Abstract 摘要
情绪是多通道的过程扮演着重要的角色在我们的日常生活。识别情绪变得越来越重要在广泛的应用领域,如医疗、教育、人机交互、虚拟现实、智能代理、娱乐等等。
面部宏表情macro-expressions或强烈的面部表情识别情绪状态是最常见的形式。然而,由于面部表情可以主动控制,它们可能不会准确地代表情绪状态。早些时候的研究表明,面部微表情比面部宏表情揭示情绪更可靠。它们是微妙的,无意识的运动响应外界刺激,无法控制。
本文提出了使用面部微表情结合大脑和更可靠的检测潜在的情感生理信号。模型测量唤醒和效价水平从面部表情、脑电图(EEG)信号、皮肤电反应(GSR)和光谱分析(PPG)信号。然后评估模型使用DEAP数据集和基于subject-independent方法自采数据集。最后讨论结果、工作的局限性,如何克服这些限制,还讨论未来的发展方向使用面部表情和情感生理信号识别。
Introduction 介绍
人类的情绪涉及众多的外部和内部活动,在我们的日常生活中起着至关重要的作用。面部表情、语言和身体姿态是受情绪影响的一些外部活动。
| Author | Effects |
|---|---|
| Verma and Tiwary (2014) | 大脑活动、心率、血压、呼吸频率、体温和皮肤传导的变化是内部情绪影响的例子*。 |
| Zheng et al. (2018) | 如今,在现代社会中,我们被数字字符、智能设备和计算机所包围。有必要与这些系统进行更好的互动,在许多人与人、人与计算机的互动中,识别情感变得越来越重要*。 |
| Khalfallah和Slama (2015) | 如果我们的远程互动、治疗、咨询或培训课程配备了情绪识别系统,其效果就会得到改善。例如,在远程电子学习中识别情绪*可以提高学习的绩效。 |
| Piumsomboon et al. (2017) | 在移情计算的应用中,目标是测量一起举行远程会议的人的情绪,并利用结果来改善远程通信*。 |
| Author | Effects |
|---|---|
| Huang et al. (2016) | 创建具有情感识别能力的智能代理可能对医疗保健、教育、娱乐、犯罪调查和其他领域有帮助*。 |
| Marcos-Pablos et al. (2016) | 它可以有利于智能助手*测量用户的情感。 |
| Bartlett et al. (2003) | 它可以有利于人形机器人*能够测量用户的情感。 |
| Zepf et al. (2020) | *讨论emotion-aware系统在汽车上的重要性。 |
| Hu et al. (2021) | *提出了一个对话代理,它可以根据语音的声学特征来识别情绪。 |
| Chin et al. (2020) | *对话代理和人之间的移情可以改善攻击性行为。 |
| Schachner et al. (2020) | 讨论了为健康护理开发智能对话代理,特别是针对慢性病。 |
| Aranha et al. (2019) | *回顾了在健康、教育、安全和艺术等不同领域中能够识别情绪的智能用户界面的软件。根据他们的评论,情绪识别经常被用于根据用户的情绪来调整声音、用户界面、图形和内容。 |
| Author | Effects |
|---|---|
| Sun et al. (2020) | 面部表情是最常用的输入模式之一,被分析用来识别情绪状态*。 |
| Samadiani et al. (2019) | 面部表情被用于许多人机交互应用中*。 |
| Li and Deng (2020) | 虽然研究表明,从面部表情中识别情绪的效果很好*。 |
| Hossain and Gedeon (2019) | 但在日常生活中使用这些方法面临一些挑战,因为它们可以被人类控制或伪造*。 |
| Weber et al. (2018); Li and Deng (2020) | 许多从面部表情中识别情绪的方法都是基于非自发的面部表情或夸张的面部表情的数据集,这并不能正确反映真实的情绪*。 |
| Zeng et al. (2008) | 在现实世界中,人们通常会表现出微妙的不自主的表情*或根据刺激的类型表现出强度较低的表情。 |
这些研究表明了开发和改进识别自发情绪的有效方法的重要性。
Recognizing Spontaneous Emotions 识别自发的情绪
文献中提出了三种主要的方法来识别现实世界中微妙的、自发的情绪:
- 从脸部提取不自主的表情
- 使用无法伪造的生理信号
- 使用各种输入模式的组合
Extracting Facial Micro-Expressions From Faces 从脸部提取面部微表情
在这种方法中,重点是提取面部微表情而不是面部宏观表情。
| Author | Effects |
|---|---|
| Ekman and Rosenberg (1997) | 面部宏观表情或强烈的面部表情是指面部的自愿性肌肉运动,这些运动是可以区分的,覆盖了面部的大部分区域,其持续时间在0.5到4秒之间*。 |
| Yan et al. (2013) | 相比之下,面部微表情指的是短暂的、非自愿的面部变化,如眉毛内侧的上扬或鼻子的皱褶,这些变化是对外部刺激的自发反应,通常在65至500毫秒的短时间内发生*。 |
| Takalkar et al. (2018) | 面部微表情很难伪造,可以用来检测真实的情绪*。 |
| Qu et al. (2016) | 这些表情持续时间短,动作细微,人类很难识别它们*。 |
图1显示了一些与面部宏观表情相比的面部微表情的例子
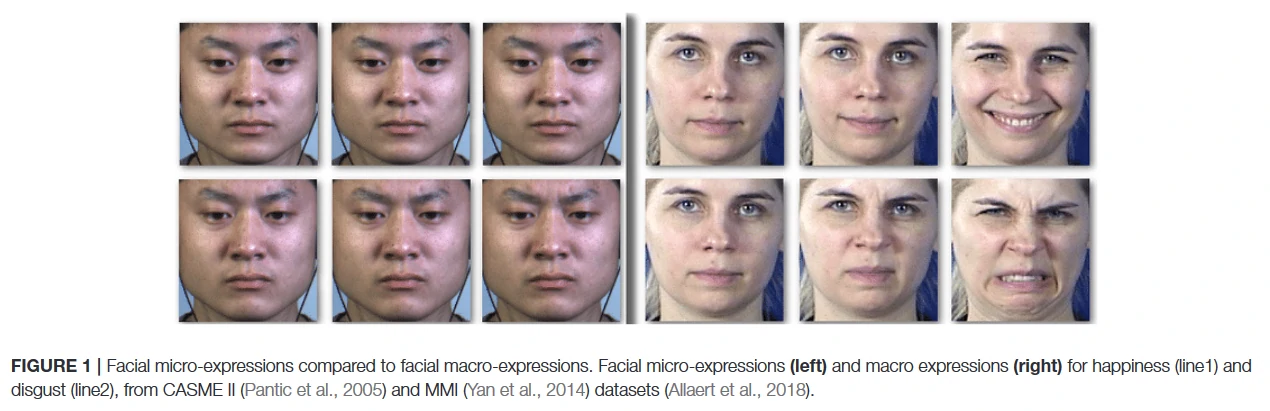
Using Physiological Signals That Cannot Be Faked 使用无法伪造的生理信号
这种方法依赖于难以伪造的生理反应,并提供对潜在情绪的更好理解。
| Author | Effects |
|---|---|
| Kreibig, 2010 | 这些反应来自中枢(大脑和脊髓)和自主神经系统(调节身体功能,如心率)*。 |
| Alarcao and Fonseca, 2017 | 脑电图(EEG)是测量大脑活动的方法之一,通常用于情绪研究*。 |
| Perez-Rosero et al., 2017; Setyohadi et al., 2018; Shu et al., 2018 | 皮肤电泳反应(GSR)和心率变异(HRV)也可以用来可靠地测量情绪状态,并被广泛用于情绪识别研究*。 |
| Wioleta, 2013 | 虽然EEG和生理信号更可靠,不能被人类控制或伪造*。 |
| Jiang et al., 2020 | 这些信号可能非常弱,容易被噪音污染*。 |
所以,只用生理信号来识别情绪是相当有挑战性的。
Using a Combination of Various Input Modalities 使用各种输入模式的组合
在这种方法中,各种模式被结合起来以克服每个单独模式的弱点。
| Author | Effects |
|---|---|
| Yazdani et al., 2012; Shu et al., 2018 | 结合不同的生理信号进行情感识别*。 |
| Busso et al., 2008; McKeown et al., 2011 | 只融合行为模式的方法已经被广泛探索*。 |
| Zheng et al., 2018; Huang et al., 2019; Zhu et al., 2020 | 最近一些研究试图通过利用生理和行为技术来改进情绪识别方法*。 |
| Koelstra and Patras, 2013; Huang et al., 2017; Zhu et al., 2020 | 许多研究使用面部表情和EEG信号的组合来实现这种改进*。 |
| Koelstra et al., 2011; Soleymani et al., 2011 | 通常,这些研究人员的工作是在受试者观看视频或看静态图像时收集的数据*。然而,人们在这些任务中往往不会表现出很多面部表情。因此,常规的面部表情策略可能无法准确识别情绪。 |
| Huang et al., 2016 | 有限的研究使用了面部微表情来代替面部宏观表情*,但这个领域仍然需要更多的研究和探索。 |
此外,根据Doma和Pirouz(2020)的研究,真正的情绪何时开始并不清楚。他们假设,在观看视频刺激的前几秒,参与者可能还处于之前的情绪状态。而在最后几秒钟,他们可能更沉浸在视频中,感受到真正的情感。这是因为他们在最后几秒钟更好地理解视频。他们发现,最后几秒钟的脑电图数据信息量更大,显示出更好的情绪预测结果。感受情绪最强烈的峰值时间受到许多因素的影响,如刺激流、参与者的个性或以前的经验。
Goals, Overview, and Contributions 目的、总览与贡献
本文假设:通过识别和分析每个刺激物中最情绪化的部分或出现情绪的时间,可以更好地理解身体对情绪的反应,并创建更强大的模型来识别情绪。
研究目的:通过将面部微表情策略与脑电图和生理信号相结合来改善情绪识别。
本文方法:首先对每个面部视频进行扫描,寻找大致表明出现情绪刺激的微表情。微表情窗口被用来大致确定情绪产生的时间。然后,分析每次试验中微表情出现前后的脑电和生理数据,与整个试验的分析进行比较。最后比较了这两种策略,并基于独立于主体的方法评估的方法。文章还使用DEAP数据集作为基准来评估的方法。作者进行了一项用户研究,在观看与DEAP数据集类似的视频任务时收集面部视频、EEG、PPG和GSR数据,但使用不同的传感器。
主要贡献:
- 将面部微表情与脑电图和生理信号相融合以识别情绪。
- 利用面部微表情来识别情绪刺激或更多信息期的数据,以提高识别精度。
- 使用低成本和开源的EEG采集设备创建一个新的多模态数据集用于情感识别。
Conclusions 结论
本文展示了如何将面部微表情与EEG和生理信号一起有效地用于识别情绪状态。
本文方法:
- 使用了面部微表情的情感识别,而不是结合生理模式的面部宏观表情的情感识别,这在识别真实情感方面更加可靠。
- 使用了面部微表情识别策略来大致确定数据中最具情感和信息的部分。
- 使用基于地标的发现策略来检测微表情,确定了每个试验的兴趣区域(ROI)。提取了微表情周围的几个帧,并将其输入到一个三维卷积网络。
- 从脑电图和生理数据中提取了一连串的特征向量,这些数据被划分为1秒的窗口。
- 为了从生理信号和EEG信号中提取时间特征,采用了LSTM。评估了用LSTM、SVM、KNN和RF分类器对ROI的分类与对所有数据的分类的比较。
- 本文的方法是基于独立于主体的方法进行评估的(subject-independent)。
本文效果:
- 根据结果与所有数据相比,可以通过使用一小部分数据获得类似甚至更好的准确性。
- 根据研究结果,面部微表情可以识别出具有足够信息和低噪音的数据中更多的情感部分。
- 本文使用一个低成本、开源的EEG采集设备来收集多模态的情绪数据。
- 根据DEAP数据集和自采数据评估了本文的方法。最后结合了多种模式,并发现融合它们的输出可以改善情绪识别。- 本文发现面部微表情比面部宏观表情方法更有效地检测出真实情绪。
未来工作:
- 由于OpenBCI硬件的高数据质量和易用性,文章希望在后续的研究中用OpenBCI的各种设置收集更多的数据。收集到的数据将被用于预训练即将到来的模型,以创建一个强大的模型来识别EEG数据中的情绪。
- 在获得发布数据集的伦理批准后,作者希望公开EEG和生理学数据。这将有助于研究人员训练更强大的情感识别模型。
- 想在未来研究更多的特征,看看改变特征集或使用更复杂的特征是否会改善LSTM方法的性能。
- 还想使用更复杂的融合策略来有效利用多模态传感器。
- 探索如何从更自然的头部运动中提取面部微表情(例如,不要求人们保持严肃)。
- 此外,在常规面部表情存在的情况下识别面部微表情,并探索如何将两者结合起来用于识别情绪,这将是非常有趣的。
- 希望可以将这种情绪识别方法纳入到医疗保健的应用中,如远程治疗课程,识别病人的情绪障碍,或创建智能助手来帮助病人或老人。
- 这种情感模型还可以用于我们与人类的日常互动中,比如加强远程会议,使远程互动更具有沉浸感
- 改善我们与虚拟代理和其他我们经常使用的互动设备的互动,让它们有能力识别和回应我们的情绪。
Preliminaries 前言
Emotion Models 情绪模型
一些研究人员认为,存在一些适用于所有年龄和文化的普遍情绪(Maria等人,2019)。为了避免在情感识别中犯错并设计一个可靠的系统,有必要对情感建模进行更深入的了解。研究人员以两种方式表示情绪:
- 第一种观点是Ekman和Friesen(1971)提出的著名的离散情绪模型,它将情绪分为六种基本类型;快乐、悲伤、惊讶、愤怒、厌恶和恐惧。
- 第二种观点认为情绪是三个心理维度的组合:唤醒和效价以及支配或强度之一。早期的研究已经证明,唤醒和效价这两个维度足以解释基本的情绪,这些情绪主要是由神经生理因素驱动的(Eerola和Vuoskoski,2011)。
文献中最常用的维度模型是Russel的Circumplex模型(Posner等人,2005),它只用效价和唤醒来代表情绪,其中价值代表从消极到积极的情绪范围。相比之下,唤醒代表一种从被动到主动的情绪。
根据罗素的圆环模型,将情绪状态归类为不连续的情绪是不正确的,因为人类的情绪状态总是几种情绪的混合物。因此,当人们报告恐惧是他们的情绪时,可能是兴奋、快乐和恐惧的混合,或者是负面情绪和恐惧的混合。所以,在积极和消极的恐惧情况下,大脑和生理信号的模式是不一样的,把它们归为一类会导致错误的识别。
| Author | Effects |
|---|---|
| Maria et al. (2019) | 基于经验、文化、年龄和许多其他因素,对情绪的感知也有很大的不同,这使得评估变得困难*。 |
| Lichtenstein et al. (2008) | *的研究表明,维度方法对自我评估更准确。 |
| Eerola and Vuoskoski (2011) | 在对复杂的情绪刺激进行评分时,离散情绪模型不如维度模型可靠*。他们还观察到离散模型和维度模型之间有很高的对应关系。 |
本文情绪模型:
面部宏表情和面部微表情通常用离散情绪来表达,以前的研究使用离散情绪模型来评估他们的策略。然而,大多数关于神经生理学情绪识别的研究和本文使用的基准数据集,都使用了环状模式(唤醒和效价)来评估他们的方法。由于本文研究的重点是揭示潜在的情绪,并且除了面部微表情外还使用了三种神经生理线索,因此使用二维环状模型来评估本文在基准数据集和自采数据集上的方法。
Emotion Stimulation Methods 情绪刺激方法
情绪有不同的诱导情绪的方法。然而,所有情绪诱导方法的效果是不一样的。Siedlecka和Denson(2019)将情绪刺激分为五种策略:
- 观看图像和视频等视觉刺激;
- 听音乐;
- 回忆个人情绪记忆;
- 完成心理程序;
- 想象情绪场景。
他们展示了不同类型的刺激如何对各种生理变量产生不同的影响。根据他们的研究,视觉刺激是文献中使用较多的最有效的诱导方法。另外:
- Roberts等人(2007)发现,双人互动可以被认为是一种情感诱导方法。
- Quigley等人(2014)增加了言语、身体运动、生理操纵器如咖啡因和虚拟现实(VR)。
Facial Micro Expressions 面部微表情
| Author | Effects |
|---|---|
| Ekman, 2003 | 面部微表情是对情绪刺激的简短面部动作,它揭示了隐藏的情绪*。 |
| Yan et al., 2013 | 微表情已被用于测谎、安全系统以及临床和心理领域,以揭示潜在的情绪*。 |
| Liong et al., 2015 | 与宏观表情相比,较少的动作和较短的持续时间是面部微表情的主要特征*。 |
| Yan et al., 2013 | *研究了微表情的持续时间,结果显示其持续时间在65至500毫秒之间。 |
| Li et al., 2013; Yan et al., 2014 | 由于视频情节是动态的、持续时间长的情感刺激,它们被用于微表情研究,并创造了大多数微表情数据集*。 |
| Li et al., 2013; Yan et al., 2013, 2014 | 为了防止微表情记录中的面部宏观表情污染,在许多研究中,参与者被要求在观看视频时抑制任何面部动作并保持扑克脸*。 |
| Yan et al., 2013 | 然而,在应对情绪化的视频刺激时,抑制是很难实现的。 |
一个微表情有三个阶段;开始阶段、顶点阶段和抵消阶段。在对情绪刺激的反应中,快速的肌肉运动发生在开始阶段,这是非自愿的,显示出真正的情绪泄漏。有时这些反应会持续片刻,作为顶点阶段。最后,情绪反应在偏移期消失,面部恢复到放松状态。
| Author | Effects |
|---|---|
| Yan et al., 2013 | 由于皮肤的自然紧张,恢复到放松状态对某些人来说可能需要更长的时间,或者因为与随后的情绪刺激合并而没有发生*。 |
| Goh et al., 2020 | 在录制的视频中,开始阶段的第一帧表示开始帧,而表情最丰富的那一帧是顶点帧。偏移帧是表情消失的时候*。 |
利用面部微表情识别情绪有两个主要步骤:
- 第一步是在视频序列中发现或定位有微表情的帧或帧。
- 第二步是识别微表情的情绪状态(Oh等人,2018;Tran等人,2020)。
一些工作使用手工特征的策略,如:
- 三正交平面的局部二进制模式(LBP-TOP)(Pfister等人,2011)
- 定向梯度直方图(HOG)(Davison等人,2015)从帧中提取特征,以发现和识别情绪。
- (Guermazi等人,2021)提出了一种基于LBP的微表情识别方法,以创建面部视频的低维高相关表示,并使用随机森林分类器对微表情进行分类。
深度学习提取深度特征:
- 深度学习技术被用来提取深度特征,并利用面部微表情进行情绪分类(Van Quang等人,2019;Tran等人,2020)。
- Hashmi等人(2021)提出了一个无损注意力残差网络(LARNet),用于编码特定关键位置的面部空间和时间特征,并对面部微表情进行分类。虽然他们在实时识别情绪方面取得了可喜的成绩,但他们的模型只有在帧率超过200帧时才有效。
- Xia等人(2019)提出了一个递归卷积神经网络(RCN)来提取面部微表情的时空变形。他们使用基于外观和基于几何的方法将面部序列转化为矩阵并提取面部运动的几何特征。他们对他们的策略进行了评估,基于留下一个视频(LOVO)和留下一个主体(LOSO)的方法,并取得了令人满意的结果。
- Xia等人(2020)提出了一个RCN网络来识别多个数据集的微表情。他们还讨论了输入和模型复杂性对深度学习模型性能的影响。他们表明,在组合数据集上运行模型时,低分辨率的输入数据和较浅的模型是有益的。
数据集方面:
- Ben等人(2021)回顾了现有的面部微表情数据集,并讨论了用于识别面部微表情的不同特征提取方法。在这项研究中,他们引入了一个新的微表情数据集,并讨论了微表情研究的未来方向。
- Pan等人(2021)总结和比较了现有的发现和微表情策略,并讨论了该领域的局限性和挑战。
- 检测面部微表情已受到越来越多的关注。许多数据集已经被创建,发现和识别方法也有了很大发展。然而,识别面部微表情仍然面临许多挑战(Weber等人,2018;Zhao和Li,2019;Tran等人,2020)。
- Oh等人(2018)讨论了数据集、发现和识别领域的各种挑战。他们表明,处理面部宏观运动,开发更强大的发现策略,以及忽略不相关的面部信息,如头部运动和跨数据集的评估,仍然需要更多的关注和研究。
Electroencephalography (EEG) Signals 脑电图信号
最近,许多神经心理学研究调查了情绪和大脑信号之间的相关性。脑电图(EEG)是神经成像技术之一,通过安装在头皮上的电极读取大脑电活动。
- 脑电图设备根据电极的类型和数量、电极的位置(灵活或固定位置)、连接类型(无线或有线)、放大器和过滤步骤的类型、设置和可佩戴性而有所不同(Teplan等,2002)。
- 像g.tec1或Biosemi2或EGI3这样具有较高数据质量的脑电图设备通常是昂贵和笨重的,需要耗时的设置。另外,还有一些数据质量较低的EEG设备,如Emotiv Epoc4或MindWave5。这些脑电图设备价格低廉,是无线设备,需要的设置时间较短(Alarcao和Fonseca,2017)。
- OpenBCI6提供了一个轻量级和开源(硬件和软件)的脑电图耳机,它的定位在这两个产品类别之间。它可以捕获高质量的数据,同时成本低,易于设置。如今,由于EEG设备的可穿戴性提高和价格降低,利用EEG信号识别情绪已经吸引了许多研究人员(Alarcao和Fonseca,2017)。
基于EEG的情绪识别是一个令人兴奋和快速增长的研究领域。
- 由于EEG信号的振幅较弱,使用EEG识别情绪具有挑战性(Islam等人,2021)。
- 一些研究专注于提取手工制作的特征,并使用浅层机器学习方法对健康护理等不同应用领域的情绪进行分类(Aydın等人,2018;Bazgir等人,2018;Pandey和Seeja,2019a;Huang等人,2021)。
一些综述研究讨论了各种手工特征的效果,如脑波段功率,以及使用各种分类器,如支持向量机(SVM)或随机森林(RF)来识别情绪。
- Alarcao和Fonseca(2017)回顾了EEG情绪识别研究。他们讨论了文献中用于情绪识别的最常见的数据清理和特征提取。根据他们的回顾,大脑波段功率,包括α、β、θ、γ和δ波段,是情绪识别的有效特征。
- Wagh和Vasanth(2019)对基于脑机接口和机器学习算法的人类情绪分析中涉及的各种技术进行了详细调查。
深度学习方法:
- 许多研究人员使用原始EEG信号并应用深度学习方法来提取深度特征并识别情绪(Keelawat等人,2019;Aydın,2020)。
- Sharma等人(2020)使用基于LSTM的深度学习方法,根据EEG信号对情绪状态进行分类。
- Topic和Russo(2021)使用深度学习来提取EEG信号的地形和全息表征,并对情绪状态进行分类。
- Islam等人(2021)对基于EEG的情绪识别方法进行了全面的回顾。他们讨论了各种特征提取方法以及用于识别情绪的浅层和深层学习方法。
近年来,研究人员专注于更先进的网络架构以提高性能。
- Li等人(2021)提出了一个基于强化学习(RL)的神经架构搜索(NAS)框架。他们用RL训练了一个循环神经网络(RNN)控制器,以使验证集上生成的模型性能最大化。在DEAP数据集上,他们用一种依赖主体的方法,对唤醒和情感取得了约98%的高平均准确性。
- 在另一项研究中(Li等人,2022),他们提出了一个多任务学习机制,同时进行唤醒、价值和支配力的学习步骤。他们还使用了一个胶囊网络来寻找通道之间的关系。最后,他们使用注意力机制来寻找通道的最佳权重,以便从数据中提取最重要的信息。他们在依赖主体的方法中,对唤醒和价值的平均准确率达到了97.25%,97.41%。
- 同样,Deng等人(2021)使用注意力机制为通道分配权重,然后用胶囊网络和LSTM来提取空间和时间特征。他们对唤醒和情绪水平的平均准确率达到了97.17%,97.34%。
Galvanic Skin Responses (GSR) Signals 皮肤电反应信号
研究表明,神经系统和人类皮肤上的汗腺之间存在联系。因为情绪亢奋而导致的汗液分泌水平的变化导致了皮肤电阻的变化(Tarnowski等人,2018;Kołodziej等人,2019),这被称为皮肤电活动(EDA)或皮肤电反应(GSR)。
当皮肤接收到大脑由情绪唤醒引起的兴奋信号时,人体的出汗就会发生变化,GSR信号也会上升。
- Kreibig(2010)表明,虽然EDA信号显示了情绪唤醒的变化,但还需要更多的研究来利用EDA信号识别情绪的类型。
- Tarnowski等人(2018)使用GSR局部最小值作为EEG的情绪纪元的指标。他们表明,GSR是情绪唤醒的一个很好的指标。
- 在许多研究中,GSR信号的统计特征被用作情绪分类的特征(Udovicic等人,2017;Yang等人,2018)。
- Kołodziej等人(2019)计算了一些峰值(局部最大值)和原始GSR信号的统计数据,作为信号的特征。他们使用了不同的分类器,并表明SVM在使用这些统计特征识别情绪唤醒方面比其他分类器效果更好。
一些研究使用了时间序列或平均信号作为特征向量。
- Setyohadi等人(2018)收集了每一秒的平均信号并应用了特征缩放。他们用这个数据对积极、中性和消极的情绪状态进行分类。他们使用了不同的分类器,带有Radial Based Kernel的SVM显示出最好的准确性。
- Kanjo等人(2019)使用GSR时间序列和深度学习分析来了解在城市中间行走时的情绪水平。
- Ganapathy等人(2021)表明,多尺度卷积神经网络(MSCNN)在提取GSR信号的深层特征和分类情绪方面是有效的。
在许多研究中,GSR信号已被独立用于识别情绪。但是,它们主要被用作补充信号或与其他生理信号相结合来识别情绪(Das等人,2016;Udovicic等人,2017;Wei等人,2018;Yang等人,2018;Maia和Furtado,2019)。
Photoplethysmography (PPG) Signals 光谱分析信号
- 光密度计(PPG)是一种利用红外线测量血容量脉冲(BVP)的新方法(Elgendi,2012)。
- 事实证明,PPG可以测量心率变异性(HRV)。HRV是对心率的时间变化的测量,以揭示医疗或精神状态(Maria等人,2019)。
由于像智能手表这样可以传输PPG信号的可穿戴设备的出现,利用PPG信号的研究受到更多关注。
- Kreibig(2010)已经显示了不同情绪状态下心率变异和心率的变化。
- 最近,有限的研究使用深度学习策略来提取PPG信号的深度特征。Lee等人(2019)使用一维卷积神经网络(1D CNN)来提取PPG信号的深层特征并对情绪状态进行分类。与GSR信号类似,PPG数据通常与其他生理信号一起使用来识别情绪状态。
Related Works 相关工作
Multimodal Datasets for Emotion Recognition 情绪识别多模态数据集
多模态情感识别已经吸引了许多研究者的注意。数量有限的包含面部视频、EEG和生理信号的多模态数据集可供下载,用于情绪识别。
- DEAP数据集(Koelstra等人,2011)
- MAHNOB-HCI数据集(Soleymani等人,2011)
由于EEG信号对肌肉伪影很敏感(Jiang等人,2019年),这类数据集使用了看视频或听音乐等被动任务,以尽量减少主体运动。
DEAP Dataset DEAP数据集
DEAP数据集包含32名参与者的EEG数据、面部视频、GSR、血容量压力(BVP)、温度和呼吸数据。它使用了40个音乐视频来刺激情绪,而EEG数据是使用Biosemi ActiveTwo EEG headset7收集的,它有32个通道。参与者使用自我评估人体模型(SAM)调查表(Bradley和Lang,1994)报告他们的唤醒、价值、支配和喜欢程度。然而,在这个数据集中,只有22名参与者有视频数据,其中4人的一些试验被遗漏。面部视频的照度很低,面部的一些传感器覆盖了部分面部表情。
MAHNOB-HCI Dataset MAHNOB-HCI数据集
在MAHNOB-HCI数据集中,眼球运动、声音、EEG数据和呼吸模式已被收集,用于图像和视频内容的标记。在观看视频片段后,参与者使用价值-唤醒模型报告他们的情绪状态。招募了30名参与者来创建这个数据集。使用了具有32个通道的Biosemi active II headset8来收集脑电图数据。
Exploring the Relationship Between Modalities 探讨各种模式之间的关系
一些研究专注于多模态情感识别中行为反应和生理变化之间的关系:
- Benlamine等人(2016)和Raheel等人(2019)使用EEG信号来识别面部微表情。
- Hassouneh等人(2020年)使用单模态策略,使用脑电图和面部数据识别身体残疾者或自闭症患者的情绪。虽然他们没有使用多模态策略,但他们表明,使用每个面部表情或EEG信号可以成功识别情绪。在他们的实验数据集中,EEG的准确率达到87.3%,面部微表情的准确率达到99.8%。
- Sun等人(2020年)研究了自发面部表情与脑电图和近红外光谱(fNIRS)测量的大脑活动之间在情绪价值上的强烈关联。
- Soleymani等人(2015)认为,虽然EEG信号对基于面部表情的情绪识别有一些补充信息,但它们不能提高面部表情系统的准确性。然而,后来的研究表明,通过结合脑电图和面部表情,可以改善。
Fusing Behavioral and Physiological Modalities 融合行为和生理模式
在许多研究中,研究人员表明情绪刺激对生理变化的影响,如心率、体温、皮肤传导、呼吸模式等。然而,他们无法确定哪些情绪被激发了。一些研究表明,将生理情绪识别和行为模式结合起来可以提高识别结果。将面部表情与生理模式相结合吸引了该领域一些研究人员的关注。这些研究大多集中在传统的面部表情方法上,并使用所有录制的视频帧来识别情绪。
- Koelstra和Patras(2013)使用EEG和面部表情的组合来生成视频的情感标签。他们提取了14个左右对的功率谱密度和横向化,并提取了230个EEG数据的特征。他们试图逐帧识别动作单元的激活,最后为每段视频提取了三个特征。他们使用了特征级和决策级的融合策略。根据他们的结果,与单一模式相比,融合策略提高了标签的性能。通过融合EEG和人脸数据,唤醒的准确性从EEG的64.7%和人脸的63.8%提高到70.9%。通过融合情绪值,这一改进从EEG的70.9%和脸部的62.8%提高到73%。
- Huang等人(2017)研究了融合面部宏观表情和EEG信号在决策层面上的情绪识别。他们使用一个前馈网络对每一帧视频中提取的面部的基本情绪进行分类。他们在这项研究中使用了他们的实验数据,在融合EEG和面部表情时,在依赖主体的策略中取得了82.8%的准确性。
- 后来,他们通过使用CNN模型改进面部表情识别来扩展他们的工作(Huang等人,2019)。他们使用FER2013数据集(Goodfellow等人,2013)预训练了一个模型,并使用小波提取功率带和SVM对EEG数据进行分类。他们在DEAP数据集上使用多模态方法中的主体依赖策略,对情绪和唤醒的准确率分别达到80%和74%。
- 在一项类似的研究中,Zhu等人(2020年)使用加权决策水平融合策略,结合脑电图、外周生理信号和面部表情来识别唤醒-情绪状态。他们使用三维卷积神经网络(CNN)来提取面部特征并进行分类,他们还使用一维CNN来提取EEG特征并进行分类。当将面部表情与EEG和生理信号相结合时,他们取得了更高的准确性。
- Chaparro等人(2018年)还提出了一种特征级融合策略,用于结合EEG和面部特征(使用70个地标坐标)来提高识别结果。
在大多数多模态情感数据集的记录视频中,在许多帧中无法观察到任何表情。这些数据集使用被动的任务,如观看视频来刺激情绪,所以情绪化的面孔只能在一小部分的帧中看到。因此,在数据分析中考虑所有的帧,或者在不考虑这个问题的情况下使用帧之间的多数票,都不能产生一个好的情感识别结果。然而,在应对这些被动任务时,可以观察到许多微表情。
- 只有Huang等人(2016)考虑了中性脸和微妙表情的存在。他们基于局部二进制模式(LBP)策略提取了所有帧的空间-时间特征。然后,他们使用这些特征训练了一个线性核SVM来计算表情百分比特征,并使用这个特征向量进行情绪分类。他们提取了所有的频率和频段,然后使用ANOVA测试来选择这些特征的子集用于EEG。对于面部分类,他们使用K-Nearest-Neighbor(KNN)分类器进行EEG和支持向量机(SVM)。他们表明,决策层的融合策略比单一模式或特征的融合效果更好。他们对情绪和唤醒的准确率分别达到了62.1%和61.8%。
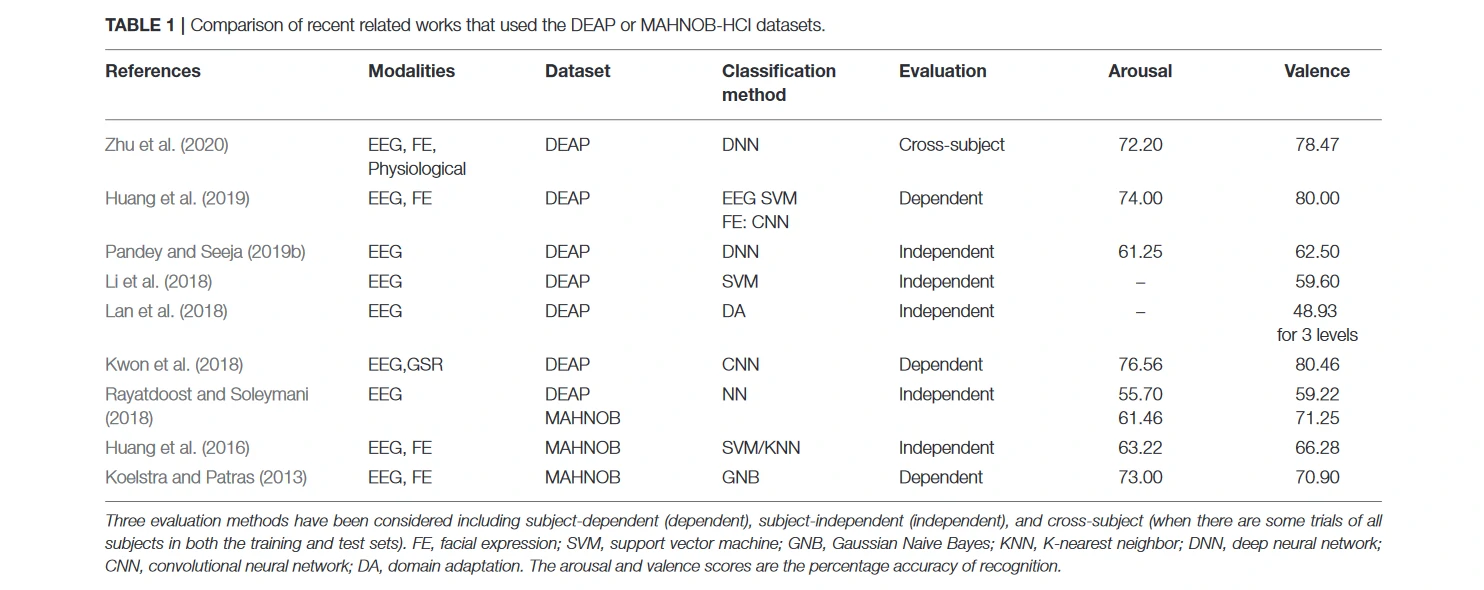
表1总结了最新的相关工作。可以看出,数量有限的研究将面部表情与EEG数据结合起来。当训练和测试集中有一些所有参与者的试验时,大多数以前的工作都会评估他们的方法是依赖主体或跨主体的。尽管设计识别未见过的参与者的情绪的一般模型在日常生活中是非常有用的,但只有少数研究使用了独立于主体的方法来设计和评估他们的方法。与依赖主体和跨主体的评价相比,独立于主体的方法的准确性较低,需要更多的研究和探索。另外,尽管一些研究集中于将面部表情与生理信号相结合,但大多数都是基于强烈的面部表情来设计和训练的。而在大多数使用的多模态数据集中,人们不允许表现出激烈的表情。
这项研究通过研究使用面部微表情策略与EEG和生理信号相结合进行多模态情感识别的最佳方式来解决这一问题,还探讨了如何利用面部微表情来识别面部视频、EEG和生理数据中最具情感的部分。此外,创建了一个新的面部视频、生理信号和EEG信号的数据集,这有助于开发情感识别的稳健模型。还探索了从OpenBCI EEG headset收集的数据的性能和质量,这是一个用于识别情绪的低成本EEG headset。此外,提出了使用多模态数据进行情感识别的策略,并最终对其进行了评估。
总的来说,这项研究的主要创新之处在于将面部微表情识别与EEG和生理信号相融合。这项工作的另一个重要贡献是利用面部微表情来识别中性状态和情绪状态,以提高使用EEG和生理信号的情绪识别。
Experimental Setup 实验设置
创建了一个新的多模态数据集,用于使用轻型可穿戴设备和网络摄像头进行情感识别。从大学生和工作人员中招募了23名志愿者(12名女性和11名男性),年龄在21至44岁之间(μ=30,σ=6)。只针对六种基本情绪中的四种,包括快乐、悲伤、愤怒和恐惧,外加一个中性状态。在观看视频的任务中收集了面部视频、EEG、PPG和GSR信号。使用唤醒-价值模型来测量情绪,自我报告数据也被用作基础真实值。
(其它详见原文)
Methodology 方法
Ground Truth Labeling 正确标签
使用来自SAM调查问卷的自我报告数据进行基础真实标记。只使用DEAP和自采数据集的报告的唤醒和价值。为了对唤醒和情感水平进行分类,尽管在SAM问卷中有九个级别的唤醒和情感,但与以前的研究类似,使用二进制分类。认为五个是创建二进制标签的阈值,对应于高和低的唤醒和价值。
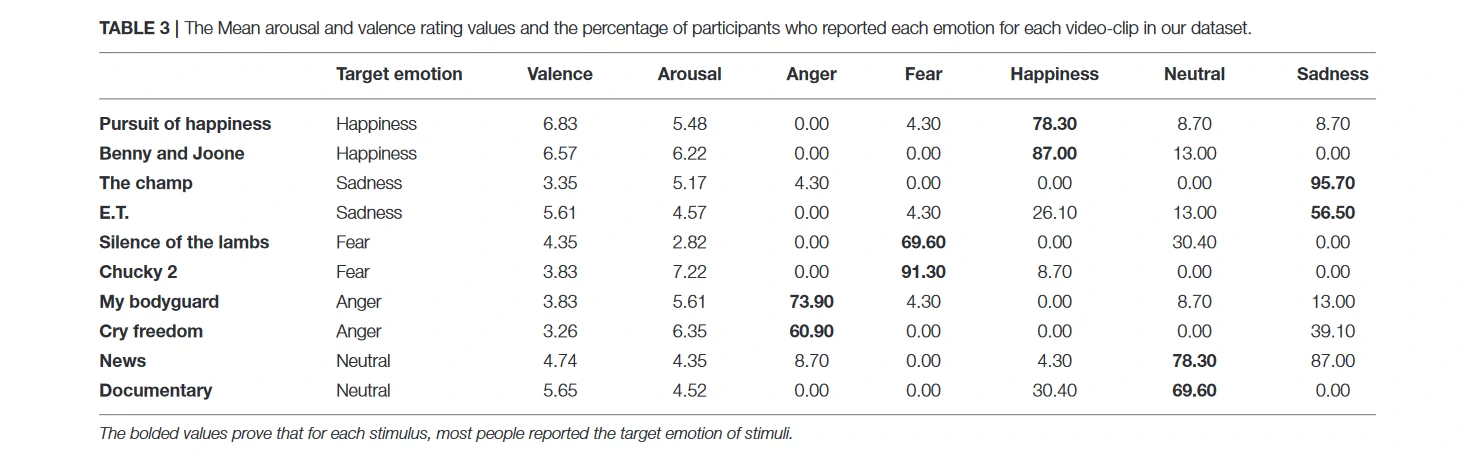
表3显示了当评分值在1到9之间时,自我报告的唤醒评分和数值的平均值。该表还显示了每个视频片段中报告每种情绪的参与者的百分比。例如,78.9%的参与者对《追求幸福》视频片段报告了幸福,而对这个视频片段只有4.3%报告了恐惧,7.8%报告了中性,8.7%报告了悲伤。可以看出,大多数参与者对所有刺激物都报告了目标情绪。尽管在自我报告问卷中包括了所有的基本情绪,但除了目标情绪列表中的情绪,没有一个参与者报告其他的情绪。因此,没有在本表和评价结果中包括其他情绪。
Imbalanced Data 不平衡的数据
在DEAP数据集中,所有参与者的低级和高级试验的总数量为339和381,而唤醒的数量为279和444。在数据集中,这些值对于价值类来说是100和130,对于唤醒类来说是94和136,分别是低级和高级。可以看出,这两个数据集在类别之间是不平衡的。另外,使用了一个离开一些对象的策略来分割训练和测试数据。因此,每一组的训练和测试集之间的不平衡状态取决于参与者的评分。使用成本敏感学习(Ling and Sheng, 2008)来处理不平衡的数据。成本敏感型学习在模型训练过程中使用了预测错误的成本。它采用了一种惩罚性的学习算法,提高了少数类的分类错误的成本。使用Scikit-learn库来测量类权重,并在训练模型时使用估计的权重。还使用成本敏感的SVM和RF来处理不平衡的数据。
Video Emotion Recognition 视频情绪识别
在DEAP数据集和自采数据集中,由于EEG信号对肌肉伪影的敏感性,要求参与者在观看视频时保持扑克脸。这个条件与微表情数据集完全相同。在微表情数据集中,参与者被要求在观看视频时抑制他们的表情并保持一张扑克脸,以防止宏观表情污染(Goh等人,2020)。这个条件导致几乎所有的帧都是中性脸,只有真正的情绪会作为微表情泄露出来。
图4显示了来自DEAP数据集、自采数据集、SMIC数据集(Li等人,2013)和FER2013数据集(Goodfellow等人,2013)的一些试验帧。SMIC数据集是专门为面部微表情的情感识别研究而收集的。正如在所有这些数据集中所看到的,情绪几乎不能被注意到,大多看到的是一张中立的脸。相比之下,在FER2013(Goodfellow等人,2013)和CK+(Lucey等人,2010)等面部宏观表情数据集中,有几组表情强烈的脸(图4)。
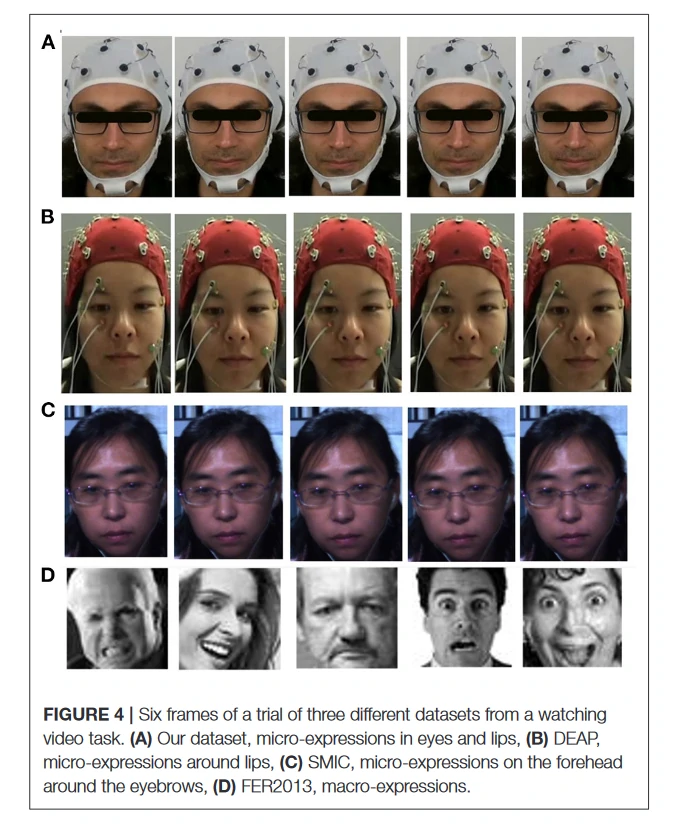
使用FER2013数据集训练了一个深度卷积神经网络,在所有试验的框架上进行了测试,主要从面部表情识别中得到了中性情绪。该模型有五个卷积层和池化层块,其结构类似于VGG-16(Simonyan和Zisserman,2014),每个块中有一些额外的层。图5显示了模型的结构。FER2013是一个由谷歌图像搜索API自动收集的大规模数据集,已被广泛用于面部情绪识别研究。它包含28,709张训练图像、3,589张验证图像和3,589张测试图像,有七个表情标签:愤怒、厌恶、恐惧、快乐、悲伤、惊讶和中性。对数据进行了预处理,将图像转换为灰度图像,使用Dlib库中的人脸检测模块提取人脸区域,对其进行标准化和大小调整,最后,将其送入深度卷积网络。将未检测到的人脸从训练和测试集中移除,在FER2013测试集数据上达到了85%的准确率。使用训练好的模型从DEAP数据集和自采数据集的每一帧记录的视频中检测情绪。使用训练好的模型,应用同样的预处理步骤,预测每一帧的情绪。
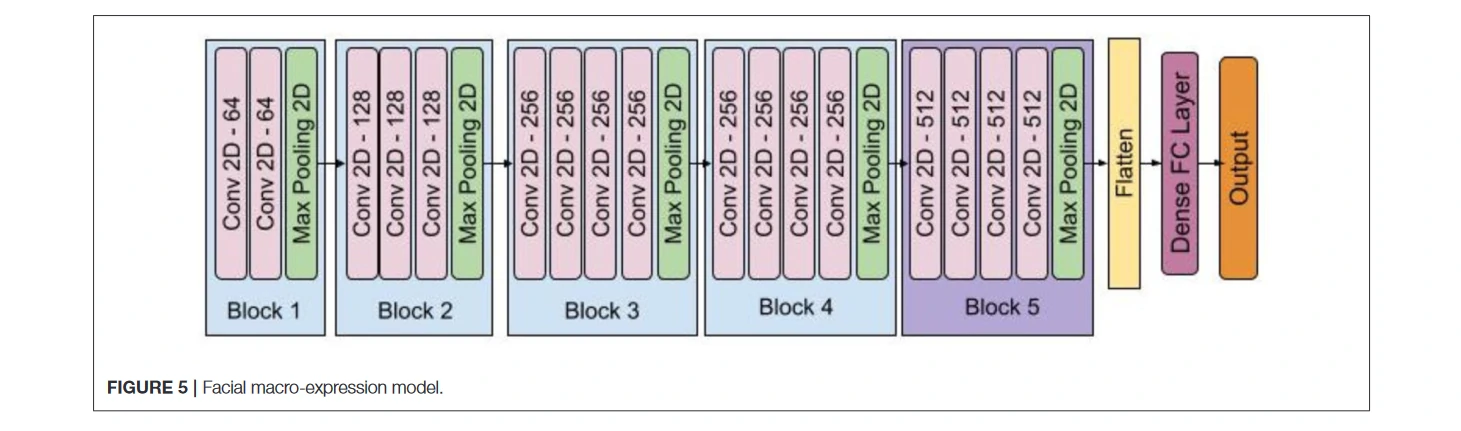
表4显示了DEAP和自采数据集的预测结果。可以看出,基于对所有框架情绪的多数投票策略,在DEAP的试验中100%检测到的情绪是中性的,在实验的试验中89.1%是中性的。对于有限的参与者,在所有的试验中,中性脸被错误地预测为悲伤的情绪。

这一结果表明,中性脸或有细微或微表情的脸不容易用面部宏观表情方法识别。由于DEAP和自采数据集中录制视频的条件与微表情数据集相同,使用微表情方法来检测这两个数据集中的面部视频表情,并研究其性能。因此,将DEAP和自采数据集中的面部数据视为具有微表情的面部数据,并使用面部微表情策略进行视频-情绪识别。
使用了一个两步的面部微表情识别策略。首先,使用了一个自动发现策略,根据与试验的第一和最后一帧相比,最大的面部组件的运动,自动找到顶点帧。然后,提取了顶点帧周围的一组帧,并考虑这些帧而不是整个视频进行分类。最后,将提取的序列输入一个三维卷积神经网络。
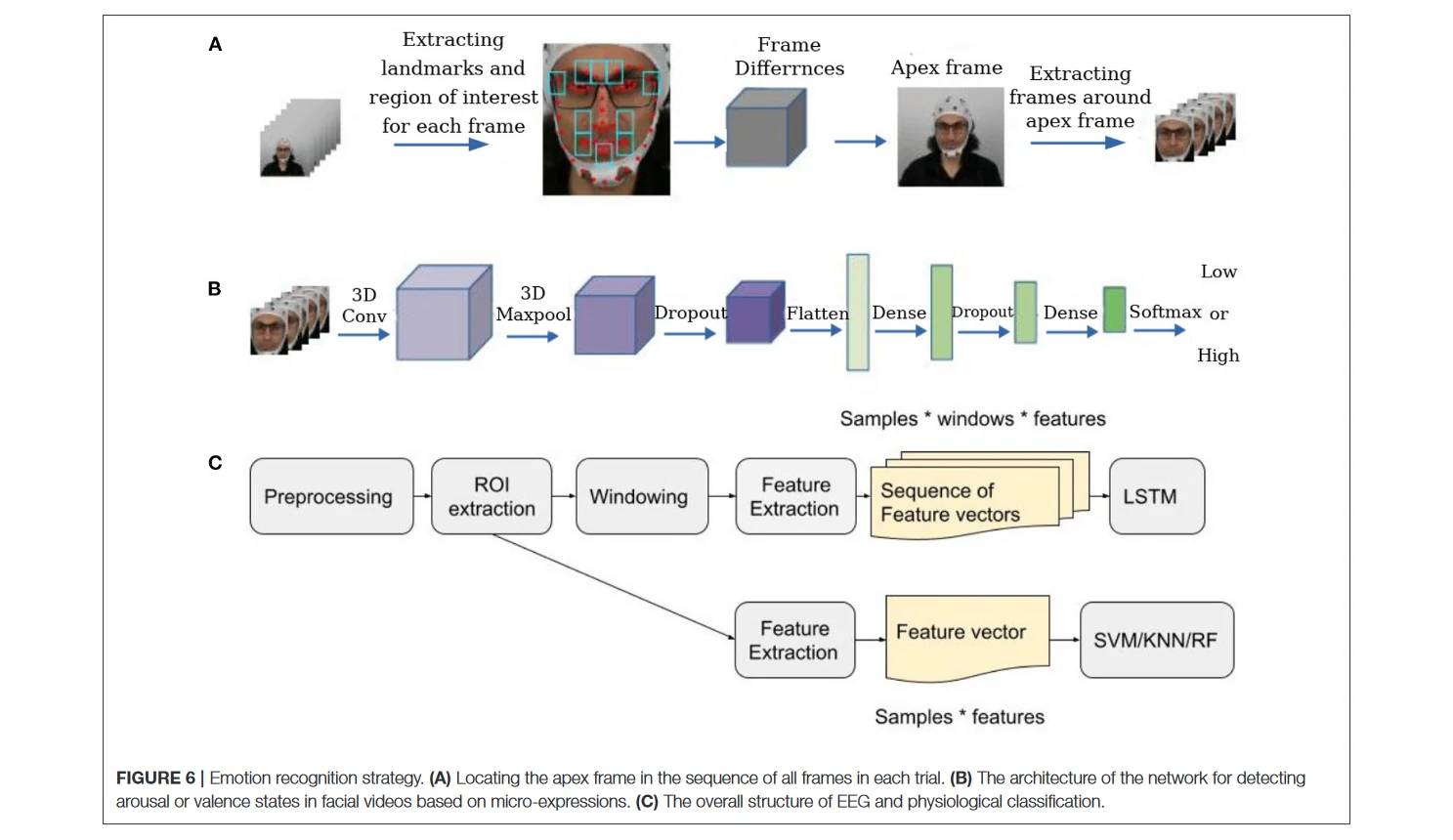
为了准备发现微表情的框架,首先,在WIDER FACE数据集(Yang等人,2016)上采用了预训练的YOLO v3网络(Redmon和Farhadi,2018)进行人脸检测。选择WIDER FACE数据集是因为它包含了不同程度的比例、遮挡和姿势的图像,增强了模型学习的特征空间,在任何条件下都有更好的实时性能。然后,按照Van Quang等人(2019)介绍的定点方法来识别每个视频中的顶点帧(有微表情的帧)。在这个定点方法中,首先提取了面部组件周围的十个区域,这些区域的肌肉运动发生得非常频繁。下一步,将视频序列的第一帧视为起始帧,最后一帧视为偏移帧,并计算出这十个区域中每一帧与起始帧和偏移帧之间的绝对像素差异。最后,计算了每一帧的每个像素的平均值。认为具有较高强度差异的帧为顶点帧。认为顶点帧周围的窗口是感兴趣的区域(ROI),在分类步骤中只使用这些帧(图6A)。
虽然自采数据集和DEAP数据集的录制视频较长,而且可能包含比面部微表情数据集更多的中性帧,但面部微表情的发现方法仍然可以找到顶点帧。因此,仍然有起始、顶点和偏移帧。在实际起始帧之前和偏移帧之后可能有几个中性帧,但所有这些帧都是一样的,不会影响发现算法的结果。这是因为实际起始帧和第一帧或实际偏移帧和最后一帧几乎相同。因此,顶点帧和实际起始或偏移帧之间测量的绝对像素差异将与顶点帧和第一或最后一帧之间的绝对像素差异实际上是一样的。虽然视频中可能有更多的面部表情和顶点帧,但实际的偏移帧,和最后一帧几乎是相同的,因为这两个帧都描述了面部的中性状态。
考虑了ROI的不同窗口大小,并在结果部分进行了讨论。图4说明了DEAP和自采数据集的顶点框架周围提取的六帧序列,此外还有SMIC数据集的一个序列。使用三维卷积神经网络(3D CNN)来对微表情序列进行分类。它是微表情情感识别领域最先进的模型之一(Reddy等人,2019),在两个流行的微表情数据集CASME II(Yan等人,2014)和SMIC(Li等人,2013)上取得了良好的表现。该方法在CASME II数据集上取得了87.8%的准确性,在SMIC数据集上取得了68.75%的准确性。用这个模型来提取深度特征并对DEAP和自采数据集中的微表情进行分类。由于这两个数据集的基础事实标签都是基于唤醒和情感水平的,所以没有根据基本的情绪对微表情进行分类,而是根据唤醒和情感水平对微表情进行分类。为了对基于唤醒或价值的情绪状态进行分类,对数据应用了两次模型,一次是对唤醒水平进行分类,一次是对价值水平进行分类。在这个模型中,没有用6作为最后一个密集层的输出形状,而是用2来对基于低和高的唤醒或价值的微表情进行分类。
首先,使用YOLO人脸检测算法来检测ROI中每一帧的人脸,然后将其转换为灰度图像,归一化,并调整其大小。最后,将预处理过的序列送入Reddy等人(2019)介绍的两个三维CNN模型,用于分别对唤醒和价值进行分类。图6B说明了三维CNN模型的结构。
EEG and Physiological Emotion Recognition 脑电图生理情感的识别
微表情是识别每个试验中最有情绪的时间的一个指标。然后使用一个基于ROI的策略,使用EEG和生理数据来识别唤醒和价值。顶点框架的时间是每次试验中最有情绪的时间。然后,在脑电图和生理学数据中找到这个时间段的相应样本。由于脑电图、生理数据和视频帧之间的采样率不同,将此时每个信号的采样率相乘来确定ROI。最后,在其周围提取了几秒钟的数据,将提取的部分视为ROI,并只对提取的数据进行分析。考虑了不同的窗口大小来提取ROI,并在结果部分进行了讨论。
为了分析EEG和生理数据,遵循情绪识别的主要步骤:预处理、特征提取和分类。首先,清理了数据,然后提取了ROI部分,并且只使用ROI数据作为特征提取步骤的输入。为了对数据进行分类,使用了两种方法对EEG和生理学数据进行分类。在第一种方法中,从整个数据或ROI部分提取了一些特征————在下面的章节中描述。用这些特征作为支持向量机(SVM)、K-近邻(KNN)(Bressan和Vitria,2003)和随机森林(RF)(Criminisi等人,2011)分类器的输入。在第二种方法中,首先,将每个试验划分为不重叠的窗口。然后从每个窗口中提取与前一种方法相同的特征,并制成一个后果特征向量的序列。用这些序列作为堆叠的长短期记忆(LSTM)网络(Staudemeyer和Morris,2019)的输入,用两层LSTM提取时间特征。最后,用一个带有Adam优化器的密集层(Kingma和Ba,2014)来分别对数据进行唤醒和价值标签分类。图6C显示了EEG和生理数据分析的整体结构。
Data Cleaning 数据清洗
EEG
使用DEAP数据集中的预处理过的EEG数据,去除前8s的数据,包括3s的基线,并将5s作为参与时间,最后将数据归一化。参与时间是通过观察选择的,是参与者沉浸在视频中的平均时间。对于自采数据集,使用带通滤波器,提取1到45赫兹之间的频率,这是脑波的频率范围(Huang等人,2016)。然后应用一个共同的平均参考,最后,将数据归一化。图7A,B显示了数据清理前后的脑电图通道的频率。
PPG and GSR
一个低切频率为0.7赫兹、高切频率为2.5赫兹的带通滤波器被用来去除PPG信号的噪声。同样地,用0.1的低切频率和15赫兹的高切频率来清除GSR信号。还使用了一个中值滤波器来去除GSR信号中的快速瞬态伪影。最后,将这些GSR和PPG信号归一化。图7C-F显示了数据清理前后的GSR和PPG信号的一个样本的振幅。
Feature Extraction 特征提取
EEG
为了提取脑电特征,对每个数据窗口应用快速傅里叶变换(FFT)来提取脑电波段功率。通过从每个窗口中提取脑电功率波段,并将每个波段的平均值视为一个特征向量,从而形成五个特征。提取了Delta(1-4 HZ)、Theta(4-8 HZ)、Alpha(8-12 HZ)、Beta(12-30 HZ)和Gamma(30-45)带。这些特征通常在以前的研究中使用(Wagh和Vasanth,2019)。
PPG and GSR
计算了GSR和PPG信号的一些统计特征。GSR信号的平均值和标准差以及GSR信号的一阶和二阶离散差构成了GSR特征向量。为了建立PPG特征向量,考虑了PPG信号的平均和标准偏差。PPG和GSR特征向量具有相似的特征,因此将这两个特征向量串联起来,并将其称为生理数据。
Fusion Strategy 融合策略
有几种方法来融合来自不同来源的数据。融合数据主要有两种方式:(1)特征级或早期融合;(2)决策级融合或后期融合(Shu等人,2018)。
在特征层面上融合了PPG和GSR信号,将创建的特征作为生理特征处理,并对其进行分类。在决策层使用了两种不同的策略来融合面部微表情、EEG和生理学分类结果。第一个策略是基于多数投票,在脑电图、面部和生理预测中选择得票最多的预测作为最终预测。在第二种策略中,使用所有概率的加权和作为决策层的融合策略(Koelstra和Patras,2013;Huang等人,2017)。给这三个分类器在[0,1]的范围内以0.01的步长赋予各种权重,在训练数据上测量最佳权重,并在融合步骤中使用这些权重。方程(1)中,px模态表示每个类别使用特定模态的概率,a、b、c是权重。
Result and Discussion 结果和讨论
Evaluation Strategy 评估策略
使用了独立于主体的策略来评估本文方法,并找到一个通用的模型。使用了离开部分主体的策略交叉验证。由于本文模型并不复杂,而且数据集的大小也不明显,所以没有使用GPU来训练模型。所有的模型都是在一台装有Gnu-Linux Ubuntu 18.04、英特尔(R)酷睿(TM)i7-8700K CPU(3.70 GHz)的电脑上训练的,有六个内核。将参与者随机洗牌成六个组,并对所有组的模型进行并行训练。对于DEAP数据集,每个折叠中的测试集都有3个参与者。在自采数据集中,有4个参与者被考虑到测试集中。报告的结果是所有组结果的平均值。
评估模型的四个主要指标是准确性、精确性、召回率和F-Score或F1。它们使用方程(2)来衡量二进制分类。在本节中,所有的结果都是基于F-Score的。在这些公式中,TP是真阳性,指的是正确的阳性类预测的数量。真阴性(TN)衡量有多少正确的阴性预测。假阳性是指错误预测的阳性类的数量。FN代表假阴性,即错误的阴性类预测的数量。使用二元分类法对唤醒和情绪分别进行分类,并选择F-Score来评估本文方法,这适合于不平衡数据。(Sun et al., 2009)。

Hyper-Parameter Tuning 超参数调优
为了衡量SVM、RF和KNN的最佳超参数,使用了网格搜索交叉验证的参数调整(Claesen和De Moor,2015)。当基于离开部分受试者策略分割数据时,使用六倍交叉验证法调整超参数。当考虑Radial Basis Function(RBF)核时,得到了最好的结果,200作为SVM的调节参数,KNN的五个邻居,RF的500个估计值。对于微观面部表情的三维卷积模型,使用的参数与源研究(Reddy等人,2019)相同。只将epochs的数量设置为50。还根据经验发现,当第一个LSTM有80个神经元,第二个有30个神经元时,使用两个堆叠的LSTM会产生更好的结果。考虑将128、32和64作为脑电图、GSR和PPG分类器的LSTM模型训练中的批次大小,并将它们的历时数设置为100。没有调整学习率。相反,在0.0010.0001的范围内使用了一个降低的学习率,当验证损失不发生变化时,学习率以0.5的速度递减。
Identifying ROI Size 确定ROI大小
微表情的持续时间在65到500毫秒之间变化。当情绪持续一段时间后,这个时间可能会增加,也可能与下一个微表情合并,而这个微表情是后续情绪刺激的反应(Yan等人,2013)。DEAP数据集以每秒50帧的速度记录面部数据。这意味着,如果认为一个微表情的长度为半秒,当帧率为50赫兹时,一个微表情会出现在25帧中。在自采数据集中,帧率是每秒30帧,所以一个微表情的长度是15帧。考虑了两种不同的窗口大小,包括20和60帧,围绕着顶点帧,以涵盖短的微表情或长的微表情。考虑了更大的窗口尺寸,以覆盖保持较长时间或与下一个微表情重叠的微表情。表5比较了这两种窗口大小对预测结果的影响,当想根据唤醒和价值水平对情绪进行分类。可以看出,对于两个数据集,60帧的结果都比较好。由于增加窗口大小会增加包括其他头部运动的概率,在序列中增加非信息数据,并增加计算成本,没有考虑更大的窗口大小。表5显示了来自DEAP和自采数据集的3D CNN模型在这两种不同窗口大小下的f-score。使用面部微表情分类的预测结果与决策层面的其他模式相结合,对唤醒和价值水平进行分类。
考虑了从EEG和生理数据中提取ROI的各种尺寸,并比较了ROI尺寸对分类结果的影响。图8显示了使用LSTM方法时各种ROI大小对分类结果的影响。报告的数值是所有折叠的F-Score值的平均值。如图8所示,对于两个数据集,使用多数融合时,15的窗口大小几乎创造了最高的F-Score。对于DEAP数据集,当考虑所有的数据时,加权融合创造了预测唤醒的最佳结果。尽管在这里显示的两个不同的数据集中没有看到任何一致的模式,但假设在最情绪化的部分的一小部分数据可以产生一个类似或比使用所有数据更好的结果。这表明,如果准确地确定数据中最情绪化的部分,可以准确地研究大脑和身体对情绪刺激的反应。
还使用SVM、KNN和RF分类器对窗口大小为15和考虑整个数据时的ROI部分进行分类。在表6中比较了这些分类器与LSTM方法在所有数据或只考虑ROI部分进行分类时的F-Score。表5中报告的窗口大小为60的面部微表情的F-Score已被考虑在融合策略中。将面部微表情方法的预测结果与使用的所有分类器进行了融合。从这些表格中可以看出,LSTM方法在两个数据集的唤醒和价值方面都取得了最佳结果。这表明,利用时间和空间特征可以帮助检测情绪。同时,融合策略的结果也大大优于单一模式。在自采数据集中,大多数人对唤醒和情感的融合进行投票,而在DEAP中只有情感的融合优于加权的融合。当应用于ROI数据时,结合PPG和GSR只提高了LSTM方法在价值水平分类中的性能。另外,基于ROI的LSTM的FScore相对接近于或有时优于在整个数据上使用LSTM。这表明,使用一小部分数据可以像使用全部数据一样具有信息量。
虽然其他分类器在其中一个数据集中的唤醒或情感的某些模式产生了良好的结果,但与LSTM方法相比,他们的预测在与其他模式融合后并没有改善。当预测精度低于或接近随机预测或二元分类的50%时,它无法在数据中找到任何特定的模式。因此,单模态预测之间的不匹配性增加,导致融合策略的f-score下降。根据表6,SVM、KNN或RFC对某些模式的f-scores低于或接近50%。因此,这导致了无效的融合。
Computation Cost 计算成本
没有使用所有的帧作为3D卷积模型的输入,而是只使用了每个视频的60个帧作为模型的输入。DEAP数据集在每个视频中有3,000帧,而自采数据集在每个视频中有2,400帧。通过提取微表情的ROI,减少了DEAP的输入大小,比率为(60/3000),自采数据集为(60/2400)。输入规模的下降导致了计算成本的大幅下降。自采数据集有230(23 * 10)次试验,而DEAP的数据集有720(18 * 40)次试验,适用于所有参与者。两个数据集的人脸模型的输入都是(60 * 64 * 64),其中60是每个试验的帧数,64 * 64是人脸区域灰度的帧的尺寸。对DEAP数据集的六折人脸模型进行并行训练花了1小时37分钟(每个历时235秒)。由于每个参与者的试验次数较少,自采数据集的训练时间为33分钟(每个震荡期为79秒)。
此外,尽管以前的研究使用LSTM网络对EEG信号进行分类,并将原始信号作为网络的输入(Ma等人,2019年),但从每秒钟的数据中提取了有限的特征,以减少输入规模。创建了一个新的数据序列,该序列比原始数据小得多,同时仍然具有信息量。例如,对于EEG数据,每个试验的大小是(持续时间(秒) * 采样率 * 通道)。将这一大小减少到(持续时间(秒) * 五个功率段)。这种减少对生理学数据也是一样的。脑电图、PPG和GSR的LSTM模型的训练是以六倍的方式平行进行的。为DEAP数据集训练所有这些模型需要12分钟和14秒,而每个历时大约需要1-3秒。自采数据集的训练时间为5分钟,每个历时的运行时间在25到100ms之间。
Final Result 最终结果
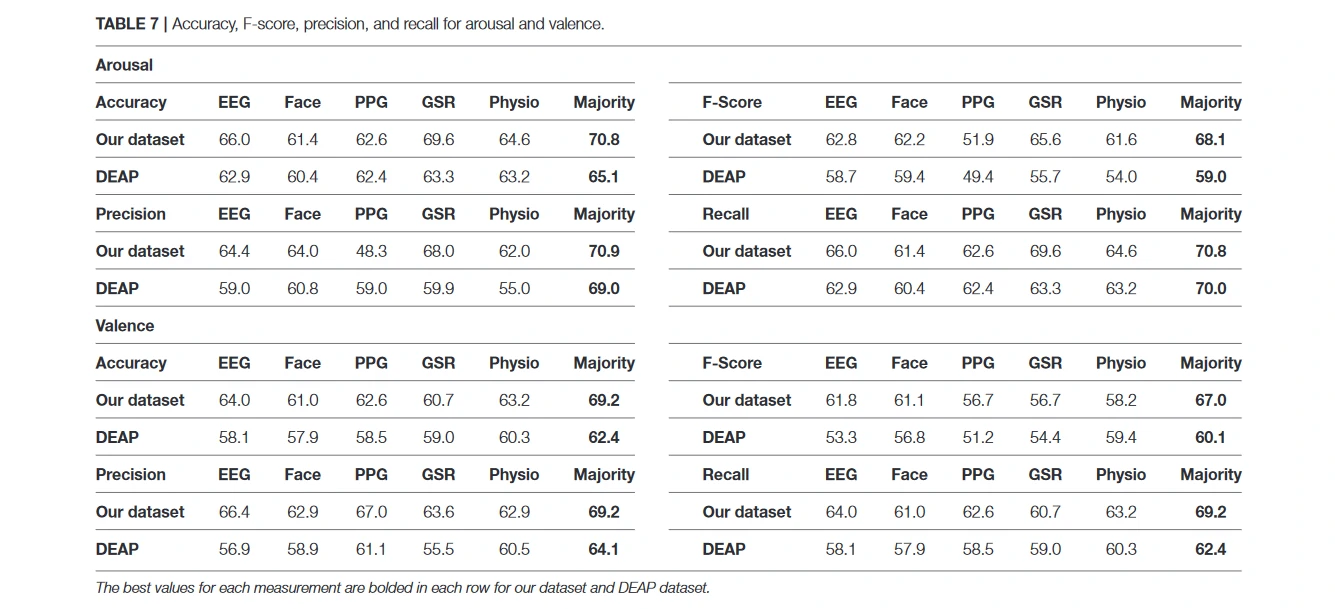
表7显示了当ROI窗口大小为15秒时,单一模式或融合策略对ROI部分进行分类的最终结果。可以看出,在两个数据集中,将微表情与EEG和生理信号融合,比使用单一模式有更高的准确性和F-Score。与使用独立于主体的策略的相关作品相比,在识别唤醒和情绪水平方面取得了类似或更好的准确性。
没有任何标准的基准来评估各种情感识别研究。有多个数据集,在数据收集方面有不同的场景,使用不同的模式和传感器记录情感数据。数据集、情感模型、分割数据的方式、评估策略和评估指标的多样性会影响最终的情感识别结果。出于这个原因,应该考虑所有这些因素来比较各种研究。与表1中报告的前人工作相比,在考虑独立于主体的方法时,所提出的方法的准确性相当高,这是最具挑战性的评价条件。
虽然检测面部微表情在文献中仍是一个很大的挑战,需要更多的探索,但已经证明,它可以大大降低视频情感识别的计算成本。检测微表情存在一些影响情绪识别性能的挑战,包括与其他面部动作的污染、姿势变化、光照不足,以及伪造或摆放微表情的可能性(Zhao and Li, 2019)。在DEAP数据集和自采数据集中,由于扑克脸的条件,伪造微表情的机会很低。然而,有一些不必要的动作会影响检测微表情和识别感兴趣区域的结果。
低成本的OpenBCI脑电图帽可以达到与DEAP数据集中使用的Biosemi Active II帽类似的性能。结果表明,虽然这个工具成本很低,但它可以作为一个可靠的工具,用于收集大脑信号进行情感识别。
与之前的研究类似,结果显示结合各种模式会带来更好的识别结果,融合后的识别率提高了38%。在DEAP数据集中,对唤醒的准确率达到65.1%,对情感的准确率达到69.2%,这比单一模式要好。在自采数据集中,这些相应的数值为70.8%和69.2%的唤醒和情感。表7显示了这些改进。虽然采用多模态数据有一些缺点,如增加计算成本和数据分析的复杂性,但提高预测性能的好处超过了它们。现在,大多数处理系统都有多个核心,使并行处理变得容易。可以在几乎与单模态分析相同的时间内利用并行处理进行多模态数据分析。
Limitations 局限性
尽管显示面部微表情可以有效地识别情绪,但仍面临着一些挑战,应该在未来解决。由于不自主的面部运动,如眨眼、头部运动或常规的面部表情,微表情可能被错误地检测到(Tran等人,2020)。这些运动会导致对顶点框架的错误检测。在未来,可以通过引入新的面部微表情数据集和使用深度学习方法来大大改善发现策略的结果。在本文中,使用了一个简单的传统微表情识别策略来检测顶点框架。在情感识别中,面部微表情可以与其他模式相结合。在未来,希望使用更强大的定点策略来提高识别质量。
此外,面部微表情方法面临着与面部宏观表情类似的挑战,包括光照条件、文化多样性、性别和年龄。这些限制可以通过使用新的数据集和更强大的深度学习方法来克服。此外,将面部微表情与生理信号相结合,将改善识别结果。对于大多数人来说,脑电图headset和生理传感器并不像相机那样容易获得。现在比以往任何时候都更接近开发情感识别的稳健模型,因为越来越多价格低廉的可穿戴设备,如智能手表、活动追踪器和VR头盔都配备了生理传感器。可以通过引入更准确、可穿戴和可负担的EEG传感器,以及开发更稳健的生理情绪识别算法来实现这一目标。
在研究中,使用了一个定点策略来检测顶点框架。由于定点方法仍然需要更多的探索,是一个开放的挑战(Oh等人,2018),可以在未来通过手动注释DEAP和自采数据集来改善结果。手动注释这些数据集是一项劳动密集型和耗时的活动。尽管如此,由于它们是在类似于微表达数据集的条件下收集的,可以将它们作为微表达数据集,用于制作更强大的微表达模型。