本篇学习报告主要介绍一篇发布于2020年CVPR的论文《ClusterFit: Improving Generalization of Visual Representations》。
背景
现如今,在许多视觉任务上,受限于对数据集真实标签的获取难度,由自监督或半监督预训练而成的卷积神经网络变得越来越受欢迎。然而,由于在预训练过程中缺乏强区别性信号(即显著特征),这些方法学习到的特征很容易与预训练目标过拟合,进而无法很好地推广到下游任务。因此,该论文提出了一个简单却有效的方法:ClusterFit。该方法可扩展到不同的弱监督和自监督预训练框架中。作者通过对多个不同目标数据集进行迁移实验,证明了ClusterFit可以显著提升模型的泛化能力。
方法
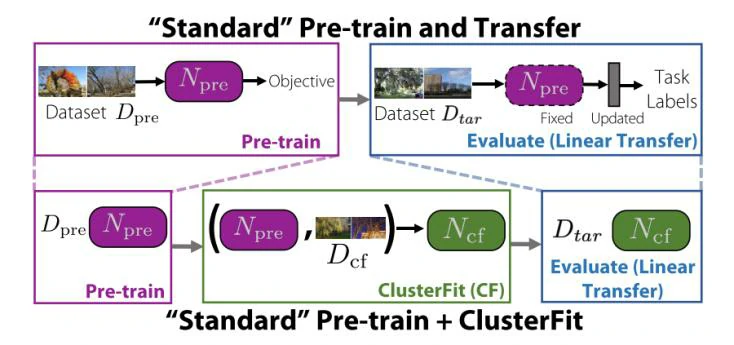
如图所示,ClusterFit的实现流程可概括为:①首先,给定一个卷积神经网络N_pre,该网络先在预训练数据集D_pre上做分类任务,因此N_pre具有一定的特征提取能力。②第二步,让预训练过的N_pre在目标数据集D_cf上采用K-means聚类算法,将数据集划分成K个groups,将groups所代表的聚类标签作为原始图像的伪标签。③从头开始初始化一个新的卷积神经网络N_cf,让其在D_cf上做伪监督分类任务,此处采用的伪监督信号L_cf即为前文中由N_pre所提供的聚类标签,由于N_cf在训练过程中未使用D_cf的原始标签,所以该方法可认为是无监督的,损失计算方法采用交叉熵损失。④在N_cf和N_pre尾部均加上一层线性层,在目标数据集D_tar进行线性验证,检验两种方法所学特征的泛化能力。
实验
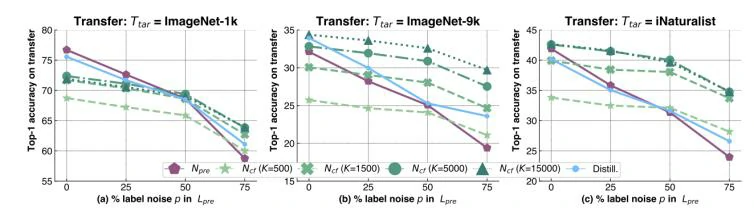
基本实验设置:设置N_pre和N_cf均为ResNet50,D_pre和D_cf均为Imagenet-1K,图中的横坐标p代表在N_pre预训练过程中加入多少百分比的噪声标签,对应每一个百分比,作者都训练出一个与N_pre相对应的N_cf,最后再用N_cf在三个数据集(Imagenet-1K,Imagenet-9K,iNaturalist)上验证N_pre的泛化能力。
在图(a)中,当p为0时,N_pre的表现要优于各个K值下的N_cf,这种情况是合理的,因为此时D_pre和D_tar均为imagenet-1K,并且预训练任务和迁移任务均为无噪声条件下分类任务,但随着p值的增大,迁移任务转化为在有噪声标签条件下的分类任务时,N_cf的表现要逐渐相似甚至优于N_pre,这证明了ClusterFit所学习到的特征更具备泛化性。
在图(b)和图(c)中,当D_tar与D_pre不同时,N_cf的表现普遍优于N_pre,并且在聚类个数越多的情况下,ClusterFit的迁移能力越强,这进一步说明了应用ClusterFit所学习到的特征可以很好地推广到下游任务。
文中还验证了在多种模态下(例如图像,音频等)的消融试验,ClusterFit所取得的效果依然令人满意。
学习总结
本文提出的ClusterFit可以显著提高在弱监督和自监督框架中学习的图像和音频特征的泛化能力。ClusterFit首先通过对原始特征空间进行聚类并重新学习聚类分配的新模型来解决过拟合预训练目标的问题,预测聚类标签为“relearn”的网络提供了一个学习对原预训练目标非敏感特征的机会,使它们更具可迁移性。最重要的是,ClusterFit是一个通用的框架,对模型,数据类型,监督形式均无任何限制,可以很便捷地嵌套进现有的框架当中,提升现有模型的鲁棒性。
论文地址:https://arxiv.org/pdf/1912.03330.pdf
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=13723