前阵子读了Transformer的论文,发现自己对BN和LN并不是很清楚,故博众家所长作此文。
Normalization
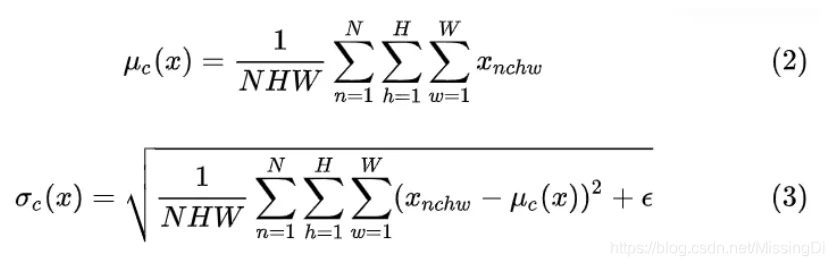
由于 ICS 问题的存在,x 的分布可能相差很大。要解决独立同分布的问题,“理论正确”的方法就是对每一层的数据都进行白化操作。然而标准的白化操作代价高昂,且不可微不利于反向传播更新梯度。因此,以 BN 为代表的 Normalization 方法退而求其次,进行了简化的白化操作。
(白化是一个比PCA稍微高级一点的算法,目的是降低输入的冗余性,输入数据集X,经过白化处理后,新的数据X’满足两个性质:特征之间相关性较低,所有特征具有相同的方差)
基本思想是:在将 x 送给神经元之前,先对其做平移和伸缩变换, 将 x 的分布规范化成在固定区间范围的标准分布。
深度学习中的ICS问题
covariate shift 是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
而统计机器学习中的一个经典假设是 “源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。
前言
在一个网络中, 如果训练数据的分布同测试数据时, 训练最有效率, 因为此时根据训练数据计算出的梯度最接近真实的梯度, 因此使用此梯度对参数进行优化最高效。
推理
神经网络的目的就是输入一批数据, 根据这批数据的分布, 预测真实数据的分布, 我们一般将这里的数据数据称之为训练数据。
如果把第一层, 也就是最底层网络去掉, 剩下的网络称之为子网络, 那么子网络的目的与原网络相同, 同样是输入一批数据, 根据这批数据的分布, 预测真实数据的分布, 而这里的输入数据就是训练数据经过第一层网络后的输出数据, 此时目的不变, 那么同样适用上面那个原则, 即输入数据的分布于测试数据的分布越接近, 那么该网络的优化越高效. 依此类推, 这个结论适用于任何层次的子网络。
结论
因此, 我们就应当考虑这样一个问题, 要尽量保证数据在经过每一层网络时, 其分布保持不变, 也就是数据在输入每一层网络之前, 其分布都与测试数据接近, 那么可以使得整个网络的训练是高效的。
ICS问题(internal covariate shift), 就是说如果训练数据在经过网络的每一层后其分布都发生了变化, 通过上述论证可知, 此时就不能保证整个网络的优化过程是高效的, 甚至说会极大地降低网络的优化效率。
ICS导致的问题
每个神经元的输入数据不再是 “独立同分布”。
- 上层参数需要不断适应新的输入数据分布,降低学习速度。
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
- 每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
通用变换框架
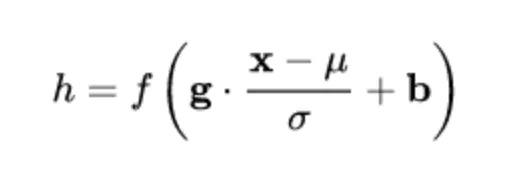
最终得到的数据符合均值为 b 、方差为 g^2 的分布。
为什么要再平移再缩放
为了保证模型的表达能力不因为规范化而下降。
第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。
平移参数和再平移参数的区别
平移参数,x 的均值取决于下层神经网络的复杂关联。
但再平移参数中,去除了与下层计算的密切耦合。新参数很容易通过梯度下降来学习,简化了神经网络的训练。
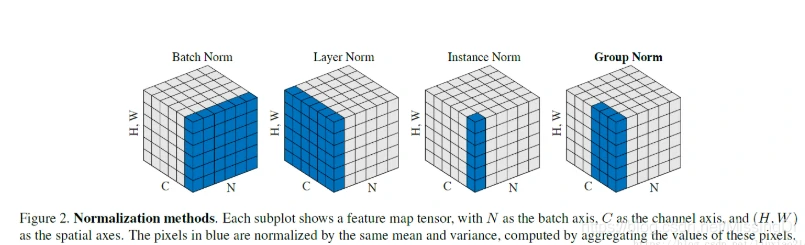
Batch Norm
每一batch的样本具有相同的均值和方差
BN在batch维度的归一化,也就是对于每个batch,该层相应的output位置归一化所使用的mean和variance都是一样的。
BN的学习参数包含rescale和shift两个参数。
- BN在单独的层级之间使用比较方便,比如CNN。得像RNN这样层数不定,直接用BN不太方便,需要对每一层(每个time step)做BN,并保留每一层的mean和variance。不过由于RNN输入不定长(time step长度不定),可能会有validation或test的time step比train set里面的任何数据都长,因此会造成mean和variance不存在的情况。
- BN会引入噪声(因为是mini batch而不是整个training set),所以对于噪声敏感的方法(如RL)不太适用。
我们在对数据训练之前会对数据集进行归一化,归一化的目的归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0, 1]或者[-1, 1]),从而消除奇异样本数据导致的不良影响。虽然输入层的数据,已经归一化,后面网络每一层的输入数据的分布一直在发生变化,前面层训练参数的更新将导致后面层输入数据分布的变化,必然会引起后面每一层输入数据分布的改变。而且,网络前面几层微小的改变,后面几层就会逐步把这种改变累积放大。训练过程中网络中间层数据分布的改变称之为:“Internal Covariate Shift”(ICS)。
BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。所以就引入了BN的概念,来消除这种影响。所以在每次传入网络的数据每一层的网络都进行一次BN,将数据拉回正态分布,这样做使得数据分布一致且避免了梯度消失。
此外,internal corvariate shift和covariate shift是两回事,前者是网络内部,后者是针对输入数据,比如我们在训练数据前做归一化等预处理操作。
需要注意的是在使用小batch-size时BN会破坏性能,当具有分布极不平衡二分类任务时也会出现不好的结果。因为如果小的batch-size归一化的原因,使得原本的数据的均值和方差偏离原始数据,均值和方差不足以代替整个数据分布。分布不均的分类任务也会出现这种情况!
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。


Layer Norm
每一个神经元有相同的均值和方差,每个样本的均值和方差不同
LayerNorm实际就是对隐含层做层归一化,即对某一层的所有神经元的输入进行归一化。(每hidden_size个数求平均/方差)
- 它在training和inference时没有区别,只需要对当前隐藏层计算mean and variance就行。不需要保存每层的moving average mean and variance。
- 不受batch size的限制,可以通过online learning的方式一条一条的输入训练数据。
- LN可以方便的在RNN中使用。
- LN增加了gain和bias作为学习的参数。
与BN不同的是,LN对每一层的所有神经元进行归一化,与BN不同的是:
- LN 中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
- BN 中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
- LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
一般情况,LN常常用于RNN网络!把一个 batch 的 feature 类比为一摞书,LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
Layer Norm
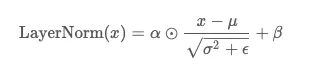
Layer Norm求均值方差
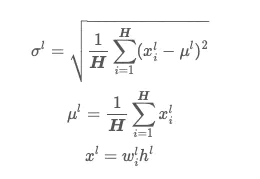
Bert layer norm实现代码
1 | class LayerNorm(nn.Module): |
总结
Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
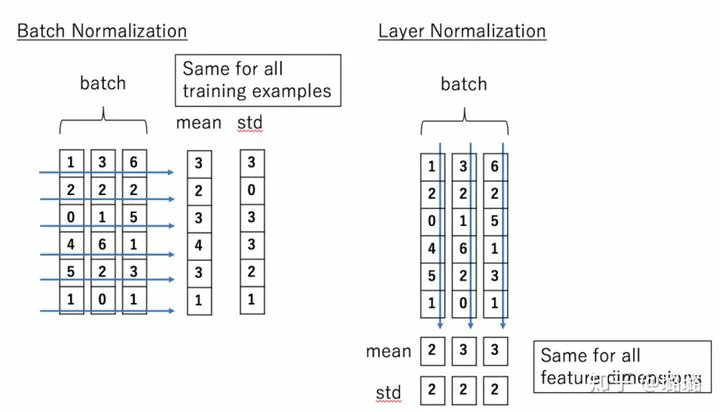
BN、LN可以看作横向和纵向的区别。
经过归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。BatchNorm这类归一化技术,目的就是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习知识。
BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来。LayerNorm则是通过对Hidden size这个维度归一。
(CV领域),如果你的特征依赖于不同样本间的统计参数,那BN更有效。因为它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系。
(NLP领域),LN就更加合适。因为它抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。对于NLP或者序列任务来说,一条样本的不同特征,其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的。
参考资料
https://www.jianshu.com/p/cb8769fd0c41
https://www.jianshu.com/p/91b54246b51c
https://blog.csdn.net/MissingDi/article/details/106155394
https://zhuanlan.zhihu.com/p/113233908
https://zhuanlan.zhihu.com/p/428620330