本篇学习报告基于ACL2021(Annual Meeting of the Association for Computational Linguistics, CCF A类会议)的论文:《ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning》,由清华大学与腾讯Wechat AI平台合作研究。
背景介绍
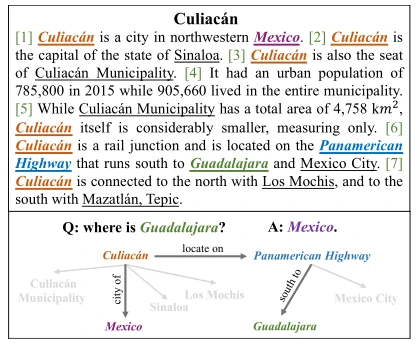
近几年,预训练语言模型(Pre-trained Language Model,简称PLM) 在自然语言处理领域的各种下游任务上表现得地极为出色,如文本分类、命名实体识别和智能问答。PLM可以在各种自监督学习方法中有效地捕捉文本中的语法和语义,为下游自然语言处理任务生成信息语言表示。然而,传统的预训练目标并没有针对相关事实去建立模型的,而这些事实往往分布在文本中且对理解整个文本至关重要。为了解决这个问题,最近的一些研究试图通过改进PLM以更好地理解实体之间的关系。但是这些方法主要是关注孤立的句内关系,这不仅忽略了对实体本身的理解,也忽略了在文档级中多个实体之间的相互作用。这些实体之间的关系理解涉及复杂的推理模式,有研究证明至少40.7%的关系事实是需要从多个句子中才能提取到的。图1所示的例子是要识别“瓜达拉哈在哪里?”的答案,我们可以很容易就可以发现,答案是无法从独立的一个句子中得到的,而是要在整篇文档中才能推理出与“瓜达拉哈”相关的国家。从这个例子我们可以看到想要捕获文本内的关系事实目前面临着两个主要挑战:(1)要想理解一个实体,要综合考虑它和其他实体的关系;(2)要理解一个关系,就要考虑在文本中复杂的推理模式。
在这篇论文中,作者提出了一个新的对比学习框架ERICA来提高PLM对实体和关系的理解能力,旨在更好地捕捉文本中实体和关系事实。具体来说,本篇文章在PLM上主要做出了以下两个贡献:(1)实体识别任务,通过给定的头部实体及其关系来区分哪些尾部实体可以被推断出来。它通过考虑文本中每个实体与其他实体的关系来提高对每个实体的理解;(2)关系判别任务,从语义上区分两种关系是否相近。通过构建具有文档级远程监督的实体对,隐式地考虑了复杂的关系推理链,从而提高了对关系理解。我们在一套语言理解任务上进行了实验,包括关系抽取、实体分类和问答。实验结果表明,ERICA提高了典型PLM (BERT和RoBERTa等)的性能,并优于基线,特别是在低资源设置下,这表明ERICA有效地提高了PLM对实体和关系的理解,并捕获了文本内的关系事实。
方法
实体与关系表示(Entity & Relation Representation)
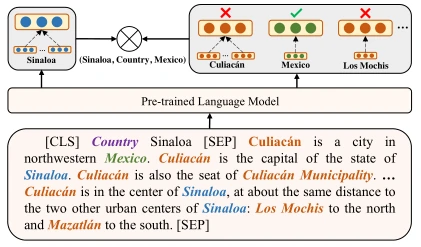
作者提出的ERICA是利用外部知识图谱在一个大规模无标记语料库上进行训练的,ERICA对一个文档中的所有实体都枚举成一组实体对。如果实体对在外部知识图谱中本身存在关系,则顺理成章生成三元组(正例),反之两个实体之间的关系被赋值为“no_relation”(反例)。ERICA使用一个PLM对每个文档进行编码生成对应的隐藏态,再经过平均池化机制去获得局部实体表示。由于一个实体在一个文档是可以出现多次的,作者就把这多次的表示求平均以得到该实体在文档中的全局表示,紧接着把最终的全局实体表示进行向链接来得到它们的关系表示。
实体识别任务(Entity Discrimination Task)
两个实体之间的关系可以用一个三元组表示,即(头实体,关系,尾实体)。实体识别任务的目标是要求在给定的头实体和关系的情况下去推断出文档中所存在的尾实体。PLM在这部分的实质工作是根据已知的正例头实体和关系的约束,将尾部实体与其他不相干的实体区分开来。论文在该部分的创新点在于使用了对比学习的方法使得PLM去考虑实体之间的关系来进行区分,而不再是像传统的方法一样单纯地将后验概率最大化。对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。与生成式学习(如常见的对抗网络)相比,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。
关系识别任务(Relation Discrimination Task)
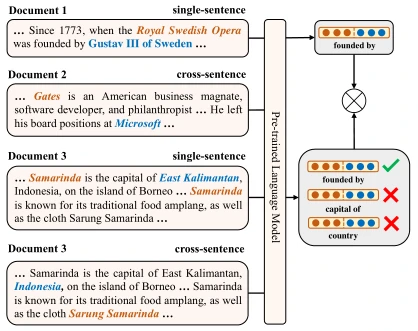
关系识别任务旨在通过语义上的判别来区分两种关系是否相近。与现有的PLM关系增强方法相比,论文的创新点在于使用了文档级的远程监督方法而不再是一般的独立句子,这进一步地帮助PLM理解现实场景中复杂的推理链,从而提高PLM对关系的理解能力。在该部分,文章训练一个基于文本的关系表示的预训练语言模型,它将正例且具有相同关系的实体对文本进行训练,使它们在语义上相近。值得注意的是,这部分的工作中也使用到对比学习的方法去区分正例关系和反例关系。
实验
在实验部分论文包含了构建远程监督的数据集构建,ERICA在自然语言处理的下游任务(关系抽取、实体分类、问答)上的表现。论文提出的ERICA是为了提升传统PLM的效果,因此论文设计了ERICA在BERT和RoBERT两个经典的PLM上做了实验。
远程监督数据集构建
论文中利用英语维基百科和Wikidata来构建了远程监督的预训练数据集。首先使用spaCy来进行命名实体识别,然后将这些识别出来的实体且在维基百科也出现的实体与Wikidata条目的超链接链接起来,从而获得每个实体的Wikidata ID。这里提到的spaCy是一种python的开源库,可以完成大部分nlp的相关人物。紧接着,通过查询Wikidata,可以对不同实体之间的关系进行远程标注。论文约束每个文档都至少包含128个单词、4个实体和4个关系三元组。最后,论文共收集了100万个文档(约1G存储空间),其中有4000多个远程标注的关系。平均而言,每个文档包含186.9个token、12.9个实体和7.2个关系三元组,一个实体在每个文档中出现1.3次。基于人工对数据集随机抽样的评估,命名实体识别的F1-score为84.7%,关系提取的F1-score为25.4%。
关系抽取
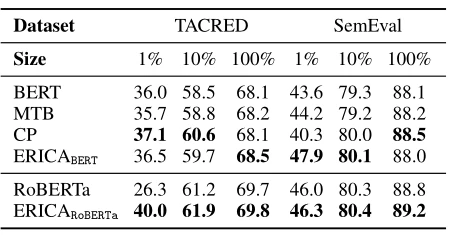
关系抽取的目的是从预定义的关系集中提取两个被识别实体之间的关系,文章在文档级和句子级的训练集上分别进行了实验,同时还把训练集所占原数据集的比例做了1%,10%,100%三种划分。表1展示了在句子级上的实验结果。句子级上的关系抽取是在两个广泛使用的数据集:TACRED和SemEval-2010 Task 8上,数据集被插入额外的标记以指明每个句子中的头实体和尾实体。BERT[2]、RoBERTa[3]和MTBandCP被作为baseline方法,从结果来看,我们可以发现ERICA与CP在句子级关系抽取任务上取得了几乎相当的结果,这意味着在文档级的预训练ERICA不影响PLM在句子层面里在关系理解上的表现。
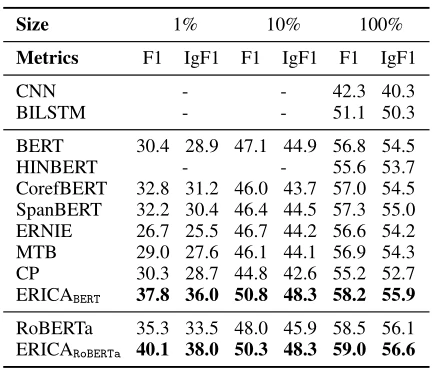
文档级的关系抽取,在该部分的评价指标使用了micro-F1和micro-ignore-F1,其中micro-ignore-F1是指忽略了训练集和测试集之间共享关系事实下的评估。对于文档级关系抽取论文选择了DocRED[1]的方法,它需要阅读文档中的多个句子以综合所有信息来识别两个实体之间的关系,CNN、BILSTM、BERT、HINBERT和CorefBERT被作为baseline方法。从表2的结果可以看出:(1)ERICA在每个数据量上都显著优于所有基线,说明ERICA在训练前通过隐式考虑文档中实体的复杂推理模式,能够更好地理解文档中实体之间的关系;(2)MTB[4]、CP[5]两种方法的效果都不如BERT,这意味着句子级的预训练缺乏对复杂推理模式的考虑,在一定程度上影响了PLM在文档级RE任务中的表现;(3)ERICA在较小的训练集上比baseline表现出更大的优势,这意味着ERICA在对比学习中获得了良好的文档级关系推理能力,从而在低资源设置下获得改进。
实体分类
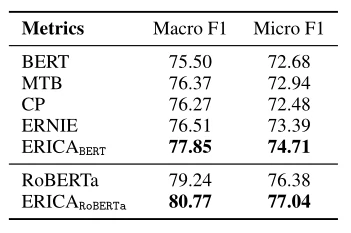
实体分类的目的是将提取出来的实体分类为预定义的实体类型。论文在FIGER这个带有远程监督标记的句子级实体类型数据集进行测试。选取BERT、RoBERTa、MTB、CP、ERNIE作为基线。从表3的结果中我们可以看出,ERICA的表现优于所有baseline,说明ERICA无论是通过实体级还是关系级对比学习,都能更好地表示实体并区分实体。
问答
问答的目的是在给定问题的文本中提取出一个特定的回答范围。该部分选择了在Multi-choice QA和Extractive QA两种模式上进行实验。我们测试训练集的多个分区。
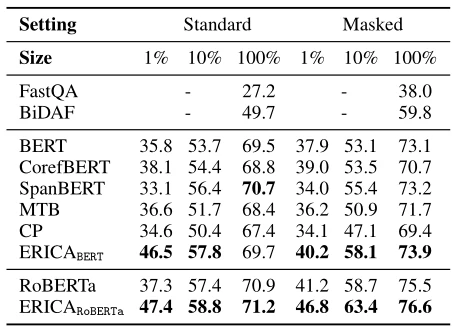
Multi-choice QA要求模型在阅读多个文档并进行多跳推理后回答实体的特定属性。首先,将问题和文档连接成一个长序列,然后找出文档中出现的所有实体将它们进行编码,编码后应用平均池来获得全局实体表示。最后,在实体表示的基础上使用分类器进行预测。FastQA[6]、BiDAF[7]两个广泛的问答系统被作为baseline,从表4所列的结果中,我们可以观察到ERICA在两种设置下都优于基线,这表明ERICA可以更好地理解文档中的实体及其关系,并根据查询提取真实答案。掩蔽设置的显著改进也表明ERICA可以更好地执行多跳推理,从上下文合成和分析信息。
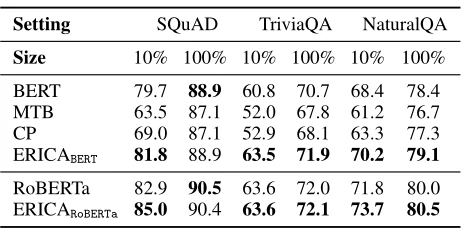
Extractive QA采用了三个广泛使用的数据集:SQuAD、TriviaQA和NaturalQA来评估各个领域的ERICA。该部分实验从数据集中设置测试集和训练集并遵循BERT的QA设置,即把给定的问题和段落连接成一个长序列,通过PLM对序列进行编码并采用两个分类器来预测答案的开始和结束索引。从表5所列的结果中,我们可以观察到ERICA优于所有基线,这表明通过实体和关系理解的增强ERICA更能够捕获文本中的关系事实和合成实体信息。
结论
在这篇文章中,我们提出了一个通用的PLM框架ERICA,这个框架通过对比学习提高实体和关系的理解。论文还证明了ERICA在几个自然语言处理任务中的有效性,包括关系抽取,实体类型和问题回答。实验结果表明,ERICA优于所有基线,特别是在低资源设置下,这意味着ERICA可以帮助PLM更好地捕获文本中的关系事实,并合成实体及其关系的信息。
总结与思考
- 对比学习是自监督的一种学习方式,也就是意味着它会减少对标注数据的依赖。本篇论文使用的对比学习方法是在基于开源数据集维基百科上进行训练的,也就是说拥有较为充足的已标注的数据来对对比学习的结果进行评估。但是在垂直领域上(例如医疗、教育等)往往缺乏专业标注数据,这就会导致无法对学习结果进行评估。虽然PLM已经被广泛应用,但是在我们使用在特定领域数据上时,就不得不去考虑有关领域迁移的相关影响。
- 在远程监督数据构建的工作中,论文明确提到构建的数据的评估结果是由人工评估的。如果在现实资源比较欠缺的情况下,这也会消耗大量的人力。但是对于已拥有行业的外部知识图谱作为指导的情况下,那么该部分的工作量将会有一定的减少。
- 本篇论文可以帮助我们实现在文档级的文本中进行实体识别和关系推理,但是论文方法目前是面向英文文本实现的,如果想要面向中文文本识别我们就要考虑输入的变化,同时也可以增加针对中文的基于文字特征方法来作为实体识别创新点进行切入,也可以引入中文的逻辑推理方法来对关系识别来进行改进或者创新。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10315
[1]Y uan Y ao, Deming Y e, Peng Li,and et al. 2019.DocRED: A large-scale document-level relation extraction dataset. InProceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, V olume 1: Long Papers, pages 764–777.
[2]Jacob Devlin, Ming-Wei Chang, Kenton Lee, ,and et al.2018.BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, V olume 1 (Long and Short Papers), pages 4171–4186.
[3]Yinhan Liu, Myle Ott, Naman Goyal,and et al. 2019.RoBERTa: A robustly optimized BERT pretraining approach.CoRR, abs/1907.11692.
[4]Michael McCloskey and Neal J Cohen. 1989.Catastrophic interference in connectionist networks: the sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier.
[5]Hao Peng, Tianyu Gao, Xu Han,and et al. 2020.Learning from context or names? an empirical study on neural relation extraction. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3661–3672,Online. Association for Computational Linguistics.
[6]Dirk Weissenborn, Georg Wiese, and Laura Seiffe. 2017.Making neural QA as simple as possible but not simpler. InProceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 271–280. Association for Computational Linguistics.
[7]Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi,and et al. 2016.Bidirectional attention flow for machine comprehension. InProceedings of 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24, 2017,Conference Track Proceedings.
论文下载地址:https://arxiv.org/abs/2012.15022
论文源码地址:https://github.com/thunlp/ERICA