对比学习综述
发展历程大概可以分为四个阶段:
百花齐放
- InstDisc(instance discrimination)
- CPC
- CMC
- 在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代
CV双雄
- MoCo v1
- SimCLR v1
- MoCo v2
- SimCLR v2
- CPC、CMC的延伸工作
- SwAV
- 这个阶段发展非常迅速,上述工作有的间隔一两个月,有的间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新
不用负样本
- BYOL以及它后续的一些改进
- 最后SimSiam将所有的方法都归纳总结了一下,融入到了SimSiam的框架中,基本上是用卷积神经网络做对比学习的一个总结性工作
transformer
- MoCo v3
- DINO
- 对于自监督学习来说,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的
这里只是把最有联系的一些工作串到一起,讲述他们的相似之处和不同之处
百花齐放
《Unsupervised Feature Learning via Non-Parametric Instance Discrimination》
InstDisc(instance discrimination)
这篇论文提出了个体判别任务以及memory bank

图1:本文方法受到有监督学习结果的启发,如果将一张豹子的图片喂给一个已经用有监督学习方式训练好的分类器,会发现他给出来的分类结果排名前几的全都是跟豹子相关的,有猎豹、雪豹,总之从图片来看这些物体都是长非常相近的;而排名靠后的那些判断往往是跟豹子一点关系都没有的类别
通过很多这样的现象,作者觉得让这些图片聚集在一起的原因并不是因为它们有相似的语义标签,而是因为这些照片长得太像了,某一些 object 就是很相似,它们跟另外一些 object 就是不相似,所以才会导致有些分类分数都很高,而有些分数非常低
最后作者根据这个观察提出了个体判别任务:无监督的学习方式就是把按照类别走的有监督信号推到了极致,现在把每一个 instance 都看成是一个类别,也就是每一张图片都看作是一个类别,目标是能学一种特征能把每一个图片都区分开来
所以图一画的很好,起到了一石二鸟的作用:不仅很简单的介绍了研究动机,自然而然地引入了问题,而且用一句话的形式引入了个体判别这个代理任务
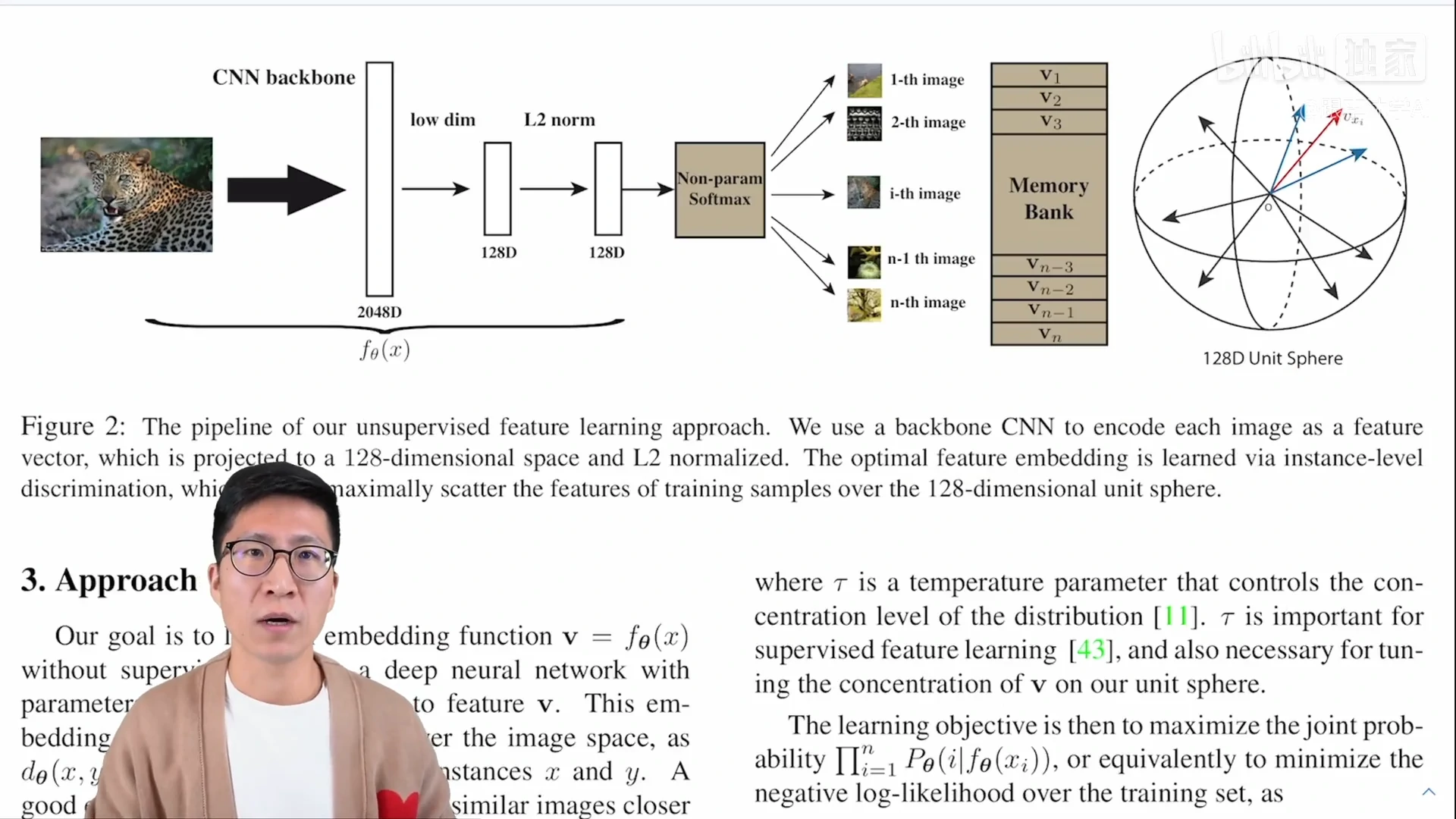
图二讲述了文章中的方法
- 通过一个卷积神经网络把所有的图片都编码成一个特征(这些特征在最后的特征空间里能够尽可能的分开,因为对于个体判别任务来说每个图片都是自己的类,所以说每个图片都应该和别的图片尽量的分开)
- 训练这个卷积神经网络使用的是对比学习,所以需要有正样本和负样本,根据个体判别这个任务,正样本就是这个图片本身(可能经过一些数据增强),负样本就是数据集里所有其它的图片
- 做对比学习,大量的负样本特征到底应该存在哪呢?本文用了 memory bank 的形式:就是说把所有图片的特征全都存到 memory bank 里,也就是一个字典(ImageNet数据集有128万的图片,也就是说memory bank里要存128万行,也就意味着每个特征的维度不能太高,否则存储代价太大了,本文用的是128维)
前向过程:
- 假如batch size是256,也就是说有256个图片进入到编码器中,通过一个 Res 50,最后的特征维度是2048维,然后把它降维降到128维,这就是每个图片的特征大小
- batch size 是 256 的话也就意味着有256个正样本,那负样本从哪来呢?自然是从 memory bank 里随机地抽一些负样本出来。本文抽了4,096个负样本出来
- 有了正样本也有了负样本,就可以用NCE loss 计算对比学习的目标函数
- 一旦更新完这个网络,就可以把 mini batch里的数据样本所对应的那些特征,在 memory bank 里更换掉,这样 memory bank 就得到了更新
- 接下来就是反复这个过程,不停的去更新这个编码 t,不停的更新这个 memory bank,最后学到这个特征尽可能的有区分性
本文的方法还有很多细节都设计的非常巧妙
- 比如说 proximal regularization:它给模型的训练加了一个约束,从而能让 memory bank 里的那些特征进行动量式的更新,跟 MoCo 的想法是非常一致的
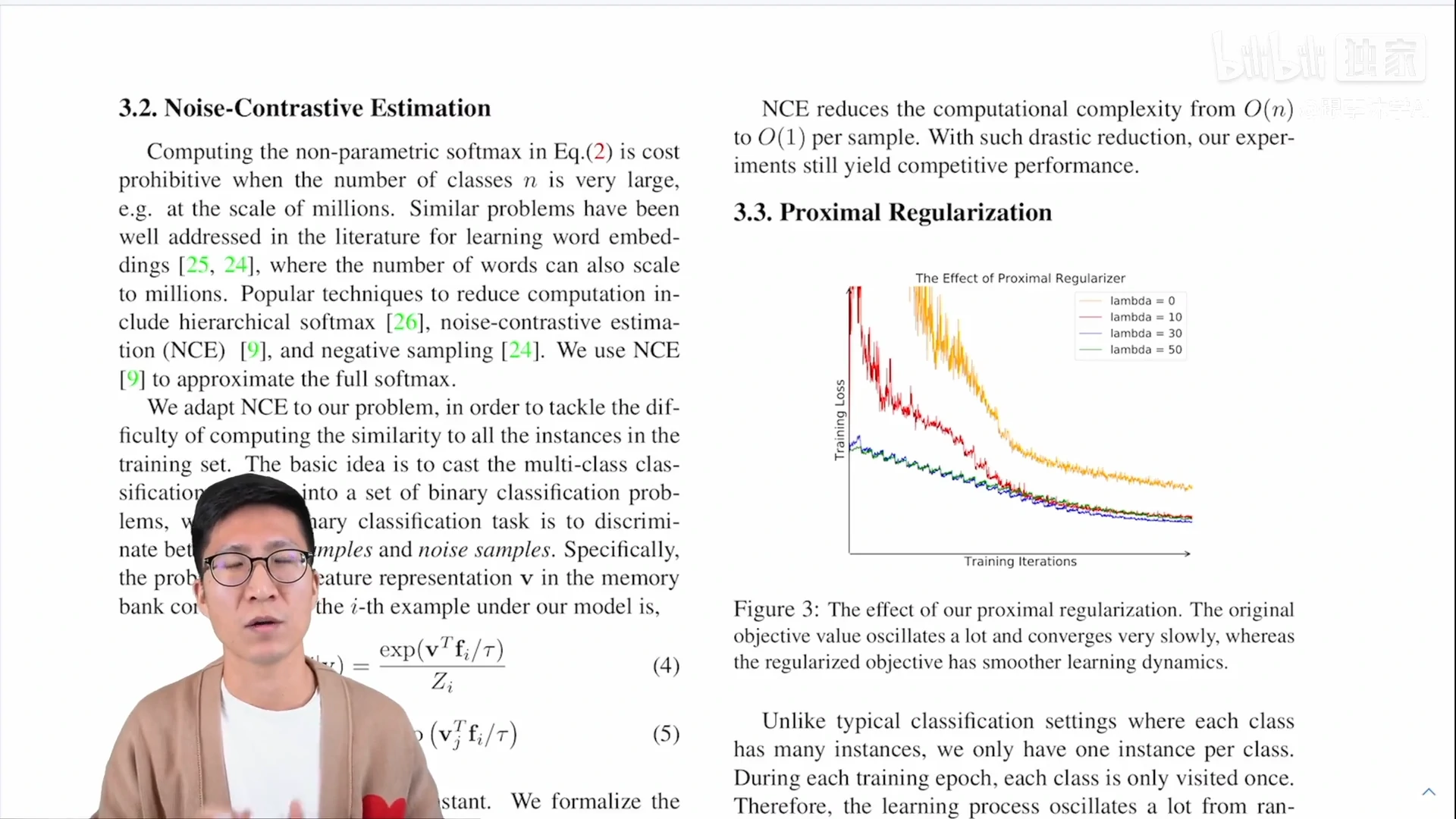
另外设置里面超参数的设定,比如说算 loss 的时候温度的设置是0.07,选了4,000个负样本,训练是200个epochs,batch size 是256,起始的 learning rate 是0.03,之后其它论文(尤其是 MoCo)所有的这些实验细节,MoCo 都是严格按照 Inst Disc 来的,这些超参数都没有进行更改。所以说 Inst Disc 这篇论文也是一个里程碑式的工作:它不仅提出了个体判别这个代理任务,而且用这个代理任务和 NCE loss 做对比学习,从而取得了不错的无监督表征学习的结果,同时它还提出了用别的数据结构存储这种大量的负样本,以及如何对特征进行动量的更新,所以真的是对后来对比学习的工作起到了至关重要的推进作用。

《Unsupervised Embedding Learning via Invariant and Spreading Instance Feature》

这是一篇 CVPR 19 的论文,跟其它论文相比,它的影响力可能不是那么大,之所以提一下这篇论文,是因为它可以被理解成是 SimCLR 的一个前身。它没有使用额外的数据结构去存储大量的负样本,正负样本就是来自于同一个 mini-batch,而且它只用一个编码器进行端到端的学习。
这篇文章也没有给自己起名字,所以就像 Inst Disc 一样就叫它 Inva Spread 好了,所以写论文的时候,最好还是给自己的方法起个名字,而不是叫 ours,这样方便别人记住也方便别人引用,也是一个双赢的事情。
本文的想法其实就是最基本的对比学习

如图1所示,同样的图片通过编码器以后它的特征应该很类似,不同的图片它的特征出来就应该不类似,这就是题目中说的 invariant 和 spreading,就是说对于相似的图片、物体,特征应该保持不变性,但是对于不相似的物体或者完全不沾边的物体,特征应该尽可能的分散开。
具体做法:
代理任务也是选取了个体判别这个任务
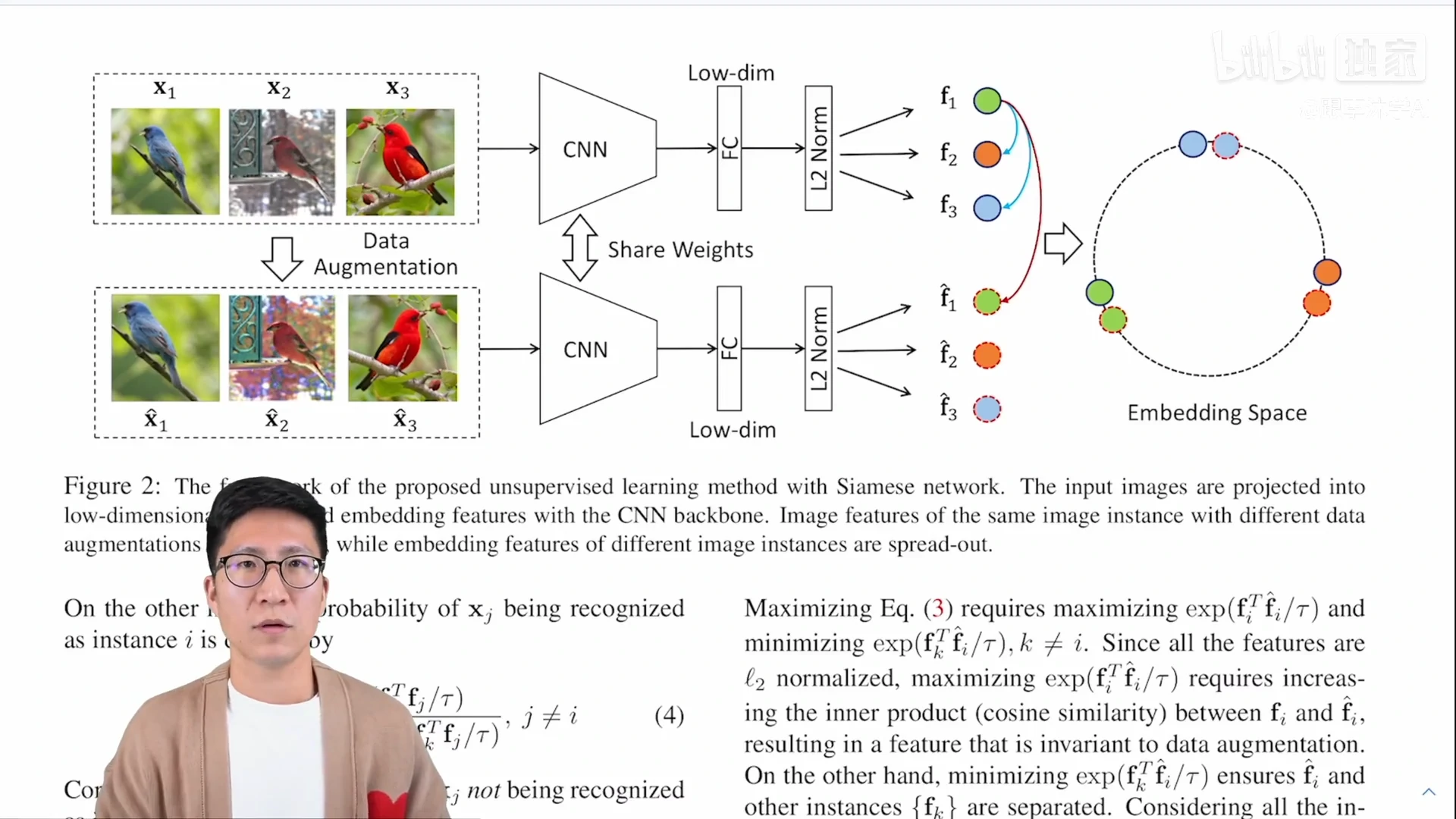
前向过程:
- 如果 batch size 是256,也就是说一共有256个图片,经过数据增强,又得到了256张图片
- 对于 x1 这张图片来说, x1’ 就是它的正样本,它的负样本是所有剩下的这些图片(包括原始的图片以及经过数据增强后的图片),也就是说正样本是256,负样本是(256 - 1) * 2,就是除去样本本身之外 mini-batch 剩下的所有样本以及它经过数据增强后的样本
- 它和 Inst Disc 的区别:Inst Disc中,正样本虽然是256,它的负样本是从一个 memory bank 里抽出来的,它用的负样本是4096甚至还可以更大
- 本文为什么要从同一个 mini-batch 里去选正负样本?因为这样就可以用一个编码器做端到端的训练了,这也就是MoCo里讲过的端到端的学习方式
- 剩下的前向过程都是差不多的,就是过完编码器以后,再过一层全连接层就把这个特征的维度降的很低,就变成128,正样本比如说上图中绿色的球在最后的特征空间上应该尽可能的接近,但是这个绿色的球跟别的颜色的特征应该尽可能的拉远
- 本文所用的目标函数也是 NCE loss 的一个变体
- 这篇论文,刚好属于另一个流派,也就是端到端的学习,而且只用一个编码器,不需要借助外部的数据结构去存储大量的负样本,它的正负样本都来自于同一个 mini-batch
- 既然它跟 SimCLR 这么像,为什么它没有取得那么好的结果呢?就是之前在 MoCo 那篇论文里反复强调过的,就是这个字典必须足够大,也就是说在做对比学习的时候,负样本最好是足够多,而本文的作者是没有 TPU 的,所以说它的 batch size 就是256,也就意味着它的负样本只有500多个,再加上它还缺少像 SimCLR 那样那么强大的数据增广以及最后提出的那个 mlp projector,所以说呢这篇论文的结果没有那么炸裂,自然也就没有吸引大量的关注,但事实上它是可以理解成 SimCLR 的前身
《Representation Learning with Contrastive Predictive Coding》
CPC(contrastive predictive coding)
一般机器学习分为判别式模型和生成式模型,个体判别显然是属于判别式范畴的,那肯定就会有一些生成式的代理任务,比如最常见的预测型的任务
cpc 这篇论文其实非常厉害,因为它是一个很通用的结构
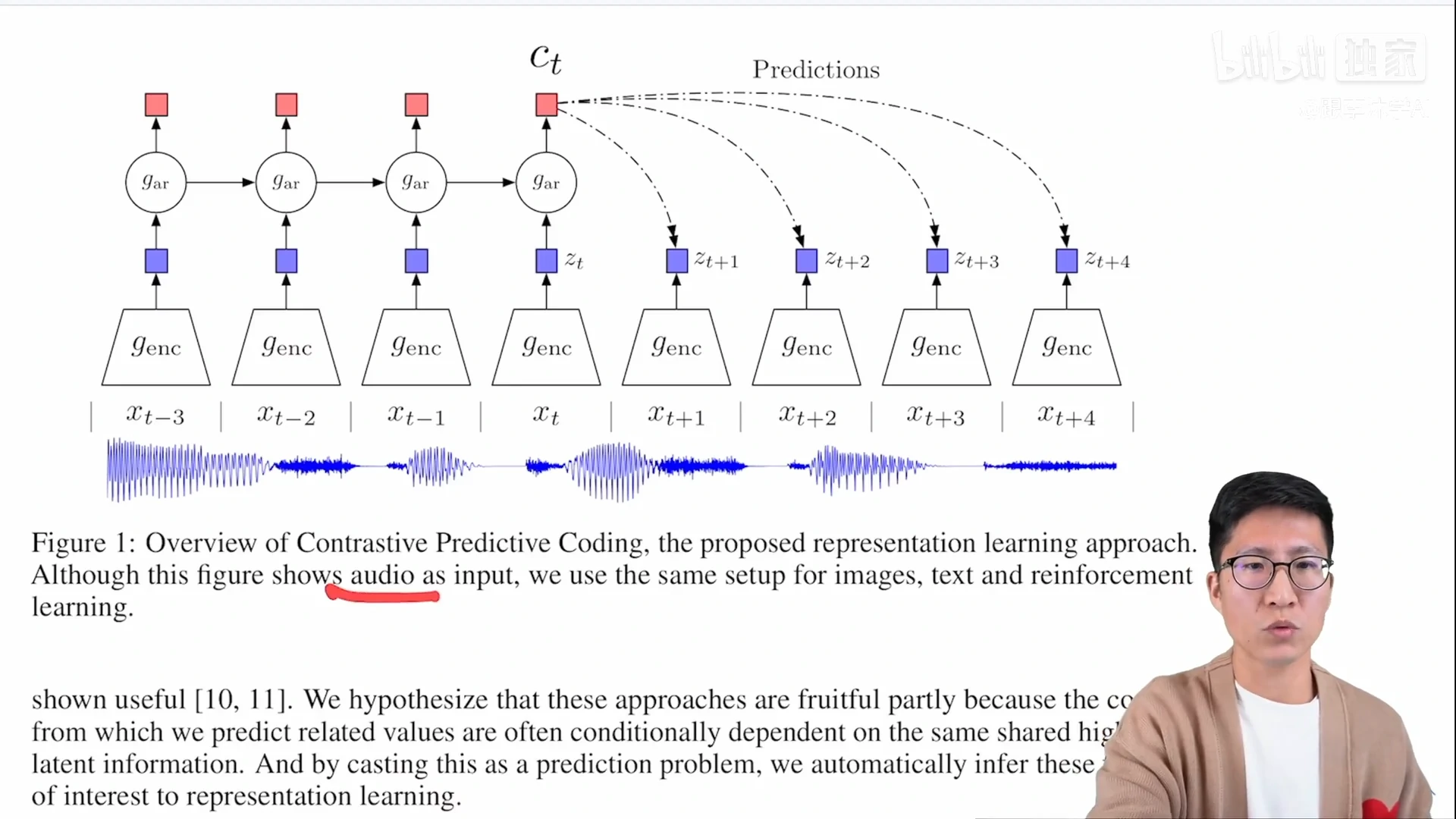
图1中描述的是CPC不仅可以处理音频,还可以处理图片、文字以及在强化学习里使用,这里为了简单,它用的是一个音频的信号作为输入。
本文的想法:假如说有一个输入 x(一个持续的序列),t 表示当前时刻,t-i 表示过去的时刻,t+i 表示未来的时刻。把之前时刻的输入全都扔给一个编码器,这个编码器就会返回一些特征,然后把这些特征喂给一个自回归的模型(gar,auto regressive),一般常见的自回归模型,就是 RNN 或者 LSTM 的模型,所以每一步最后的输出,就会得到图中红色的方块(ct,context representation,代表上下文的一个特征表示),如果这个上下文的特征表示足够好(它真的包含了当前和之前所有的这些信息),那它应该可以做出一些合理的预测,所以就可以用 ct 预测未来时刻的这个zt + 1、zt + 2(未来时刻的特征输出)
对比学习在哪里体现的呢?正样本其实就是未来的输入通过编码器以后得到的未来时刻的特征输出,这相当于做的预测是 query,而真正未来时刻的输出是由输入决定的,也就是说它们相对于预测来说是正样本;负样本的定义其实很广泛,比如可以任意选取输入通过这个编码器得到输出,它都应该跟预测是不相似的,这就是cpc定义正负样本的方式
这套思想是很朴实的,把输入序列换成一个句子,也可以说用前面的单词来预测后面的单词的特征输出;如果把这个序列想象成一个图片的 patch 块从左上到右下形成一个序列,就可以用上半部分的图片特征去预测后半部分的图片特征,总之是非常灵活
《Contrastive Multiview Coding》
CMC(contrastive multiview coding)
cpc是用预测的代理任务做对比学习,cmc这篇论文定义正样本的方式就更为广泛了:一个物体的很多个视角都可以被当做正样本
cmc 的摘要写的非常好:
- 人观察这个世界是通过很多个传感器,比如说眼睛或者耳朵都充当着不同的传感器来给大脑提供不同的信号
- 每一个视角都是带有噪声的,而且有可能是不完整的,但是最重要的那些信息其实是在所有的这些视角中间共享,比如说基础的物理定律、几何形状或者说它们的语音信息都是共享的
- 在这里举了个很好的例子:比如一个狗既可以被看见,也可以被听到或者被感受到
-基于这个现象作者就提出:他想要学一个非常强大的特征,它具有视角的不变性(不管看哪个视角,到底是看到了一只狗,还是听到了狗叫声,都能判断出这是个狗) - cmc工作的目的就是去增大互信息(所有的视角之间的互信息)
- 如果能学到一种特征能够抓住所有视角下的关键的因素,那这个特征就很好了,至少解决分类问题不在话下

cmc到底是怎么样去形成正样本和负样本从而去做对比学习的呢?如图一所示,它选取的是 NYU RGBD 这个数据集(这个数据集有同时4个view,也就是有四个视角:原始的图像、这个图像对应的深度信息(每个物体离观察者到底有多远)、SwAV ace normal、这个物体的分割图像)
cmc 的意思是说,虽然这些不同的输入来自于不同的传感器或者说不同的模态,但是所有的这些输入其实对应的都是一整图片,都是一个东西,那它们就应该互为正样本,也就是说,当有一个特征空间的时候,比如图中圆圈所示的特征空间,这四个绿色的点在这个特征空间里就应该非常的接近。这时候如果随机再去挑一张图片,不论是用图片还是用风格的图像(总之属于一个不配对的视角)的话,这个特征就应该跟这些绿色的特征远离
这就是 cmc 定义正负样本的方式,它的正样本来自于多个视角,一旦定义好了正负样本,剩下的工作就大差不差了
cmc 是第一个或者说比较早的工作去做这种多视角的对比学习,它不仅证明了对比学习的灵活性,而且证明了这种多视角、多模态的这种可行性。所以说接下来 open AI,很快就出了 clip 模型:也就是说如果有一个图片,还有一个描述这个图片的文本,那这个图像和文本就可以当成是一个正样本对,就可以拿来做多模态的对比学习
cmc 原班作者人马用对比学习的思想做了一篇蒸馏的工作:不论用什么网络,不论这个网络是好是坏是大是小,只要你的输入是同一张图片,那得到的这个特征就应该尽可能的类似,也就意味着想让 teacher 模型的输出跟 student 模型的输出尽可能的相似,它就通过这种方式把 teacher 和 student 做成了一个正样本对,从而可以做对比学习
所以说让大家意识到对比学习如此灵活,可以应用到不同的领域,cmc 功不可没
一个小小的局限性:当处理不同的视角或者说不同的模态时候,可能需要不同的编码器,因为不同的输入可能长得很不一样,这就有可能会导致使用几个视角,有可能就得配几个编码器,在训练的时候这个计算代价就有点高(比如说在 clip 这篇论文里,它的文本端就是用一个大型的语言模型,比如说 bert,它的图像端就是用一个 vit,就需要有两个编码器),这样其实又回到了刚开始讲ViT时候所说的说这个 Transformer 的好处————Transformer有可能可以同时处理不同模态的数据
事实上现在已经有人这么做了,2021的 ICLR 就有一篇 ma clip,它就用一个 Transformer 去同时处理两个输入模态,效果反而更好,所以说这可能才是 Transformer 真正吸引人的地方:一个网络能处理很多类型的数据,而不用做针对每个数据特有的改进。
总结
第一阶段大概讲了这四篇论文,可以看到:
- 它们使用的代理任务是不一样的,有个体判别,有预测未来,还有多视角多模态
- 它们使用的目标函数也不尽相同,有 NCE,有 infoNCE,还有 NCE 的其它变体
- 它们使用的模型也都不一样,比如说 invariant spread 用了一个编码器;Inst Disc 用一个编码器和 memory bank; cpc有一个编码器,还有一个自回归模型;cmc 可能有两个甚至多个编码器
- 它们做的任务从图像到视频到音频到文字到强化学习,非常的丰富多彩