2017 年,Google 机器翻译团队发表的《Attention is All You Need》完全抛弃了RNN和CNN等网络结构,而仅仅采用注意力机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了人们研究的热点。受到Transformer强大的特征表示能力的启发,研究人员提议将Transformer应用到计算机视觉任务。与其他网络类型(例如CNN和RNN)相比,基于Transformer的模型在各种视觉基准数据集上显示出可与CNN进行竞争甚至在某些领域表现出更好的性能。本次学习报告基于Transformer最开始提出的论文《Attention Is All You Need》对Transformer的模型以及注意力机制进行学习。

研究背景与意义
RNN,LSTM以及gated RNN在序列模型中已经得到了广泛的应用,例如语言建模、机器翻译等等。目前,依旧有大量的工作在致力于循环语言模型和编码器-解码器结构。
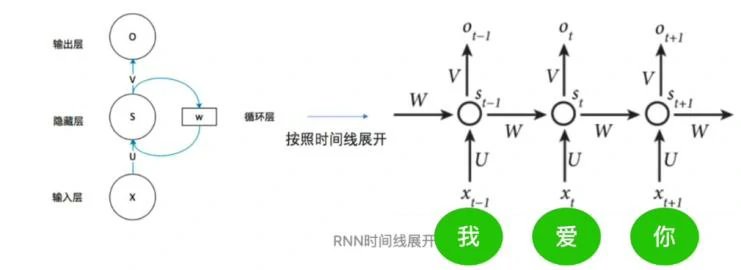
循环模型通常按照输入输出序列的位置顺序进行计算的。在整个计算过程,会生成一个隐含状态的序列。当step=t时,隐含状态输出St是由上一时刻隐含状态输出St-1和当前输入Xt得到的。这种隐藏态的顺序性限制了训练样本的处理不能并行化训练。因为内存的约束限制了批处理样本的长度,长度较长的序列无法通过循环模型的方法进行训练。尽管一些工作通过因式分解(factorization tricks)和条件计算(conditional computation)的技巧显著地提高了计算的效率和模型的性能,但是序列计算的主要约束依旧没有解决。
注意力机制已经成为众多序列建模和转导模型任务中的一个重要组成部分,它可以在不考虑输入或输出序列的距离情况下对依赖进行建模。然而,目前大部分的注意力机制也仅仅被用于RNN之间的链接。
针对RNN远距离信息丢失问题,谷歌提出了Transformer模型。该模型替代了传统的RNN,其仅利用注意力机制就学习到输入和输出序列的全局依赖。Transformer允许并行化,并且在翻译任务上达到了较好的效果与较高的效率。
自注意力机制(self-attention),有时被称为内部注意力机制(intra-attention),是一种仅仅关注单个序列内部不同位置信息并计算序列的表示的注意机制。自注意力机制目前已经成功地应用于各种各样的任务,包括阅读理解,摘要总结,文本的暗含和学习任务独立的句子表示等等。
Transformer是第一个完全依靠自注意力机制来计算输入和输出表示的转换模型,它完全没有使用顺序对齐的RNNs或卷积神经网络。
论文模型
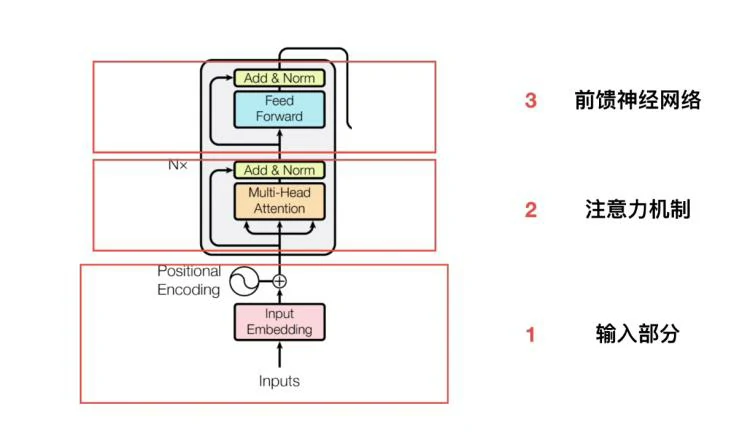
绝大部分的序列处理模型都采用encoder-decoder结构,其中encoder将输入序列(x1,x2 , …, xn)映射到连续表示(z1,z2,…,zn) ,然后decoder生成一个输出序列 (y1,y2,…,yn),每个时刻输出一个结果。Transformer模型延续了这个模型,整体架构如下图3所示。模型主要包括两部分,左半部分为编码器(Encoder),右半部分为解码器(Decoder),编码器和解码器都使用了堆叠的自注意层和点式的、完全连接的层。
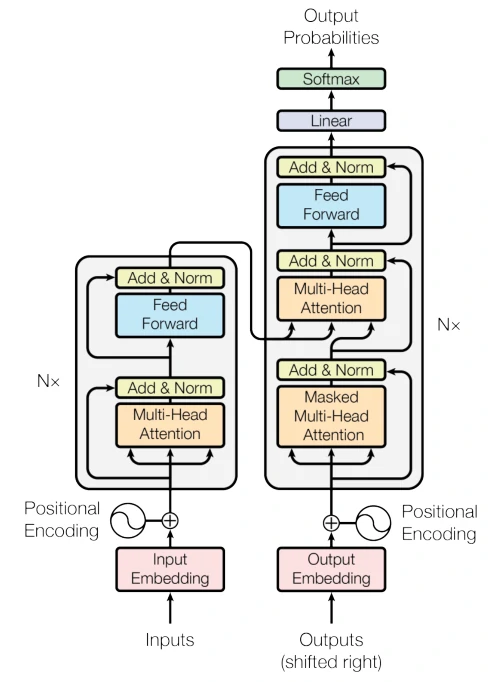
编码器和解码器
编码器:编码器在论文中有六层。每一层由两部分组成,分别为多头注意力块(multi-head self-attention mechanism)和全连接前馈网络块。每块之间使用一个残差链接之后进行层标准化(Layer Normalization)。为了使用残差链接,每层的输出维度与输入维度必须相同。
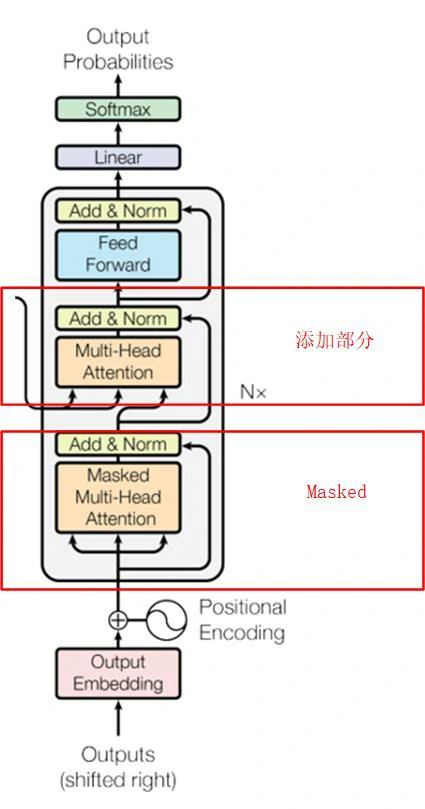
解码器:解码器也由六层相同的层组成。除了与编码器每层包含的两个子块相同之外,解码器还在中间添加了第三个子块,它对编码器的输出执行多头注意力机制变换。与编码器类似,Transformer在每个子层输出使用残差链接,然后是层标准化。还修改了解码器中的self-attention为Masked Multi-Head Attention,以防止后续位置的词作为输入,确保了预测位置i的值时只用到已知的输出,因为在预测句子的时候,当前时刻是无法获取到未来时刻的信息的。
注意力机制
注意力函数可以被描述为将query和一组key-value对映射到输出,其中query, keys, values和输出都是向量。输出为这些值的加权总和,其中分配给每个值的权重是由query的compatibility函数和相应的key来计算的。Attention其实就是计算一种相关程度,计算步骤分为三步:
- 计算比较Q和K的相似度,用f来表示,计算相似度的方法有很多,如点乘,权重,拼接权重,感知器等等,论文采用的是第一种方式的变化——缩放点乘(Scaled Dot-Product Attention)。
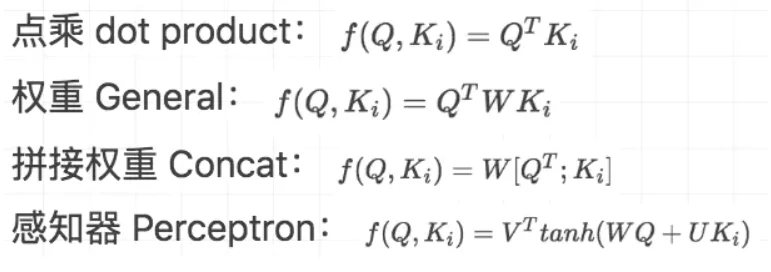
- 将得到的相似度进行softmax归一化
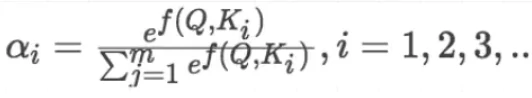
- 针对计算出来的权重,对所有的values进行加权求和,得到Attention向量
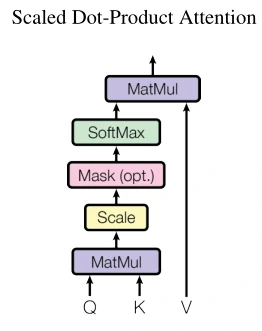
缩放点乘(Scaled Dot-Product Attention)如图6所示,输入包括维度K的查询Q和键V,Attention函数后输出结果。在流程中,Mask是可选的。对于解码器来说,我们是不能看到未来的信息的,所以对于decoder的输入,我们只能计算它和它之前输入的信息的相似度。
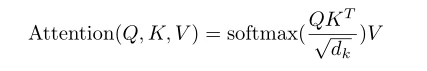
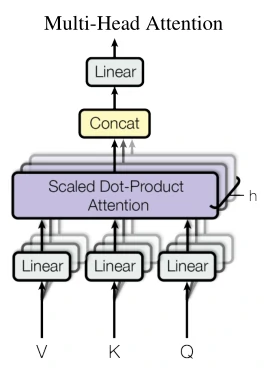
多头注意力机制(Multi-Head Attention)如图7所示,作者没有使用d-model维度key、value和query的单一的注意力机制,而是将key,value和query分别线性映射h次,得到维度分别为dk、dk和dv的线性向量。作者实验指出:线性地对Q、K和V进行线性规划是有益的。
位置编码
注意力机制虽然可以并行处理输入数据,但同样会忽略了序列关系,因此作者在文章中加入了位置编码。因为Transformer模型不包含递归和卷积,为了让模型能够利用序列的顺序,我们必须在序列中注入一些关于词的相对或绝对位置的信息。为此,作者将“位置编码”添加到输入的embedding中,位于编码器和解码器的最开始。位置编码采用相同的维度d-model的向量,可以对两者进行求和。位置编码有很多选择,本文中选择使用正余弦函数如下:
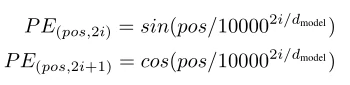
实验结果
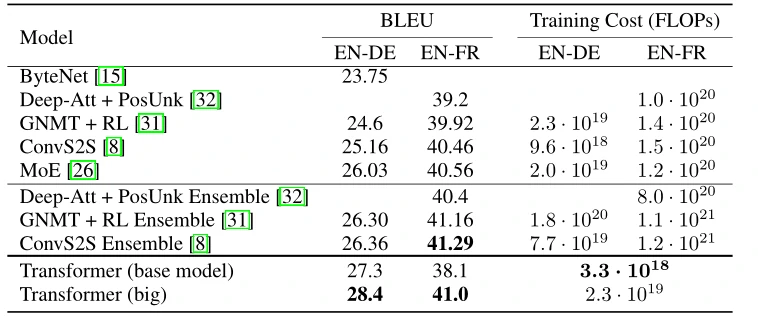
作者在标准的WMT 2014英语-德语数据集上进行训练,该数据集包含大约450万个句子对。句子使用字节对编码进行编码,拥有大约37000个单词的共享源目标词汇表。对于英语-法语,作者使用了明显更大的WMT 2014英语-法语数据集,该数据集由36M个句子组成,并将标记拆分为32000个词块词汇。句子对按近似序列长度分批排列在一起。每个训练批包含一组句子对,其中包含大约25000个源token和25000个目标token。表1为当时效果对比。其中BLEU为评分标准,可以看到,Transformer在训练损失降低了1-2个数量级的同时也得到当时最高的评分。
总结与思考
Transformer是第一个用纯attention搭建的模型,用多头自注意机制取代了编码器-解码器体系结构中最常用的循环层。在翻译任务上获得了更好的结果,也为后续的BERT模型做了铺垫。其优点主要有三部分:
- 每层的计算复杂度低,整体训练成本低;
- 解决了RNN不能并行计算的问题,解决了序列计算的主要约束;
- 解决了网络中远程依赖之间的路径长度(指的是要计算一个序列长度为n的信息要经过的路径长度)。CNN需要增加卷积层数来扩大视野,RNN需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。
同样,Transformer也存在着一定缺点:
- 局部信息的获取不如RNN和CNN强
- 在使用词向量的过程中,会做如下假设:对词向量做线性变换,其语义可以在很大程度上得以保留,也就是说词向量保存了词语的语言学信息(词性、语义)。然而,位置编码在语义空间中并不具有这种可变换性,它相当于人为设计的一种索引。那么,将这种位置编码与词向量相加,就是不合理的,所以不能很好地表征位置信息。
Transformer作为2020年被用到CV领域最火的跨域模型,学习其原理是很有必要的。在表情识别实验中,2020年有研究表明:表情识别的热点图主要集中在人脸的五官位置,基于五官位置的局部特征的表情识别在准确率与基于人脸全局特征的表情识别准确率相差无几,并且基于局部特征显著缩小了算法的计算损失。如何对五官部位的局部特征进行整合是目前项目主要解决的问题,采用Transformer思想对表情局部特征进行自注意力机制的学习能让模型自主的学习表情特征的权重和关联以提升表情识别的效果。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10574
[1] Han K, Wang Y, Chen H, et al. A survey on visual transformer[J]. arXiv preprint arXiv:2012.12556, 2020.
[2] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[3] Li S, Deng W. A deeper look at facial Expression dataset bias[J]. IEEE Transactions on Affective Computing, 2020.
论文下载地址:http://papers.nips.cc/paper/7181-attention-is-all-you-%0Aneed.pdf