Experimentation 实验
Baseline 基线
实验是健全的科学的一个重要组成部分。试验应该是公平的。
- 你的结果应该与以前的最佳方法进行比较。
- 将基线的选择更新为最新的。
- 如果你以一种新颖的方式解决了一个现有的问题,但由于某种原因无法与以前的工作相比较,怎么办?潜在的比较点:一个合理的人可能提出的第一个可行的方案。
Persuasive Data 有说服力的数据
把自己放在读者的位置上。
你想被对于某一类问题,有一种算法是现有的最佳选择的说法给说服。
- 什么数据:其特点
- 机制:需要进行规范化或清理
- 充分性:较大的数据集提供不同的统计特性。数据量要足够大,以保证实验将能够检测到被假设的效果。
- 数据集的数量:单个数据集可能不具有说服力
- 领域知识:问题已被抽象或简化
- 例如在生物或医学领域
- 无效的结果
- 限制:需要数据方面的知识来帮助评估结果的重要性,然后尽可能地矫正数据。例如这可能涉及到按照明确的指导原则,仔细地手工处理数据。
- 如果参数是通过调整得出的,那么确定其有效性的唯一方法就是看它们在其他数据上是否有良好的表现。选择参数来适应数据,或者选择数据来适应参数,都有可能使研究无效。
- 参考数据集:允许机构之间和论文之间直接比较工作。它有风险,即方法可能变得非常专业(低鲁棒性),以至于对其他数据不起作用。
- 验证你所测试的是你打算测试的东西,只有在假设正确的情况下,实验才应该成功。询问单一的数据集是否足够?
- 你的主张应该适用于什么量的数据?
Interpretation 解释
- 考虑对结果是否有其他可能的解释;如果有,则设计进一步的测试以消除这些可能性。
- 结论应得到结果的充分支持。特殊情况下的成功并不能证明一般情况下的成功,所以要注意试验中可能使其特殊的因素。
- 不要得出不适当的结论或推论。例如,如果一种方法在大数据集上比另一种方法快,而它们在中等数据集上的速度相同,这并不意味着第二种方法在小数据集上更快;这只意味着不同的成本在不同的规模上占优势。
- 不要夸大你的结论。例如,如果一个新的算法比现有的算法差一些,把它们说成是等价的是错误的。如果差异很小,读者可能会推断它们是等价的,但你这样说是不诚实的。
- 数字测量法允许进行数字操作,但如果应用于我们希望实现的定性目标,这种操作并不总是有意义的。 不能直接解释分数之间的差异程度。
- 预测性:我们论文中的结论通常是关于系统的属性,而不是我们已经看到的数据上的行为。
An “Experimentation” Checklist “实验”总结清单
design of the experiments 实验设计
- 是否已经确定了适当的基线?是什么让它们变得合适?它们是SOTA吗?
- 必须收集哪些数据,从哪里收集?
- 读者将如何为自己收集可比数据?
- 数据是否真实?它的数量是否足够?人工数据需要什么验证?
- 是否应在数据中加入实例以检验结果的有效性?
- 是否有关于这个问题的参考数据,其局限性是什么?
- 是否需要一个领域专家来解释结果?
- 结果可能有哪些限制?
- 实验结果是否应该与模型的预测相符?
- 报告的结果是全面的还是选择的?选择的结果是否有代表性?
- 其他试图用不同的硬件、数据和实现方式来验证工作的人可能会观察到哪些持久的特性?
- 实验是可行的吗?你是否有必要的资源(时间、机器、数据、代码、人力),以合理的标准进行实验?
software to be developed 待开发的软件
- 能否从其他地方获得基线,或者是否需要实施?它们的标准是否与你的系统的实施类似?
- 需要多少代码工作?哪些现有资源可以使用?也就是说,你的“造轮子”工作是否被有效利用?
- 代码(或建议的贡献)能否被分解成组件?如何测试各个组件的正确性,并评估其重要性?
- 你怎么知道这些代码是正确的?
- 代码是否会被公开?如果不,为什么不?
the use of human subjects 人的“使用”
- 在哪些方面可能需要人类?为数据做注释?作为测试对象?你的问题可以在没有人的情况下得到有意义的回答吗?
- 他们将如何被选中?
- 将需要多少人,这与你的预算如何对应?如果使用较少的人,或使用较少的时间,会有哪些妥协?
- 如何保持客观性和独立性?需要采取什么措施来避免引入偏见?
- 是否需要道德审查?
- 伦理审查:1. 参与者为自愿参与并且可以随时退出;2. 已经给参与者提供了关于项目的相关信息;3. 数据进行匿名及保密;4. 对参与者权益的保护
Statistical Principles 统计原理
Variables 变量
- 理想的实验是研究一个变量对被研究对象的行为的影响。
- 消除变量(消融实验)
- 明确了解相关参数
Samples and Populations 样本和总体
- “新的算法通常比旧的算法快”:声称新的算法平均来说更快。
- (这样的声明可以很容易地在无理论分析的基础上和在实验的基础上作出。)
- 但是是什么的平均值?如果预期的含义只是在实验中进行的运行中,新的比旧的平均快,那么这些运行中的什么东西使它们具有代表性或预测性?
- 总体:所有可能运行的集合
- 但在所有的可能性中,总体是无限的,因为它必须包含所有可能的输入数据的组合
- 有必要采用取样的方式
The task may be qualitatively changed. 任务可能会有质的变化。
- 例如,一个搜索引擎在每次运行时,对一个给定的查询和网页集合会取得同样的效果,但对不同的查询或不同的集合会取得不同的分数————这可能是由于新数据改变了任务的性质。在任务发生质变的情况下,谈论总体、样本或平均数可能没有意义,所以解释结果的其他策略可能是合适的。
Reporting variability 报告差异性
- 平均值提供了对典型行为的宝贵洞察力。
- 一个描述性的统计数字是标准差
- 你可以报告特定的值,如1/4至3/4,与中位数相结合
- 实验运行次数是奇数比偶数要好,因为中间的运行将是中位数。
Statistical Tools 统计工具
- 相关性用于确定两个变量是否相互依赖。
- 回归是用来确定两个变量之间的关系。
- 统计假设检验:假设检验用于调查改进是否有意义。通常的情况是,在对同一任务的两种技术进行的一系列比较中,一种技术在某些时候比另一种技术好,但不是所有的时候。
- 有一些软件包可以做很多困难的工作。其次,许多统计问题可以用基本概率来表述,然后通过计算来解决。
Visualization of Results 结果可视化
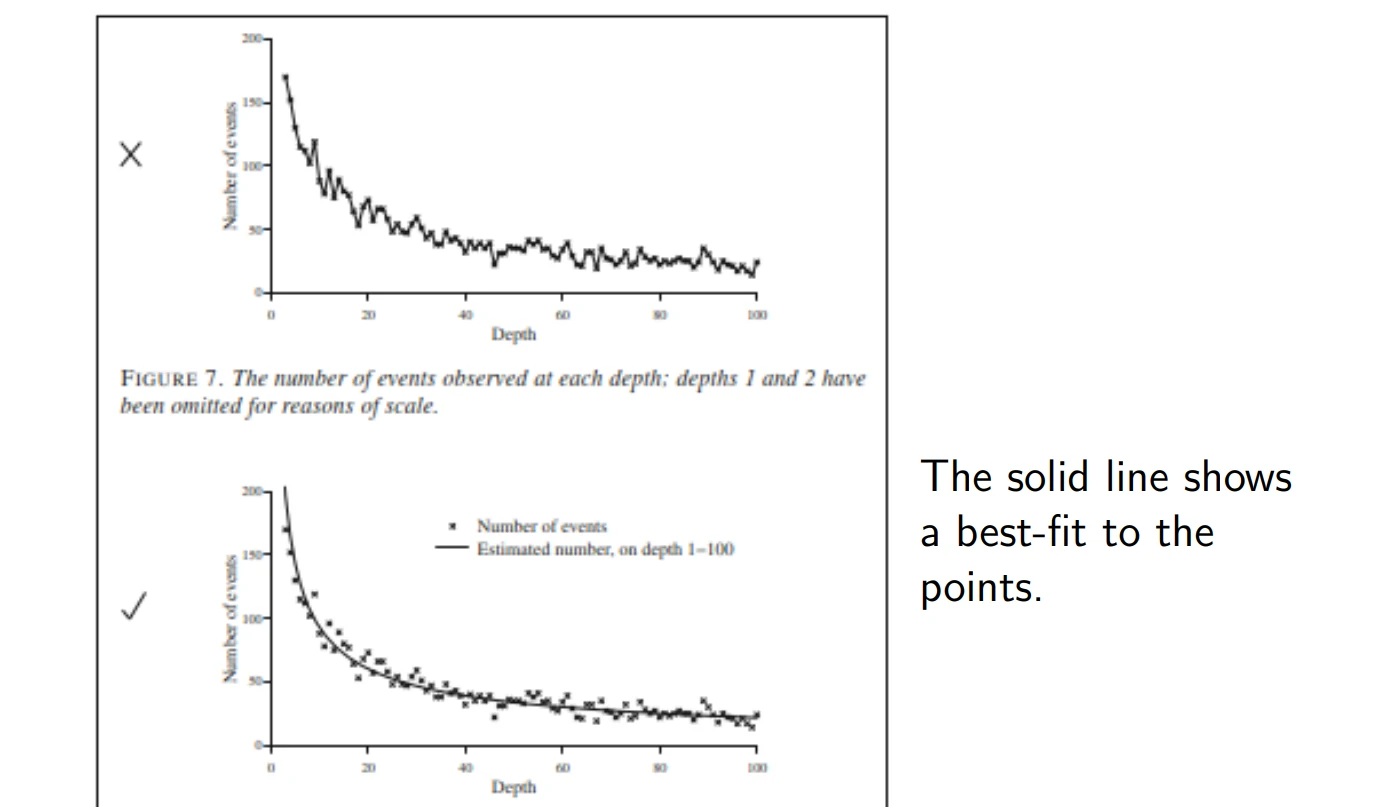
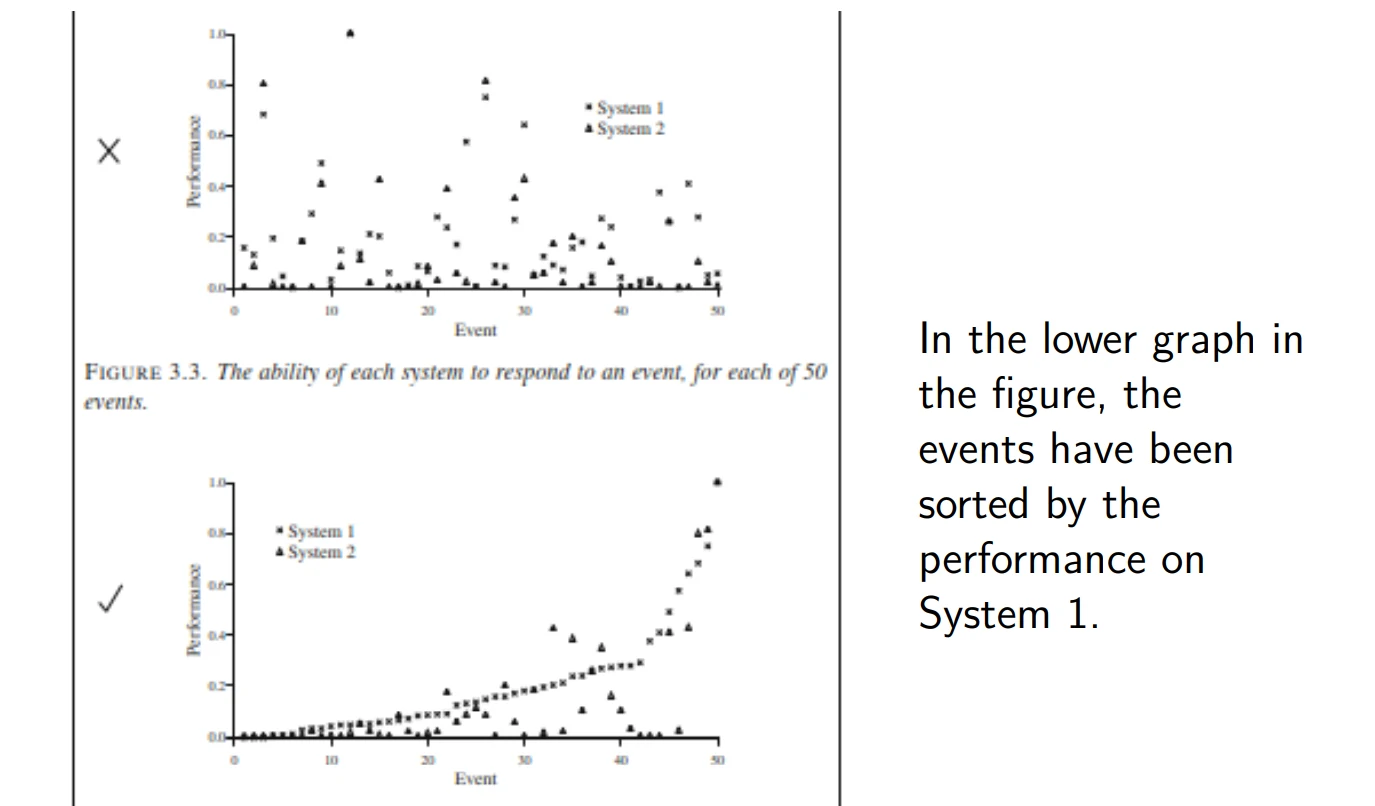
A “Statistical Principles” Checklist “统计原则”总结清单
- 哪些变量可能影响你的结果?对这些变量的分析是否意味着你需要利用统计学的方法?
- 你能预测改变每个变量的效果吗?它们是如何互动的?它们是独立的吗?
- 实验是如何区分变量的影响的?
- 影响是随机的还是系统的?如何控制它们?
- 将使用什么方法来调查异常值?
- 什么是总体?如何抽取样本?证明样本将具有代表性的论据是什么?
- 各项测量的精确度如何?达到一个特定的精度水平有多重要?
- 总结你的结果的正确方式是什么–平均数?一个中位数?一个最小值?
- 什么形式的差异会出现,以及如何在你的结果中捕捉到它?
- 你希望观察到的效应有多大,需要多少次测量才能可靠地观察到它?
- 假设检验是否合适,如果合适,是哪一种?
- 这些结果有意义吗?它们与任何明显的比较点是否一致?
- 哪些可视化方法可能有助于深入了解结果的模式或行为?