在图像处理中,比较常见的任务有识别、检测、追踪等,这些任务的模型通常在训练阶段通过参数估计学得如何提取输入图像的特征,并建立输入图像与输出之间的映射,在应用阶段之间提取输入图像的特征,以得到相应的结果。
但有这样一类特殊的模型,其参数估计的目的不是通过提取特征来建立输入输出之间的映射,而是学习训练数据的分布,从而模型在应用阶段能够生成与训练数据相似的图像,通常这些图像与真实图像极为相似,我愿称之为“以假乱真”的哲学,这类模型就是生成式模型。
基于特定分布进行数据生成,是近年来机器学习领域研究和落地,通常由模型通过学习一组数据的分布,然后生成类似的数据。在机器学习领域,主流的生成模型共有几类:
- 生成式对抗网络(Generative adversarial net, GAN)
- 变分自编码器(Variational autoencoder, VAE)
- 流模型(Flow-based model)
这 4 类模型是基于不同的原理构建的,在本文中,我将介绍最常被用到的两类模型—— GAN 和 VAE。 GAN 和 VAE 分别是对抗学习和变分推断运用在深度学习的先例,此后学习隐变量的生成式模型很大一部分是基于这两种思路构建。
生成对抗网络(GAN)
生成式对抗网络(Generative adversarial net, GAN)是一种基于对抗学习的深度生成模型,最早由 Ian Goodfellow 在 《Generative Adversarial Nets》 提出,一经提出就成为了学术界研究的热点,Ian Goodfellow 也因此被人称为“GANs 之父”。
GAN 的基本思想
想必看过金庸小说的同学们都知道,“老顽童”周伯通有一样异于常人的本领——左右互博,有了这样一门武功,一来只有自己一个人也能玩得不亦乐乎,二来自己一个人就能切磋武艺。那是不是神经网络也可以通过这种方式来“修炼功夫”? 对抗学习就是基于这样的思想。
GAN 的思想很简单,总结起来就是以假乱真、相互对抗,而它的做法也是非常之简单粗暴,同时(或者说交替)训练两个网络,通过两个网络之间的博弈,从而达到互相促进的作用。
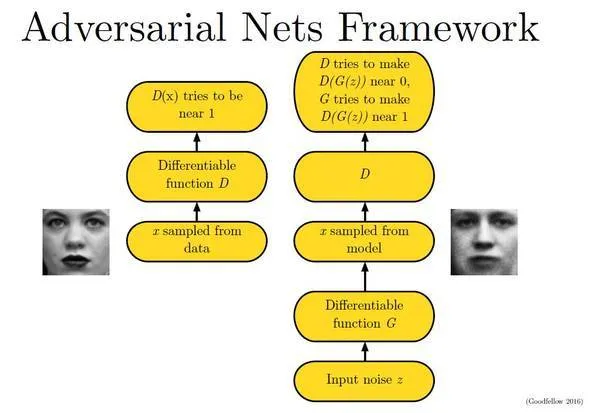
在 GAN 的整体框架中,用于训练的模型由两个网络组成,一个网络是生成器 G(generator),用于数据的生成;另一个网络是判别器 D(discriminator),用于对生成器生成的数据和训练数据进行真假判别。就拿图像生成为例,在图像生成模型的训练过程中:
- G是生成图像的网络,它接受一个随机的噪声z,并根据噪声生成图像,生成的图像记作G(z)
- D是一个判别网络,判别一张图像是不是“真实的”。它的输入参数是x,x代表一张图像,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图像。
在训练过程中,生成器和判别器就像是两个相互博弈的人,生成网络 G 的目标就是尽量生成真实的图像去欺骗判别网络 D,而 D 的目标就是尽量把 G 生成的图片和真实的图片分别开来。通过相互对抗,生成网络的生成能力和判别网络的判别能力将越来越强,最终当模型收敛时,我们将得到一个生成效果较好的生成器。
GAN 的具体实现和训练过程
为了描述 GAN 如何完成这个博弈过程,我们先定义 GAN 目标函数:
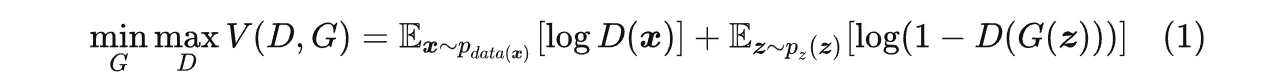
让我来解释一下这个公式:
- 这个式子由两部分构成。第一部分判别网络在真实图像上的对数似然(衡量“将真实图片判定为真”的能力),第二部分是判别网络在生成网络生成的图像上的对数似然的(衡量“将生成图片判定为假”的能力)。
- 在第一部分中,x 表示真实图像,D(x) 表示 D 判断真实图像是否真实的概率;在第二部分中,z 表示输入 G 的噪声,G(z) 表示 G 网络生成的图像,而 D(G(z)) 是 D 网络判断 G 生成的图片的是否真实的概率。
- 对于判别网络 D 来说,它的目的是能够区分生成图像和真实图像,这需要它对目标函数进行最大化。
- 对于生成网络 G 来说,它需要生成能够“骗”过 D 的数据,这就意味着它需要最小化第二项似然,由于在 G 进行参数更新时,不会对第一项的值造成影响,所以相当于生成网络在最小化似然函数。
借用论文里的一张图来说明这个过程,如下图:
在实际实现中,两个网络的更新是交替进行的,这导致在超参数调节不合适时,会出现参数更新不平衡的问题,不过这个问题不是这篇博客讨论的重点,暂且挂起不谈。
其训练过程如下图所示(来自原论文):

可以看到,在每一轮迭代中:
- 先更新由生成器生成数据,并由判别器对生成数据和训练数据进行判别,并利用梯度下降法对判别器的参数进行更新,这样对判别器的更新每次迭代要重复多次。
- 再利用生成器生成数据,并利用梯度下降法进行生成器的参数更新,每次迭代只需要更新一次
DCGAN
GAN 依然存在一些缺点,比如说训练不稳定,生成过程不可控,不具备可解释性等,于是后来出现了若干改进的版本。
当卷积神经网络再视觉领域大放光彩后,有人尝试将卷积操作融合到 GAN 中,也就是接下来要讲的深度卷积对抗生成网络(DCGAN)。
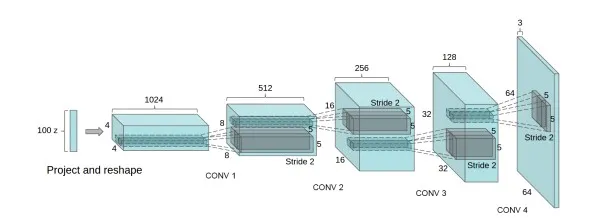
DCGAN 在《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS》被首次提出,是基于 GAN 的基本框架构建的生成模型,相比于 GAN ,它有了如下的改进:
- 取消所有 pooling 层。G 网络中使用转置卷积(transposed convolutional layer)进行上采样,D 网络中用加入 stride 的卷积代替 pooling;
- 在 D 和 G 中均使用 batch normalization;
- 去掉 FC 层,使网络变为全卷积网络;
- G 网络中使用 ReLU 作为激活函数,最后一层使用 tanh;
- D 网络中使用 LeakyReLU 作为激活函数;
DCGAN 的网络结构如下图:
DCGAN的训练过程与 GAN 相同,不过由于网络结构的改变,相比于 GAN ,DCGAN 的训练相对平衡,并且对局部特征的提取和还原能力较 GAN 强。但由于 DCGAN 属于早期的 GANs ,所以依然存在部分 GAN 的问题,在 DCGAN 后 GAN 又有了若干改进版,由于数量较多、有的比较水,这里就暂且挂起,不多叙述。
变分自编码器(VAE)
如果说 GAN 在数据生成模型领域为我们选择了一条简单粗暴的道路,那接下来要讲的模型则为我们提供了更加巧妙的办法。
变分自编码器(variational autoencoder, VAE)采用变分推断的方式来构建,与其他自编码器类似,变分自编码器也是由编码器和解码器组成,其本质是对一个含隐变量的函数进行密度估计。在训练过程中, VAE 的主要目的是进行极大似然估计,为了使得隐变量服从某一分布,在参数估计的过程中采用了变分推断的思想。
KL 散度
针对这一问题,在变分推断中,我们希望望找到一个相对简单好算的概率分布 q(z) ,使它尽可能地近似我们待分析地后验概率 p(z|x) ,以求我们能够用 q(z) 来近似 p(z|x) 。所以,为了度量两个概率分布 q(z) 和 p(z|x) 之间的距离,我们需要用到的一个工具就是 KL 散度。
KL 散度(Kullback-Leibler divergence)即相对熵,两个概率分布间差异的非对称性度量。如果两个分布越接近,那么 KL 散度越小,如果越远,KL 散度就会越大。对于两个分布 p 和 q ,其 KL 散度的公式为:

VAE 的基本思想
假设我们有一个判别任务,现有一个等待判别的事物 X ,这个事物有一个类别 y ,我们需要建立一个模型 y = f(x; w) 使得 p(y|X) 的概率尽可能大,即让 f(x; w) 尽可能地接近 y 。
如果我们使用生成式模型去解决这一问题,就需要用贝叶斯公式将这个问题转换成:
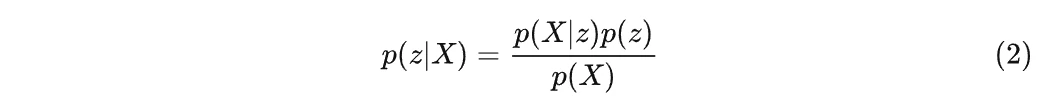
让我们再考虑一下数据生成问题,则问题可以转换成:当我们有式子左边的 p(z|X) ,应该如何生成一个符合某种 z 的 X(其中 z 为符合某种分布的隐变量)?
一个解决方式是:每次随机生成一个 X ,用 p(z|X) 计算概率,如果概率满足,则结束,如果不满足,则继续随机生成。但这种方式在某些情况下是不现实的,特别是右部的公式难以直接计算得到,所以,我们需要采用其他可行的方法来解决这一问题。这时就可以用到变分推断的思想结合自编码器,假设隐变量 z 服从某种分布来解决这一问题。
由于公式(2)中,右部的积分公式难以计算,我们可以用一个变分函数 q(z|X) 去代替 p(z|X) 。在 VAE 中,这个函数将采用编码器实现),当编码器能够将数据能够完美地将真实数据编码成服从一定分布的隐变量时,那解码器就能将服从这一分布的隐变量解码成接近真实数据的生成数据,从而解码器将能作为生成器使用,这便是 VAE 的基本思想。
为了能采用 q(z|X) 去代替 q(z|X) ,我们需要使得两个分布布尽可能地相近,于是乎我们选择了 KL 散度这个指标用来衡量两者的相近程度,于是有:
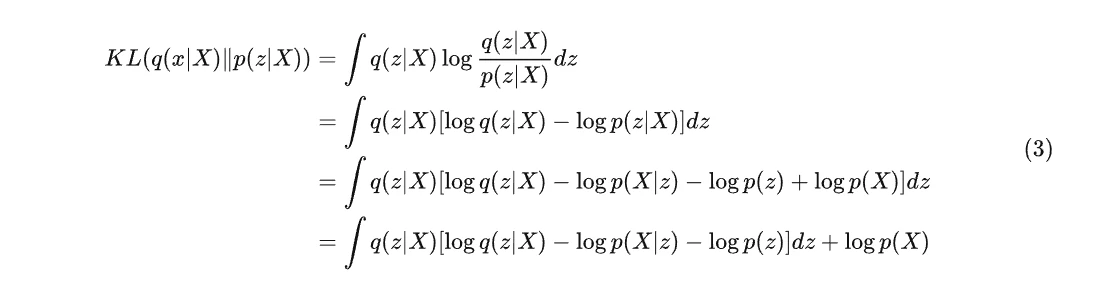
左右整理一下,我们可以得到:
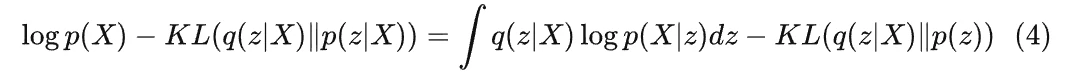
我们知道在 X 给定的情况下,p(X) 是个固定值,而我们的目的是最大化 KL(q(z)||p(z|X)),所以我们需要让等号右边那部分尽量大,所以,为了找到一个好的 q(z|X),使得它和 p(z|X) 尽可能地相近,我们需要:
- 右边第一项的对数似然的期望最大化
- 右边第二项的 KL 散度最小化
VAE 的实现
为了将数据编码到隐变量,我们需要假设隐变量 z 服从某种分布。通常我们假设 z 服从高斯分布,则计算公式为:
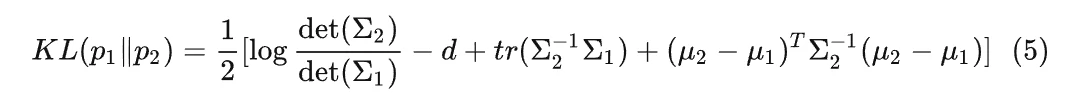
为了计算方便,我们再进行一个比较强的假设,假设隐变量服从标准正态分布,即服从均值为 0 ,方差为单位矩阵的高斯分布,则:
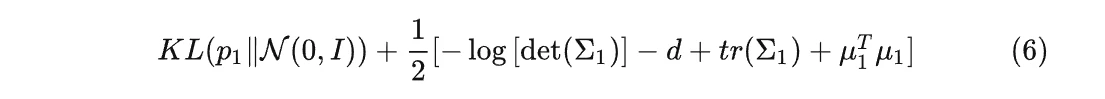
接下来,我们就能通过构建编码器,得到一个由输入 X 求解隐变量 z 的函数,利用梯度下降法,可根据公式(6)对网络参数进行优化,使得编码器近似接近我们想要拟合的函数。
而对于公式(4)的第一项,我们可以通过构建一个从 z 再变回 X 的解码器,通过梯度下降法进行解码器参数优化,从而实现对 p(X|z) 的极大似然估计,我们将得到一个将符合高斯分布的隐变量变成生成数据的生成器。
CVAE
条件变分自编码器(CVAE) 是 VAE 的变种。VAE 是无监督学习,但是当我们需要网络能够根据我们的需要生成特定的图片,需要加入标签 y 辅组训练,这就是 CVAE。
CVAE 可以看作是有监督学习的 VAE 。将公式(4)的右部变为:
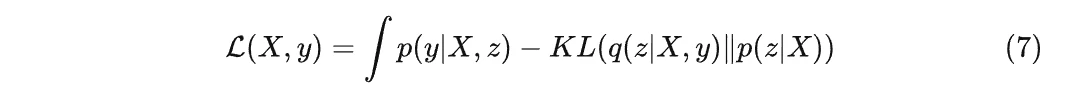
在这里,自编码器需要重构的是 y|X 而不是 X, 所以最终的生成器能够根据标签进行采样而生成对应的数据。