今年,德国马克思·普朗克学会旗下的智能系统研究所 (MPI Inteliligent Systems) 斩获 CVPR 2021 最佳论文奖,本文主要内容也是基于此篇论文展开——《GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields 》。

前言
GIRAFFE(Generative Neural Feature Fields)的发展大体经历了NeRF(Neural Radiance Fields)、GRAF(Generative Radiance Fields) 两个阶段,GIRAFFE也是NeRF和 GAN 的结合。
NeRF简单来说是用一个MLP模型去隐式地学习一个静态3D场景。不同于传统基于点云、体素等显式三维重建方法,NeRF通过提供大量相机参数如位置坐标、视角方向来渲染生成场景颜色值和体积密度。基于这些训练的场景信息,即可以从任意角度对图片进行合成。
NeRF需要提供大量不同视角下的场景图片,要对每个场景重新训练,并且不能产生新的场景。GRAF是一种NeRF表示的条件变体,展示了如何从一组未设定相机pose的2D图像中学习出丰富的生成模型,除了改变视角之外,GRAF 还允许修改生成对象的形状和外观。
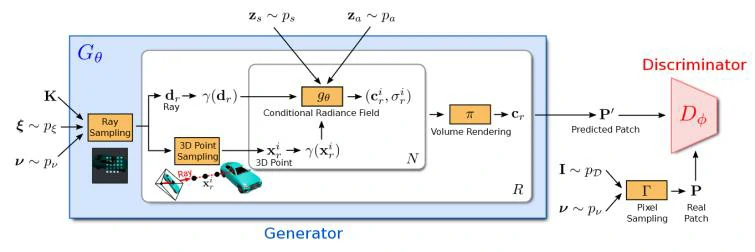
GRAF 整体框架和 GAN 接近,如上图所示,主要包含Generator与 Discriminator两部分,在生成图像的 Generator 中用到了 NeRF 的机制。训练阶段,GRAF使用稀疏的K x K个像素点2D采样模板进行高效优化,测试阶段,预测出目标图片的每个像素的颜色值。
GRAF虽然实现高分辨率下可控的图像合成,但是只能局限于单物体场景。考虑到世界是三维的,并且很多人忽略了场景的复合结构性质。因此GIRAFFE的关键假设是,将合成的3D场景表示合并到生成模型中实现更可控的图像合成。将场景表示为复合生成神经特征场,允许将一个或多个对象从背景以及单个对象的形状和外观中分离出来,同时从非结构化和未定位的图像集合中学习,而无需任何额外的监督。将该场景表示与神经渲染管道相结合,可产生快速且逼真的图像合成模型。
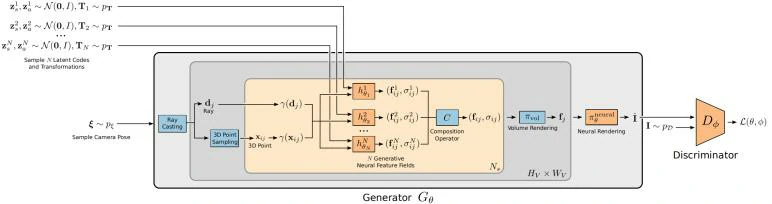
经过一系列改变后,GIRAFFE 可以控制相机姿势,物体在场景中摆放的位置与角度,及物体的形状与外观。更强大的是,GIRAFFE 还可在场景中自由地增加多个物体,将生成的场景从单个物体扩展到多个物体——合成训练图片以外的物体。
方法
主要分为三个部分:
- Objects as Neural Feature Fields
NeRF场景表达公式:
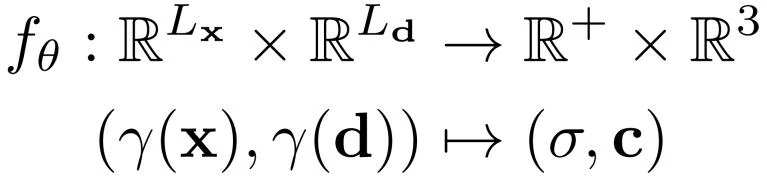
输入任意一个空间坐标以及观察角度,MLP会预测一个RGB值和体素密度。
GRAF场景表达公式:
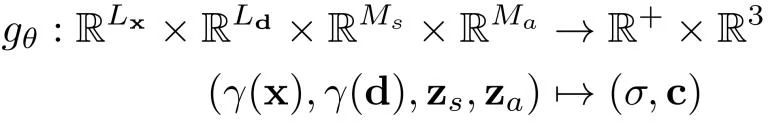
相比NeRF增加了形状和外观编码 zs, za ~ N(0, 1)
GIRAFFE场景表达公式:
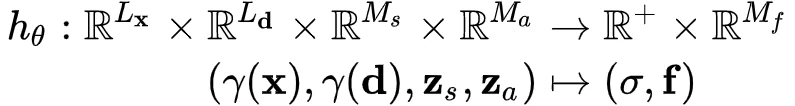
相比GRAF, 颜色输出从三维变成 M_f 维,将输出的 Color c,变成了 Feature f。
其次,GIRAFFE 对场景中的每一个物体(包括背景)引入了一个仿射变换 T = {s, t, R} ,表示物体放置在场景中的位置和方向,可以让物体与背景分离开,从而控制物体在场景中的位置,也可以自由地增减物体。
- Scene Compositions
假设一个场景可以描述成 1 个背景和N-1个物体,GIRAFFE将背景也看成一个物体,固定住背景的尺度和平移参数作为参照,以场景空间原点为中心。这 N 个实体通过他们各自的仿射变换组合到一起,而这 N 个实体,各自经过他们的神经辐射场,生成各自的 σ_i 与 F_i,计算总密度通过对不同物体进行密度求和,总颜色则对不同物体的密度进行颜色加权求和:
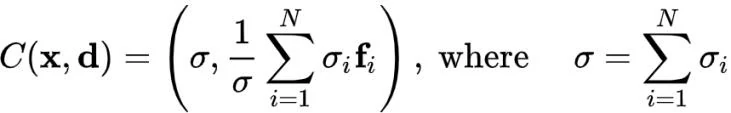
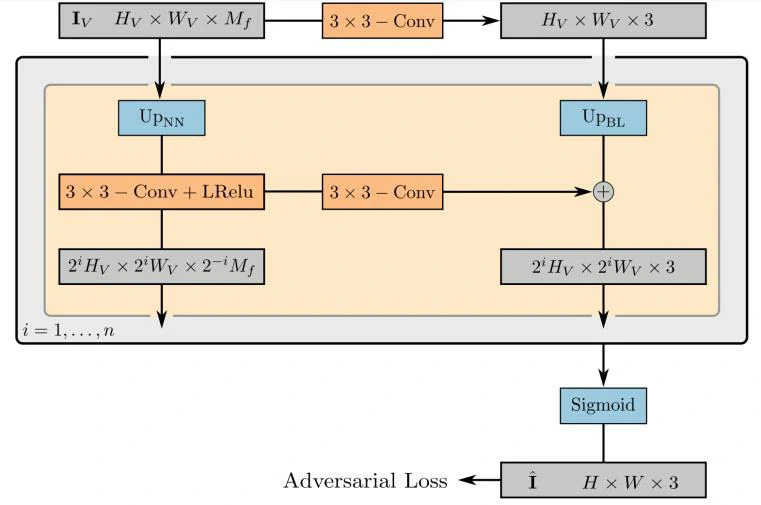
- Scene Rendering
GIRAFFE的Scene Rendering分成 3D Volume Rendering 和 2D Neural Rendering 两个部分。其中 3D volume rendering和NeRF的相似,只是从3维拓展到了 M_f 维。 2D Neural Rendering 结构如图所示,将低分辨率的特征映射上采样到高分辨率的RGB图像。
结果


总结
GIRAFFE 引入了合成的神经特征场,利用NeRF隐式表示简洁性和可拓展性等特点,通过改变相机位姿,物体在场景中摆放的位置与角度,以及目标的形状与外观来控制多个物体场景的合成。此外,GIRAFFE 还可以在场景中自由地增加多个物体,将生成的场景从单个物体扩展到多个物体,是强化版的 GRAF。
文章也提到了模型的两个局限性。一是模型的属性解耦能力不够强,比如背景前物体会被“附着”到背景上;二是存在“Dataset Bias”的现象,在celebA-HQ数据集中,眼睛和头发的方向主要指向相机,而不考虑面部旋转。但文中在旋转对象时,生成的图像中的眼睛和头发不会保持固定,而是根据数据集偏差进行调整。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10263
https://zhuanlan.zhihu.com/p/391210153
https://zhuanlan.zhihu.com/p/384521486
[1] Mildenhall, B. et al. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. in Computer Vision – ECCV 2020 (eds. Vedaldi, A., Bischof, H., Brox, T. & Frahm, J.-M.) vol. 12346 405–421 (Springer International Publishing, 2020).
[2] Niemeyer, M. & Geiger, A. GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields. in Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2021).
[3] Schwarz, K., Liao, Y., Niemeyer, M. & Geiger, A. GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis. in Advances in Neural Information Processing Systems (NeurIPS) (2020).