第四阶段主要是讲 Transformer 是怎么和对比学习有机结合起来的,在这个阶段主要就是简单的讲一下 MoCo v3 和 DINO 这两篇工作
《An Empirical Study of Training Self-Supervised Vision Transformers》
MoCo v3 这篇论文虽然题目说的是自监督的 Vision Transformer,但其实 MoCo v3 只是一种架构,所以说卷积神经网络也可以用,Vision Transformer 也可以用
事实上 MoCo v3 怎么从 v1、v2 变到 v3,作者只用了一页去讲,大部分的篇幅都在讲自监督的训练、ViT 有多不稳定、发现了一个什么样的问题以及怎样用一个小小的改进就能让这个训练变得更稳定、效果也更好,这个写法就跟 SimCLR v2 有点像
- SimCLR v1 变到 v2,其实只用了半页的篇幅去写,剩下大部分的东西都是在讲这怎么做半监督学习
而 MoCo v3 大部分的篇幅都是在讲怎么样去提高 ViT 训练的稳定性,所以就是为什么这篇论文的题目叫做一个实验性的 study
摘要还是一贯的直白,上来就写这篇论文并没有描述一个新的方法,接下来作者就说其实这篇论文就是做了一个很直接、很小的一个改动,让自监督的 ViT 训练的变得更稳定了,但是不得不写一篇论文来把这个发现告诉大家,因为自监督的训练 Vision Transformer 已经是大势所趋了,这里有很多有趣的发现,所以我们分享给大家看,所以这篇论文的影响力依旧很大,它是 ICCV 21 的一篇口头报告论文
在讲训练稳定性之前,先看一下 MoCo v3 的架构,因为没有模型总览图,所以直接看伪代码如下图所示

- MoCo v3 其实就相当于是 MoCo v2 和 SimSiam 的一个合体
- 整体的框架来说,它还是有两个网络,一个是 query 编码器,一个是 key 编码器,而且 key 的编码器是动量编码器,最后的目标函数用的是对比学习的 loss,所以说从这个角度讲,它是个 MoCo v2
- 但是如果仔细看细节就会发现,query 编码器现在除了这个骨干网络之外,它还有 projection head,还有 prediction head,这个其实就是 BYOL,或者说是 SimSiam
- 而且它现在这个目标函数也用的是一个对称项,就是说它既算 query1 到 key2 的,也算这个从 query2 到 key1 的,从这个角度讲它又是 SimSiam
- 所以说,MoCo v3 就是 MoCo v2 和 SimSiam 一个很自然的一个延伸工作
- 因为 Vision Transformer 的出现,所以说作者就很想把卷积神经网络换掉换成 Vision Transformer,看看结果到底会变得如何,是不是自监督学习加上 Vision Transformer 就能取得像 nlp 那边的成功,然后就迅速试了一下,把骨干网络从一个残差网络换成了 ViT,下图展示的是一个 ViT 自监督训练的一个训练曲线
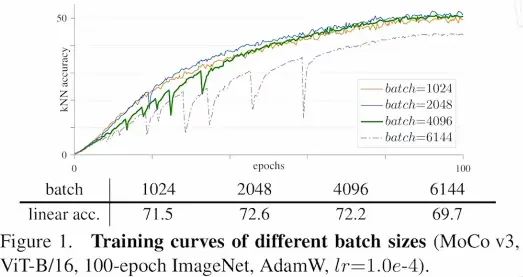
- 作者发现当 batch size 比较小的时候其实还好,这个曲线比较平滑,比如说图中的橘黄线和蓝线在当 batch size 比较小的时候就比较平滑,不会出什么问题,这个效果也还行
- 但是当 batch size 变大了以后,作者就发现这个曲线会莫名出现这种情况:训练的时候突然准确度就掉下来一下,再训练一段时间后又掉下来一下,虽然说它每次还能很快的恢复上去,但是恢复上去就不如原来的那个准确度高了,最后这个准确度也会差很多
- 按道理来说,一般大 batch size 会得到更好的结果,但是在这里大 batch size 反而得到了更差的结果,作者就觉得这是一个问题,这个问题得解决,如果能解决训练的这个问题,很有可能就能用更大的 batch size 去训练一个更大的 Vision Transformer 从而得到更好的结果
- 在训练与分割的网络时候也会有这种情况发生,知乎上有人看到 MoCo v3 这篇论文以后也说,之前在训练别的任务的时候也遇到过类似的问题,有人也采用类似的方式解决了这个问题,有人也就没有管,所以说有的时候很小的一个问题,也可以是一个问题的很好的出发点
- 针对这个问题,MoCo v3 的作者就提出来一个小 trick,他是怎么想到这个解决方式的呢?他观察了一下训练的时候每一层回传梯度的情况,这个是比较常见的操作,一般如果网络训练的不好,而且不知道为什么的时候,一般首先就是要去查一下梯度,然后作者就发现,当每次 loss 有这种大幅的震动导致这个准确度大幅下降的时候,梯度也会有一个波峰,而这个波峰其实是发生在第一层,就是在做 patch projection 时候
- 这个 patch projection 是什么呢?如果读过 Vision Transformer 的论文就知道,这个其实是属于模型的第一步,属于 tokenization 的那个阶段————就是如何把一个图片把打成 patch,然后给它一个特征。
- 这一步是怎么做的呢?其实就是一个可以训练的全连接层,能训练当然是好事,但是如果每次梯度都不正常,那还不如不训练,所以说作者就简单的尝试一下,如果不训练,直接冻住结果会怎样,所以就随机初始化了一个 patch projection 层,然后把它冻住,就是整个训练过程中都不变,结果发现问题就解决了,而且很神奇的是这个 trick 不光是对 MoCo v3 有用,它对 BYOL 也有用,如果用 BYOL 那套框架,把残差网络换成 Vision Transformer,刚开始就把 patch projection 层冻住,一样能获得更平滑的训练曲线,获得更好的训练结果
在这篇论文之后也有很多研究者意识到了第一步 tokenization 阶段的重要性,所以也有很多后续的工作去改进
第一阶段说白了,如果不想改 Transformer 这个模型本身,因为它又简单扩展性越好,所以说如果中间这一块我们不动,那能改的除了开始就是结尾,那开始就是 tokenization 阶段,结尾就是改目标函数
《Emerging Properties in Self-Supervised Vision Transformers》
DINO 这篇论文也说的是一种自监督训练 Vision Transformer 的方式,但这篇文章主要的卖点是:Vision Transformer 在自监督训练的情况下会有一些非常有趣的特性,它把它效果最炸裂的这些图片放到了图一如下图所示,放到了文章开头

- 这个图的意思就是说一个完全不用任何标签信息训练出来的 Vision Transformer,如果把它的自注意力图拿出来进行可视化的话,会发现它能非常准确的抓住每个物体的轮廓,这个效果甚至能直接媲美对这物体做分割,比如说图中像牙刷还有长颈鹿,这些物体的边界抠的非常的精准,甚至比很多做无监督分割的工作都要做的好
DINO 具体操作如下图所示
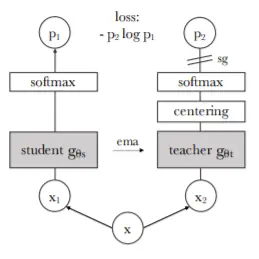
- 其实它的方法倒不是说多新,跟之前的一系列对比学习的工作都非常的相似,就是换了个方式来讲故事,至于 DINO 这个名字,来自于它的题目 self distillation with no labels,就是 distillation 和 no label
- 整个框架叫一个蒸馏的框架,至于为什么是自蒸馏,其实就跟 BYOL 一样,因为自己跟自己学或者自己预测自己,所以就是自蒸瘤
- 对于 MoCo 来说,左边的网络叫做 query 编码器,右边叫做 key 编码器,对于 BYOL 来说,左边叫做 online network,右边叫做 target network,DINO 其实就是延续的 BYOL,它只不过是换了个名字,把左边叫成 student 网络,右边叫成 teacher 网络
- 因为 student 要预测 teacher,所以可以把 teacher 网络的输出想成是 ground truth
- 至于具体的前向过程,跟 BYOL 或者跟 SimSiam 都是非常类似的,同样就是当有同一个图片的两个视角以后,用 x1、x2 通过编码器得到了两个特征,这个编码器自然也是有 projection head、prediction head
- 为了避免模型坍塌,DINO 做了另外一个额外的操作,叫做 centering,这个操作就是把整个 batch 里的样本都算一个均值,然后减掉这个均值,其实就算是 centering,这个就很像是 BYOL 对于 batch norm 的讨论,因为 batch norm 也是对整个 batch 里的样本做了一个均值和方差
- 最后有一个 stop gradient 的操作然后用 p1 去预测 p2
再看伪代码如下图所示

它真的跟 MoCo v3 实在是太像了,尤其是前像过程不就是一模一样吗,就只有目标函数稍微有点不一样,这里多了一个 centering 的操作,防止模型坍塌
总结
MoCo v3 和 DINO 这两篇工作,从方法和模型角度上来说,其实它们跟第三阶段基本是一模一样的,主要就是融合了 Vision Transformer
到这里就把过去两三年比较有代表性的对比学习的工作都串了一遍,这里我们就再画一张大图如下图所示,整体再快速的把这些工作再过一遍,看一下它们之间的联系与不同
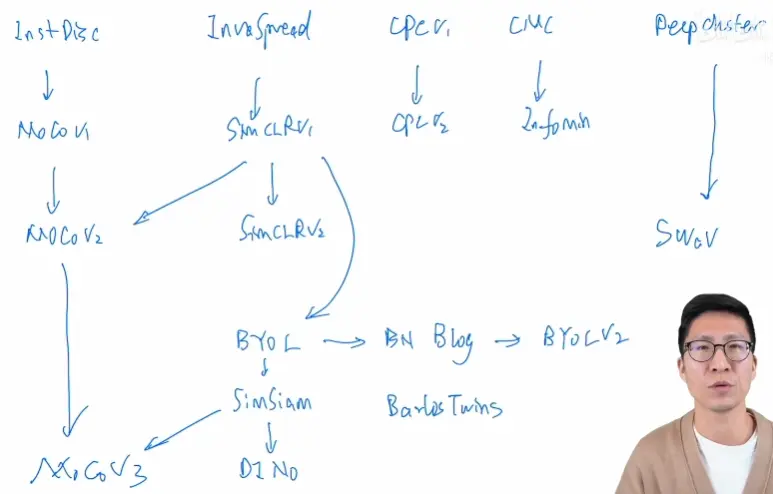
从最开始的 Inst Disc 开始,它提出了个体判别的任务,而且它提出用一个 memory bank 的外部数据结构去存储负样本,从而能达到一个又大又一致的字典去做对比学习
如果不用外部结构的话,另外一条路就是端到端的学习,也就是 Inva Spread 这篇论文做的,它就只用了一个编码器,从而可以端到端的学习,但因为受限于 batch size 太小,所以说它的性能不够好
CPC v1 这篇论文提出了 infoNCE 这个 loss,而且 CPC v1 是一个预测型的代理任务,不仅可以做图像,还可以去做音频、视频、文字和加强学习,是一个非常全能的结构
最后还有 CMC 这个工作,它就把两个视角的任务扩展到了多个视角,从而给接下来多视角或者多模态的这个对比学习打下了铺垫
另外还有一篇论文 deep cluster 并没有讲,它是基于聚类学习的,当时还没有用对比学习
接下来就进入了第二阶段,第二阶段主要是 MoCo v1 开始,它算是 Inst Disc 的一个延伸性工作,它把 memory bank 变成了一个队列,然后把动量更新特征,变成了动量更新编码器,从而能预训练一个很好的模型
MoCo 也是第一个能在很多视觉的下游任务上,让一个无监督预训练的模型比有监督预训练模型表现好的方法,它属于使用外部数据结构的
自然端到端的学习肯定也有延伸性的工作,也就是 SimCLR v1,SimCLR v1 跟 Inva Spread 方法是很像的,但是它用了很多的技术,比如说加大了 batch size,用了更多的数据增强,加了一个 projection head,训练的更长时间,总之所有的这些技术堆起来让 SimCLR 在 ImageNet 取得了非常好的的结果
然后 CPC v1 把这些技术也全都拿来用了一遍,CPC v2 就直接比 CPC v1 在 ImageNet 上高了 30 多个点
最后 CMC 把这些都分析一下,提出了一个 info Min 的这个原则,它说两个样本或者两个视角之间的互信息,要不多不少才是最好的
然后 MoCo 的作者看到 SimCLR 用的这些技术确实都很管用,所以就把这些即插即用的技术拿过来用在 MoCo 上,就有了 MoCo v2,MoCo v2 的效果就比 MoCo v1 和 SimCLR v1 都要好
然后 SimCLR 的作者也对模型进行了一些改动,得到了 SimCLR v2,但 SimCLR v2 主要是去做半监督学习的
之前提 deep cluster 主要就是为了引出 SwAV,SwAV 就是把聚类学习和对比学习结合起来的一个工作,也取得了不错的结果,但它这个不错的结果主要是来自于它提出的 multi crop 的技术,如果没有这个技术,它其实跟 SimCLR 或者 MoCo v2 的结果都是差不多的
第三阶段就来到了 BYOL 这个方法,因为处理负样本实在是太过麻烦,所以 BYOL 就说能不能不要负样本,能不能不去跟负样本做对比,结果它们发现还真行,就自己跟自己学,把一个对比任务变成一个预测任务就可以了,而且目标函数也很简单,不再使用 info NCE,而是用一个简单的 mse loss 就可以训练出来
但是大家都觉得很不可思议,所以立马就有一篇这个博文出来,它们就假设说 BYOL 能够工作主要是因为有 batch norm,这个 batch norm 提供了一种隐式的负样本,所以 BYOL 能够正常训练而不会模型坍塌
但是 BYOL 的作者很快就又发了另外一篇论文叫 BYOL v2,通过做了一系列实验以后,最后说 batch norm 只是帮助了模型的训练,如果能用另外一种方式能提供一个更好的模型初始化,BYOL 不需要 batch norm 提供的那些 batch 的统计量照样能工作,就把之前博客里提出来假设给打破了,但它们提出的其实也只是另外一个新的假设
紧跟着 BYOL,SimSiam 就出来了,SimSiam 就把之前的工作都总结了一下,因为它觉得之前的这些论文都在一点一点往上堆技术,那如果堆的太多了就不好分析了,这个领域也就不好再推进下去了,所以 SimSiam 就化繁为简,又提出来一个很简单的孪生网络的学习方法,它既不需要用大的 batch size,也不需要用动量编码器,也不需要负样本,然后照样能取得不错的结果,SimSiam 提出的假设就是说 stop gradient 这个操作是至关重要的,因为有这个操作的存在,所以 SimSiam 可以看成是一种 EM 算法,通过逐步更新的方式避免模型坍塌
另外还有一篇工作叫 barlow twins,它主要就是更换了一个目标函数,把之前大家做的这种对比或者预测变成了两个矩阵之间去比相似性,因为它已经是 21 年 3 月提出来的,所以很快就淹没在了 Vision Transformer 这波洪流之中
最后第四阶段就来到了 Vision Transformer,主要讲的两个工作就是 MoCo v3 和 DINO,其实都是把骨干网络从残差换成了 ViT,主要学习的方法其实是没有改变的
但是换成 Vision Transformer 以后,面临的问题都是训练不稳定或者不好训练,所以他们就提出了各自的方法:MoCo v3 提出来把 patch projection layer 冻住,DINO 就提出把 teacher 网络的输出先做一下归一化,做一下 centering。这 2 种方式都能有效的提高模型训练的稳健性,防止模型坍塌,让 Vision Transformer 用自监督的方式也能训练的很好
到此,又把所有的这些工作快速的串了一遍,现在对比学习还是一个很火的方向,虽然说可能没有 Vision Transformer 那么火,而且尤其是 MAE 火爆了以后,大家都去尝试掩码学习,而不是去尝试对比学习了,所以说对比学习又从一个火爆发展期变成了一个发展潜伏期
但是我对它的前途还是非常看好的,毕竟多模态的对比学习还是一个主流,CLIP 的效果就很好,而且在多模态里面,图像和文本对之间的对比学习 loss 还是一个标准的目标函数,基本上所有的工作都有在用,而且对比学习它属于一个想法而不是具体的一个工作,它在几十年之前就已经提出来了,所以接下来我们应该还是会看到很多对比学习的工作的,很期待对比学习跟其它方法的结合