本文将阅读参考2020年发表的一篇综述A Survey on 3D Skeleton-Based Action Recognition Using Learning Method[82],结合阅读过的论文和所做实验,对深度学习骨架动作识别方法进行梳理总结,并构思之后的研究方法。
骨架动作识别
动作识别作为计算机视觉中极其重要的组成部分和最活跃的研究问题,已经被研究了几十年。人类依靠动作来处理事务和表达情感,应用领域广阔,如智能监控系统、人机交互、虚拟现实、机器人等[1]-[5]。
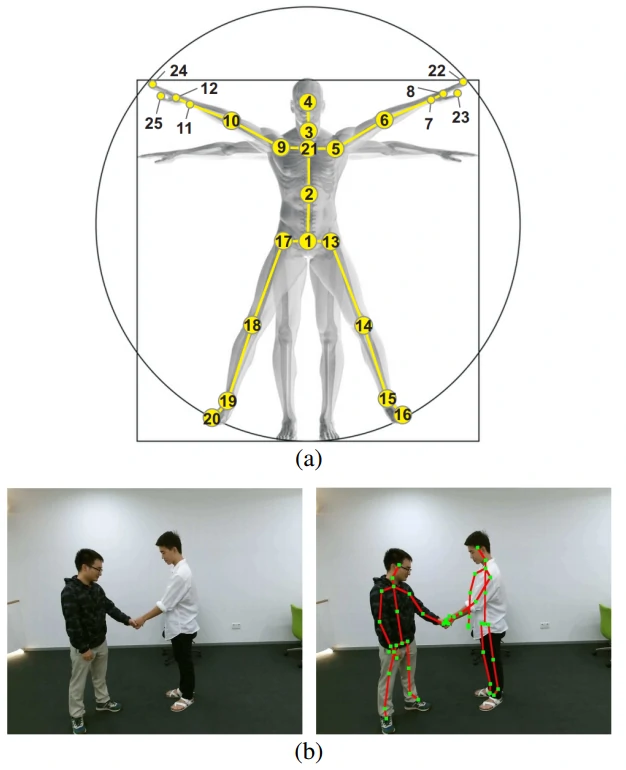
通常,在此任务中使用 RGB 图像序列 [6]-[8]、深度图像序列 [9]、[10]、视频或这些模态的某种融合形式(例如 RGB + 光流)[11]-[15],并且通过各种技术也取得了杰出的成果。然而,**与骨骼数据(一种人体关节和骨骼的拓扑表示)相比,以前的那些模态更消耗算力。面对复杂的背景, 涉及身体尺度的变化条件,视角变化和移动速度等情况时缺乏鲁棒性。此外,像 Microsoft Kinect [17] 和先进人体姿态估计算法 [18]-[20] 等传感器也可以更轻松地获得准确的 3D 骨架数据 [21]**。图1 展示了骨架图数据的可视化结果。
与其他模态数据相比具有的优势,骨架序列还有如下三个主要的特点:
- 空间信息,关节节点与其相邻节点之间存在很强的相关性, 帧内骨架数据中存在丰富的身体结构信息。
- 时间信息,具有帧间信息,强时间相关性。
- 时空共现信息,考虑关节和骨骼空间域和时间域之间的共现关系。
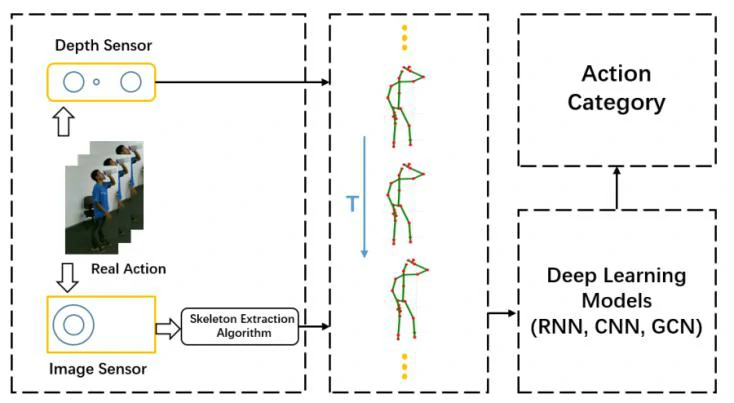
早期机器学习,手工提取特征的方法只在一些特定数据集上表现良好,算法难以推广或应用到更广泛的领域。 随着深度学习方法在其他计算机视觉任务上的发展和先进表现,使用骨架数据的RNN,CNN和GCN也开始出现。图 2 显示了使用深度学习方法从原始 RGB 序列或视频到最终得到动作类别的基于 3D 骨架的动作识别的一般流程。
基于RNN的方法
在基于RNN的方法中,RNN内部的递归结构是通过将前一时间的输出作为当前时间的输入来建立的[40],这是一种处理顺序数据的有效方法,骨架序列是关节坐标的自然时间序列,这可以被视为序列向量,而RNN本身就适合于处理时间序列数据。此外,为了进一步改善学习到的关节序列的时序上下文信息,一些别的RNN方法(LSTM,GRU)也被用到骨架行为识别中。该综述也从三方面指出了RNN所存在的问题。
第一个方面,时空建模,可以看作是动作识别任务中的原理。由于基于 RNN 架构的空间建模能力弱,一些相关方法的性能通常无法获得有竞争力的结果[41]-[43]。
第二个方面,网络结构有待改进。尽管 RNN 的性质适用于序列数据,但众所周知的梯度爆炸和消失问题是不可避免的。 LSTM 和 GRU 可能在一定程度上削弱了这些问题,但是,tanh和 sigmoid 激活函数可能会导致梯度衰减。
第三个方面,数据驱动方面。考虑到并非所有关节都为动作分析提供信息,**[51] 将全局上下文感知注意力添加到 LSTM 网络,它选择性地关注骨架序列中的带有信息的关节点**。此外,由于数据集或深度传感器提供的骨架并不完美,会影响动作识别任务的结果,因此[52]将骨架变换到另一个坐标系中,以实现对缩放、旋转和平移的鲁棒性,然后从转换后的数据中提取运动特征,而不是将原始骨架数据发送到 LSTM。
基于CNN的方法
与 RNN 不同,CNN 模型可以高效、轻松地学习高级语义线索,其天生具备出色的提取高级信息的能力。然而,CNNs 通常专注于基于图像的任务,而基于骨架序列的动作识别任务无疑是一个强时间依赖问题。因此,如何在基于 CNN 的架构中平衡和更充分地利用空间和时间信息仍然具有挑战性。
通常,为了满足 CNN 输入的需要,将 3D 骨架序列数据从向量序列转换为伪图像。然而,同时具有空间和时间信息的相关表示通常并不容易,因此许多研究人员将骨骼关节编码为多个 2D 伪图像,然后将它们输入 CNN 以学习有用的特征 [53]、[54]。但是这样只是简单地将时空信息编码为行和列,因此,只有卷积核内的相邻关节才会学习到共生特征,也就是说,一些与所有关节相关的潜在关联可能会被忽略,因此 CNN 无法学习相应的有用特征。
除了 3D 骨架序列的表示外,基于 CNN 的技术还存在一些其他问题,例如模型的大小和速度 [3]、CNN 的架构(双流或三流 [62])、遮挡、视点变化等[2]、[3]。所以使用CNN的基于骨架的动作识别仍然是一个待研究的问题。
基于GCN的方法
受人类 3D 骨骼数据自然是拓扑图而不是基于 RNN 或基于 CNN 的方法处理的序列向量或伪图像这一事实的启发。因为骨架数据本身就是一个自然的拓扑图数据结构(关节点和骨骼可以被视为图的节点和边),而不是图像或序列那样的格式。
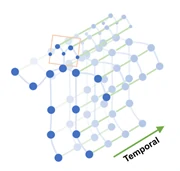
Sijie 和 Yuanjun [31] 首次提出了一种新的基于骨架的动作识别模型——时空图卷积网络模型(ST-GCN,Spatial Temporal Graph Convolution Networks for Skeleton Based Action Recognition)。 如图3所示,该模型是建立在一系列骨架图之上的,其中每个节点对应于人体的一个关节。有两种类型的边,一种是符合关节自然连通性的空间边,另一种是跨越连续时间步长连接同一关节的时间边。并在此基础上构造了多个时空图卷积层,实现了信息在时空维度上的集成。ST-GCN网络核心是GCN和TCN模块组成。GCN对空间维度的数据进行卷积操作,帮助学习了到空间中相邻关节的局部特征。TCN使用传统的卷积层完成时间卷积操作,对时间维度的数据进行卷积操作,学习时间维度关节点变化特征。
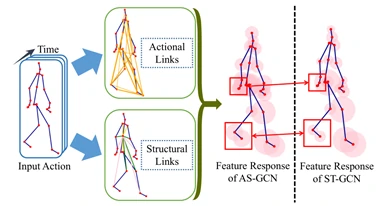
根据这项工作,使用 GCN 进行基于骨架的动作识别引起了人们的注意,因此最近做了许多相关工作。最常见的研究集中在有效利用骨架数据 [68]、[78],Maosen 和 Siheng [68] 提出的 AS-GCN (Action Structural Graph Convolutional Networks)不仅可以识别一个人的动作,还可以使用多任务学习策略输出对主体下一个可能姿势的预测。这项工作中构建的图可以通过两个名为 Actional Links 和 Structural Links 的模块捕获关节之间更丰富的依赖关系。如图4所示。
根据之前的介绍和讨论,最常见的关注点仍然是数据驱动,我们想要的只是获取3D骨架序列数据背后的潜在信息, “如何挖掘潜在信息?”,这仍然是一个开放的具有挑战性的问题。尤其是骨骼数据本身是一个时空耦合的,而且,在将骨骼数据转化为图形时,如何确定关节和骨骼之间的连接方式。
骨架序列数据集
骨架序列数据集主要有MSRAAction3D[79],3D Action Pairs[80],MSR Daily Activity3D[39]等,这些数据都在许多综述中有过分析[27,35,36],所以这里主要分析如下**两个数据集NTU-RGB+D[22]和NTU-RGB+D 120[81]**。数据集在2016年提出,包含56880个视频samples,这些样本都是从一个大规模骨架行为识别数据集Microsoft Kinect v2上收集的,NTU-RGB+D提供了每个人、每个动作的25个关节的3D空间坐标。在该数据集上,建议使用两种协议对提出的方法进行评估:跨子类Cross-Subject和跨视角Cross-View。其中Cross-Subject包含40320个训练样本和16560个验证样本,划分规则是根据40个subjects进行的;其中Cross-View将camera2和3作为训练集(37920个样本),将camera1作为验证集(18960个样本)。近来,提出了NTU-RGB+D的扩展版本NTU-RGB+D 120,包含120个动作类别和114480个骨架序列,视角点是155个。
除了该综述提及的数据集外,Kinects 也是一个常见大型行为识别数据集,Kinetics视频来源于YouTube,包含多达 650,000 个视频剪辑的大规模、高质量数据集,涵盖 400/600/700 人类行为类,具体取决于数据集版本。这些视频包括演奏乐器等人与物体之间的互动,以及握手和拥抱等人与人之间的互动。每个动作类至少有 400/600/700 个视频剪辑。每个剪辑都带有一个动作类的人工注释,持续大约 10 秒。
总结和讨论
在综述中,分别基于三种主要的神经网络架构介绍了基于 3D 骨架序列数据的动作识别。动作识别的意义、骨架数据的优越性以及不同深度架构的属性都得到了强调。
在基于RNN的方法中,骨架序列是关节坐标的自然时间序列,这可以被视为序列向量,而RNN本身就适合于处理时间序列数据。此外,为了进一步改善学习到的关节序列的时序上下文信息,LSTM和GRU也被用到骨架行为识别中。当使用CNN来处理这一基于骨架的任务的时候,可以将其视为基于RNN方法的补充,因为CNN结构能更好地捕获输入数据的空间潜在信息,而基于RNN的方法正缺乏空间信息的构建。最后,相对新的方法图卷积神经网络GCN也有用于骨架数据处理中,因为骨架数据本身就是一个自然的拓扑图数据结构(关节点和骨骼可以被视为图的节点和边,而不是图像或序列那样的格式。
我们得出结论,在三种不同的学习结构中,最常见的仍然是从 3D 骨骼中获取有效信息,而GCN中基于拓扑图的方法,是人体骨骼关节最自然的表示。 NTU-RGB+D 数据集上的表现也证明了这一点。然而,这并不意味着基于 CNN 或 RNN 的方法不适合此任务。相反,当对这些模型采取一些新的策略时,例如多任务学习策略,将在跨视图或跨子类评估中进行超越改进。然而,NTU-RGB+D 数据集的准确度非常高,很难再进一步提高。所以也应该关注一些更难的数据集,比如增强的 NTU-RGB+D 120 数据集。
至于未来的方向,长期动作识别、更高效的3D骨架序列表示、实时操作仍然是开放的问题,此外,无监督或弱监督的策略以及零样本学习也可能成为引领方向。
个人总结思考
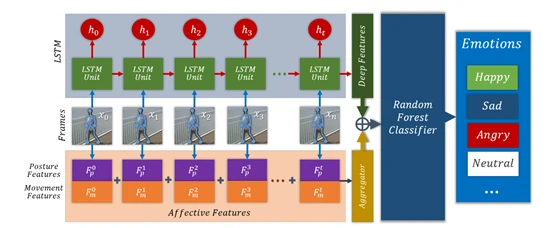
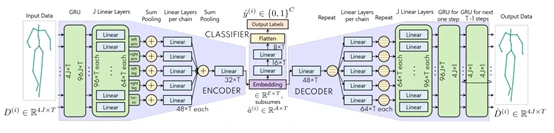
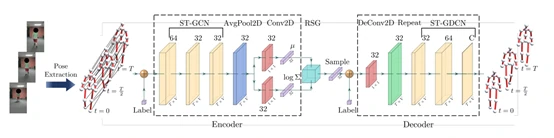
- 在过往复现过的步态情绪识别的论文中,2019 年 Identifying Emotions from Walking Using Affective and Deep Features[83] 采用RNN中LSTM的方法,如图5所示。STEP[84](AAAI 2020)采用了RNN中GRU的方法,如图6所示。Take an Emotion Walk[85](ECCV 2020)采用了GCN中ST-GCN的方法,如图7所示。
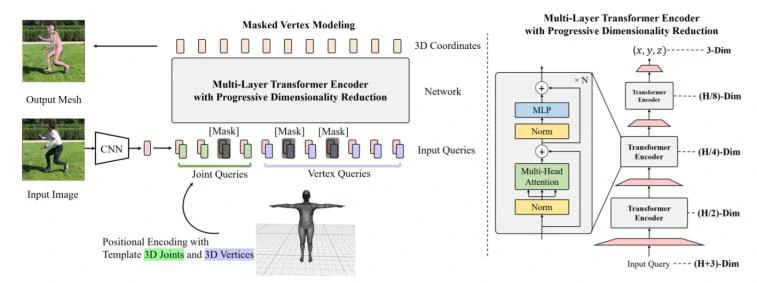
- 最近深度学习中处理骨架序列数据除了该综述所提及的三种方法(CNN,RNN,GCN)之外,Transformer模型在相关任务上得到了应用并取得了不错的效果,可以借鉴在动作识别任务上。Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。例如微软在CVPR 2021 发表的文章End-to-End Human Pose and Mesh Reconstruction with Transformers[86]首次将Transformer引入人体形状重建任务中,提出MEsh TRansfOrmer 网络,如图8所示,在多个数据集上表现出了强大的可解释性和精度。
在提取时域信息时,得益于 self-attention 机制,Transformer 能捕捉长时序输入的内在关联,且不受制于其距离。相比较于ST-GCN模型中采用的时序卷积TCN(Temporal convolutional network),其学习时序信息,表现往往受制于感受野的大小[87]。今后研究,可以对基于ST-GCN类方法的TCN模块进行改进,应用Transformer更好地把握时域全局信息。
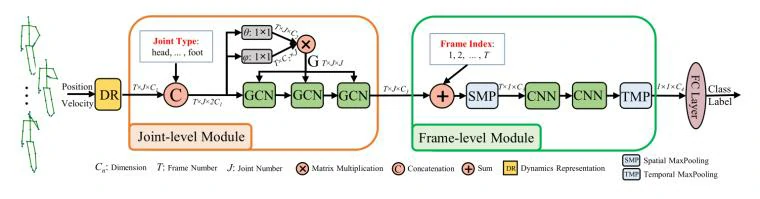
除了单独使用某种网络,也可以混合使用。CVPR 2020 发表的一篇文章Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition ,提出端到端语义引导神经网络 (SGN) ,使用GCN加CNN的结构可以获取多种模态信息 。网络结构如图9所示。
- 今后研究,可以采用多任务学习或多网络分支的方法,对于不同模型的优势进行整合,如在提取单帧空间信息时,同时使用GCN和Transformer,再将两部分信息整合起来。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10234