MoCoV1
Momentum Contrast for Unsupervised Visual Representation Learning
(特征相似性方式计算:当前batch与当前batch为正样本,与特征库中的所有样本为负样本)
如果没有label约束,每epoch网络参数不同,同一个样本提取的特征分布有差异,会出现退化解现象,作者使用EMA防止该问题,使用内存存储(作者约束特征库最大存储65536个样本)key-value形式保证正样本对之间的相似性,正负样本之间的差异。
每batch 特征库以队列的形式出队和入队,将保存最久的batch特征出队,当前batch(最新)的特征入队。将当前batch的两个不同数据增强方式作为正样本对,其中一个正样本batch与更新前的特征库concat。具体:
每个图片两种不同数据增强方式作为key-value 对,用可bp的编码器(student)提取value的特征q,同时用teacher(由student ema所得)提取key的特征k;
将特征q(N * C)与特征k(N * C)进行矩阵求和得到N * 1,将特征q(N * C)与特征库(C * K)矩阵乘法得到N * K特征(得到当前样本与特征库所有样本特征的相似性)。将N * 1和N * K特征进行concat(以最后一个维度进行融合)为N * (1+K)作为prediction。
=> 此时,N个target都为0,即为当前batch样本的最新特征。
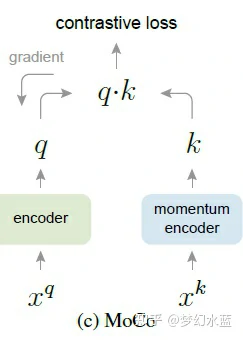
moco-v1
EMA防止退化解。
MoCoV2
Improved Baselines with Momentum Contrastive Learning
参考对比学习依赖数据增强,作者新增了高斯模糊+MLP+cos lr 调整策略。
note:作者说明仅仅在非监督预训练时,MLP替换FC效果会提升。而在分类任务或者迁移学习上进行fine-tune时,没有使用MLP。
MoCoV3
An Empirical Study of Training Self-Supervised Visual Transformers
vit不稳定的训练不影响模型是否work,效果只会有1-3%的降低;
移除 ViT 中的位置嵌入只会使准确性降低一小部分。 这表明自监督的 ViT 可以在没有位置归纳偏差的情况下学习强特征,但这也意味着该位置没有被充分利用。
ViT不稳定训练说明:
作者在进行ViT训练时发现,batch为1k、2k时训练较为稳定,且逐增加,batch在4k甚至6k时,训练不稳定,可看成是跳出局部最优解,全局最优解取决于当前acc,如果当前acc不佳,最后最佳acc可能也不好;
blr越小越稳定,但效果越差。blr过大也会导致过于振荡导致最后效果不佳。
MLP:
自监督预训练时,在特征提取后使用,两个编码器(A和B)并行使用,B=mB+(1-m)A更新,m=0.99时效果最佳;=》(这里不同于MoCo V1,V2使用内存存储,作者直接使用batch来做正负样本,同一个样本不同增强为正样本对,与其余样本互为负样本对)
fine-tune时,将提取特征的网络frozen,只fine-tune分类器头。=> linear probe
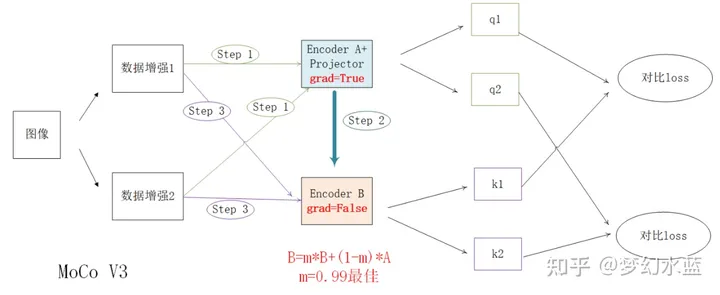
MoCo V3 整个训练逻辑图
上图为MoCo V3 自监督预训练逻辑流程,在fine-tune时,只使用Encoder A+head,且Encoder A中的grad=False,即不进行梯度更新,只fine-tunehead。
MoCo V1、V2、V3对比
思想
V1与V2均使用内存存储形式,存储固定数量样本的特征,V3使用大batch实现。
V1与V2 loss计算时输入维度为N(1+K),N为每个样本特征向量的长度,1+K为内存中所有样本数量(1+65535),每个特征库中第一个样本为正样本,其余为负样本,V3直接对batch的特征向量进行归一化后,矩阵乘法后维度为BB,target分别为每个样本当前所在索引位置。
网络结构
V1、V2与V3中预训练时,Encoder B由Encoder A进行动量计算所得,v1 head为fc,V2 与V3head为mlp。
V1、V2中encoder的backbone为resnet,V3为ViT。
note:
V3中发现ViT训练不稳定并不代表ViT用于图片不能work,不稳定只是效果上会有1-3%的差异;
ViT训练不稳定与lr、batch以及层有关,第一次就出现了dip现象,作者就猜想后续每层都会出现此类现象。batch为1k、2k训练稳定,再大就会出现不稳定。
lr太小,虽然vit训练稳定但效果差1-2%,lr太大,vit训练不稳定越明显。blr=1e-4最佳,lr=blr*batch/256
重点:解决不稳定问题,作者直接对第一层随机初始化用固定参数,不参与参数更新。对其它网络都适用
训练trick
v1简单使用裁剪、翻转,v2、v3在v1基础上新增高斯模糊;
v2、v3使用学习率调整策略训练。