本篇学习报告基于论文《Inverting Generative Adversarial Renderer for Face Reconstruction》。此论文提出一种新颖的生成对抗渲染器(Generative Adversarial Renderer,GAR),用于取代基于简单图形规则的可微分渲染器来完成三维人脸模型的重建任务。相关成果发表在2021 CVPR(Oral)。原文链接与代码地址见文末。

研究背景和内容
从无约束的单目人脸图像中准确恢复人脸的三维形状是一项具有挑战性的任务。目前最先进的三维人脸重建方法大致可以分为两大类:
- 基于深度学习的方法
基于深度学习的方法通常采用回归的方式,将人脸图像作为输入,学习回归相应的三维形变模型(3D Morphable Models,3DMM)参数。然而,这些方法通常需要大量的标记数据,而正确标注的3DMM参数很难获取。 - 基于优化的方法
基于优化的方法一般将人脸的成像视为一个生成过程。它将一系列几何系数(如反照率、纹理、光照、视角等)作为输入与输出,按照一定的图形规则渲染图像。然后通过优化方法最小化渲染图像和目标图像之间的距离。然而,由于图形规则通常采用简化的模型来表征人脸图像采集的物理过程,导致成像过程中的许多细节无法建模,这给人脸重建的优化带来了困难。
在最近的研究中,可微分渲染器[1]给两类方法都提供了一个有效的工具。在基于学习的方法中,回归的参数可以通过可微分渲染器渲染到二维图像中,然后添加光度损失进行优化。通过这种方式,可以在不需要输入图像标注的情况下训练模型。对于基于优化的方法,可微分渲染器引入了基于梯度的优化,允许使用更复杂的损失函数,并能够稳定训练过程。 然而,主要基于图形学基础的可微分渲染器简化了真实世界中光照、反射等真实机制,因而难以生成足够真实的图像,如图2的(b)、(c)所示。

为了解决上述的问题,作者提出了一种基于对抗生成网络的自监督方式进行三维模型的渲染,以取代传统的基于图形的可微分渲染器,同时保持使用渲染器进行训练的优势。总的来说,该方法的主要贡献有三方面:
- 第一个提出使用条件神经渲染器(conditional neural renderer)用于人脸重建,而不是基于图像的可微分渲染器。
- 提出的条件神经渲染器以人脸法线贴图和隐变量作为输入,然后产生生动逼真的人脸图像。
- 基于该渲染器提出了新的人脸重建算法,并在多个人脸数据集上实现了最先进的性能。
方法
基于生成对抗的渲染器
为了实现人脸几何参数受控的生成器,文章提出了基于StyleGan v2[2]的一系列渲染模块组成的生成式对抗渲染器(GAR)。这些基于三维人脸几何信息的渲染模块,在保持使用随机隐变量生成纹理的同时显式地加入了人脸的几何信息。
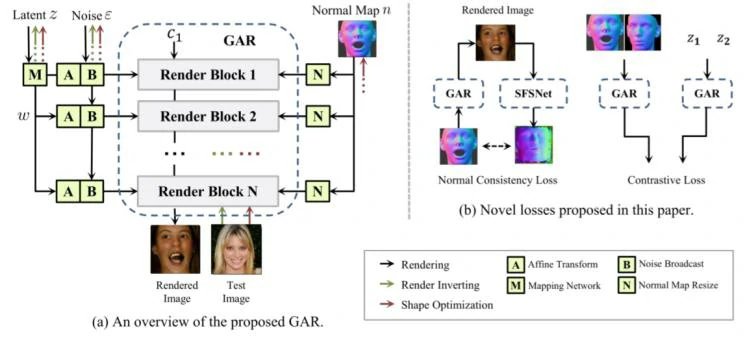
具体而言,对于每个模块的4维输入特征(批次、通道数、长、宽),StyleGAN v2提出在通道数上进行风格注入,以调控生成的结果。而在长宽的图像维度上,文章提出同时注入与人脸几何相关的法线信息,以监督整张人脸在图像中的位置和五官的分布。该注入以乘积的方式添加,保持特征图在不同几何信息的位置具有针对性的响应。
为了规范化生成网络得到的结果以匹配输入条件,文章还提出了法线一致性损失(Normal Consistency Loss)(见图3(b)左侧)。利用几何学方法渲染一批合成人脸训练了一个人脸法线估计网络(SFSNet),然后使用该网络预测生成输出图像的人脸法线贴图作为弱监督保持法线的近似一致性。
另外,文章还提出为了控制生成图像的纹理信息和人脸的几何信息能够解耦,在训练过程中采用交换几何信息和注入变量信息的方式,并利用预训练的关键点检测保持人脸几何信息的一致性以及人脸识别网络提取的特征保持纹理信息的一致性。

通过GAR生成图像的例子可以在图4中看到,这表明提出的方法比传统的基于图形的渲染器生成的人脸图像具有更高的视觉质量,甚至发型,眼镜和其他属性都能很好地生成。
基于反向渲染的人脸三维重建
GAR经过训练后,可以代替可微分渲染器进行基于优化的人脸三维重建任务。
在此,人脸重建的目标是给定一张自然环境下的人脸图像,通过优化3DMM的参数以及输入的隐变量和噪声重建其人脸几何结构。反向渲染技术可以充分利用GAR的优势,以生成的与给定的图像相似的图片为目标,反推出输出的人脸形状与纹理。
文章中设计了与生成器结构对称的反向网络,用于估计隐变量的初始优化值,以解决随机初始化导致基于梯度的优化可能会卡在损失函数的局部最小值的问题。反向网络生成的特征图与GAR对应层的特征图具有相同的空间大小。将各层统计的均值和标准差串联起来,然后进行最大似然估计(MLP),得到重构的隐变量。另外,为了获得良好的3DMM初始人脸参数,文章中采用了传统的基于二维人脸关键点的3DMM拟合算法。GAR反向网络和3DMM参数预求解方法为优化提供了良好的初始化,通过最小化渲染图像和输入图像之间的光度损失,可以实现对三维人脸形状的优化。
实验结果
人脸图像生成的评价
为了定量分析生成的图像质量,文章中使用Progressive GAN[3]、StyleGAN[4]和提出的GAR随机生成50000张图像,并计算生成的图像与真实图像数据之间的FID(Frechet Inception Distance)分数。如表1所示,结果表明,提出的GAR在更多的条件约束下训练,并且网络的可控性得到了提升。

人脸重建的评价
- 定性比较
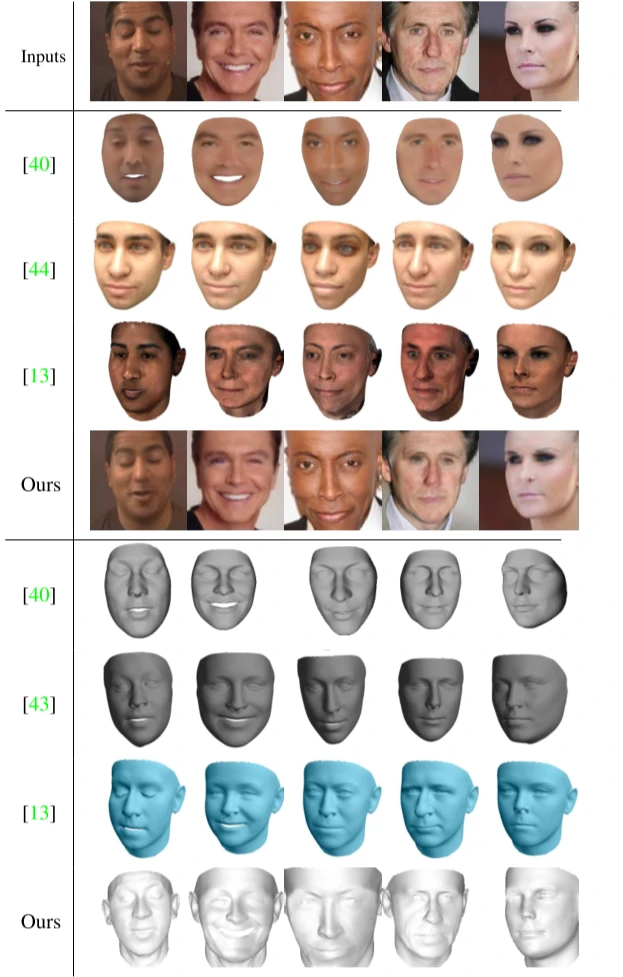
作者将提出的重建算法与几种最先进的方法在MoFA-Test数据集[5]上进行了定性比较,如图5所示。第2-5行是渲染的图像,可见文章提出的方法渲染的图像非常接近输入图像。第6-9行是重建的人脸网格,该重建方法的结果在形状和表情方面显然更准确,具有更多高保真的细节。
- 定量比较
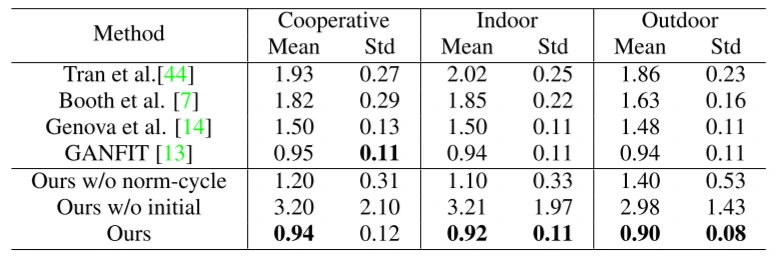
为了定量评估该重建算法的性能,作者使用扫描的人脸来测试准确性。具体而言,使用Florence数据集[6]中每个视频的5帧,并将重建结果与真实标注的三维扫描网格进行比较。结果如表2所示,文章的方法在平均误差方面有较好的结果。
消融实验
下面介绍针对所提出的人脸重建框架的不同组成部分的消融研究的结果。
法线一致性损失(Normal Consistency Loss)的影响。如表2的第5行和第7行所示,当训练没有该损失的GAR(“Ours w/o norm-cycle”)时,训练不能保证生成器在输入的法线贴图上处于良好的状态。这说明所提出的法线一致性损失对于提高输入法线贴图的可控性具有重要意义。
渲染器反向网络初始化的效果。如表2的第6行和第7行所示,当隐变量没有被反向网络初始化(“our w/o initial”)时,重建误差严重增加,并且对于特定的人脸可能不会收敛。
条件的选择。以往的工作倾向于采用3DMM参数或深度作为条件输入。然而,作者发现以人脸法线贴图作为条件对提出的GAR是一种更有效的形式。以人脸法线贴图作为输入,可以更稳定、更快地减少损失,并能更好地收敛到最优状态。
法线信息注入模块的作用。与简单地将法线贴图和特征映射连接相比,该方法在进一步减小损失方面是有效的,说明了该方法的有效性。
总结与思考
文章提出了一个新颖的生成对抗渲染器(GAR)与一种反向渲染网络以实现人脸重建。GAR比基于传统图形学的渲染器效果更加真实,大大减小了渲染图像与真实图像之间的差异。而基于GAR的反向网络以生成与给定图像相似的图像为目标,反推出人脸的形状与纹理进而完成三维人脸的重建。GAR不仅解决了基于图形学的可微分渲染器存在的本质问题,而且达到了很好的效果,这为我们解决三维人脸重建问题提供了新的思路。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=9918
[1] Kyle Genova, Forrester Cole, Aaron Maschinot, Aaron Sarna, et al. Unsupervised training for 3D morphable model regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8377–8386, 2018.
[2] Tero Karras, Samuli Laine, Miika Aittala, et al. Analyzing and improving the image quality of StyleGAN. In Proc. CVPR, 2020.
[3] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196, 2017.
[4] Tero Karras, Samuli Laine, Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019.
[5] Ayush Tewari, Michael Zollhofer, Hyeongwoo Kim, et al. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 1274–1283, 2017.
[6] Andrew D Bagdanov, Alberto Del Bimbo, Iacopo Masi. The florence 2d/3d hybrid face dataset. In Proceedings of the 2011 joint ACM workshop on Human gesture and behavior understanding, pages 79–80. ACM, 2011.
原文链接:https://arxiv.org/abs/2105.02431
Github地址:https://github.com/WestlyPark/StyleRenderer
参考链接:https://zhuanlan.zhihu.com/p/370573907