原文
ViT 论文链接:https://arxiv.org/abs/2010.11929
这次李沐博士邀请了亚马逊计算机视觉专家朱毅博士来精读 Vision Transformer(ViT),强烈推荐大家去看本次的论文精读视频。朱毅博士讲解的很详细,几乎是逐词逐句地讲解,在讲解时把 ViT 相关领域的研究也都介绍了,听完之后收获满满。
ViT 应该是过去一年计算机视觉领域影响力最大的一个工作。ViT 挑战了卷积神经网络在计算机视觉领域的绝对统治地位。ViT证明如果能在足够大的数据集上去训练,那么就可以不需要卷积神经网络,直接使用标准的 Transformer 也能把视觉问题解决好。ViT 不仅在计算机视觉领域挖了一个大坑;同是它也打破了 CV 和 NLP 之间的壁垒,在多模态领域也挖了一个大坑。可以说,ViT 开启了计算机视觉新时代。
标题、摘要、引言、结论
首先是论文标题,论文标题的意思是:一张图片等价于很多 16 × 16 的单词,Transformer 用于大规模图像识别 。16 × 16 是指将一张图片划分成若干个块(patch),每一个 patch 大小为 16 × 16。这样一张图片就可以看作是若干个 patch 组成。这篇论文的作者还是蛮多的,有12个作者,可以看出这篇论文工作量确实很大,论文作者全部来自于 Google。

下面是论文摘要,摘要写的很简洁,总共只有4句话。
- 尽管 Transformer 已经成为自然语言处理任务事实上的一种标准,但是在计算机视觉上的应用还是非常有限。
- 在计算机视觉领域,注意力机制要么和卷积神经网络一起使用,要么在保持原有网络结构不变的情况下替换局部的卷积运算(例如 ResNet-50 中把其中每某一个残差块使用注意力机制替代)。
- 本文证明对卷积神经网络的依赖不是必要的,原始的 Transformer 可以直接应用在一系列小块图片上并在分类任务上可以取得很好的效果。
- 在大的数据集上预训练的模型迁移到中小型图片数据集上 (ImageNet, CIFAR-100, VTAB等),与目前最好的卷积神经网络相比,ViT 可以取得非常优秀的结果并且需要更少的训练资源。
(但是仍然需要2500天 TPUv3 训练天数,目前的深度学习真的是进入到了大力出奇迹的时刻,在计算资源上学术界很难能比过工业界。)

在介绍引言之前,朱毅博士首先介绍了 Transformer 用在计算机视觉上的一些难处。主要是如何将2D图片数据转换成 1D数据?目前 BERT 能够处理的序列长度是512,如果直接将图像像素转换成 1D。即使是 224 × 224 大小的图片,其序列长度也有5万多,计算复杂度将是 BERT 的100倍,如果是检测或分割任务,那计算复杂度就更大了。
引言前两段主要是交代故事背景,在自然语言处理任务上,通常会在大的训练集上去训练 Transformer,然后在小的特定任务数据集上去微调。目前可以训练含有上千亿参数的 Transformer 模型,且随着模型和数据集的增加,并没有出现饱和现象。在计算机视觉领域,卷积神经网络仍然占据主导。最近一些新的研究,有的将自注意力机制和卷积神经网络结合起来训练(即在较小的特征图上使用自注意力机制),这是一种减少序列长度的方法;还有的是使用局部图片作为输入,然后使用 Transformer,也有论文研究分别在图像高度或宽度上使用 Transformer,这些都是为了减少序列长度。但以上方法都存在不足,都是针对特定任务来使用,在大规模图像识别数据集, 像 ResNet 这样的网络仍然是主流。

下面作者介绍如何将 Transformer 用在计算机视觉。首先将图像划分为一个个 patch,然后使用全连接网络进行线性变换,这样就得到了 patch 线性变换序列,最后将 patch 输入到 Transformer,这里可以将 patch 看成是一个个单词。举个例子,假设图像大小是 224 × 224,划分成 16 × 16 的 patch, 则最终会有196个patch。可以看到,整篇论文处理流程还是很简洁的,基本上没有什么技术难点。
紧接着作者指出,Transformer 与卷积神经网络相比缺少归纳偏置,例如相关性(locality)和平移不变性(translation equivariance)。因此为了得到更好的结果,需要有足够多的训练数据,最后一段就是介绍模型效果,果然效果拔群。

下面是论文结论部分。第一段总结本文做的工作,图片处理成 patch 序列,然后使用 Transformer 去处理,取得了接近或超过卷积神经网络的结果,同时训练起来也更便宜。第二段是未来展望:
- 一是和目标检测和分割结合起来,ICCV 2021 最佳论文 Swin Transformer 就证明了 Transformer 在检测和分割任务也能取得很好的效果;
- 另一个是自监督预训练,因为本文是有监督预训练,自监督和有监督预训练还存在着很大的差距,最近何恺明博士的新论文 MAE 就研究了这个问题;
- 最后是更大规模的 ViT,半年之后作者团队就提出了 ViT-G。

相关工作
下面是相关工作,总共有6段。第1段说2017年 Transformer 被提出来以后,已经成为许多 NLP 任务最先进的方法,代表性的工作有 BERT(完形填空去预测缺少的词)和 GPT(语言模型,预测下一个词)。第2段是说,将自注意力用于图像处理,需要每个像素和每个像素两两交互,复杂度与像素数量平方成正比。因此在图像处理中使用 Transformer 需要做一些近似处理,包括在局部图像块用自注意力、使用稀疏的 Transformer 以及在轴上使用注意力,这些方法都取得了很好的效果,但是需要复杂的工程能力去实现硬件加速。

接着作者介绍和本文最接近的相关工作,ICLR 2020 的这篇论文使用的 patch 大小是 2 × 2,处理的数据集是 CIFAR-10 数据集,和 ViT 很接近,也是从头到尾使用注意力机制来处理。和这篇论文不同之处是我们的工作显示更大规模的预训练可以使得 Transformer 能取得比 CNN 更好的效果;同时我们使用了更大的 patch,我们的模型可以处理中等尺度的图片。下面是自注意力机制和 CNN 结合的一些工作,包括图片分类、物体检测、视频处理、文本视频任务等。
另一个最近的工作是 iGPT, 将 Transformer 用于生成式模型,在 ImageNet 上可以取得72%的准确率。我们的工作研究了更大规模的数据集,主要是 ImageNet-21k 和 JFT-300M。

ViT模型、实验
下面是ViT模型介绍,模型总览图如下图所示。输入为一张图片,将图片划分成9个patch,划分后的 patch 序列经过线性投射层变换得到 patch embedding ,与此同时对这些 patch 还添加了 position embedding,这样每一个 token 既包括图像信息又包括了位置信息。这里作者还借鉴了 BERT,添加了 class embedding,也包括位置信息,最终将这些 token 输入到 Transformer,最后 class embedding 对应的输出经过 MLP Head 进行类别判断,整个模型包括 L 个 Transformer。
下面是具体实现,假设图像大小是 224 × 224 × 3,划分成 16 × 16 × 3 的 patch,则最终会有196个 patch。将每一个 patch 拉平,则每一个 patch 维度变为 768。线性投射层使用 E 表示,维度为 768 × 768 ( D ),D 是参数。则经过线性变换后输出为: X E = 196 × 768 × 768 × 768 = 196 × 768,输出为196个 token,每个 token 维度为768。因为还有一个 class token,位置编码维度为 1 × 768,和 patch embedding 直接相加(sum),则最终输入维度为 197 × 768。
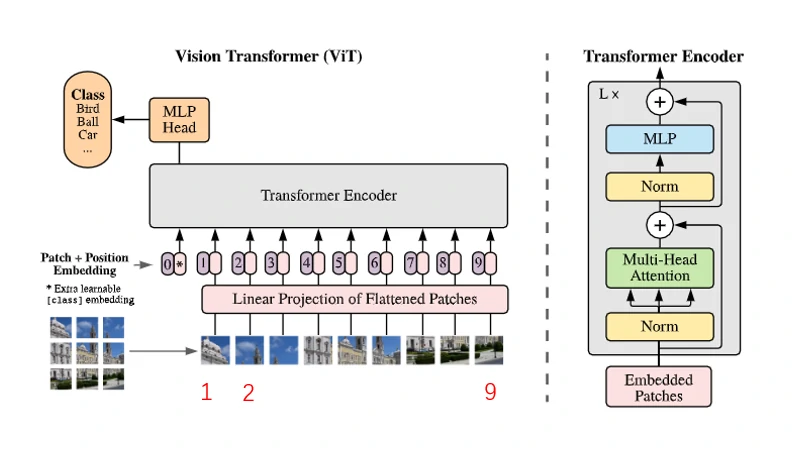
下面是论文原文介绍,首先是 patch embedding 的处理,然后是 class embedding 的处理,最后是 position embedding 的处理。 在附录里作者比较了各种 position embedding 的实验结果,以及 class token 的使用对最终分类结果的影响。为了减少对 Transformer 的改动,作者这里还是使用了 class token 和 1D position embedding。

下面是归纳偏置介绍,主要是所有 patch 的空间关系都需要从头去学;另一个是将注意力机制和 CNN 特征图结合起来一起使用,构建混合模型,最后是微调模型以及对大尺度图片的处理。

下面是论文实验部分。这里作者主要设计了三种不同大小的 ViT 模型,如下表所示。
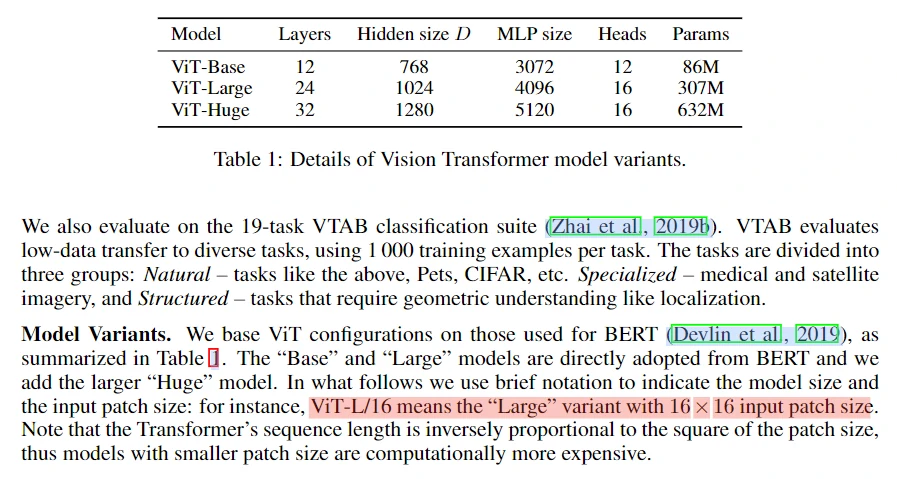
第一个实验结果是作者分别将 ViT 模型在不同的数据集上去预训练,然后在基准数据集上去比较,虽然从表中看到 ViT-H/14 比卷积模型 BiT-L 准确率高得并不多,但是从训练天数可以看到,ViT-H/14 需要的训练天数是 BiTL-L 的 1/4 左右,训练代价更小。
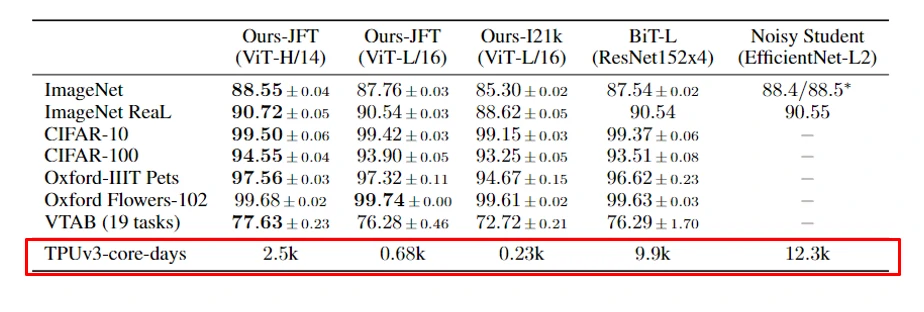
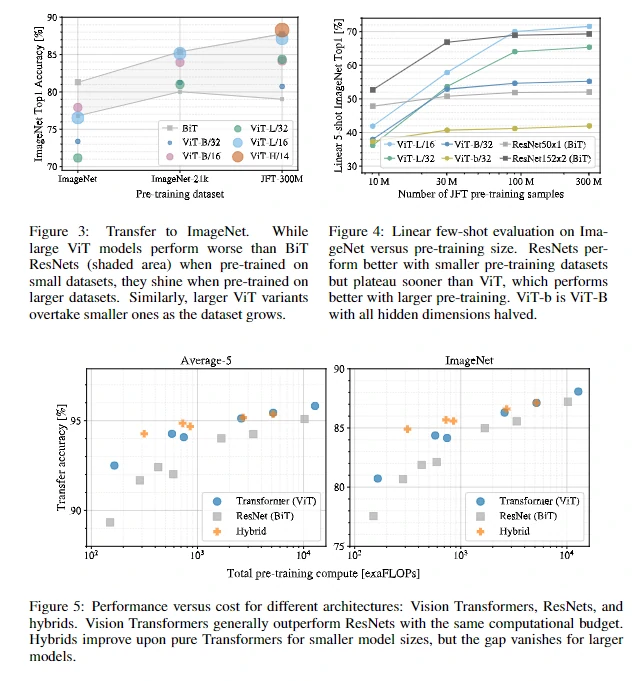
图3、4 表明随着预训练数据集的增大,Transformer 的效果会渐渐好于 ResNet,这表明 Transformer 有很好的可扩展性。图5表示,在同样运算能力下,Transformer 的效果也是好于 ResNet。
下面是一些可视化结果,中间这张图可以看到虽然本文使用的是 1D 的位置编码,但是网络仍然能学到不同 patch 位置间关系;右边这张图则表示 Transformer 学习能力,可以看到随着网络越深,获取全局信息能力越强。

最后作者也做了一个小的自监督实验,证明了 Transformer 是优于卷积神经网络,最近大火的 MAE 也证明了这一点。