本篇学习报告选取的内容为《Unsupervised Representation Learning by Predicting Image Rotations》,出自2018年的International Conference on Learning Representations(ICLR)。该篇论文主要针对自监督任务问题提出了一种通过构造识别图片旋转情况(作为一种伪标签)的辅助任务来提高模型学习图片语义信息的能力,从而对预训练模型进行微调来应对图像分类等下游场景任务。
研究背景和内容
目前各种卷积神经网络模型凭借其优越的性能,在机器视觉、自然语言等领域取得了不小的成功,但是这些方法大多都采用了大量需要手工标注的数据对网络模型进行训练优化,而这样的标注一般需要大量的人力与物力,并且在现实场景中,无标签的数据才是大多数,故利用这些海量的无监督数据来改进监督学习任务是非常有必要的。
自监督是无监督的一个重要分支,具体表现为从无监督的数据中,通过巧妙地设计自动构造出有监督数据(伪标签),并利用这些数据学习一个预训练模型。识别伪标签就成为预训练模型需要完成的任务,如果模型能较好地完成这个任务,说明它能够学习到输入中的高级语义信息,泛化能力比较强。
自监督学习的方法主要可以分为3类:(1)基于上下文(Context based)、 (2)基于时序(Temporal Based)、(3)基于对比(Contrastive Based)。
基于时序的方法主要利用样本间的许多约束关系,可以是随机打乱视频帧,然后学习对它们排序[1],也可以是从视频里取一帧,然后选临近的帧作为正例,随机的离得远的帧作为负例,来学习训练网络[2]等等。
基于对比的方法主要通过学习对两个事物的相似或不相似进行编码来构建表征,可以是利用模型判断全局特征和局部特征是否来自同一图像[3]。
而基于上下文的方法则专注于数据本身的上下文信息,构造出辅助任务,而对于图片一般可以变现为抠图,除去图片中的某一部分,利用剩余的部分来预测剔除的部分作为辅助任务[4]。而本文则采用的是将图片做几何旋转变换,将旋转情况作为辅助任务来训练具有较好识别能力的网络模型。
方法分析
该论文采用图片旋转作为几何变换,具体表现为0、90、180和270度的旋转变化,如图1所示。

这几个离散的旋转角度就是该方法中自己创建的伪标签(这里分别设为y=0,1,2,3),然后把这些不同旋转角度的图片放入到ConvNet网络,让其不断训练学习,计算出四种旋转变换的概率,选最大概率作为预测结果(即四分类任务),具体步骤如图2所示,其中g(.)为旋转变换函数,F(.)为对图片旋转变换识别得到的概率,如Unsupported image type.代表旋转90度的概率。
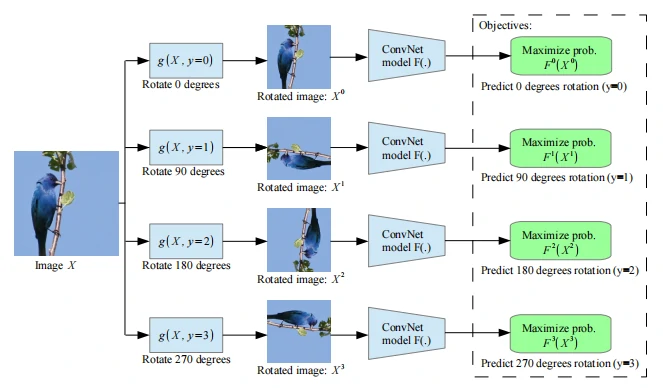
为了能识别出图片的几何变换,需要学会关注图像中高语义的部分,如眼睛、鼻子、尾巴和头部等,即更好地学习图片的语义信息,如图3所示。自监督下得到的效果与有监督学习的效果相似,这样便可以根据下游任务对模型进行微调来应对不同的下游任务。


实验与结果
为了对旋转图片训练得到的模型进行评估,下游任务分别利用了多种常见数据集进行实验。
CIFAR-10实验
将经过旋转识别训练后的ConvNet称为RotNet,并在CIFAR-10实验中采用Network-In-Network(NIN)结构的RotNet。同时为了找出最好的RotNet结构组成,依次设计了含有3、4、5个卷积模块(每个卷积模块包含3层卷积)的RotNet模型,然后将每张图片的四个角度变换的副本传入RotNet进行训练,进行对比实验,结果如表1所示。发现在第二个卷积模块得到的特征图准确度最高,并且卷积模块越多,每个模块(第一个除外)的准确度越高。

同时,为了使得RotNet模型更佳,文中研究了与离散旋转的数量关系。作者额外设计了一组含有8个旋转角度(0, 45, 90, 135, 180, 225, 270, 315)和2组含有2个旋转角度(0,180)、(90,270)的情况进行对比。结果如表2所示,并不是越多角度越好(过多角度可能产生视觉误差),之前的4个角度方案更佳适合。

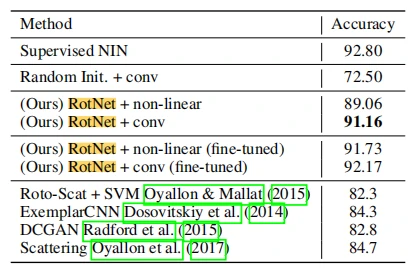
基于上面的结论,在和其他无监督方法对比时,作者用到的是在RotNet模型中第二个卷积模块产生的特征图像,然后设计了两种分类器:由三个全连接层组成的非线性分类器和由三个卷积层+线性预测层(相当于一个卷积模块)组成的分类器,即最后分别是RotNet + non-linear和RotNet +conv的方法。结果如表3所示。相较其他无监督方法,该论文提出的方法(尤其RotNet +conv)更为出色,并且也只是略低于有监督情况下的准确度,并且显示微调对准确度的提升是有帮助的。
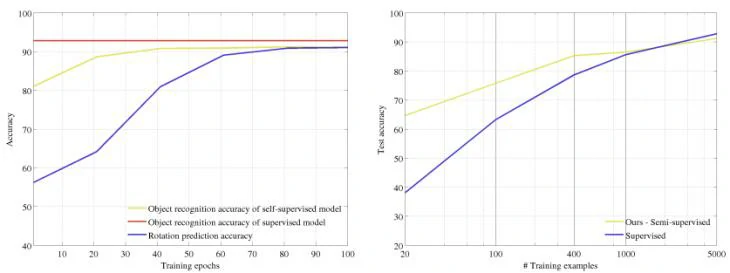
同时作者还严谨地探究了下游任务图片分类准确度与辅助任务旋转角度分类准确度之间的联系,这里图片分类选用的是RotNet + non-linear方法。结果如图7左边子图所示,旋转预测任务的能力提高有助于下游任务的准确度提升。
受自监督取得较好结果启发,作者也将该思想和RotNet用作半监督下的研究,在训练分类器时使用的只是可用图片的一组子集及其对应标签,并将该方法与一种用所有可用图片训练分类器的全监督方法进行对比,结果如图4所示。实验结果表明,在可用图片样例较少时,半监督的方法优于全监督的方法。
IMAGENET等其他数据集实验
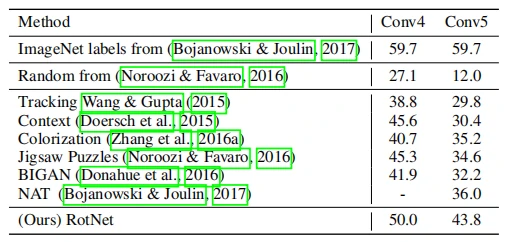
这里将ConvNet改为AlexNet,并且AlexNet的卷积层没有归一化单元、dropout单元等部分,而是在每个线性层之后设置批处理形式的归一化单元,并且选用非线性分类器进行分类。同时受Noroozi & Favaro[5]的启发,将Imagenet数据集的子集ISLVRC的1000类分类任务作为此次的对比任务,并且分别用在AlexNet的conv4和conv5得到特征图片送入分类器进行分类预测。结果如图5所示,该方法优于大多其他无监督的方法。
此外还将非线性分类器换成逻辑回归线性分类器,对Imagenet-ISLVRC进行分类,结果如表4所示。
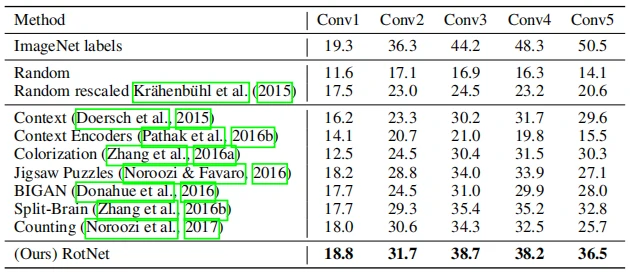
受到Zhou等人[6]的启发,作者将采用逻辑回归分类器的方法运用到场景分类数据集Places的205类分类任务中,并与其他无监督方法进行对比,结果如表5所示。
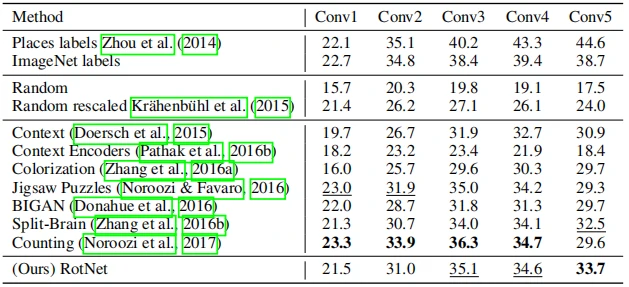
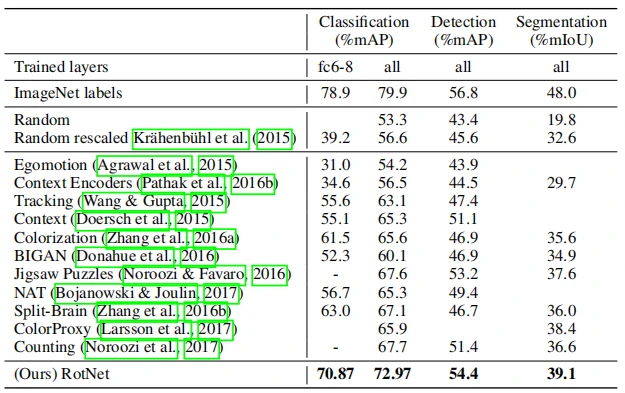
最后,作者为了更好地说明本文提出的自监督方法的广泛适用性,在PASCAL VOC 2007数据集进行了分类和检测实验,同时利用PASCAL VOC 2012数据集去探究在分割任务中的效果。在分类任务中,分别采用在conv5前修复特征信息(column fc6-8)和对整个网络进行微调(column all)来应对下游任务。在分类任务和目标检测任务中,评估指标采用平均精度均值mAP,而平均交并比mIoU则用作分割任务的性能指标。结果如表6所示,实验结果证明该方法优于其他无监督的方法,并且在检测方面,与有监督方法56.8%的mAP较为接近。
总结与思考
在有监督研究取得成功后,对于无监督、自监督下的分类、检测等任务就更具挑战性但也同时更具实用性。本文提出旋转作为自监督的辅助任务,虽然简单,但结果显示对于旋转情况的良好学习实际上对于网络模型在图片语义特征的学习中,提供了强大的监督信号,增强了其学习的泛化能力。而之前的一些基于几何变换的辅助任务,虽然得到的结果也同样可观,但前期的几何变换以及对于该变换任务的完成却较为复杂。
此外,该论文凭借其简单而又有效的思路,为后面学者研究探索自监督提供了巨大的帮助与启发,像Zeyu Feng等人[7]就在该论文的基础上进行更为深入的研究和改进,并取得不错的结果。
该论文提出的旋转任务在取得较好效果的同时,也存在一定的局限性。就好比一个圆形乃至对称的几何体,当采取旋转变换时,其前后的差别并不会太大,对于训练识别图片语义的效果理论上就会大打折扣。而且对于旋转角度的选定也是极为严格的,如果像旋转一个45度角的话,很有可能就会使得旋转后的图片信息不完整或者出现图片阴影误差,这都是旋转操作需要考虑和改进的地方,或许额外增加一些变换操作或者一些限制条件,就可能会降低因旋转操作自身的一些限制给模型性能带来的影响。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10288
[1] Lee H Y , Huang J B , Singh M , et al. Unsupervised Representation Learning by Sorting Sequences[C]// 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017.
[2] Sermanet P , Lynch C , Chebotar Y , et al. Time-Contrastive Networks: Self-Supervised Learning from Video[C]// 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
[3] Hjelm R D , Fedorov A , Lavoie-Marchildon S , et al. Learning deep representations by mutual information estimation and maximization[J]. 2018.
[4] Pathak D , Krahenbuhl P , Donahue J , et al. Context Encoders: Feature Learning by Inpainting[J]. IEEE, 2016.
[5] Noroozi M , Favaro P . Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles[C]// Springer, Cham. Springer, Cham, 2016.
[6] Zhou B , Lapedriza A , Xiao J , et al. Learning Deep Features for Scene Recognition using Places Database[J]. Advances in Neural Information Processing Systems, 2014, 1.
[7] Feng Z , Xu C , Tao D . Self-Supervised Representation Learning by Rotation Feature Decoupling[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2019.
论文下载地址:https://arxiv.org/abs/1803.07728
论文源码地址:https://github.com/gidariss/FeatureLearningRotNet