FR的任务、结构、特征发展、损失函数发展、骨干网发展
人脸识别任务分类(FR,Face Recognition)
(1)1:1(人脸验证)
- 1:1一般叫face verification任务,是二分类(e.g., comparing one face to another)
- Face Verification(人脸验证;人脸确认;人脸校验) = 验证你是不是你? (1:1 matching)
- 在互联网买机票、车票,医院挂号,政府惠民工程项目,以及各种证券开户、电信开户、互联网金融开户都会用到
(2)1:N(人脸识别)
- 1:n一般叫face identification任务,是多分类 (e.g., searching for a face in a database of many faces)
- Face Identification(人脸识别) = 找出你是谁? (1:n matching)
- 跟1:1的A/B两张照片比对最大的区别是A/B A/C A/D……多个1:1计算,这个最大的问题是一旦BCD总和数量越大计算速度越慢,而总和超过20万,就回出现多个相似结果(20万人这个大数会导致有不少人长相相似),需要人工辅助定位。
- 主要用于人脸检索、排查犯罪嫌疑人、失踪人口的全库搜寻、一人多证的重复排查,以此相似度列出相应的结果,可以大大提高排查效率。
- 1:1的实际使用场景是更加受限而单一的,而1:n的实际使用场景更加wild、更加不可控。因此要到达较高的可用性,1:1会更加容易,而1:n会更难一些。
(3)N:N
- N:N 该算法实际上是基于1:N的算法,输入多个求解结果。比如视频流的帧处理所用,对服务器的计算环境要求严苛
(4)人脸聚类
- 寻找类似的人?
人脸识别的挑战
- 类间差别(Intra-personal variation)
- 类内差别(Inter-personal variation)
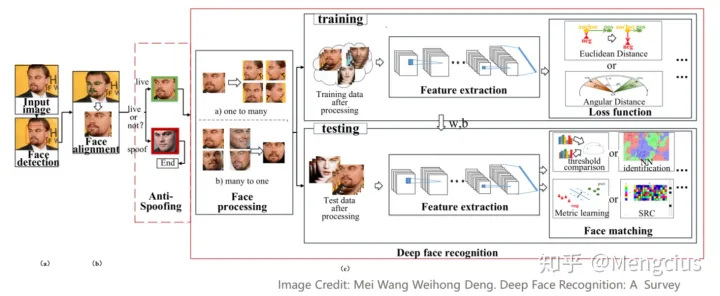
深度人脸识别系统
- 首先,人脸检测器用于定位人脸。 然后,人脸与标准化的规范坐标对齐。 最后, FR模块执行人脸识别。
- FR模块的人脸防欺骗(anti-spoofing)可识别人脸是否有效或是否有欺骗性;人脸处理在训练和测试之前处理识别困难之处;
- 在训练时,用不同的架构和损失函数提取具有判别性的深层特征;当提取测试数据的深层特征后,使用人脸匹配方法进行特征分类。
- 下图中列举了数据处理、结构设计、损失函数和人脸匹配等方面的一些重要方法
- Deep Face Recognition: A Survey. Mei Wang,Weihong Deng. 201804
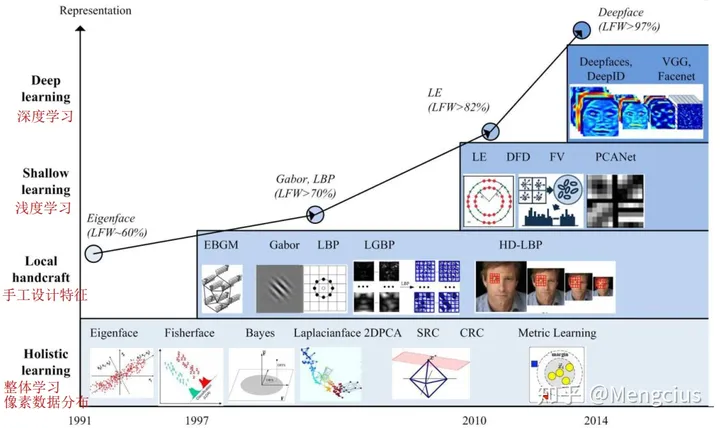
FR特征表示的发展
- 在20世纪90年代和21世纪初,整体方法主导了FR
- 在21世纪初和21世纪10年代,基于局部特征的FR和基于学习的局部描述符相继问世
- 2014年,DeepFace和DeepID实现了最先进的精度,研究重点已转向基于深度学习的方法。
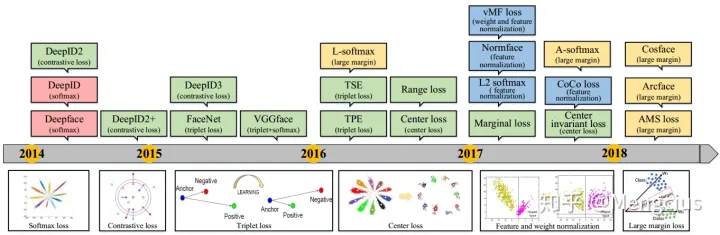
FR损失函数的发展
- 2014年的Deepface和DeepID标志着基于深度学习的FR诞生,用的是Softmax loss
- 2015年之后,基于欧氏距离的损失在损失函数中一直扮演着重要的角色,如对比损失(Contrastive loss)、三元组损失(Triplet loss)、中心损失(Center loss)
- 2017年,特征和权重归一化(Feature and weight normalization)也开始显示出优异的性能,这导致了softmax变种的研究,如L2 softmax
- 在2016年和2017年,Large margin loss进一步推动了大间隔特征学习的发展,如L-softmax、A-softmax、Cosface、Arcface
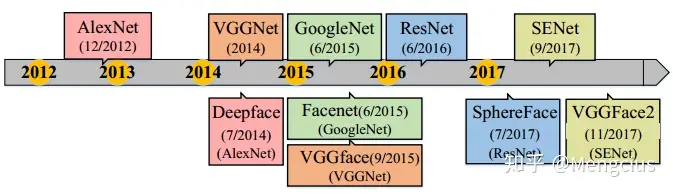
FR骨干网络的发展
- 深度FR的体系结构始终遵循深度对象分类的网络结构,由AlexNet演化到SENet
FR的数据集
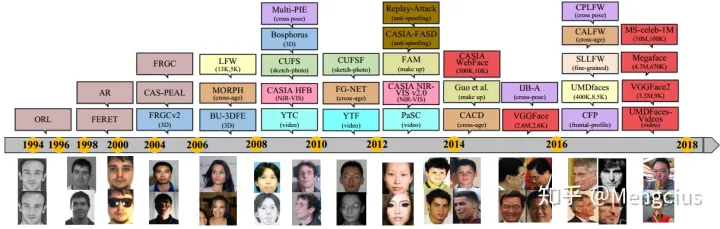
FR数据集的演变
- 2007年之前,FR的早期工作集中在约束的和小规模数据集。
- 2007年引入LFW数据集,标志着无约束条件下FR的开始。从那时起,设计了更多具有不同任务和场景的测试数据库。
- 2014年CASIA-Webface提供了第一个广泛使用的大规模公共训练数据集。
- 红色矩形表示训练数据集,其他颜色矩形表示具有不同任务和场景的测试数据集
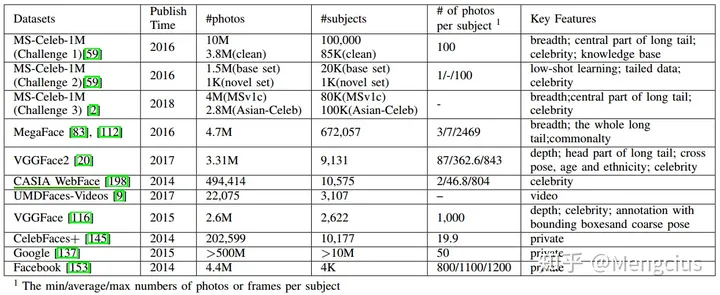
用于训练常用的FR数据集
用于测试的常用FR数据集
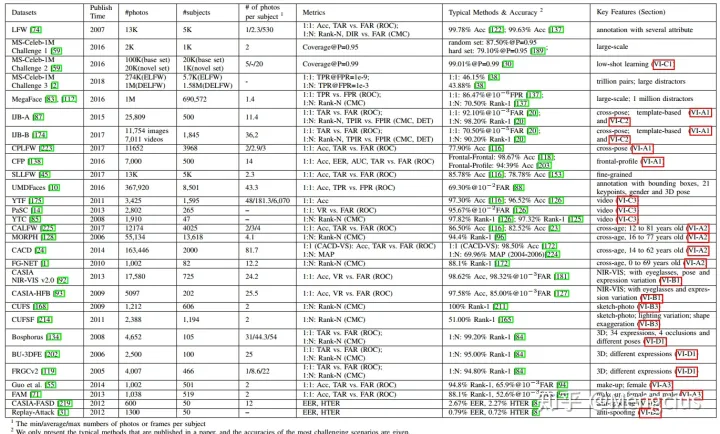
数据集列举
LFW 人脸识别数据集
- 无约束自然场景人脸识别数据集,该数据集由13323张互联网名人在自然场景(不同朝向、表情和光照环境)下的人脸图片组成。共有5749个名人,其中有1680人有2张或2张以上人脸图片,只有85人拥有超过15张图片,4069人只有1张图片。每张人脸图片都有唯一的姓名ID和序号加以区分。
- LFW数据集主要测试人脸识别的准确率。该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。
- http://vis-www.cs.umass.edu/lfw/
FDDB 人脸检测数据集
- 无约束自然场景人脸检测数据集,该数据集包含在从各个不同自然场景拍摄的2845幅图像中的5171个人脸。每个人脸都有其规定的坐标位置。
- FDDB数据集主要测试人脸检测的准确率。人脸识别算法需要在该数据集每张图像上进行人脸检测,对检测到的人脸进行位置标定。然后根据数据集本身给出的正确答案计算正确检出人脸数与误检人脸数而评判人脸检测算法的好坏。
- http://vis-www.cs.umass.edu/fddb/
CelebA(CelebFaces,CelebFaces+) 人脸属性识别数据集
- Large-scale Celeb Faces Attributes (CelebA) Dataset由香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集,主要用于人脸属性的识别。202599张人脸图片,10177个身份,以及5个地标位置,每张图片40个二进制属性注解。
YouTube Faces(YTF)
- YouTube Video Faces是用来做人脸验证的。在这个数据集下,算法需要判断两段视频里面是不是同一个人。有不少在照片上有效的方法,在视频上未必有效/高效,视频图像质量较差。该数据集包含3,425段视频中的1,595个人。 最短片段持续时间为48帧,最长片段为6,070帧,视频片段的平均长度为181.3帧。
CASIA-WebFace
- Chinese Academy of Sciences (CASIA),第一个广泛使用的FR大规模公共训练数据集。49万张图片,1万个人。
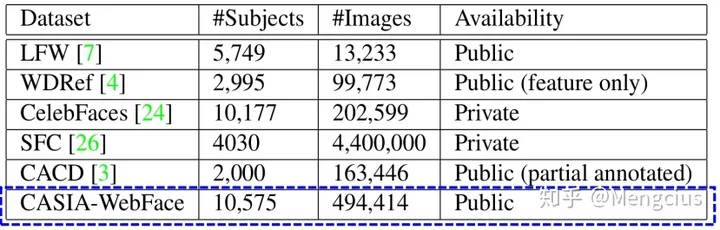
- Chinese Academy of Sciences (CASIA),第一个广泛使用的FR大规模公共训练数据集。49万张图片,1万个人。
IJB-A 数据集
- IJB-A (IARPA Janus Benchmark A) 数据集中不仅包括被摄对象的静态图像而且同时也包括被摄者的视频片段。因为这个特点,引入了模板的概念:指在无约束条件下采集的所有感兴趣面部媒体的一个集合。该媒体集合不仅包括被拍摄者的静态图像也包括视频片段。
- 数据集中的所有媒体都是在完全无约束环境下采集的。很多被拍摄者的面部姿态变化巨大,光照变化剧烈以及拥有不同的图像分辨率。
- 不足是该数据集的规模小,IJB-A数据则只包含来自500个对象的5396幅静态图像和20412帧视频数据。
MegaFace 数据集
- 美国华盛顿大学发布的百万级人脸数据MegaFace数据集,包括690572个对象和约4.7百万张图像,将人脸数据的规模推向了一个高度。
- 这个数据集方针设定不同,其内容是几十位互联网名人的图片再加上普通人的1百万张图片作为干扰数据。相比人脸识别,更倾向于在大噪声下的人脸验证,并且数据的分布同样不平衡,平均每个对象只有7幅图像,同一对象内人脸数据的变化小。
MS-Celeb-1M 数据集
- 微软亚洲研究院发布,该数据集包含10万个对象和约1千万张图像。 这是迄今最大规模的人脸识别数据集,尽管规模很大但数据分布不平衡且大姿态的面部数据占比少且存在不少的噪声数据。
- 从1M个名人中,根据他们的受欢迎程度,选择100K个。然后,利用搜索引擎,给100K个人,每人搜大概100张图片。共100K╳100=10M个图片。测试集包括1000个名人,这1000个名人来自于1M个明星中随机挑选。而且经过微软标注。每个名人大概有20张图片,这些图片都是网上找不到的。
- MSR IRC是目前世界上规模最大、水平最高的图像识别赛事之一,MSRA(微软亚洲研究院)图像分析、大数据挖掘研究组组长张磊发起,每年定期举办。
孪生网络架构
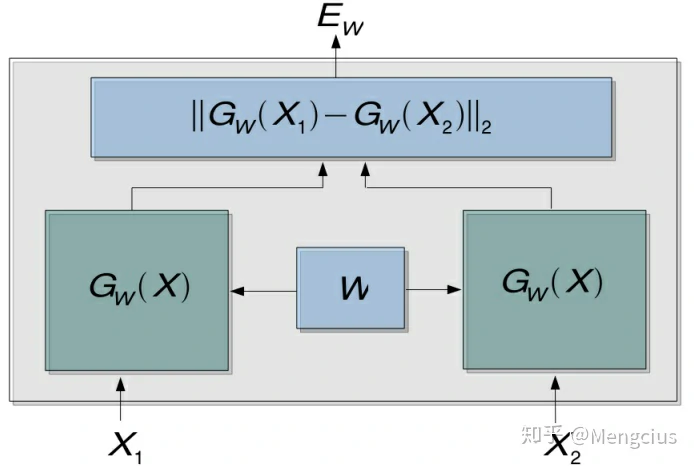
孪生网络(Siamese network)是连体的神经网络,孪生架构(Siamese Architecture)是一种框架,神经网络的“连体”是通过共享权值来实现的。Siamese指两个暹罗连体人胞胎。孪生神经网络用于处理两个输入”比较类似”的情况,如计算两个句子或者词汇的语义相似度。
- 左右两个神经网络的权重是一模一样的,甚至代码实现时可以是同一个网络,不用实现另外一个,因为权值都一样,两边可以是lstm或者cnn。
伪孪生神经网络(pseudo-siamese network):如果左右两边不共享权值,而是两个不同的神经网络,就是,。它两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。伪孪生神经网络适用于处理两个输入”有一定差别”的情况,如验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字)。
孪生神经网络的用途是衡量两个输入的相似程度。将两个输入feed进入左右两个神经网络,这两个神经网络分别将输入映射到新的空间中的向量,在新的空间中判断Cosine距离、exp function、欧式距离等就能得到两个输入的相似度了。通过Loss的训练来使相似图像的相似度D变小,不相似的图像相似度D变大。
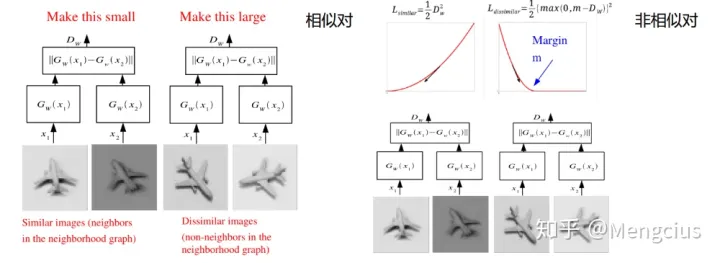
- 传统的siamese network使用Contrastive Loss(对比损失)。当然损失函数还有其他选择,Softmax当然是一种好的选择,但不一定是最优选择,即使是在分类问题中。下图是用了对比损失:
- 为使邻居的输出相隔得很远,按平方支付
- 为使非邻居的输出小于边际m,按平方支付。D大于m时取0,不相似的D越大。
- 在nlp和cv领域都有很多应用:
- 1993年Yann LeCun就把Siamese神经网络用在了签名验证上,即验证支票上的签名与银行预留签名是否一致。NIPS 1993《Signature Verification using a ‘Siamese’ Time Delay Neural Network》
- 2010年Hinton用来做人脸验证,效果很好,即将两个人脸feed进卷积神经网络,输出same or different,这里属于二分类。ICML 2010《Rectified Linear Units Improve Restricted Boltzmann Machines》
- 手写体识别
- 基于Siamese网络的视觉跟踪算法也已经成为热点,2016《Fully-convolutional siamese networks for object tracking》
- 词汇的语义相似度分析,QA中question和answer的匹配
- kaggle上Quora的question pair的比赛,即判断两个提问是不是同一问题,冠军队伍用的就是n多特征+Siamese network
- 参考
FR的损失函数
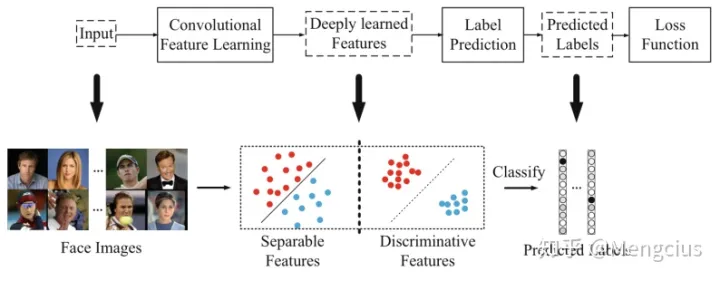
标签预测(最后一个全连接的层)就像一个线性分类器,深度学习的特征需要容易分离(separable) 。此时softmax损失能够直接解决分类问题。
但对于人脸识别任务,深度学习的特征不仅需要separable,还需要判别性(discriminative) 。 可以泛化从而识别没有标签预测的未见类别。
基于欧几里得距离的损失函数
对比损失 (Contrastive Loss)、三元组损失 (Triplet Loss)、中心损失 (Center Loss)
基于Angular Margin的损失函数
L-Softmax Loss、A-Softmax Loss、COCO Loss、CosFace Loss、ArcFace Loss