论文概要
基于脑电信号(EEG)的情绪分类是健康大数据的重要组成部分。在这方面的主要挑战之一是不同的被试之间的脑电数据不适应的问题。域自适应是减少源域和目标域之间数据差异的有效方法。这篇论文研究通过对抗域适应的方法,通过一个鉴别器将一个小样本的目标域数据转换到源域,从而在用源域数据训练的分类器上快速适应目标域数据。在本研究中,提出了一种新的方法称为“少标签对抗域自适应”(FLADA)的跨被试的情绪分类。为了评估所提出的方法的性能,在公共数据集DEAP数据集进行测试。结果发现,在少量的目标数据下,所提出的FLADA模型在准确性方面优于现有的方法。
厦门大学信息学院的Yingdong Wang为此文第一作者。厦门大学信息学院的Chen Wang为此文的通讯作者。
该论文已被Expert Systems With Applications(中科院一区,IF=8.5)接收,题目为《Cross-subject EEG emotion classification based on few-label adversarial domain adaption》

研究背景
基于脑电图(EEG)的情感识别在许多领域中是一个重要问题,例如在脑机接口(BCI)方面,它促进了人机交互。研究表明:与面部情绪相比,EEG是一种更真实的情绪检测方式。在医学领域,情绪识别有助于诊断和治疗各种精神疾病,例如自闭症和抑郁症。此外,情绪评估有助于医生和专家监测患者的恢复过程。长期的情绪记录和分析有助于人们更好地了解自己的情绪状态,并及时做出必要的调整。
然而,跨主体脑电情感识别仍存在一些问题。这些挑战主要源于EEG的个体差异和非平稳特征。因此,对新的个体的脑电进行情感分类面临着许多问题。在这方面,最常见的处理方法是收集新的个体的大量的EEG数据。但是脑电数据的采集通常需要专业设备和环境,且对被试者的准备和监测过程有较高要求,这导致收集过程成本较高。
这项论文重点研究了多源主题和目标主题数据有限的领域自适应方法。该方法可以在较短的时间内用少量的脑电数据训练出脑电情感分类模型,是一种适合于实际应用的方案。这项研究的思路是在每个源域模型上测试目的域数据,然后寻找和目的域数据相似的源域数据,通过对抗域适应的方法构建数据迁移的映射方法从,而在用源域数据训练的分类器上快速适应目标域数据。
方法与结果分析
脑电情绪特征
作者采用了微分熵(Differential Entropy)作为情绪分类的指标。EEG信号是一种非常复杂的连续数据,它反映了大脑的电活动。微分熵可以作为一种特征提取工具,用来量化EEG信号的复杂度或不确定性,这些特征可以反映出大脑在不同情绪状态下的活动模式。微分熵是用于连续随机变量的信息量的度量,与离散随机变量的熵(香农熵)相对应。它衡量的是随机变量分布的不确定性或复杂度。这项研究采用微分熵作为情绪分类的特征。微分熵的数学表示如下:
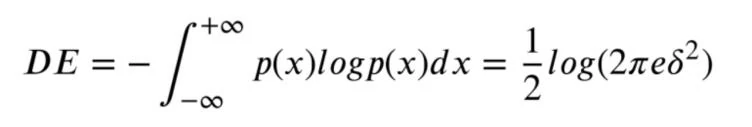
算法模型
本篇论文提出的对抗域适应模型如图1所示:
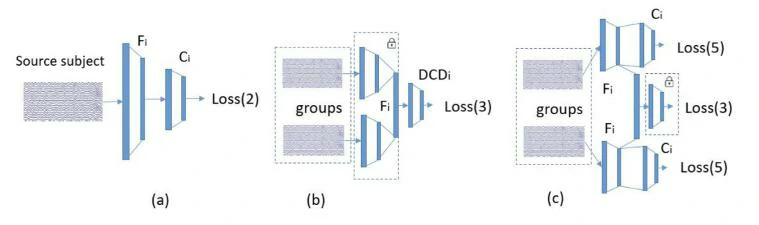
所提出的模型主要分为三个步骤:
(a)用源域数据训练一个特征提取器Fi和分类器Ci。这个阶段首先将源域数据放入特征提取器中,计算高阶特征。然后将提取到的高阶特征放入分类器中进行分类训练,分类器给出分类预测,通过对比分类预测和源域数据的真实标签,计算损失并反向传播。
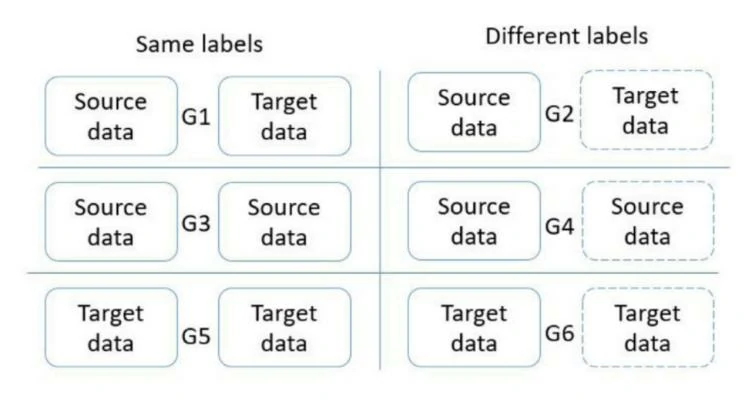
(b)用上一步中训练的特征提取器对源域和目的域数据进行特征提取,将得到的源域高阶特征和目的域高阶特征组成样本对,根据样本对的标签(相同或不同)和来源(源域或目的域)将样本对分为6组(具体分组方式图2所示),用样本对训练鉴别器DCDi。
(c)最后进行联合训练:首先冻结鉴别器,将源域数据和目的域数据放入特征提取器提取高阶特征,然后将高阶特征组成样本对,同时将提取到的高阶特征放入分类器中执行分类训练和将样本对放入鉴别器中执行分组训练,冻结鉴别器的意思是得到的损失函数不再传给鉴别器。然后是冻结特征提取器和分类器,训练鉴别器,流程和刚刚一样,区别是损失函数不再传给特征提取器和分类器,而是传给鉴别器。
试验结果
本论文使用DEAP作为试验数据集,DEAP是一个用于情绪分析的广泛使用的公共数据集。专为分析情绪状态下的脑电图(EEG)而设计。DEAP数据集包含了多名参与者在观看音乐视频时的生理反应数据。这些音乐视频被选中是因为它们能够激发不同类型的情绪反应。在看完视频后,参与者需要对他们所观看的视频进行评分,如愉悦度、激活度、优势度等,这为数据提供了情绪标签。在DEAP数据集上对模型进行测试,结果如表1所示:
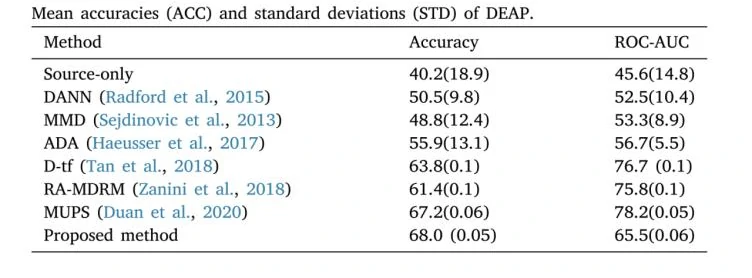
Source-only是由源域数据训练的然后直接用目的域数据测试的。所获得的分类准确率和其他方法相比低至少10%。DANN、MMD和ADA采用零样本对抗域自适应方法(zero-shot-adversarial domain adaption),该方法不需要任何标记的目标数据。它们通过对抗性网络提取共同特征,但相应的准确率相对较低。这可能是由于在这种方法中要考虑的因素太多。D-tf和RA-MDRM方法中使用了迁移学习。D-tf方法主要集中在变换网络的设计,而RA-MDRM集中在通过空间协方差矩阵的EEG信号表示的数据。这两种方法都利用了基于黎曼几何的对称正定矩阵的流形,这两种方法都提高了脑电情感分类的准确率。然而这些方法不能充分利用所有数据。MUPS使用模型无关的元学习方法,以找到最合适的模型来快速适应新数据。但是MUPS方法需要大量的任务来学习模型。本研究充分利用了源域数据和目的域数据之间的共同特征,达到了最高的准确率。
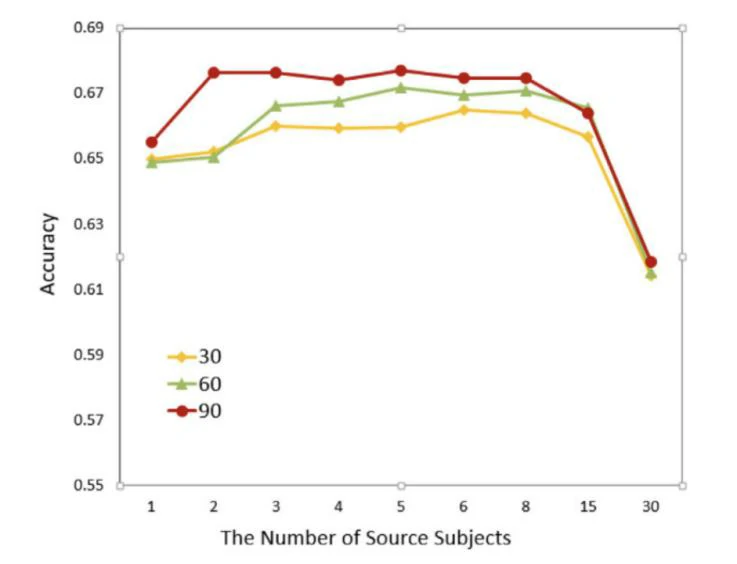
最后,本篇论文还对源域数据的个体数对于域适应的影响做了研究,研究表明,过多的源域并不会提升模型的分类性能,相反,还会导致模型性能下降。目的域和一些源域之间存在弱相关性,盲目增加源于并不能提高准确性,并且会提升计算负担。
结论
这项研究提出了一种少样本的对抗域适应模型。包括三个步骤:1.用源域数据构建特征提取器和分类器2.将源域数据和目的域数据组成样本对,训练鉴别器3.特征提取器、分类器和鉴别器联合训练。核心思想是在源域和目的域之间学习普适的特征,从而在源域上快速适应目的域。实验结果表明,这项研究的方法相较于现有方法具有更好的分类结果。并且训练时间显着减少。
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=14919