本文将通过实现一个简单的歌词生成AI,快速了解深度学习的基本流程以及PyTorch这款必备的深度学习框架。
介绍
首先我们要知道,深度学习或者说神经网络的本质其实是一个数学问题。我们可以通过“训练”让一个神经网络学习“输入”到“输出”之间的数据映射关系。

例如当神经网络看到这张图片时,它应该知道输出是一只狗。

在PyTorch中,构建神经网络的核心数据结构是一个叫做张量(Tensor)的东西。
它和numpy数组非常类似,不过Tensor的运算可以被放在GPU上执行,利用GPU的并行运算来加速整个计算过程。在Tensor之上,我们可以构建各种复杂的数学模型。
PyTorch同时提供了梯度(Gradient)的自动计算,梯度你可以简单理解为导数在高维度上的推广。
这是因为对于神经网络的“训练”,或者说一般的最优化问题,大家会用到一个核心算法————梯度下降(gradient descent)。
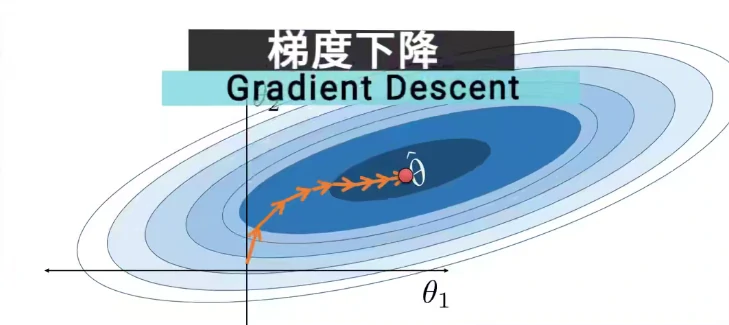
而PyTorch将偏导数的计算、链式法则这些细节全都隐藏在了框架中,因此我们可以关注于解决实际问题,而不是这些繁琐的计算细节。
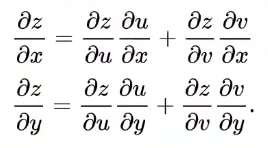
除了这些基本的计算功能以外,PyTorch对神经网络还有各种模块化的封装,比如常见的卷积层(conv layer)、线性层(linear layer)、池化层(pooling layer)、padding layer、各种激活函数、CNN、RNN、Transformer模型等等。
安装PyTorch
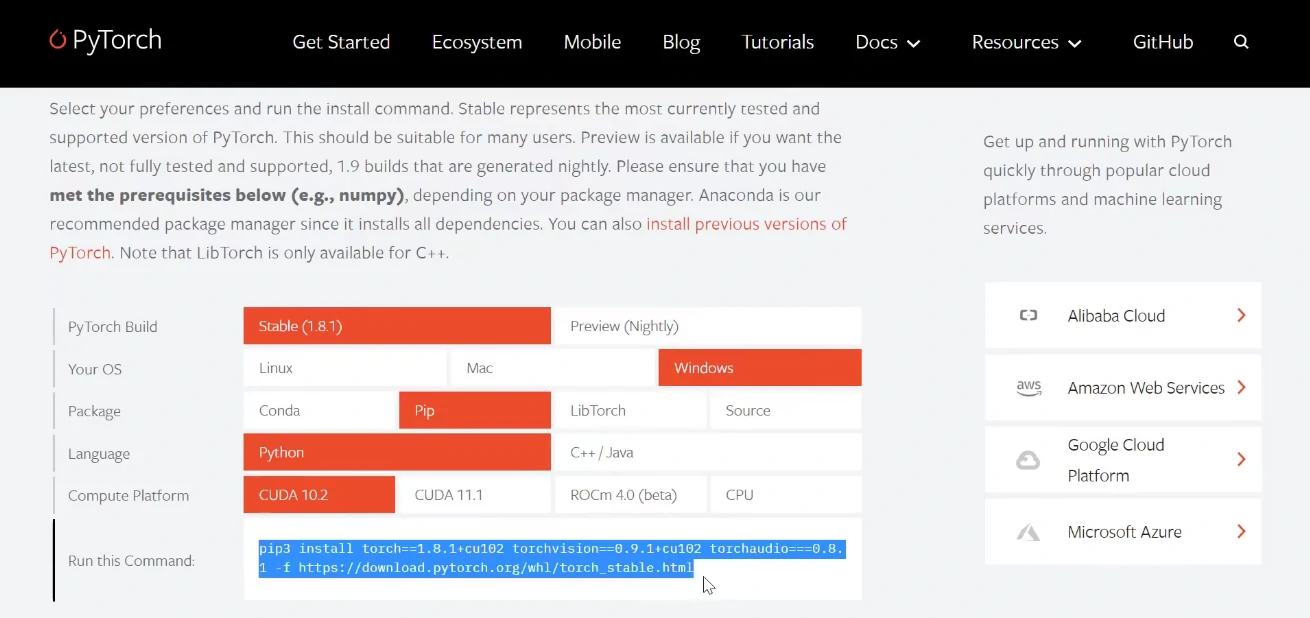
PyTorch的安装还是非常容易的,我们可以在PyTorch官网选择对应的操作系统、CUDA版本,Anaconda其实不是必须的,只是可以更好地进行包管理。最后复制下面的命令到控制台安装即可。
数据集(Dataset)
训练的第一步是准备我们需要的原始数据,数据集(Dataset)通常很容易被我们忽视,但又是深度学习中相当重要的一环。有时候即使你的模型再好,但是训练的数据很差,最后也很难得到一个好的结果。
这里使用的是这个中文歌词语料库。
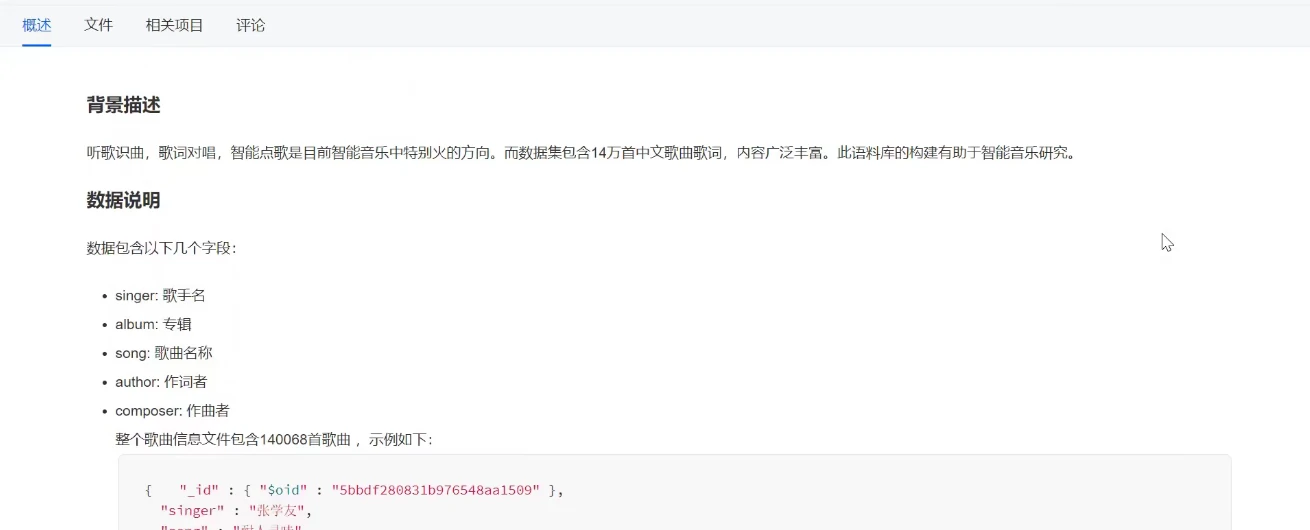
在下载的原始数据集中我们可以看到很多非中文歌曲,以及有些歌词中的格式不工整,有些歌词的前面包含了不需要的信息。
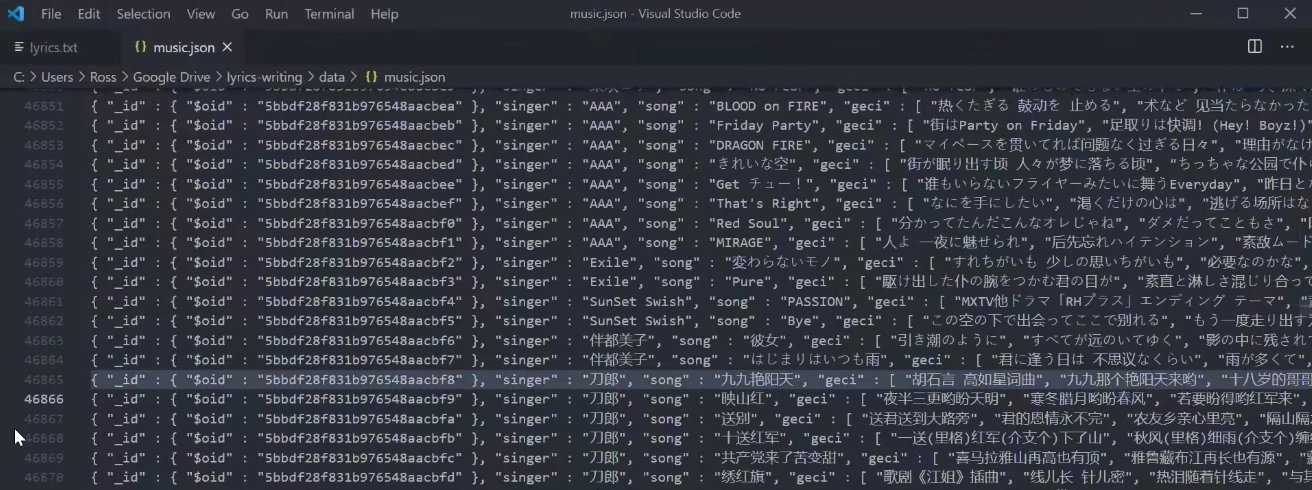
因此我们需要对这些原始数据做一些预处理(Data Preprocessing),并将数据转换成我们需要的格式。需要写一个处理脚本data_preprocess.py,过滤掉不需要的歌词,去除多余的文件,并以斜杠来分隔歌词的每一句,每一行是一首歌的歌词,最后存放在一个纯文本中(data/lyrics.txt)。
接下来可以利用PyTorch提供的DataSet和DataLoader来读取这个歌词文件。这两个类封装了基本的数据操作,比如切分训练数据、随机打乱数据、或者对数据进行简单变换等等,这样我们就不用自己去造轮子了。
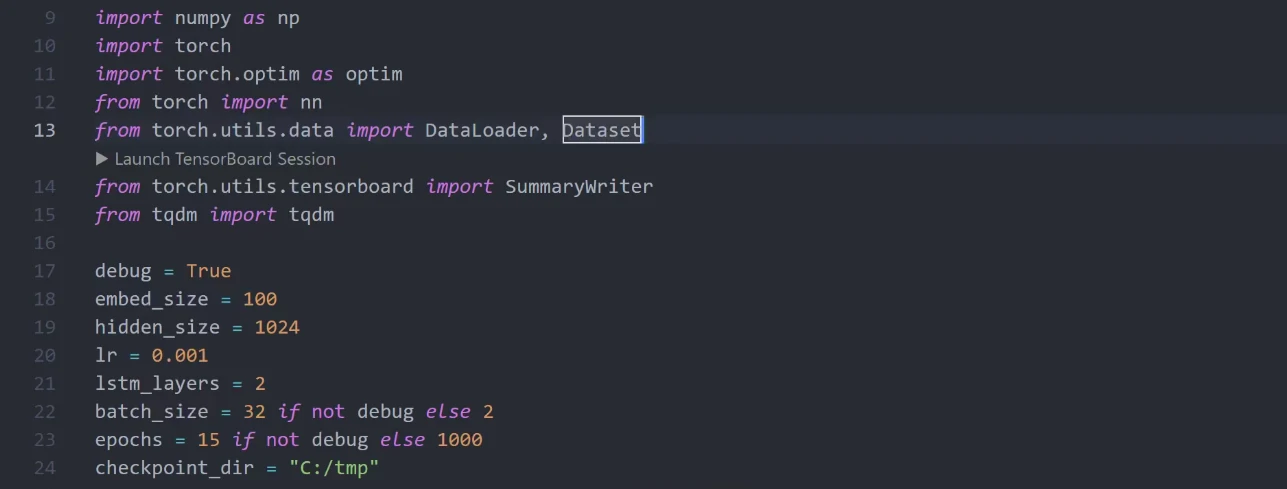
我们可以通过继承DataSet类来定义我们的歌词数据集,接下来我们在init函数中加载之前的这个歌词文件,并将所有的文字转换成一个个索引。【PyTorch神经网络不支持“字符”类型的输入,我们需要将文字转换成不重复的整型值才能传递给网络】
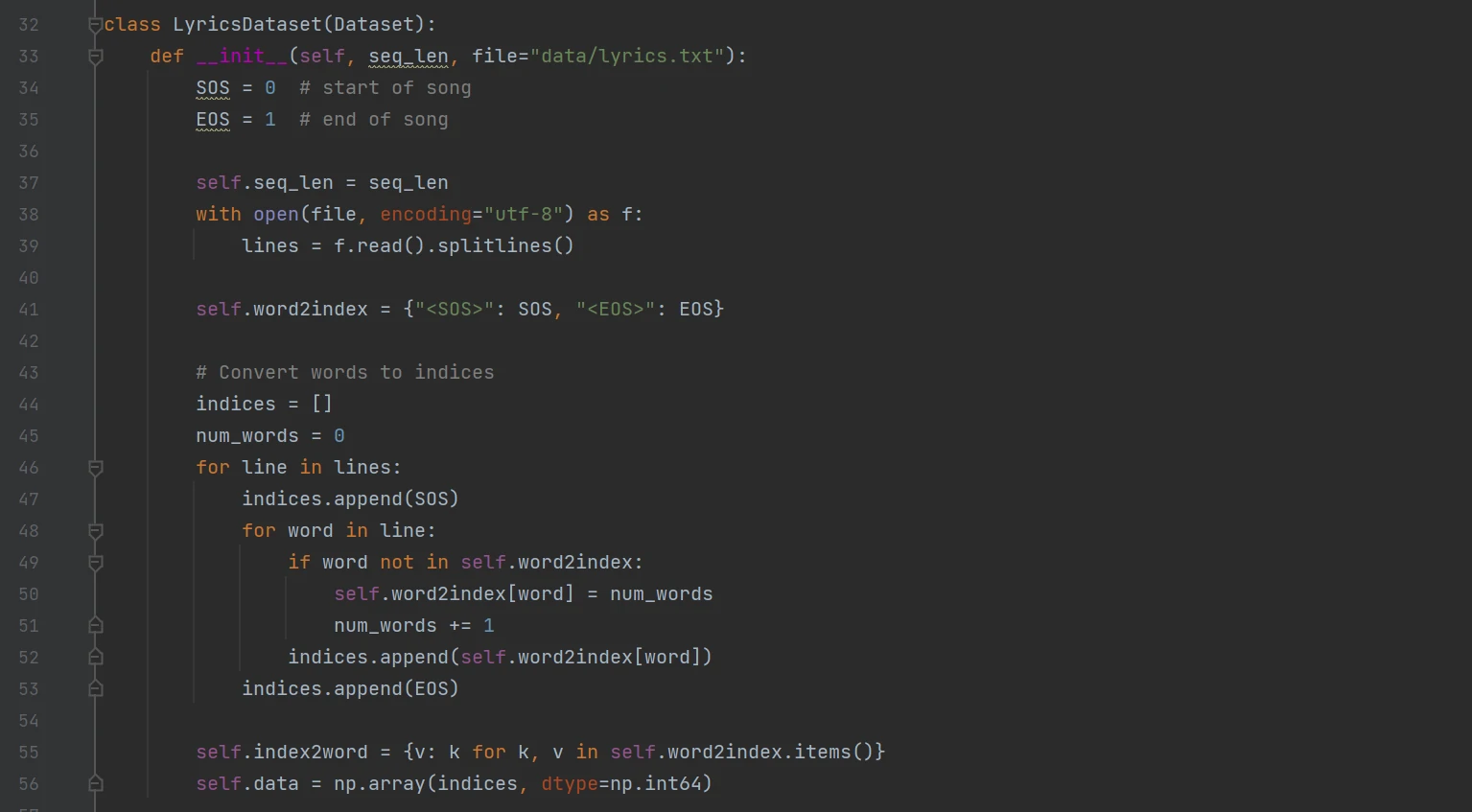
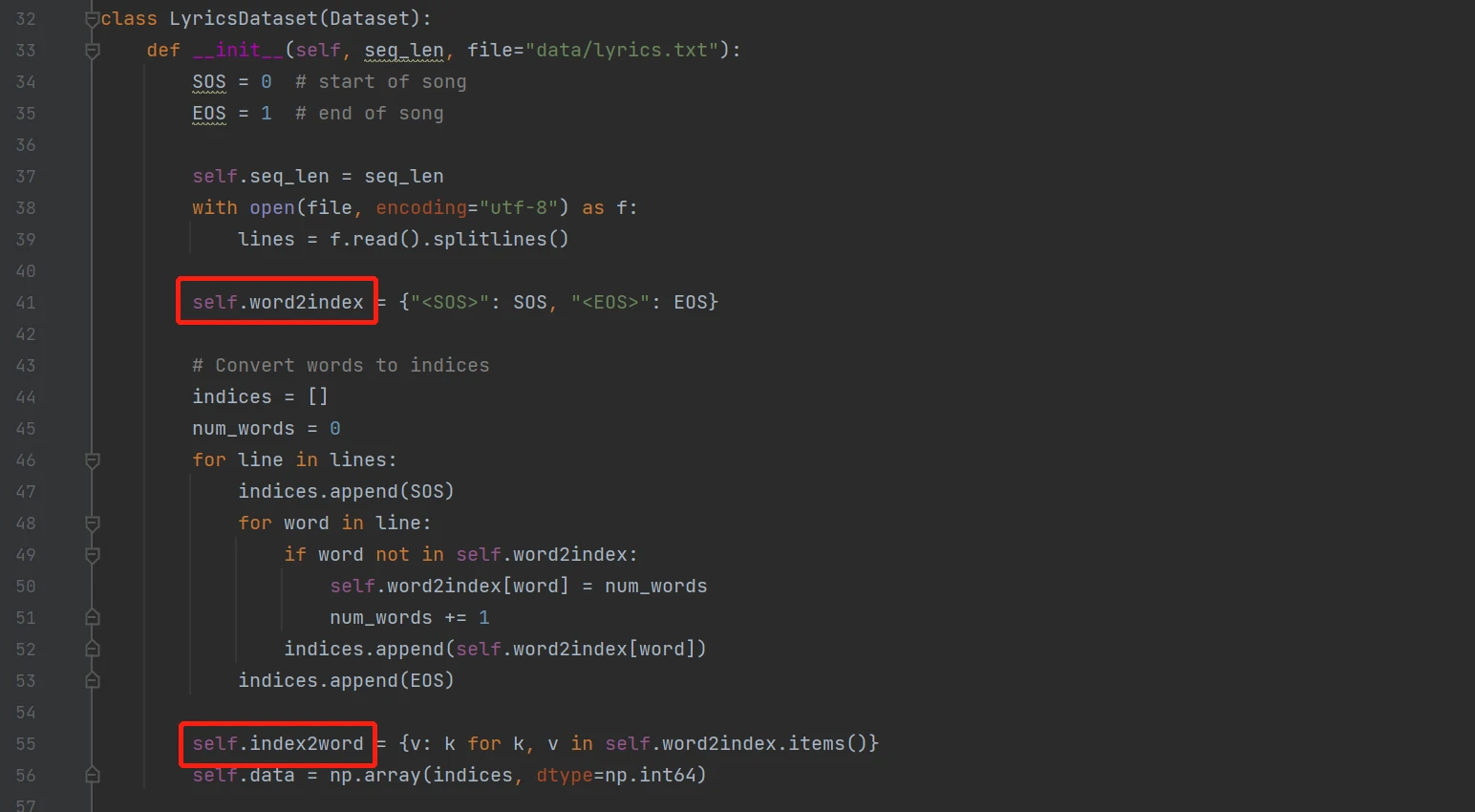
这里我们定义两个dict用来保存索引到文字以及文字到索引的映射。
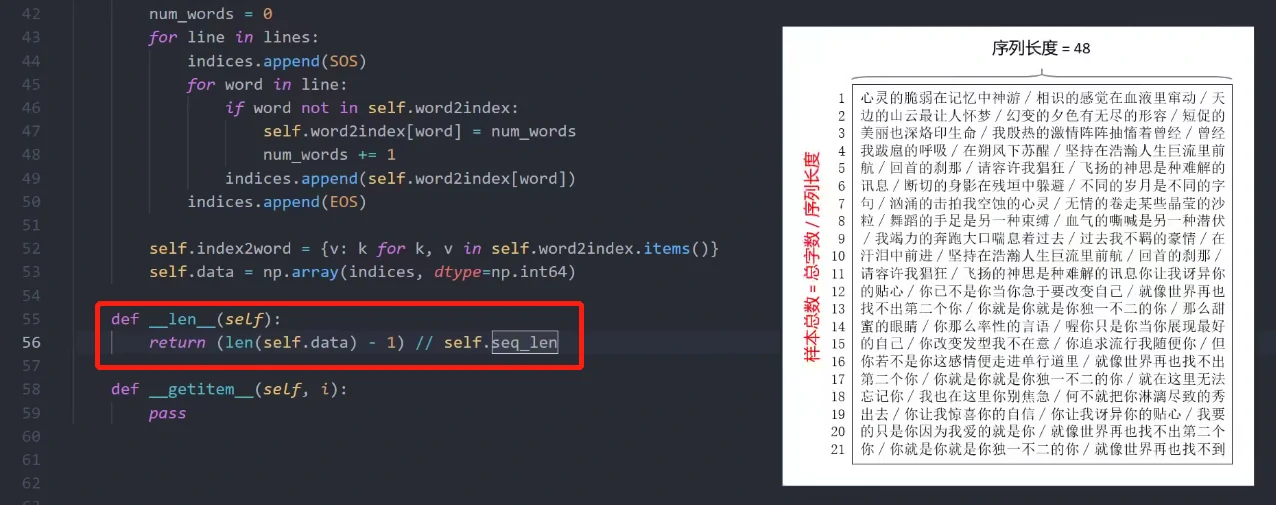
接下来我们需要实现两个函数,第一个函数len,我们需要返回样本的总数。这里我们将所有歌词文本拆分成一个个长度为48的序列,所以样本总数(seq_len)等于文字的总数/序列长度(48),这里为什么减1,后文会提及。
第二个函数getitem,我们可以根据指定的下标返回对应的文字序列。
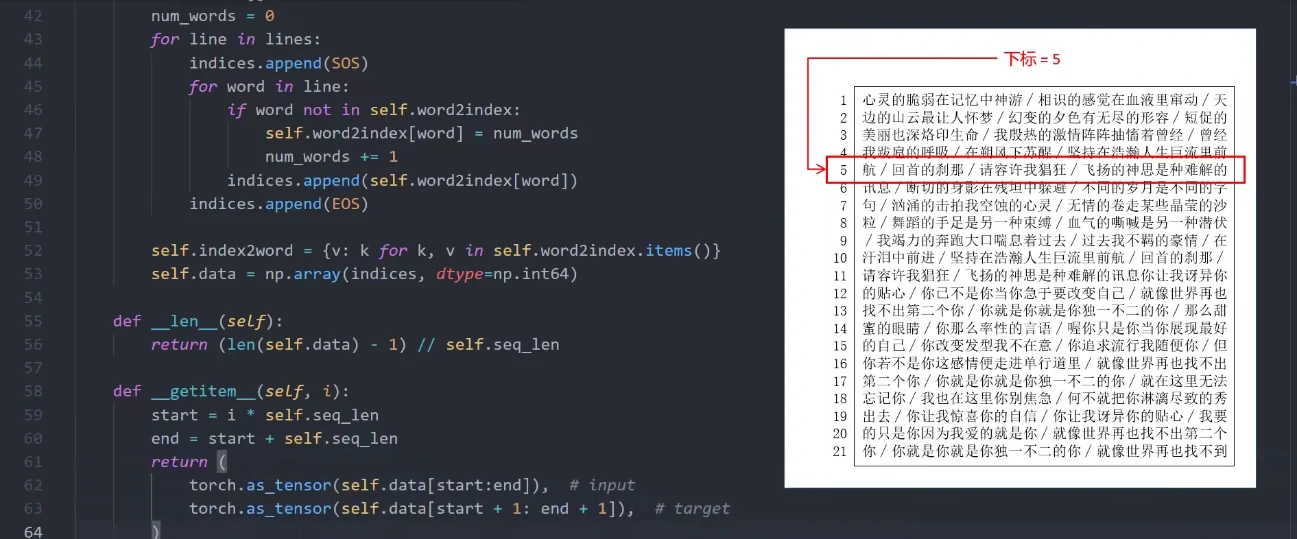
这里返回的数据可以分为两部分,一部分代表网络的输入,另一部分代表网络的输出,输入和输出刚好相差一个字,因为输出的文字刚好是对下一个字的预测。

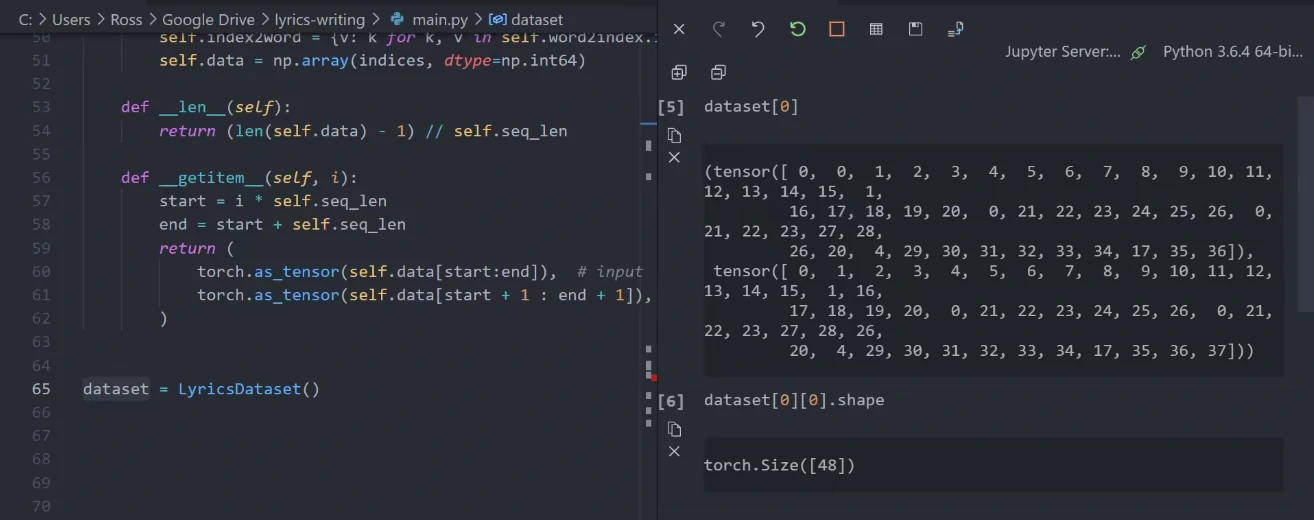
定义完毕之后,我们对刚刚的代码进行一下简单测试。这里我们可以创建一个数据集对象,然后根据下标随便获取其中一个样本,可以看到返回了一个整数序列,长度为48,其中的每个数字代表一个文字的索引。
我们当然可以根据之前创建的映射将它们再还原成一个个字符。
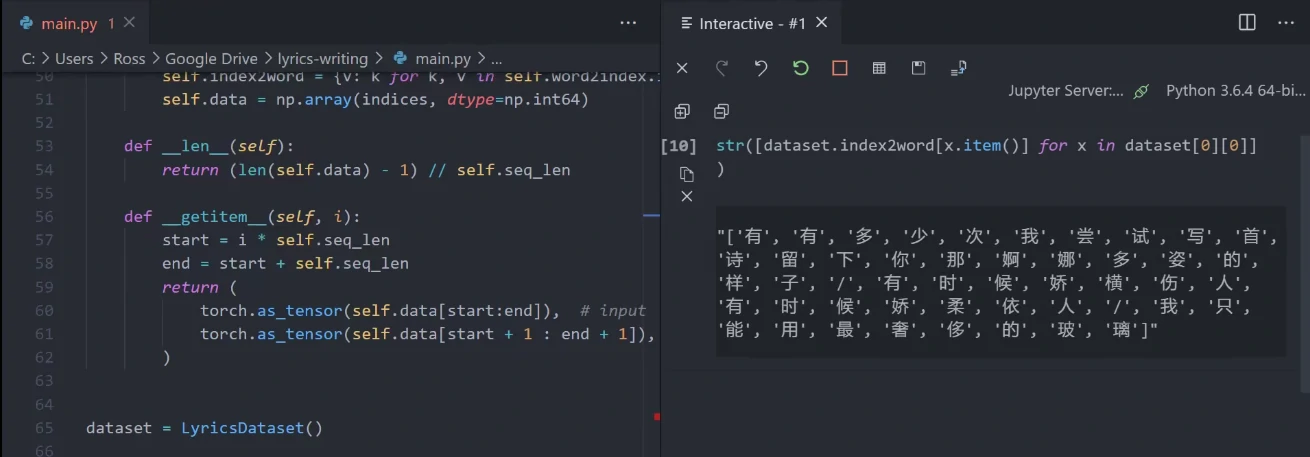
这一步检查其实是很有必要的,不然一步错步步错。
在定义了Dataset之后,我们需要再创建一个DataLoader来访问其中的数据,主要是DataLoader允许我们随机打乱数据,或者按批次(batch)读取数据。

当然这里还进一步将数据随机分成了两部分,一部分用来做训练,另一部分用来做测试(验证),原因在之后训练的时候会讲到。

创建模型(Build Model)
接下来,我们来定义我们用到的这个神经网络结构。
在PyTorch中,我们可以通过继承nn中的Module类来定义一个神经网络。这里最关键的是forward函数,它定义了我们网络从输入到输出的整个计算过程,比如数据会经过哪些层、层与层之间应当如何连接等等。
在定义模型时,有一点非常重要,不管我们要解决的问题有多么复杂,最好都先从构建一个最基本的模型开始,这样会大大降低训练和调试的难度,并且我们在增加模型复杂度之后,可以以这个简单的模型做参照,确保复杂的模型是否能真的表现的更好。
其实对于文本生成问题,使用当下最流行的Transformer架构应该是更好的选择。
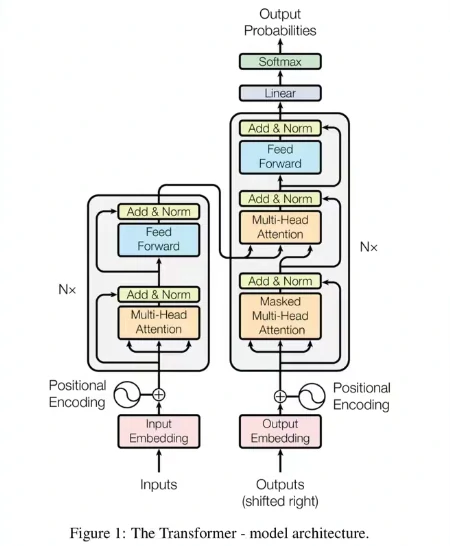
不过这里我们先用一个更加简单、基本的RNN(Recurrent Neural Network,循环神经网络:特指将当前的状态信息循环传递给自身的网络模型)模型来做演示。
首先我们会将这里输入的文字经过一个embedding层转换成一个向量,因为高维向量能够很好地表示不同文字间的语义关联。
接着我们将这个向量传入一个LSTM单元,最后通过一个线性层转换成输出的文字。
和所有的分类问题(categorization)一样,这里的文字是使用one-hot向量来编码的。
另外LSTM单元同时有一个隐藏状态的输入和一个隐藏状态的输出,正是因为有这个隐藏状态,才使得我们的神经网络具有记忆的能力,因为我们不希望生成的歌词前言不搭后语,我们需要让模型记住文字前后的关系。
训练(Training)
在训练的过程中,每次会从数据中抽取一小部分(称之为一个batch),然后我们会一个batch接着一个batch训练。
当所有的数据都被训练过一遍之后(称之为一个epoch),通过我们会对模型训练若干个epoch,让它更好地去拟合训练数据。
我们可以在循环中实现整个训练的过程,对于每个epoch,我们会一个batch接着一个batch地训练。
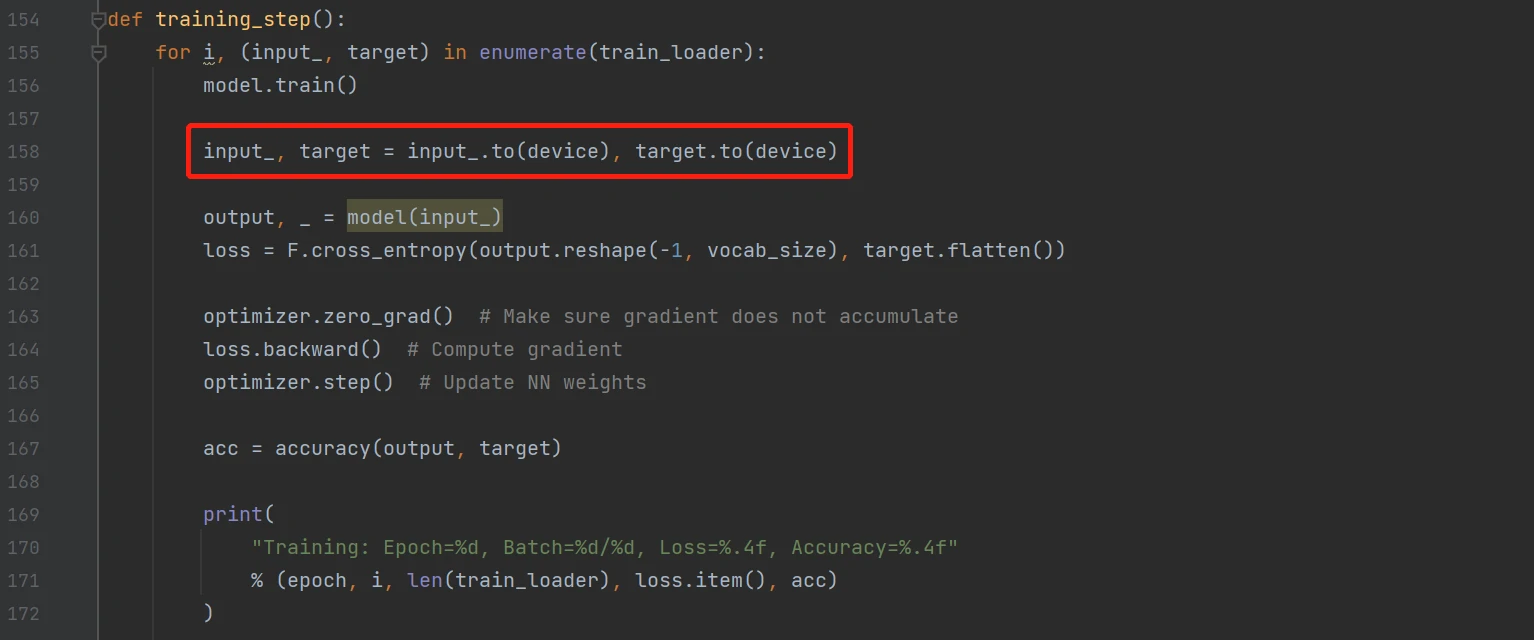
标记代码单纯代表将训练数据上传至GPU,如果使用GPU来加速训练过程的话是有必要的。
接下来我们将数据传入之前创建的模型,让模型预测一个输出,然后我们会去计算这个输出与标准答案(ground truth)之间的“差异”,这里我们会用到损失函数(Loss Function)。
对于不同的问题,我们会用到不同的损失函数,比如对于纯数值类型的输出(Scalar Output),像温度、房价、身高…,这个loss可以简单是输出与标准答案的绝对值或者是平方差。

而对于我们这种情况,由于我们的输出是ont-hot编码的文字,因此我们会用到交叉熵(Cross Entropy),可以简单将这个loss理解为输出与标准答案之间的差距,通常我们希望这个loss越小越好,这样代表预测的结果与标准答案更接近。
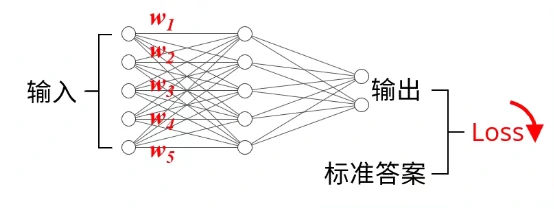
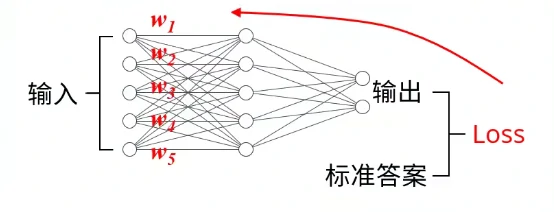
我们训练神经网络的目标,就是通过缓慢调节网络中的各种权重(Weight)来降低这个loss,用到的算法就是之前提到的梯度下降。关于梯度的计算,我们可以轻松地通过调用一句backward()完成,然后我们可以调用optimizer的step(),通过计算得到的梯度自动修改网络的权重。
其中optimizer.zero_grad()也非常重要,它会在计算之前先将梯度清零,避免我们得到一个累加的梯度值。
刚刚我们提到的optimizer是优化器,它可以通过计算得到的梯度自动更新网络的权重。
Adam和SGD是两个非常常用的优化器。

另外优化器有一个额外的参数————学习速率(Learning Rate),它会影响每次权重变化的大小。
学习率越大,神经网络权重的变化量就越大,但学习率绝不是越大越好,过大的学习率会让loss无法收敛,甚至可能出现随着训练增大的情况。
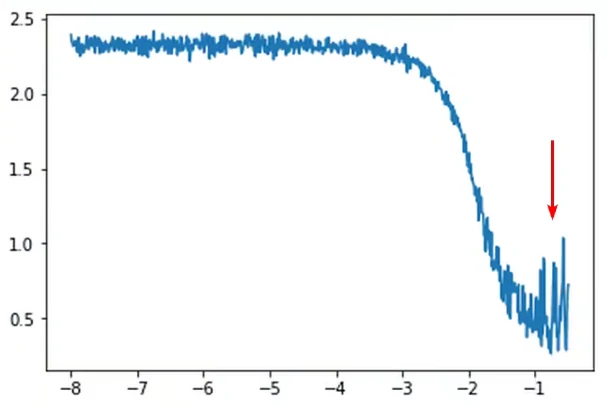
学习率设置的过小会降低训练的速度,甚至可能让你的神经网络学不到任何东西。
当然也有人尝试使用动态的学习率,比如随着训练的推进逐渐降低学习率。关于学习率和优化器的选择又是一个很宽泛的话题,这里就不展开讨论了。
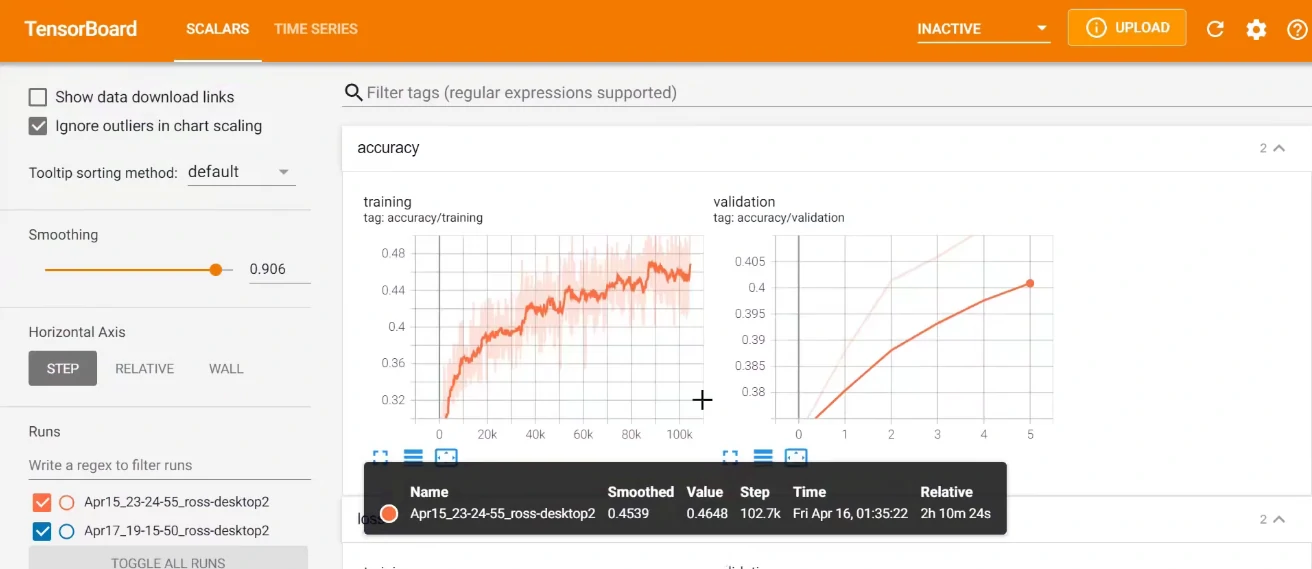
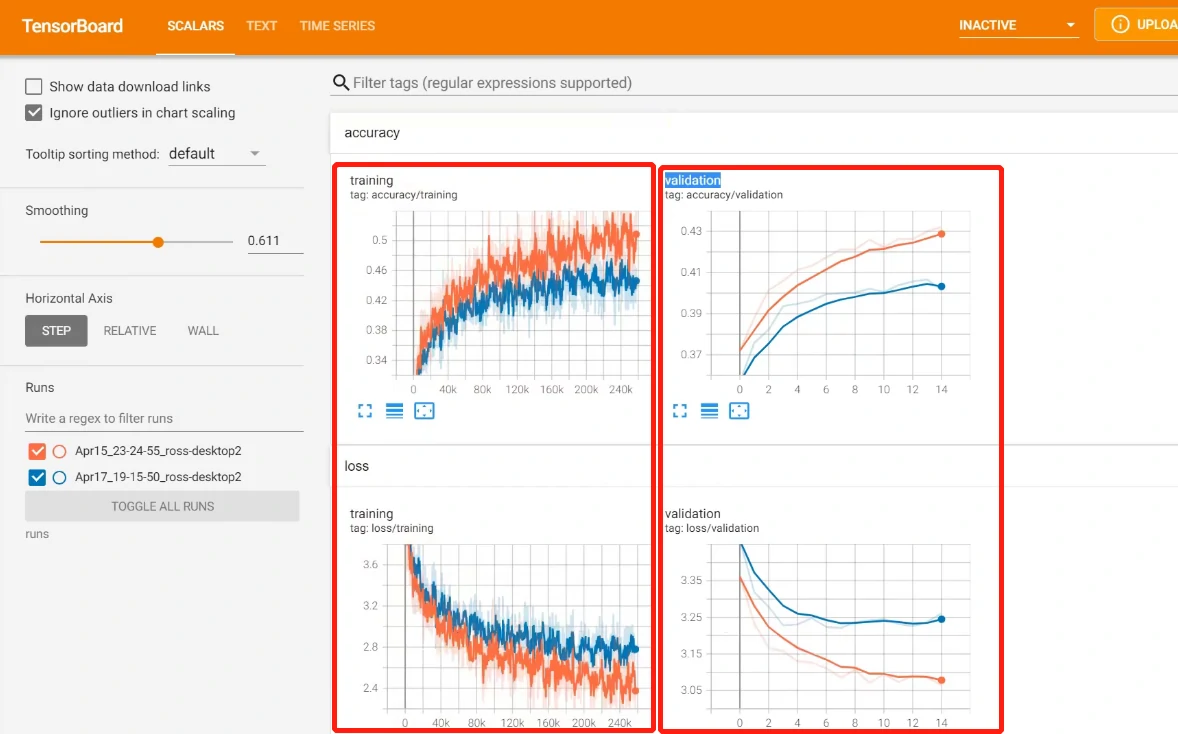
另外在训练的过程中,我们可以将loss打印出来以方便我们跟踪模型的训练进度。这里我们还可以用到Tensorboard这个库,然后可以调用add_scalar()来绘制像loss、精确度这样标量的数据,命令行调用tensorboard –logdir=runs可查看。
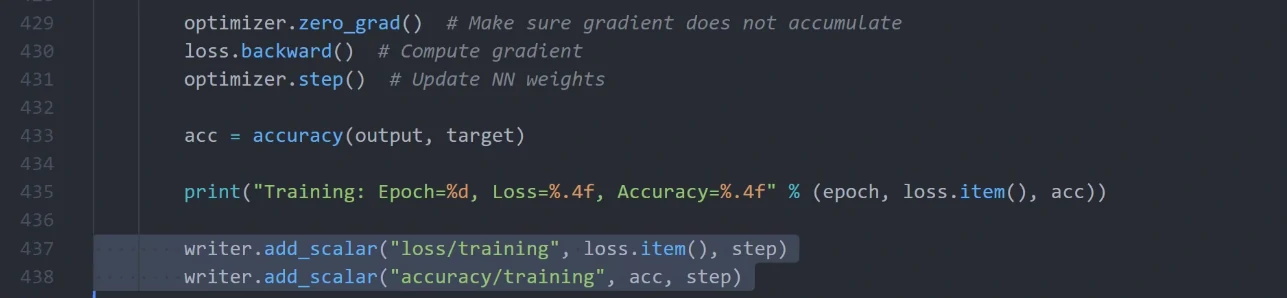
这一步不是必要的,但是图表呈现的信息往往比数字要直观很多。
模型评估(Model Evaluation)
我们将数据分成了训练和测试两部分,通过我们会预留少量的数据做评估,这一部分数据并不会拿来做训练。
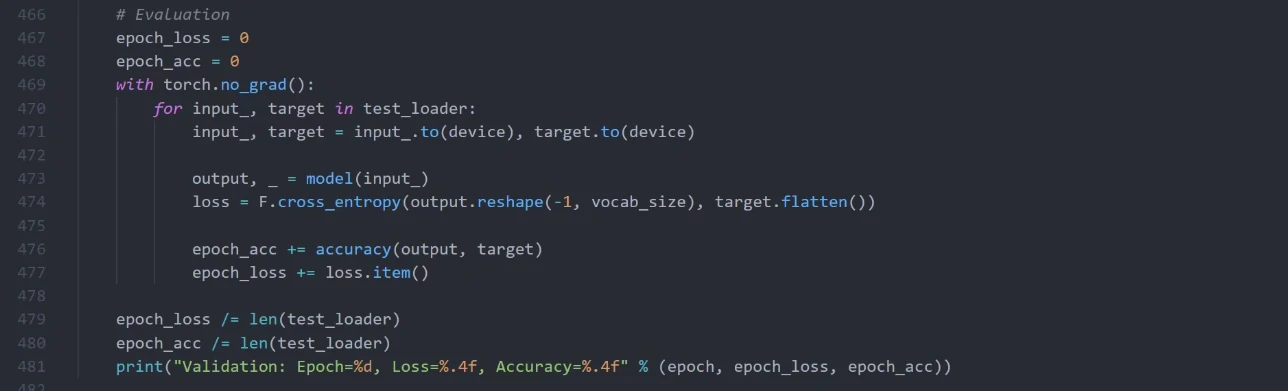
评估的代码和训练非常相似,除了我们不会计算梯度来更新网络的权重。我们同样会输出一个loss,然后观察这个loss下降的情况,因为单纯训练loss的降低并不能代表模型表现得很好,模型也有可能过度拟合(Overfit)我们的训练数据,也就是说我们的模型对于训练数据表现得很好,但是对于从没有见过的数据却表现得很差。
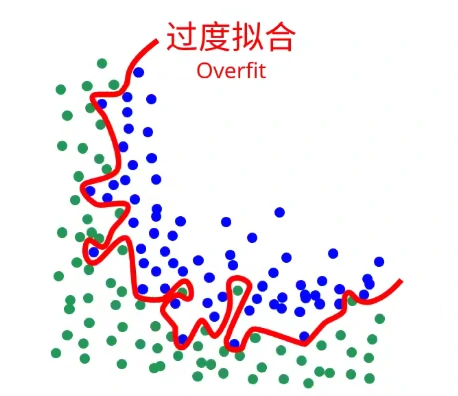
为了避免这种情况,我们会同时关注训练和评估时候的loss以及精确度这些指标。
最基本的验证(Sanity Check)
在真正训练之前,我们最好对之前的代码做一个最最基本的验证,因为训练一个模型通常会花很多时间,有时候一两天都有可能,如果等你训练完了才发现模型根本不工作,那一定让人气到原地升天。
so how to do?
比如我们可以修改这里的dataloader,让我们暂时只用第一个batch的数据,并且我们只用batch中的前两个样本来做训练。


如果在这种情况下loss都不会降低,也就是说我们的模型都不能过拟合,那么我们的代码肯定哪里有问题,需要进行调试。
真正的模型训练(Model Training)
在训练的过程中,我们还可以每隔一段时间,让目前的模型生成一段输出,这一步主要是为了实时观测模型的预测结果,may大be可以看到我们模型的输出随着训练有显著的提升。
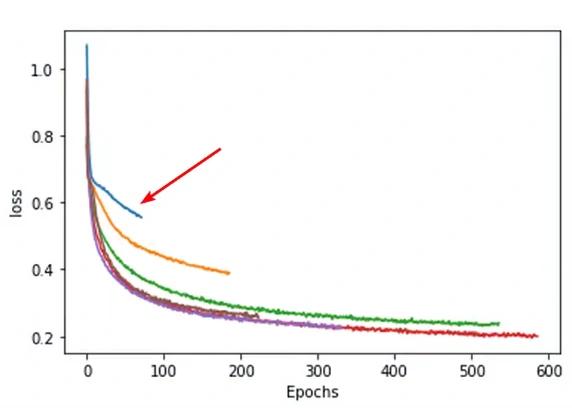
我们还可以做一些改进,比如使用两层的lstm单元,并在输出之前额外增加了一个线性层。与之前的模型相比较,新的模型进一步降低了loss并提高了预测的准确度。
虽然不是每一个修改都能保证模型效果的提升,不过模型优化确实需要我们不断地进行尝试,通常我们在loss不再降低的时候就可以停止训练了(需要同时观察validation loss而不单单是training loss)。
推断(Inference)
生成歌词的generate()函数稍微有点长,不过总体来说,它会将我们规定的首字符先传递给神经网络,然后让神经网络自由创作,直到这一句结束(遇到“/”分隔符为止)。
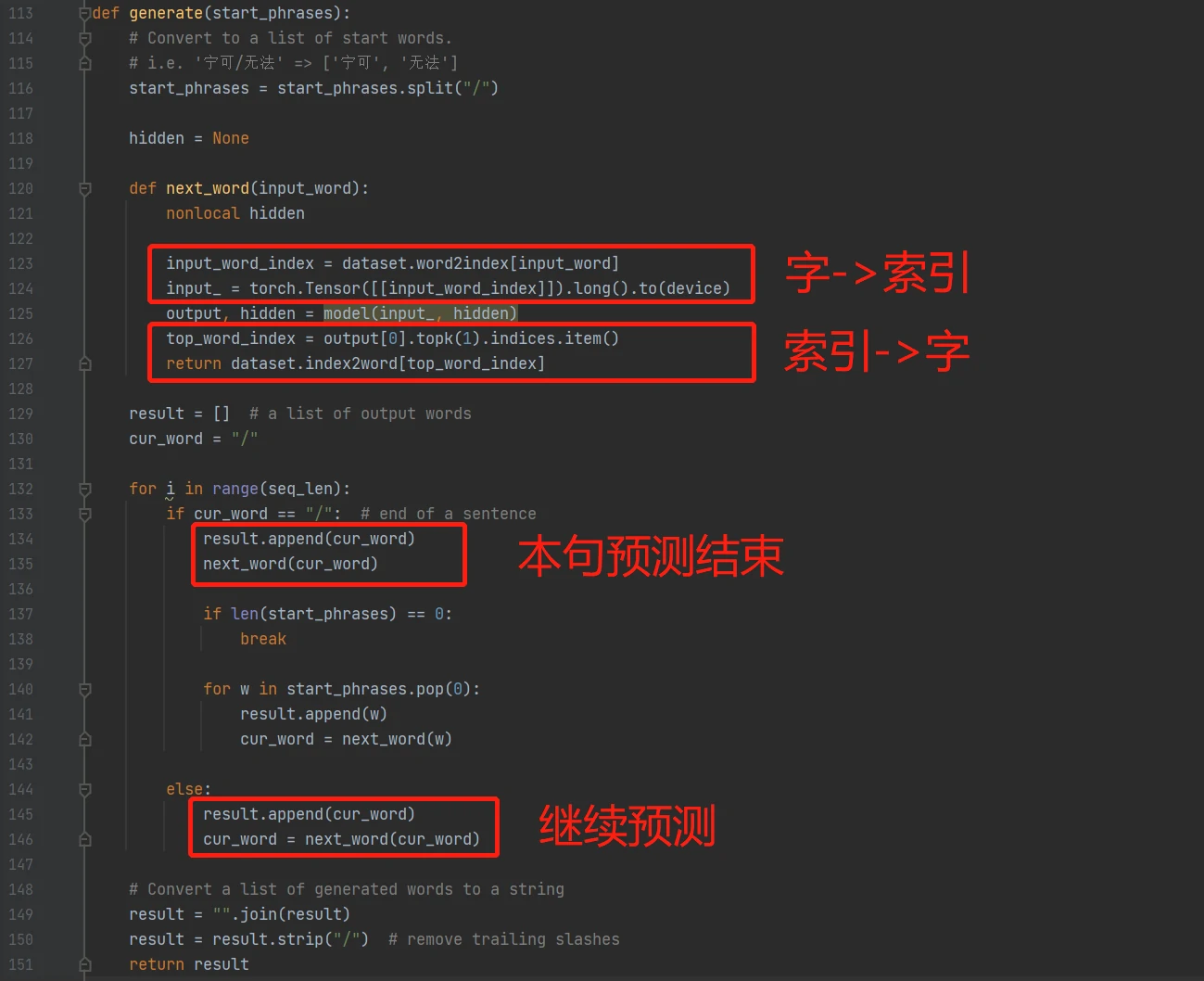
这里的next_word函数会将当前字符传入神经网络然后返回预测的下一个字,中间也会维护一个隐藏状态hidden
总结
本文也只不过提到了深度学习的冰山一角,像图像、声音、语言处理等等,每一个子领域都有太多东西值得去推敲,每年也会看到很多新的突破。
要训练一个好的模型绝对不是一件轻松的事情,有时候对模型结构的一点点修改,甚至是对(超)参数(hyper parameter)的一点点调整,都有可能带来很大的性能提升。
参考与鸣谢
https://www.bilibili.com/video/BV1oq4y1E7Vd
https://github.com/rossning92/ai-lyrics-writing