拼接
下图是pcm数据的储存:
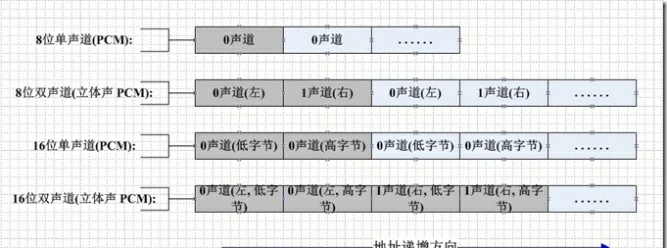
将两个pcm数据进行合并只需将这两个pcm数据直接连续写入到一个文件中就能够获得一个拼接好的数据。要注意的是要控制好写入的buffer大小这样才能保证数据写入的速度(例如1kb)
音频拼接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| DataInputStream ins1 = new DataInputStream(new BufferedInputStream(new FileInputStream(file1.file)));
DataInputStream ins2 = new DataInputStream(new BufferedInputStream(new FileInputStream(file2.file)));
DataOutputStream outputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(file)));
byte[] bytes = new byte[1024];
byte[] bytes2 = new byte[1024];
boolean isfinish1= false;
boolean isfinish2 = false;
while(!isfinish1){
int temp = ins1.read(bytes);
if(temp <= 0){
isfinish1 = true;
} else {
outputStream.write(bytes);
}
}
while(!isfinish2){
int temp = ins2.read(bytes2);
if(temp <= 0){
isfinish2 = true;
} else {
outputStream.write(bytes2);
}
}
ins1.close();
ins2.close();
outputStream.close();
|
裁剪
剪pcm和拼接pcm相似,一个是将两个文件写入一个文件,另一个则是将一个文件中的一段写入另外一个新的文件,这里主要的问题是如何确定数据所表明的时间点。
这里要经过计算获得开始写入和结束写入的数据位置,经过采样率、声道数和比特数来获得每秒的数据量。
每秒数据量 = 采样率 ∗ 声道数 ∗ 比特数 / 1000 / 8
音频裁剪
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| DataInputStream inputStream = new DataInputStream(new BufferedInputStream(new FileInputStream(source.file)));
DataOutputStream outputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(file)));
int audioFormat = 0;
if(source.bit_num == 16){
audioFormat = AudioFormat.ENCODING_PCM_16BIT;
} else {
audioFormat = AudioFormat.ENCODING_PCM_8BIT;
}
int bufferSize = AudioRecord.getMinBufferSize(source.sample_rage_hz,source.channel,audioFormat);
byte[] buffer = new byte[bufferSize * 2];
int sample = source.getSampleNuit();
while(start < end){
inputStream.read(buffer,0,buffer.length);
outputStream.write(buffer, 0, buffer.length);
start = (bufferSize * 2 + start * sample) / sample;
}
inputStream.close();
outputStream.close();
|
混音
线性叠加后求平均
对于pcm的混音原理比较简单,就是数据的加和,可是不一样加和获得的效果是不同的。例如此样例就是用了最简单的线性叠加后求平均。就是两个pcm文件对应的数值向加除以2,固然为了能够调节这两个音频声音大小,能够在每一个数据以前乘以一个系数。
数据结果 = [(pcm数据1 ∗ 系数1) + (pcm数据2 ∗ 系数2)] / 2
优势:不会产生溢出,噪音较小
缺点:衰减过大,影响质量
还有复杂的方法:例如归一化混音和从新采样法等。
音频混音————线性叠加后求平均
1
2
3
4
| private byte remixAVG(byte buffer1, byte buffer2) {
int value = (buffer1 + buffer2) / 2;
return (byte) value;
}
|
归一化混音(自适应加权混音算法)
使用更多的位数(32 bit)来表示音频数据的一个样本,混完音后在想办法下降其振幅,使其仍旧分布在16 bit所能表示的范围以内。
为避免发生溢出,使用一个可变的衰减因子对语音进行衰减。这个衰减因子也就表明语音的权重,衰减因子随着音频数据的变化而变化,因此称为自适应加权混音。当溢出时,衰减因子较小,使得溢出的数据在衰减后可以处于临界值之内,而在没有溢出时,又让衰减因子慢慢增大,使数据较为平缓的变化。
基本公式是:C = A + B - AB / (数据类型的最大值)(byte数据就是:C = A + B - AB / 127; short数据就是:C = A + B - A * B / 32767;)
音频混音——归一化混音(自适应加权混音算法)
1
2
3
4
5
6
7
8
9
| private short remixNOR(short buffer1, short buffer2) {
int value;
if (buffer1 < 0 && buffer2 < 0) {
value = (int) (buffer1 + buffer2 - buffer1 * buffer2 / (-(Math.pow(2,16-1)-1)));
} else {
value = (int) (buffer1 + buffer2 - buffer1 * buffer2 / (Math.pow(2,16-1)-1));
}
return (short) value;
}
|
降噪
常见的开源降噪方案
Speex:Speex是一套主要针对语音的开源免费,无专利保护的应用集合,它不仅包括编解码器,还包括VAD(语音检测)、DTX(不连续传输)、AEC(回声消除)、NS(去噪)等实用模块。
RNNoise:RNNoise降噪算法是根据纯语音以及噪声通过GRU训练来做。包含特征点提取、预料等核心部分。
WebRTC:WebRTC提供了视频会议的核心技术,包括音视频的采集、编解码、网络传输、显示等功能,并且还支持跨平台:Windows、Linux、Mac、Android。使用的就是WebRTC的音频处理模块audio_processing
RNNoise降噪方案
传统降噪算法大部分是估计噪声+维纳滤波,噪声估计的准确性是整个算法效果的核心。根据噪声的不同大部分处理是针对平稳噪声以及瞬时噪声来做。
RNNoise的优点主要是一个算法通过训练可以解决所有噪声场景以及可以优化传统噪声估计的时延和收敛问题。
RNNoise的缺点是深度学习算法落地问题。因为相对大部分传统算法,RNNoise训练要得到一个很好的效果,由于特征点个数、隐藏单元的个数以及神经网络层数的增加,导致模型增大,运行效率。
总的来说,RNNoise处理之后的数据更干净些,几乎没有电流音和杂音,但是受限于训练集、特征点问题,在处理一些数据时候会把正常的原声数据一并错误处理掉。
RNNoise的代码是基于C开源的,集成到Android中需要使用NDK。开源代码中的rnn_data.c和rnn_data.h是通过机器学习训练出来的,不是通用的。
开源项目提供的一个测试方法,但是该方法是针对文件处理的,可以把一个带噪音的PCM文件处理成无噪音文件。直播SDK中的音频数据是分段的byte数组数据,所以中间需要添加一些接口来让RNNoise来支持分段数据的降噪处理。
根据RNNoise的降噪过程和业务接口流程,把接口定义成init、process、free三个接口。
在process数据时发现RNNosie的处理窗口大小是480,所以传入的数据也必须是480的正整数倍。如果不是的话处理之后会有明显的新引入噪音。
1
2
3
4
5
| #define FRAME_SIZE_SHIFT 2
#define FRAME_SIZE (120<<FRAME_SIZE_SHIFT)
#define WINDOW_SIZE (2*FRAME_SIZE)
|
- 开源代码中的rnn_data.c和rnn_data.h是通过机器学习训练出来的,不是通用的。在处理一个噪音数据时发现有些数据中的原声也会一并处理掉,这个效果如果不通过新的数据集训练那么降噪之后的数据是不可用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#ifndef RNN_DATA_H
#define RNN_DATA_H
#include "rnn.h"
#define INPUT_DENSE_SIZE 24
extern const DenseLayer input_dense;
#define VAD_GRU_SIZE 24
extern const GRULayer vad_gru;
#define NOISE_GRU_SIZE 48
extern const GRULayer noise_gru;
#define DENOISE_GRU_SIZE 96
extern const GRULayer denoise_gru;
#define DENOISE_OUTPUT_SIZE 22
extern const DenseLayer denoise_output;
#define VAD_OUTPUT_SIZE 1
extern const DenseLayer vad_output;
struct RNNState {
float vad_gru_state[VAD_GRU_SIZE];
float noise_gru_state[NOISE_GRU_SIZE];
float denoise_gru_state[DENOISE_GRU_SIZE];
};
#endif
|
- 机器学习和训练是RNNoise的灵魂,需要业务接入方根据自身的使用场景通过大量的数据集来找出最合适的处理集。
WebRTC降噪方案
WebRTC的代码是基于C++开源的,集成到Android中需要使用NDK。
WebRTC只能处理特定的采样率数据:8000、16000、32000、44100、48000,这个是其代码内部是写死的,需要自己实现音频重采样来满足WebRTC的降噪采样率需求。
根据WebRTC的降噪过程和业务接口流程,把接口定义成init、process、free三个接口。区别RNNoise的是需要在process中做增益处理,WebRTC降噪会降低数据的声音大小,通过增益用来补充声音大小。
在process数据时发现WebRTC的处理窗口大小必须是160或是320个byte,根据采样率不同窗口大小不同。这个和处理RNNoise是一致都只能传正整数倍数据,要不还是会新引入噪音数据。
WebRTC的降噪NS模块和增益AGC模块是独立的,为了一次数据完成两个过程需要组合数据,边降噪边增益,减少处理耗时。
自定义调用WebRTC暴露的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
private void initProccesor(){
mProcessor = new WebrtcProcessor();
mProcessor.init(frequency);
}
private void processData(byte[] data){
if(mProcessor != null){
mProcessor.processNoise(data);
}
}
private void processData(short[] data){
if(mProcessor != null){
mProcessor.processNoise(data);
}
}
private void releaseProcessor(){
if(mProcessor != null){
mProcessor.release();
}
}
|
自定义降噪类WebrtcProcessor.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| package com.test.jni;
import android.util.Log;
public class WebrtcProcessor {
static {
try {
System.loadLibrary("webrtc");
} catch (UnsatisfiedLinkError e) {
Log.e("TAG", "Couldn't load lib: - " + e.getMessage());
}
}
public void processNoise(byte[] data){
if(data == null) return;
int newDataLength = data.length/2;
if(data.length % 2 == 1){
newDataLength += 1;
}
short[] newData = new short[newDataLength];
for(int i=0; i<newDataLength; i++){
byte low = 0;
byte high = 0;
if(2*i < data.length){
low = data[2*i];
}
if((2*i+1) < data.length){
high = data[2*i+1];
}
newData[i] = (short) (((high << 8) & 0xff00) | (low & 0x00ff));
}
processNoise(newData);
for(int i=0; i<newDataLength; i++){
if(2*i < data.length){
data[2*i] = (byte) (newData[i] & 0xff);
}
if((2*i+1) < data.length){
data[2*i+1] = (byte) ((newData[i] >> 8) & 0xff);
}
}
}
public native boolean init(int sampleRate);
public native boolean processNoise(short[] data);
public native void release();
}
|
只使用的话上述代码已足够,下面稍微看一下源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| #include <jni.h>
#include "audio_ns.h"
#include "noise_suppression.h"
extern "C" {
NsHandle* handle = NULL;
void innerProcess(short in_sample[], short out_sample[], int length){
int curPosition = 0;
while(curPosition < length){
audio_ns_process((int) handle, in_sample + curPosition, out_sample + curPosition);
curPosition += 80;
}
}
JNIEXPORT jboolean JNICALL
Java_com_test_jni_WebrtcProcessor_init(JNIEnv *env, jobject instance, jint sample_rate) {
handle = (NsHandle *) audio_ns_init(sample_rate);
return false;
}
JNIEXPORT jboolean JNICALL
Java_com_test_jni_WebrtcProcessor_processNoise(JNIEnv *env, jobject instance, jshortArray sample) {
if(!handle)
return false;
jsize length = env->GetArrayLength(sample);
jshort *sam = env->GetShortArrayElements(sample, 0);
short in_sample[length];
for(int i=0; i<length; i++){
in_sample[i] = sam[i];
}
innerProcess(in_sample, sam, length);
env->ReleaseShortArrayElements(sample, sam, 0);
return true;
}
JNIEXPORT void JNICALL
Java_com_test_jni_WebrtcProcessor_release(JNIEnv *env, jobject instance) {
if(handle){
audio_ns_destroy((int) handle);
}
}
}
|
上述代码实际上WebRTC降噪一次性只处理了80个short数据(在8000采样率中是这样的),意思就是说WebRTC每次只能处理10毫秒,0.01秒的数据。那么依次类推,针对44100采样率的数据处理的话,每次能处理的数据长度就应该是441个short数据了。
WebRTC的降噪是如何初始化和处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #include "audio_ns.h"
#include "noise_suppression.h"
#include <stdio.h>
int audio_ns_init(int sample_rate){
NsHandle* NS_instance;
int ret;
if ((ret = WebRtcNs_Create(&NS_instance) )) {
printf("WebRtcNs_Create failed with error code = %d", ret);
return ret;
}
if ((ret = WebRtcNs_Init(NS_instance, sample_rate) )) {
printf("WebRtcNs_Init failed with error code = %d", ret);
return ret;
}
if (( ret = WebRtcNs_set_policy(NS_instance, 2))){
printf("WebRtcNs_set_policy failed with error code = %d", ret);
return ret;
}
return (int)NS_instance;
}
int audio_ns_process(int ns_handle , short *src_audio_data ,short *dest_audio_data){
NsHandle* NS_instance = (NsHandle* )ns_handle;
if(
WebRtcNs_Process(NS_instance ,src_audio_data ,NULL ,dest_audio_data , NULL) ||
WebRtcNs_Process(NS_instance ,&src_audio_data[80] ,NULL ,&dest_audio_data[80] , NULL) ){
printf("WebRtcNs_Process failed with error code = " );
return -1;
}
return 0;
}
void audio_ns_destroy(int ns_handle){
WebRtcNs_Free((NsHandle *) ns_handle);
}
|
具体的降噪细节在WebRtcNs_Process()函数中,具体算法细节笔者浅尝辄止,下述仅简述思路:
把前50帧的数据拿来构建噪声模型,把前200帧的信号强度用来计算归一化的频谱差值计算。根据这两个模型使用概率目的函数来计算出每帧的信噪比并区分出噪声和声音,然后根据计算出的信噪比在频域使用维纳滤波器对噪声信号进行噪声消除,最后在根据降噪前后的能量比和信号噪声似然比对降噪后的数据进行修复和调整后输出。
两种降噪方案集成优缺点对比
目前WebRTC最新代码只支持采样率为8000、16000、32000、44100、48000的音频进行降噪,针对其余的采样率需要进行数据重采样到上述采样率之后进行降噪,处理完毕之后需要再次恢复原采样率;RNNoise对采样率没有要求,可以适配常见的采样率。
WebRTC在降噪之后还需要对数据进行增益处理,但是增益会增大电流音,效果会稍差些。
WebRTC处理数据的buffer目前代码是320的整数倍;RNNoise处理数据的buffer目前代码是480的整数倍。输入的buffer需是固定大小的,如果不是正整数倍,需要外部在传入时处理下。
从代码复杂度看,WebRTC的代码是多于RNNoise代码的。RNNoise支持机器学习,通过机器学习生成rnn_data.h和rnn_data.c文件来匹配不同的降噪效果。
降噪耗时对比,RNNoise处理3840字节的buffer数据耗时大概在6ms左右,但在开始时耗时在30ms左右,递减到6ms并稳定;WebRTC处理3840字节的buffer数据耗时大概在2ms左右,但在开始时耗时在10ms左右,递减到2ms并稳定。对比发现WebRTC处理效率更好些。
从处理流程上看都是需要init、process、free操作的,对接入方接入成本是一致的。
补充
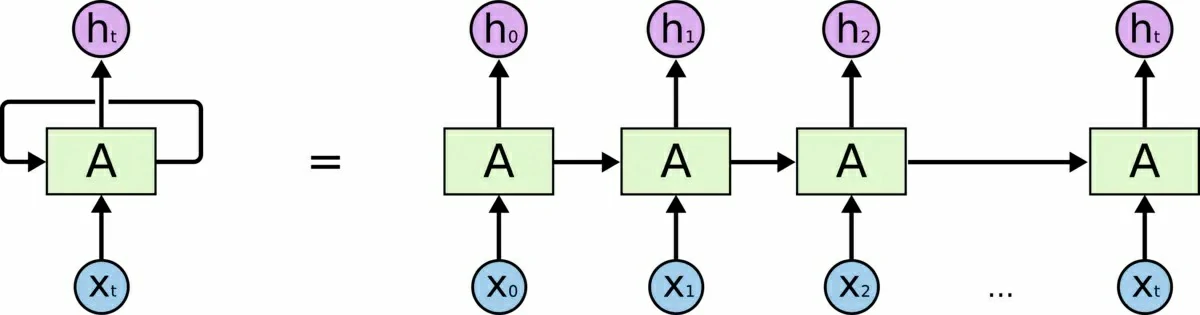
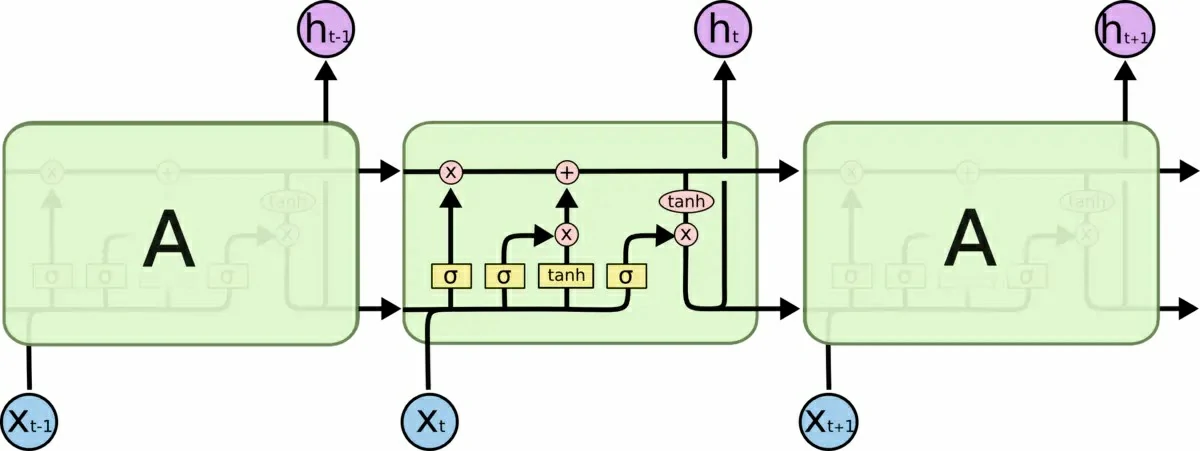
RNN(循环神经网络Recurrent Neural Networks,上)和LSTM(长短期记忆Long Short Term Memory,下)
变音
对于变声的处理一般有以下三种:
变速又变调
即改变音频的速度(语速),又改变音频的频率(音调)
我们可以对原始音频进行重采样,重采样有上采样和下采样,分别是对原始音频进行插值和抽取,比如P/Q重采样,一般我们的处理是,先对原始音频进行插值,在相邻两点间插入P个采样点,全部插入结束后再每隔Q个采样点进行采样,这样得到的音频语速和音调都是原来的Q/P倍
变调又变速(提高)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public byte[] up(byte[] data, int up) {
if (up == 1) {
return data;
}
int length = data.length;
int upLength = length / up;
byte[] upData = new byte[upLength];
for (int i = 0, j = 0; i < length; ) {
if (j >= upLength) {
break;
}
upData[j] = data[i];
i += up;
j++;
}
return upData;
}
|
变调又变速(降低)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public byte[] down(byte[] data, int down) {
if (down == 1) {
return data;
}
int length = data.length;
int downLength = length * down;
byte[] downData = new byte[downLength];
for (int i = 0, j = 0; i < length - 1; ) {
for (int k = 0; k < down; k++) {
downData[j] = data[i];
j++;
}
i++;
}
return downData;
}
|
变速不变调
只改变语速,不改变音调
只是改变语速的话,那么就要稍微复杂点,和重采样方法差不多,区别在于我们需要先规定一帧音频的长度,一般我们的采样率设为44.1KHz,也就是一秒钟采样44.1K次,我们可以规定一帧为1024,所有我们可以简单的根据丢帧和重复帧来实现变速不变调,比如对于P/Q变速,我们先对原始音频的每一帧重复P次,最后的结果再进行每隔Q帧取一帧,这样就得到音频音调不变,语速变为Q/P的音频
变速不变调(提高)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public byte[] speedUp(byte[] data, int up) {
final int FRAME_LENGTH = 1024;
if (up == 1) {
return data;
}
int length = data.length;
int frameShift = FRAME_LENGTH * up;
int upLength = length / up;
byte[] upData = new byte[upLength];
for (int i = 0, j = 0; i < length; ) {
if (i + FRAME_LENGTH >= length) {
System.arraycopy(data, i, upData, j, length - i);
break;
}
System.arraycopy(data, i, upData, j, FRAME_LENGTH);
i += (FRAME_LENGTH + frameShift);
j += FRAME_LENGTH;
}
return upData;
}
|
变速不变调(降低)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public byte[] speedDown(byte[] data, int down) {
final int FRAME_LENGTH = 1024;
if (down == 1) {
return data;
}
int length = data.length;
int downLength = length * down;
byte[] downData = new byte[downLength];
for (int i = 0, j = 0; i < length; ) {
if (i + FRAME_LENGTH >= length) {
int lastlength = length - i;
for (int k = 0; k < down; k++) {
System.arraycopy(data, lastlength, downData, j, lastlength);
j += lastlength;
}
break;
}
for (int k = 0; k < down; k++) {
System.arraycopy(data, i, downData, j, FRAME_LENGTH);
j += FRAME_LENGTH;
}
i += FRAME_LENGTH;
}
return downData;
}
|
变调不变速
只改变音调,不改变语速
如果只是变调的话,就要结合重采样和变速不变调来做,我们先对音频信号进行变速不变调处理,再对其进行重采样,比如,我想要让音调变为原来的P/Q倍,那么我们需要先对其进行P/Q变速不变调,语速变为原来的Q/P,接着,在对其进行Q/P重采样,这样,最后就得到了语速不变,而音调变为原来的P/Q倍
设置语速
1
2
3
4
5
| public byte[] setSpeed(byte[] data, int up, int down) {
byte[] downData = speedDown(data, down);
byte[] upData = speedUp(downData, up);
return upData;
}
|
设置音调
1
2
3
4
5
6
| public byte[] setTone(byte[] data, int up, int down) {
byte[] speedData = setSpeed(data, down, up);
byte[] downData = down(speedData, down);
byte[] upData = up(downData, up);
return upData;
}
|
例如,将up设为4,down设为5,声音就变得低沉。