统计算损失函数,通过损失函数下降的梯度计算参数的偏导,更新W和b参数
- 重复计算更新,不断降低损失函数,逼近最佳模型,使用最佳模型进行计算,提高准确率