本篇学习报告的内容为“基于原始单通道脑电图的自动睡眠分期评分模型”,所参考的文献为《DeepSleepNet: A Model for Automatic Sleep Stage Scoring Based on Raw Single-Channel EEG》。该论文提出了DeepSleepNet(深度睡眠网络),一种基于原始单通道 EEG 的自动睡眠分期评分模型,它不同于现有的开发算法以从 EEG 中提取特征的工作,它旨在通过利用深度学习的特征提取功能来自动化手工工程特征的过程。它在第一层使用两个具有不同过滤器大小的 CNN 和双向 LSTM。可以训练 CNN 来学习滤波器以从原始单通道 EEG 中提取时不变特征,而可以训练双向 LSTM 将时间信息(例如睡眠分期转换规则)编码到模型中。该论文还提出了一个两步训练算法,可以通过反向传播有效地端到端地训练我们的模型,同时防止模型遭受大型睡眠数据集中呈现的类不平衡问题(即,学习仅对大部分睡眠阶段进行分类)。
深度睡眠网络介绍
DeepSleepNet 的架构由两个主要部分组成,第一部分是表示学习,可以训练它学习过滤器,以从每个原始单通道 EEG epoch 中提取时不变特征。 第二部分是序列残差学习,可以训练它编码时间信息。该架构旨在按照 AASM 和 R&K 手册的标准对 30 秒 EEG 时期进行评分。
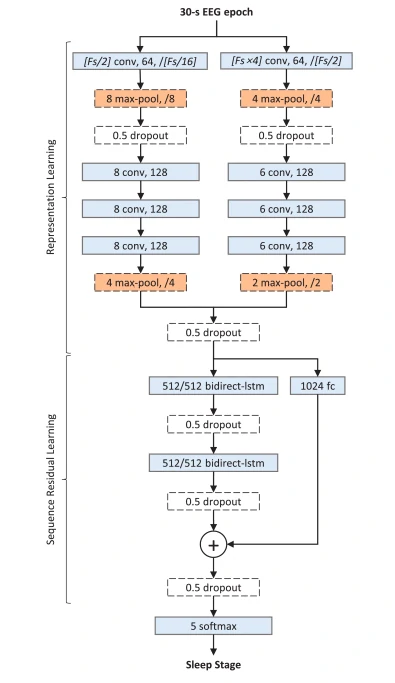
表示学习
它在第一层使用两个具有小和大过滤器尺寸的 CNN 从原始单通道 30-s EEG epochs 中提取时不变特征。每个 CNN 由四个卷积层和两个最大池化层组成,每个卷积层依次执行三个操作:一维卷积、批归一化和应用激活函数ReLU。每个池化层使用最大池化的操作对输入进行下采样。过滤器大小、过滤器数量、步长大小和池化大小的规格如图1所示。每个卷积块显示一个过滤器大小、过滤器数量、还有步长。每个最大池块显示池化层和步长大小。然后将在后面内容中解释 dropout 块。形式上,假设有来自单通道 EEG 的 N 个 30-s EEG epochs {x1, … , xN}。我们使用两个 CNN 从第 i 个 EEG 时期 xi 中提取第 i 个特征 ai 如下:
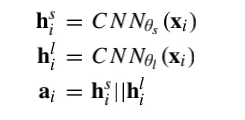
其中 CNN(xi) 是使用 CNN 将 30-s EEG epoch 转换为特征向量 的函数,θs和θl分别是第一层中具有小过滤器和大过滤器尺寸的 CNN 的参数,并且||是将两个 CNN 的输出组合在一起的连接操作。然后将这些连接或链接的特征 {a1, … , aN} 转发到序列残差学习部分。
序列残差学习
这部分由两个主要组件组成:双向LSTM和一个shortcut connection连接。我们使用shortcut connection将这部分重构为一个残差函数进行计算。这使我们的模型能够将它从先前输入序列中学习到的时间信息添加到从 CNN 中提取的特征中。我们还在shortcut connection中使用全连接层将来自 CNN 的特征转换为可以添加到 LSTM 输出的向量。该层通过其权重参数、批量归一化和ReLU 激活进行矩阵乘法运算。形式上,假设有来自 CNN {a1, … , aN} 的 N 个特征按顺序排列并且 t = 1 … N 表示 30-s EEG epochs 的时间索引,我们的序列残差学习定义如下:
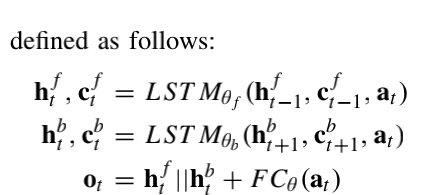

对于表示学习部分,选择了 CNN-1 和 CNN-2 的参数,目的是根据 [14] 提供的指南从 EEG 中捕获时间和频率信息。例如,在图 1 中,CNN-1 的 conv1 层的过滤器大小设置为 Fs/2(即采样率 (Fs) 的一半),其步幅大小设置为 Fs/16 以检测某些 EEG 模式何时出现。另一方面,CNN-2 的 conv1 层的过滤器大小设置为 Fs×4,以更好地捕获 EEG 中的频率分量。它的步幅大小也设置为 Fs/2,高于 CNN-1 的 conv1 层,因为不需要执行细粒度卷积来提取频率分量。后续卷积层 conv2_的过滤器和步长大小被选择为较小的固定大小。认为使用多个小过滤器尺寸的卷积层代替单个大过滤器的卷积层可以减少参数数量和计算成本,并且仍然可以达到相似水平的模型表达能力。对于序列残差学习部分,Bidirect-LSTM 和 fc 层的参数设置为1024。这是为了限制我们的模型只能选择和组合重要的特征,以防止过拟合的。
两步训练算法介绍
两步训练算法(参见算法 1)是我们开发的一种技术,用于通过反向传播有效地端到端训练我们的模型,同时防止模型遭受类不平衡问题(即,学习仅对大多数模型进行分类)睡眠阶段)存在于大型睡眠数据集中。该算法首先对模型的表征学习部分进行预训练,然后使用两种不同的学习率对整个模型进行微调。我们使用交叉熵损失来量化这两个训练步骤中预测和目标睡眠阶段之间的一致性。 softmax 函数(即图 1 中的最后一层)和交叉熵损失的组合用于训练我们的模型以输出互斥类的概率。
预训练
第一步是使用类平衡训练集对模型的表示学习部分进行有监督的预训练,使模型不会过拟合到大多数睡眠阶段。这可以在算法 1 的第 1-8 行中看到。具体来说,从模型中提取两个 CNN,然后与 softmax 层(softmax)堆叠在一起。需要注意的是,这个软 tmax 与模型中的最后一层不同(见图 1)。这个堆叠的 softmax 层仅在此步骤中用于对两个 CNN 进行预训练,其中在预训练结束时丢弃其参数。我们将这两个用 softmax 堆叠的 CNN 表示为 pre_model。然后使用名为Adam的基于小批量梯度的优化器以类平衡训练集训练 pre_model,学习率为lr。在预训练结束时,丢弃 softmax 层。类平衡训练集是通过复制原始训练集中的少数睡眠阶段获得的,这样所有睡眠阶段都具有相同数量的样本(即过采样)。
微调
第二步是对整个模型使用顺序训练集进行有监督的微调。这可以在算法 1 的第 9-19 行中看到。这一步是将阶段转换规则编码到模型中,并对预训练的 CNN 进行必要的调整。具体来说,init_model 的两个 CNN 的参数 θs 和 θl 被替换为来自 pre_model 的参数,从而得到模型。然后使用具有两种不同学习率 lr1 和 lr2 的小批量 Adam 优化器,使用序列训练集训练模型。由于 CNN 部分已经过预训练,因此我们对 CNN 部分使用较低的学习率 lr1,对序列残差学习部分使用较高的学习率 lr2,以及一个 softmax 层。我们发现,当我们使用相同的学习率对整个网络进行微调时,预训练的 CNN 参数被过度调整为序列数据,这些数据不是类平衡的。结果,该模型在微调结束时开始过度拟合大多数睡眠阶段。因此,在微调期间使用了两种不同的学习率。此外,我们使用启发式梯度裁剪技术来防止梯度爆炸,这是训练 RNN(如 LSTM)时的一个众所周知的问题 [23]。当梯度超过预定义的阈值时,该技术使用全局范数将梯度重新调整为较小的值。顺序训练集是通过在所有受试者中根据时间顺序排列原始训练集而获得的。

正则化
我们采用了两种正则化技术来帮助防止过拟合问题。第一种技术dropout,它在训练期间以指定的概率将输入值随机设置为 0(即丢弃单元及其连接)。如图 1 所示,在整个模型中使用了概率为 0.5 的 Dropout 层。重要的是要注意,这些 dropout 层仅用于训练,并在测试期间从模型中删除以提供确定性输出。第二种技术是 L2 正则化,它将惩罚项添加到损失函数中,以防止模型中参数的大值(即梯度爆炸)。由于两个主要原因,我们只在两个 CNN 的第一层应用了权重衰减。首先,中指出 L2 正则化会限制模型学习长期依赖的能力。其次,我们发现,在没有正则化的情况下,CNN 第一层的滤波器过度拟合 EEG 数据中的噪声或伪影。这种正则化有助于模型学习更平滑的滤波器(即包含较少的高频元素),从而略微提高性能。定义惩罚程度的正则化参数 lambda 设置为 10的-3次方。
实验数据
我们使用来自两个公共数据集的不同 EEG 通道评估了我们的模型:蒙特利尔睡眠研究档案 (MASS)和 Sleep-EDF。使用 TensorLayer (https://github.com/zsdonghao/tensorlayer) 实现了我们的模型,这是一个从 Google Tensorflow 扩展的深度学习库。该库允许我们将数值计算(例如训练和验证任务)部署到多个 CPU 和 GPU。
实验结果
睡眠分期评分表现
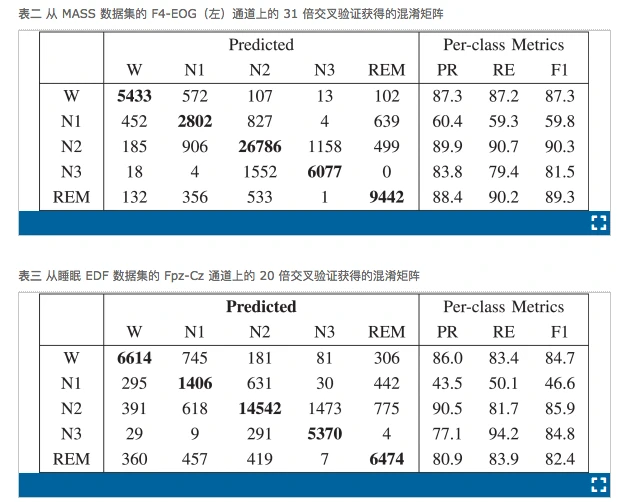
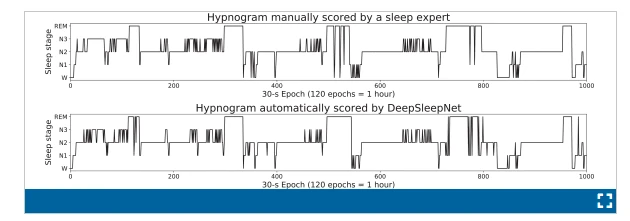
表二和三分别显示了从 MASS 和睡眠 EDF 数据集的 F4-EOG(左)和 Fpz-Cz 通道的31折和20折交叉验证中获得的混淆矩阵.我们没有包括从 Sleep-EDF 数据集的 Pz-Oz 通道获得的混淆矩阵,因为 Fpz-Cz 通道提供了更好的性能。每行和每列分别代表睡眠专家和我们的模型分类的每个睡眠阶段的 30 秒 EEG 时期的数量。粗体数字表示我们的模型正确分类的时期数。每行的最后三列表示从混淆矩阵计算的每类性能指标。可以看出,N1阶段表现最差,F1小于60,而其他阶段的F1明显更好,范围在81.5和90.3之间。大多数错误分类的阶段在 N2 和 N3 之间。还可以看出,混淆矩阵通过对角线几乎是对称的(N2-N3 对除外)。这表明错误分类不太可能是由于不平衡类问题引起的。图 2 展示了由睡眠专家手动评分的催眠图示例,并由我们的 DeepSleepNet 为 MASS 数据集中的 Subject-1 自动评分。
模型分析



其次,我们分析了我们的模型如何利用双向 LSTM 从一系列 EEG epoch 中学习时间信息。具体来说,我们研究了双向 LSTM 如何管理它们的记忆细胞中使用 的可视化技术中。我们发现前向 LSTM 的几个记忆单元是可解释的。 例如,当受试者分别处于 W 或 N1 阶段时,几个细胞正在跟踪觉醒或睡眠开始,将它们的值重置为正数。然后,在阶段 N2、N3 和 REM(或简称为 R)期间,单元格值下降到负值(即变为不活动状态)。图 4 说明了根据我们的模型预测的一系列睡眠阶段,该单元格值的变化。睡眠阶段按时间从左到右,从上到下排列。 每个睡眠阶段颜色对应tanh(c),其中+1(即活动)是蓝色,-1 是红色(即不活动)。还有其他可解释的单元格,例如在每个受试者数据开始时以高值开始然后随着每个睡眠阶段缓慢下降直到受试者数据结束的那些单元格,或者当他们发现连续N3 和 REM 阶段的顺序。 这些细胞的存在表明,序列残差学习部分内部的 LSTM 学会了跟踪每个主体的当前状态,这对于根据阶段转换规则正确识别下一个睡眠阶段很重要。
展望及结论
我们提出了 DeepSleepNet 模型,该模型利用 CNN 和双向 LSTM 从原始单通道 EEG 中自动学习睡眠阶段评分特征,而无需使用任何手工设计的特征。 结果表明,在不改变模型架构和训练算法的情况下,该模型可以应用于不同的 EEG 通道(F4-EOG(左)、Fpz-Cz 和 Pz-Oz)。与 MASS 和 Sleep-EDF 数据集上最先进的手工工程方法相比,它实现了相似的整体准确性和宏观 F1 分数,这两种方法具有不同的属性,例如采样率和评分标准(AASM 和 R&K)。结果还表明,从序列残差学习部分学习的时间信息有助于提高分类性能。这些表明我们的模型可以从不同的原始单通道 EEG 中自动学习睡眠阶段评分的特征。
我们使用来自 MASS 数据集的 F4-EOG(左)通道评估我们的模型有两个主要原因,这与文献中报道的大多数依赖中央叶电极(如 Cz)的现有方法不同, C4 和 C3。 第一个原因是将评分性能与我们之前的手工工程方法进行比较。 第二个原因是,与现有方法相比,在睡眠诊所或家庭环境中收集数据更容易、更舒适。 这是因为两个电极都没有读取来自多毛头皮的电活动的问题。我们的模型分析结果还表明,我们的模型学习到了几个与AASM手册一致的特征。由于我们的模型会自动从原始脑电图中学习特征,因此我们的方法与手工工程网相比,DeepSleepNet模型是实现远程睡眠监测的更好方法。
个人总结
本论文提出了一种名为 DeepSleepNet 的深度学习模型,用于基于原始单通道 EEG 的自动睡眠分期评分。它的模型利用 CNN 来提取时不变特征,并利用双向LSTM从EEG epoch学习睡眠阶段之间的阶段转换规则。实现了两步训练算法,该算法使用过采样数据集预训练我们的模型以缓解类别不平衡问题,并使用 EEG 时期的序列微调模型以将时间信息编码到模型中。结果表明,在不改变模型架构和训练算法的情况下,模型能够从具有不同属性和评分标准的两个数据集的不同原始单通道 EEG 中自动学习睡眠分期评分特征。由于模型会自动从原始 EEG 中学习特征,因此与手工工程相比,DeepSleepNet 是实现实用化睡眠监测的更好方法。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10363
原文链接:https://ieeexplore.ieee.org/document/7961240
代码公开:https://github.com/akaraspt/deepsleepnet