背景
卷积神经网络(Convolution Neural Network, CNN)因其强大的特征提取能力而被广泛地应用到计算机视觉的各个领域,其中卷积层和池化层是组成CNN的两个主要部件。理论上来说,网络可以在不对原始输入图像执行降采样的操作,通过堆叠多个的卷积层来构建深度神经网络,如此一来便可以在保留更多空间细节信息的同时提取到更具有判别力的抽象特征。然而,考虑到计算机的算力瓶颈,通常都会引入池化层,来进一步地降低网络整体的计算代价,这是引入池化层最根本的目的。
作用
池化层大大降低了网络模型参数和计算成本,也在一定程度上降低了网络过拟合的风险。概括来说,池化层主要有以下五点作用:
- 增大网络感受野。
- 抑制噪声,降低信息冗余。
- 降低模型计算量,降低网络优化难度,防止网络过拟合。
- 使模型对输入图像中的特征位置变化更加鲁棒。
对于池化操作,大部分人第一想到的可能就是Max_Pooling和Average_Pooling,但实际上卷积神经网络的池化方法还有很多,本文将对业界目前所出现的一些池化方法进行归纳总结:
池化大盘点
Max Pooling(最大池化)
定义

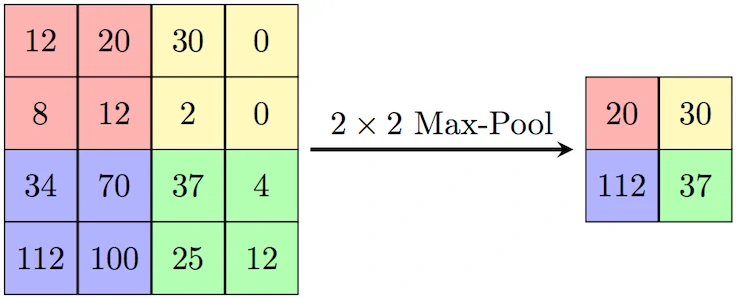
解说
对于最大池化操作,只选择每个矩形区域中的最大值进入下一层,而其他元素将不会进入下一层。所以最大池化提取特征图中响应最强烈的部分进入下一层,这种方式摒弃了网络中大量的冗余信息,使得网络更容易被优化。同时这种操作方式也常常丢失了一些特征图中的细节信息,所以最大池化更多保留些图像的纹理信息。
Average Pooling(平均池化)
定义

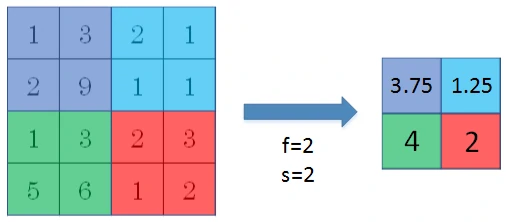
解说
平均池化取每个矩形区域中的平均值,可以提取特征图中所有特征的信息进入下一层,而不像最大池化只保留值最大的特征,所以平均池化可以更多保留些图像的背景信息。
Global Average Pooling(全局平均池化)
论文地址: https://arxiv.org/pdf/1312.4400.pdf%20http://arxiv.org/abs/1312.4400
代码链接: https://worksheets.codalab.org/worksheets/0x7b8f6fbc6b5c49c18ac7ca94aafaa1a7
背景
在卷积神经网络训练初期,卷积层通过池化层后一般要接多个全连接层进行降维,最后再Softmax分类,这种做法使得全连接层参数很多,降低了网络训练速度,且容易出现过拟合的情况。在这种背景下,M Lin等人提出使用全局平均池化**Global Average Pooling[1]**来取代最后的全连接层。用很小的计算代价实现了降维,更重要的是GAP极大减少了网络参数(CNN网络中全连接层占据了很大的参数)。
定义

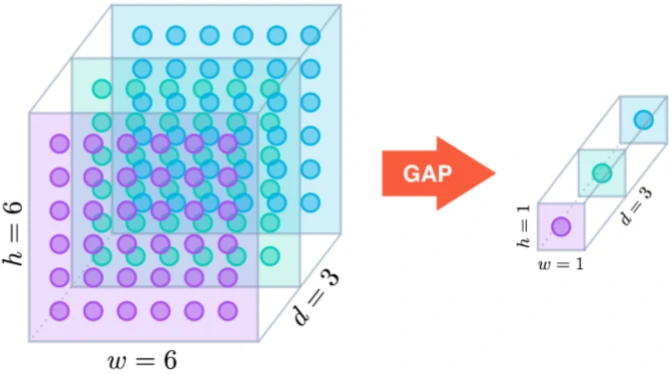
解说
作为全连接层的替代操作,GAP对整个网络在结构上做正则化防止过拟合,直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。除此之外,使用GAP代替全连接层,可以实现任意图像大小的输入,而GAP对整个特征图求平均值,也可以用来提取全局上下文信息,全局信息作为指导进一步增强网络性能。
Mix Pooling(混合池化)
论文地址: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.678.7068&rep=rep1&type=pdf
定义

解说
混合池化优于传统的最大池化和平均池化方法,并可以解决过拟合问题来提高分类精度。此外该方法所需要的计算开销可忽略不计,而无需任何超参数进行调整,可被广泛运用于CNN。
Stochastic Pooling(随机池化)
论文地址: https://arxiv.org/pdf/1301.3557
代码链接: https://github.com/szagoruyko/imagine-nn
定义
随机池化**Stochastic Pooling[3]**是Zeiler等人于ICLR2013提出的一种池化操作。随机池化的计算过程如下:
- 先将方格中的元素同时除以它们的和sum,得到概率矩阵。
- 按照概率随机选中方格。
- pooling得到的值就是方格位置的值。
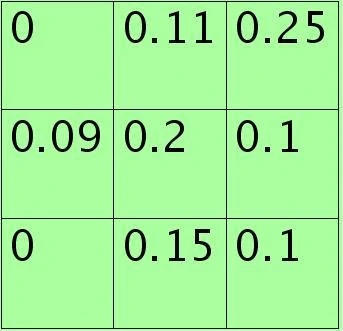
假设特征图中Pooling区域元素值如下(参考Stochastic Pooling简单理解):
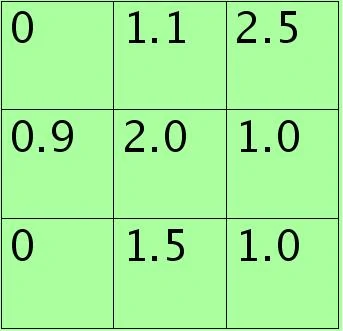
3×3大小的,元素值和sum=0+1.1+2.5+0.9+2.0+1.0+0+1.5+1.0=10。方格中的元素同时除以sum后得到的矩阵元素为:
每个元素值表示对应位置处值的概率,现在只需要按照该概率来随机选一个,方法是:将其看作是9个变量的多项式分布,然后对该多项式分布采样即可,theano中有直接的multinomial()来函数完成。当然也可以自己用0-1均匀分布来采样,将单位长度1按照那9个概率值分成9个区间(概率越大,覆盖的区域越长,每个区间对应一个位置),然随机生成一个数后看它落在哪个区间。比如如果随机采样后的矩阵为:
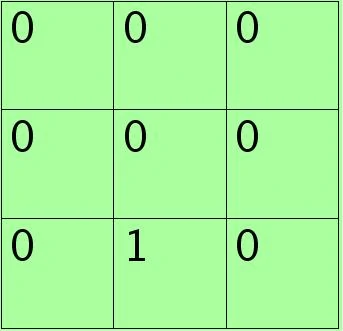
则这时候的poolng值为1.5。使用stochastic pooling时(即test过程),其推理过程也很简单,对矩阵区域求加权平均即可。说明此时对小矩形pooling后的结果为1.625。在反向传播求导时,只需保留前向传播已经记录被选中节点的位置的值,其它值都为0,这和max-pooling的反向传播非常类似。本小节参考**Stochastic Pooling简单理解[4]**。
解说
随机池化只需对特征图中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大,而不像max-pooling那样,永远只取那个最大值元素,这使得随机池化具有更强的泛化能力。
Power Average Pooling(幂平均池化)
定义

Detail-Preserving Pooling(DPP池化)
论文地址: https://openaccess.thecvf.com/content_cvpr_2018/papers/Saeedan_Detail-Preserving_Pooling_in_CVPR_2018_paper.pdf
代码链接: https://github.com/visinf/dpp
为了降低隐藏层的规模或数量,大多数CNN都会采用池化方式来减少参数数量,来改善某些失真的不变性并增加感受野的大小。由于池化本质上是一个有损的过程,所以每个这样的层都必须保留对网络可判别性最重要的部分进行激活。但普通的池化操作只是在特征图区域内进行简单的平均或最大池化来进行下采样过程,这对网络的精度有比较大的影响。基于以上几点,Faraz Saeedan等人提出一种自适应的池化方法-DPP池化**Detail-Preserving Pooling[6],该池化可以放大空间变化并保留重要的图像结构细节,且其内部的参数可通过反向传播加以学习。DPP池化主要受Detail-Preserving Image Downscaling[7]**的启发。

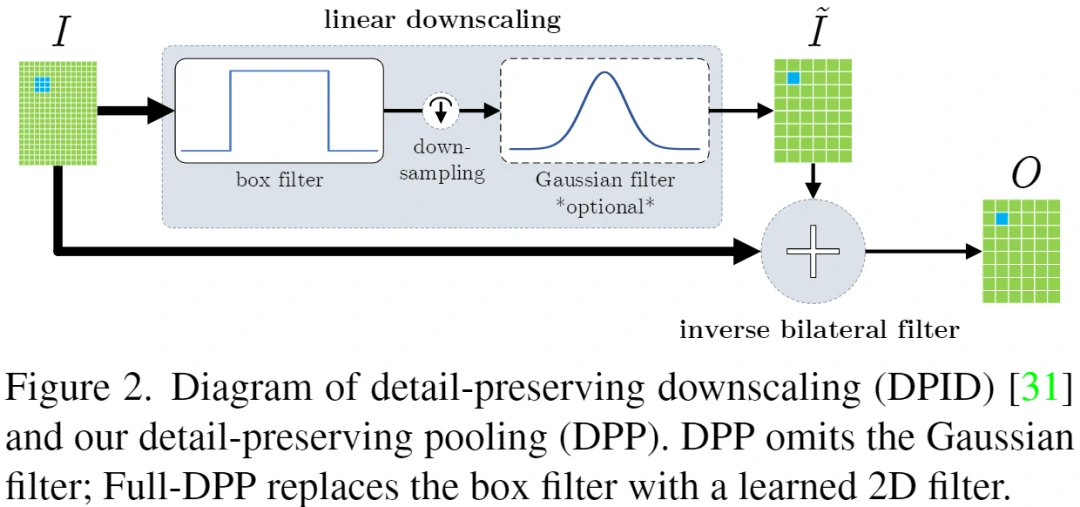
如下图8展示了DPID的滤波图,与普通双边滤波器不同,它奖励输入强度的差异,使得与I的差异较大的像素值贡献更大。


解说
DPP池化允许缩减规模以专注于重要的结构细节,可学习的参数控制着细节的保存量,此外,由于细节保存和规范化相互补充,DPP可以与随机合并方法结合使用,以进一步提高准确率。
Local Importance Pooling(局部重要性池化)
论文地址: http://openaccess.thecvf.com/content_ICCV_2019/papers/Gao_LIP_Local_Importance-Based_Pooling_ICCV_2019_paper.pdf
代码链接: https://github.com/sebgao/LIP
背景
CNN通常使用空间下采样层来缩小特征图,以实现更大的接受场和更少的内存消耗,但对于某些任务而言,这些层可能由于不合适的池化策略而丢失一些重要细节,最终损失模型精度。为此,作者从局部重要性的角度提出了局部重要性池化**Local Importance Pooling[8]**,通过基于输入学习自适应重要性权重,LIP可以在下采样过程中自动增加特征判别功能。
定义

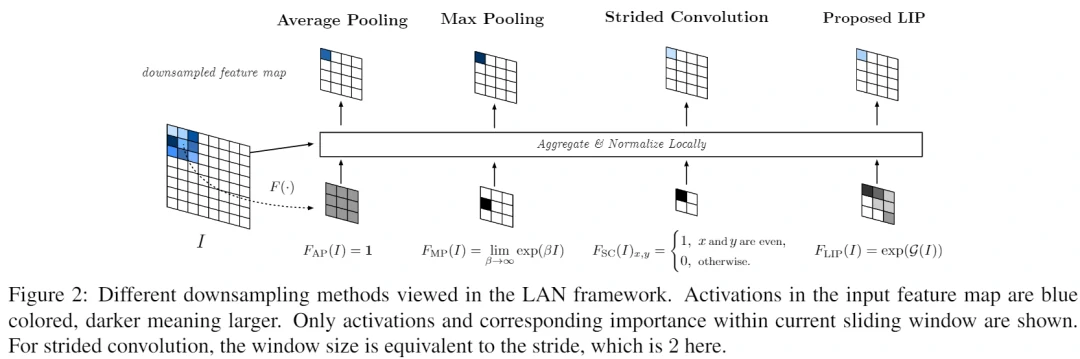
图中分别对应了平均池化,最大池化和步长为2的卷积。首先最大池化对应的最大值不一定是最具区分力的特征,并且在梯度更新中也难以更新到最具区分力的特征,除非最大值被抑制掉。而步长为2的卷积问题主要在于固定的采样位置。
因此,合适的池化操作应该包含两点:
a. 下采样的位置要尽可能非固定间隔
b. 重要性的函数F需通过学习获得
- Local Importance-based Pooling
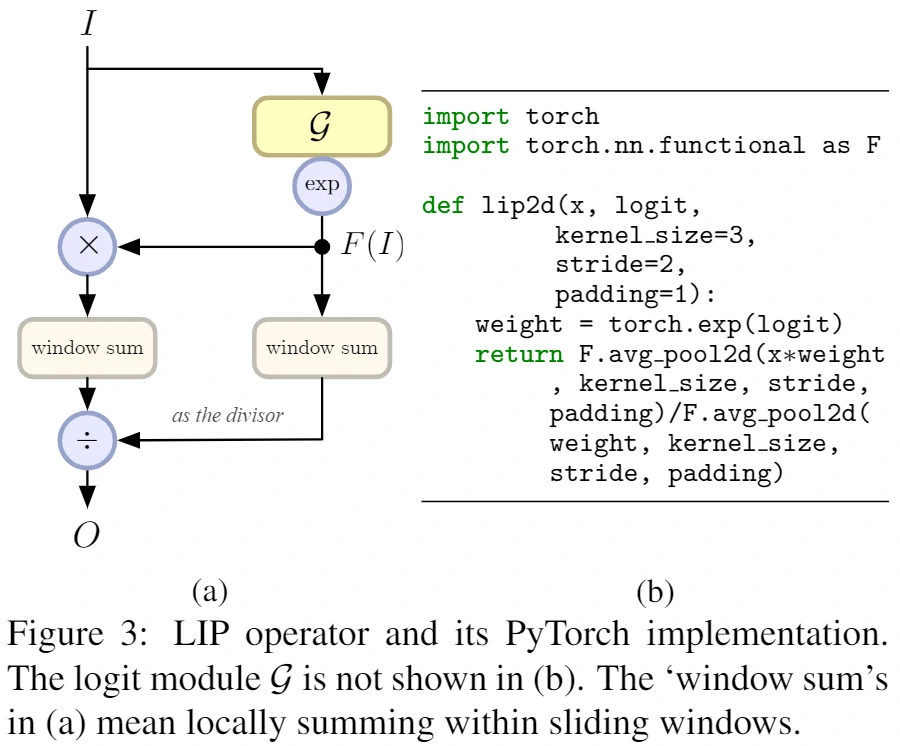

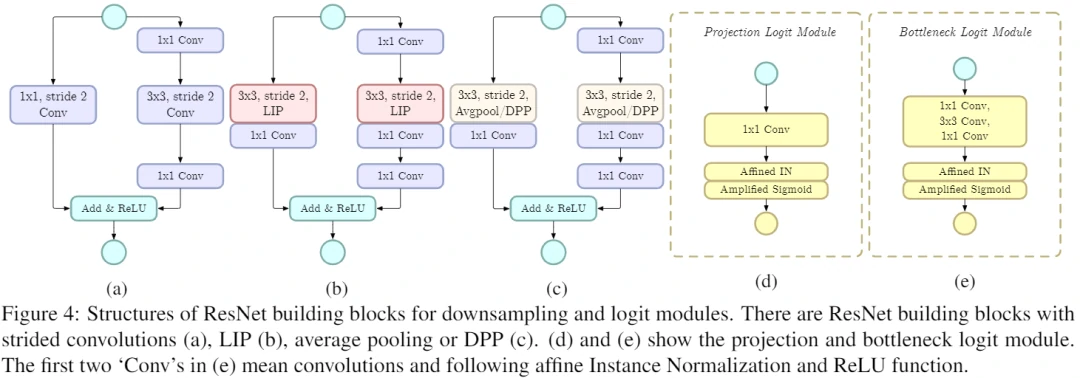
解说
Local Importance Pooling可以学习自适应和可判别性的特征图以汇总下采样特征,同时丢弃无信息特征。这种池化机制能极大保留物体大部分细节,对于一些细节信息异常丰富的任务至关重要。
Soft Pooling(软池化)
论文地址: https://arxiv.org/pdf/2101.00440
代码链接: https://github.com/alexandrosstergiou/SoftPool
定义
- SoftPool的计算流程如下:
a. 特征图透过滑动视窗来框选局部数值
b. 框选的局部数值会先经过指数计算,计算出的值为对应的特征数值的权重
c. 将各自的特征数值与其相对应的权重相乘
d. 最后进行加总
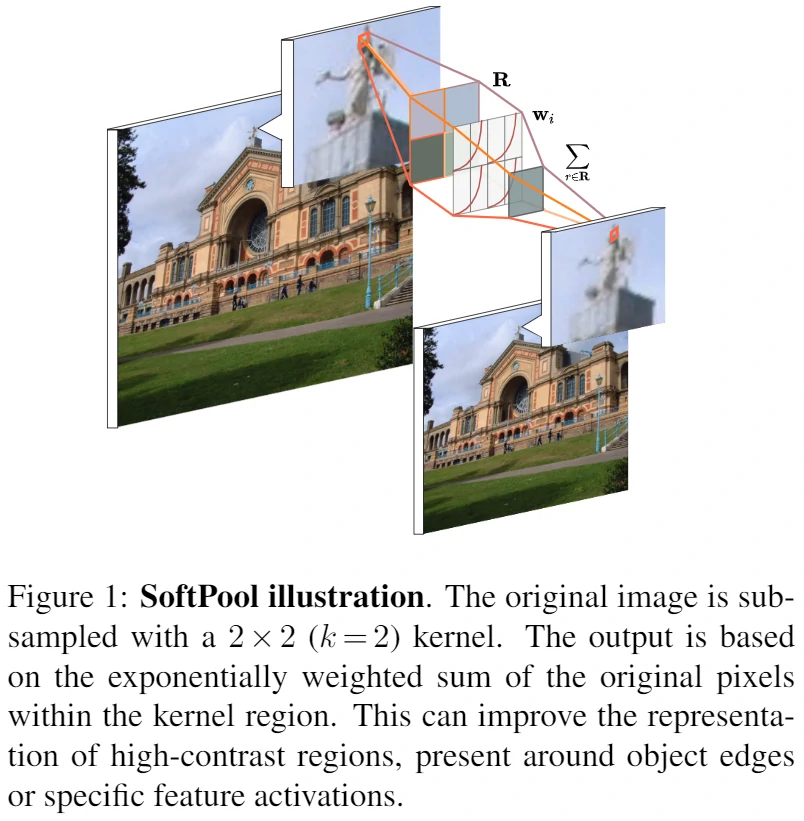

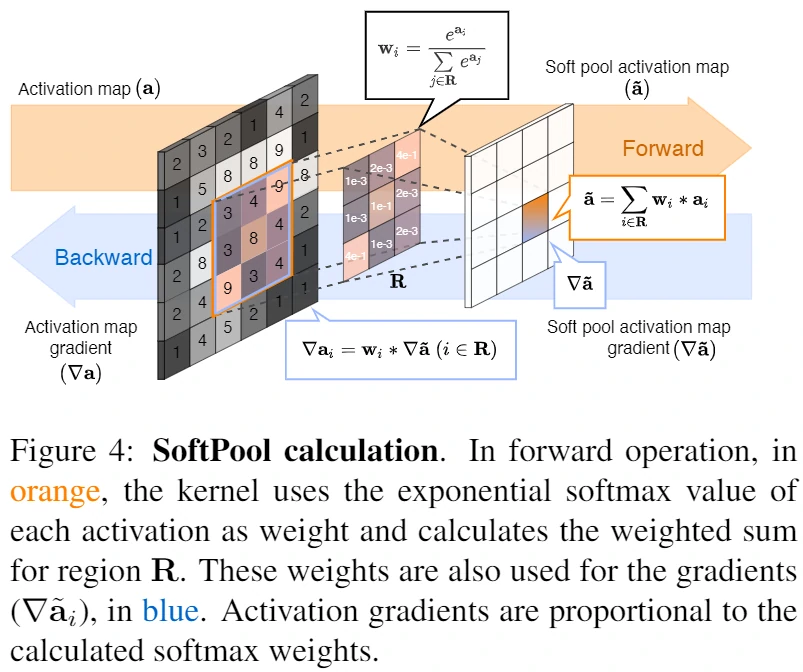
解说
作为一种新颖地池化方法,SoftPool可以在保持池化层功能的同时尽可能减少池化过程中带来的信息损失,更好地保留信息特征并因此改善CNN中的分类性能。大量的实验结果表明该算法的性能优于原始的Avg池化与Max池化。随着神经网络的设计变得越来越困难,而通过NAS等方法也几乎不能大幅度提升算法的性能,为了打破这个瓶颈,从基础的网络层优化入手,不失为一种可靠有效的精度提升手段。
参考资料
https://mp.weixin.qq.com/s?__biz=MzU1MzY0MDI2NA==&mid=2247488307&idx=1&sn=128c7eb852e09cf827c13c7791be45aa
[1] Network in Network.
[2] Mixed pooling for convolutional neural networks.
[3] Stochastic pooling for regularization of deep convolutional neural networks.
[4] https://www.cnblogs.com/tornadomeet/archive/2013/11/19/3432093.html.
[5] Signal recovery from pooling representations.
[6] Detail-preserving pooling in deep networks.
[7] Rapid, detail-preserving image downscaling.
[8] LIP: Local Importance-based Pooling.
[9] Refining activation downsampling with SoftPool.