微表情能够揭示人类试图隐藏的真实情绪。微表情识别的研究旨在让机器有足够的智能,能够从人脸视频序列中识别人类的真实情绪。为了促进心理学领域和计算机视觉领域针对微表情的进一步研究,由中国图象图形学学会(CSIG)举办、CSIG机器视觉专业委员会承办,中国科学院心理研究所的王甦菁博士组织一系列云上微表情的学术活动。本次云上微表情讲座将阐述西南大学电子信息工程学院情感计算课题组在过去五年内同国内外合作单位,围绕深度学习方法在微表情识别与检测中的研究工作,由彭敏、张志豪和王重阳三位博士研究生进行报告。
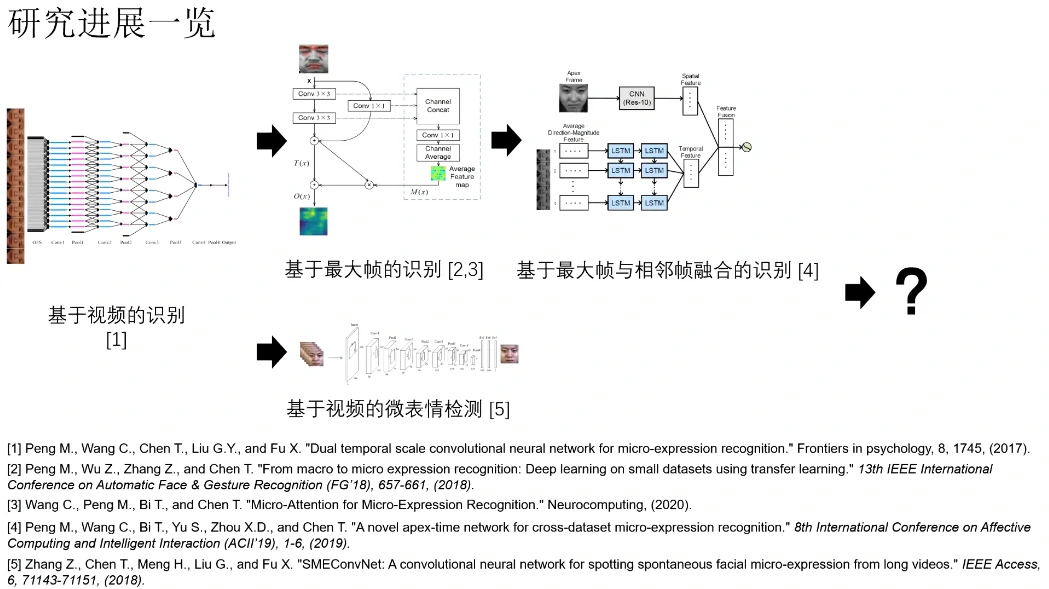
Part 1 视频和最大帧的识别
(彭敏,博士研究生,中科院重庆绿色智能技术研究院)
(陈通,教授,西南大学电子信息工程学院)

研究一:基于视频的端到端微表情识别

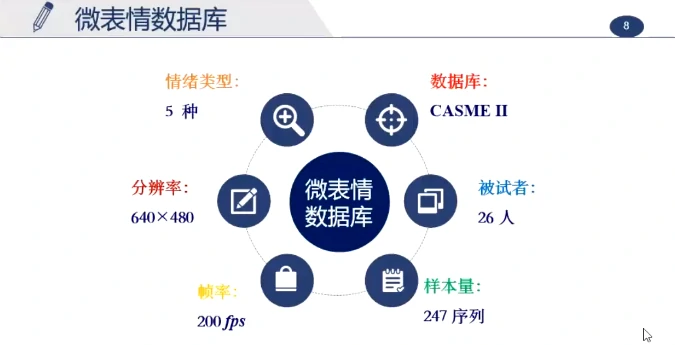
两个常用的微表情数据集:CASME I、CASME II
如何用现有的深度学习网络去训练两个有限集的微表情数据样本,两个数据集帧率不同
如何把视频输入到网络里去训练
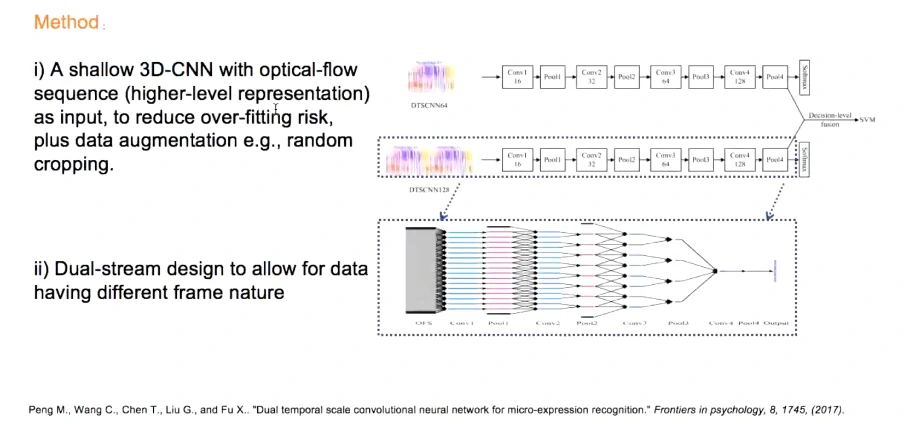
提出了双尺度的深度神经网络,双通道(结构相同,考虑到数据量有限所以模型相对浅层避免过拟合)
对于帧率不同用双通道,60帧单通道、120帧双通道
输入的并不是原始序列,而是经过了光流处理,解决个体差异和背景噪声的问题,光流也是相对比较稀疏的特征,更好地提取表情的运动关系
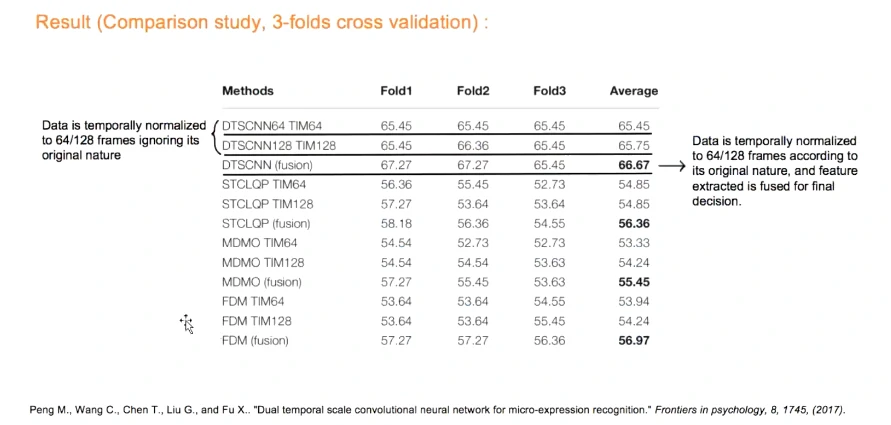
比单尺度和传统方法都好

使用3D卷积神经网络去提取时序信息,输入的是光流特征,相对于原始信息更容易收敛、不容易抖动
结合不同的帧率尺度,能提取更多信息(相对与归一到同一个帧率)

使用卷积神经网络,但数据量有限,能否使用现有的图像数据集进行与训练?
整个视频输入存在数据冗余,很多帧是没有用的,微表情持续时间短、局部运动,微弱的时空信息
研究二:基于最大帧的端到端微表情识别

视频输入改为某一帧输入(标注)

权重初始化、宏表情数据集进行数据迁移、注意力机制残差模块
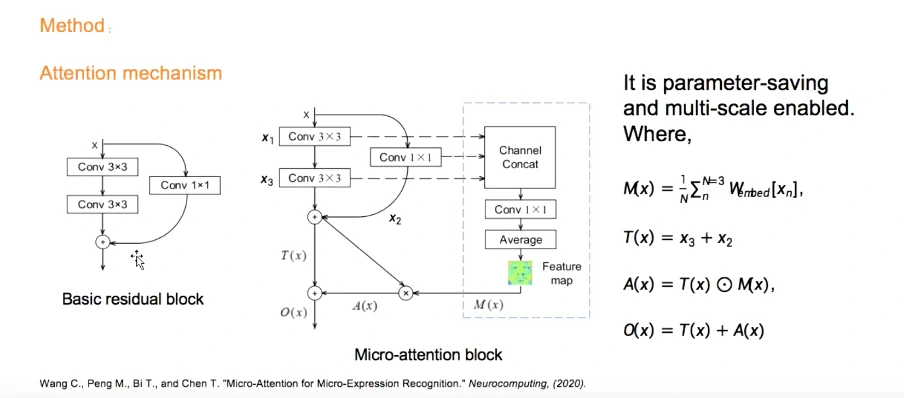
三个层进行特征融合Channel Concat
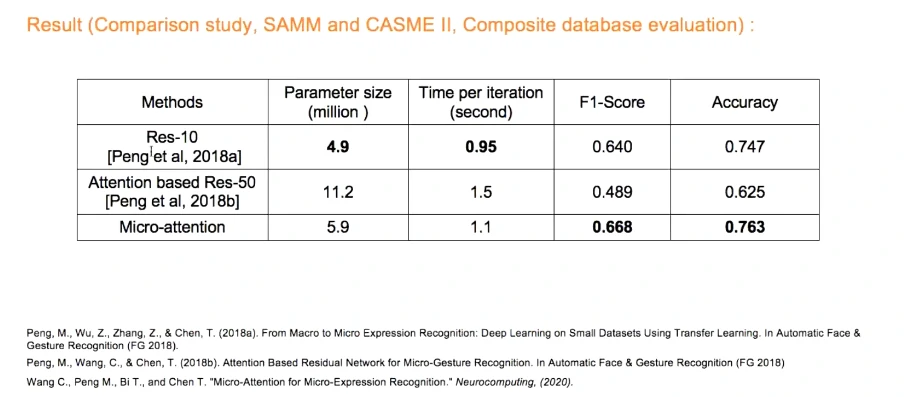
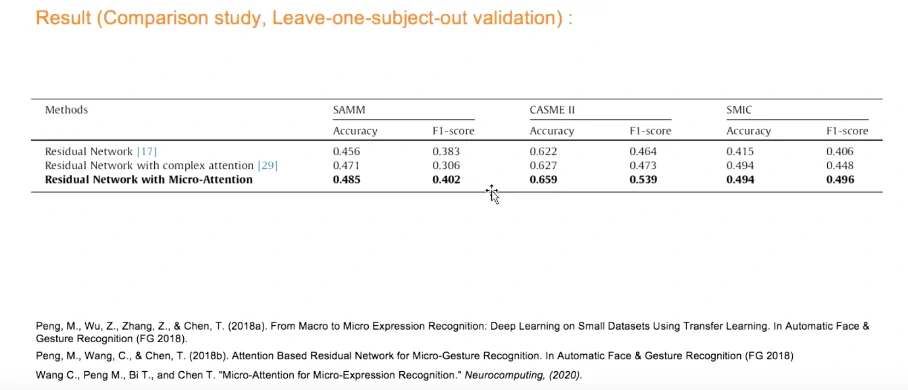
参数量增长不明显,但结果比较客观
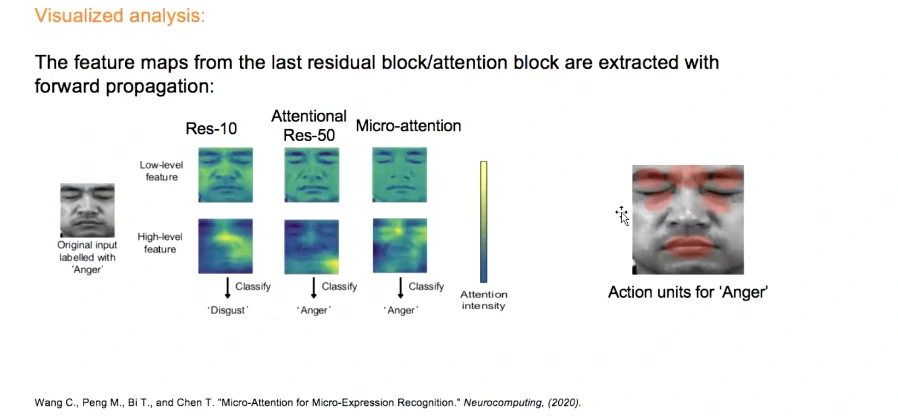
可视化分析:愤怒表情。第三列加入了注意力比较符合

利用最大帧的方式比较可行,基于最大帧更多考虑的是哪一帧能展现更多信息

漏掉了很多表情的持续信息,能否考虑非人工标注的最大帧?
挖掘视频帧集合,更能表现微表情信息?
Part 2 基于卷积网络和滑动窗处理的检测
(张志豪,博士研究生,中科院心理所)
(陈通,教授,西南大学电子信息工程学院)
(傅小兰,研究员,中科院心理所)





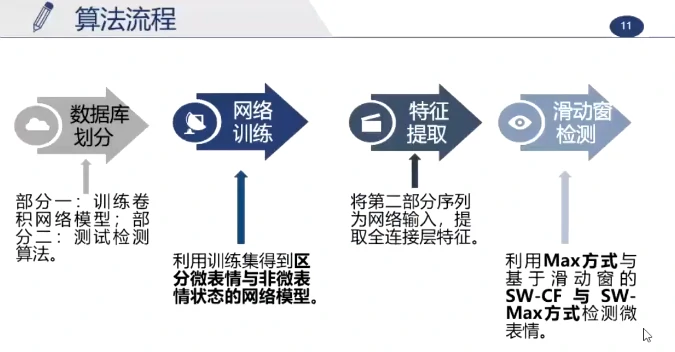
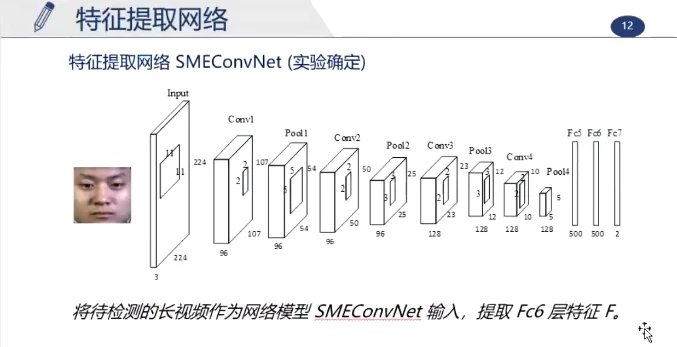
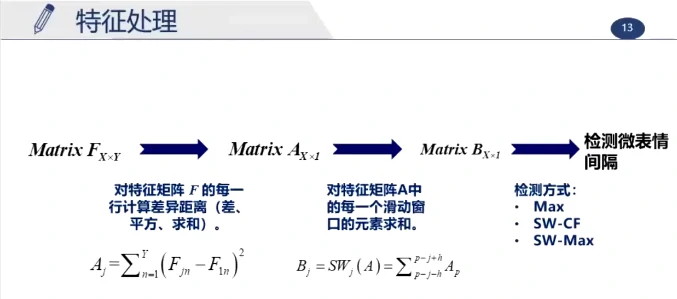
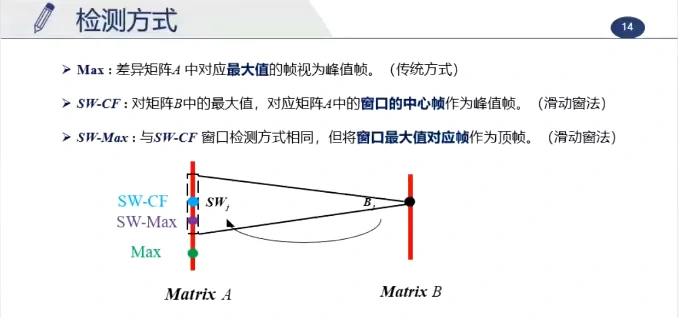

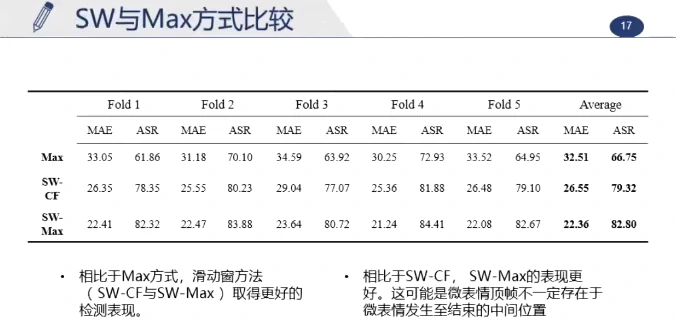
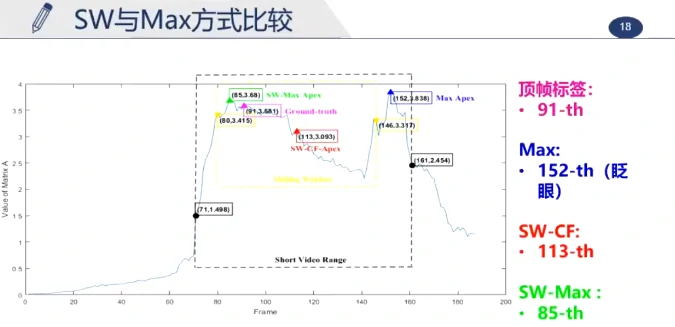
这个长视频大约持续200帧,真实的峰值帧约为第91帧,最大值检测为第152帧(但实际这一帧在眨眼),使用滑动窗更准确,更能排除其他的运动干扰
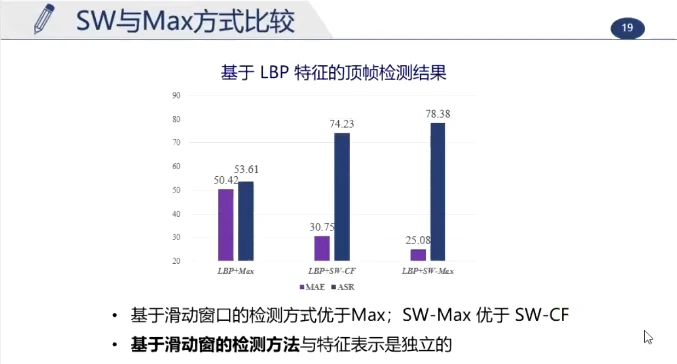
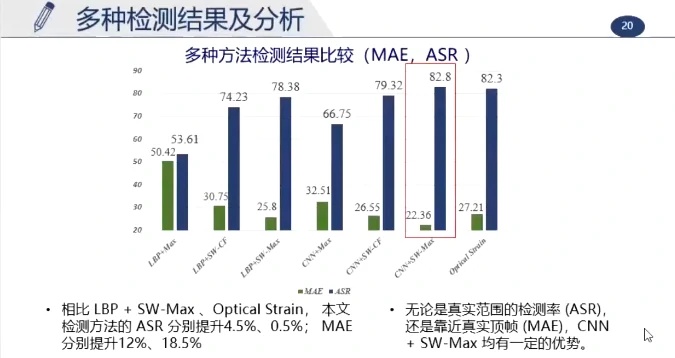
(该项目是第一个使用深度学习来对微表情进行检测的)
Part 3 基于最大帧和相邻帧融合的识别
(王重阳,博士研究生,伦敦大学学院人机交互中心)
(陈通,教授,西南大学电子信息工程学院)
最大帧有它的好处,基于视频也有它的好处,能不能融合起来?

跨数据集的微表情识别,有哪些因素是比较重要的?是否使用单帧是足够的?
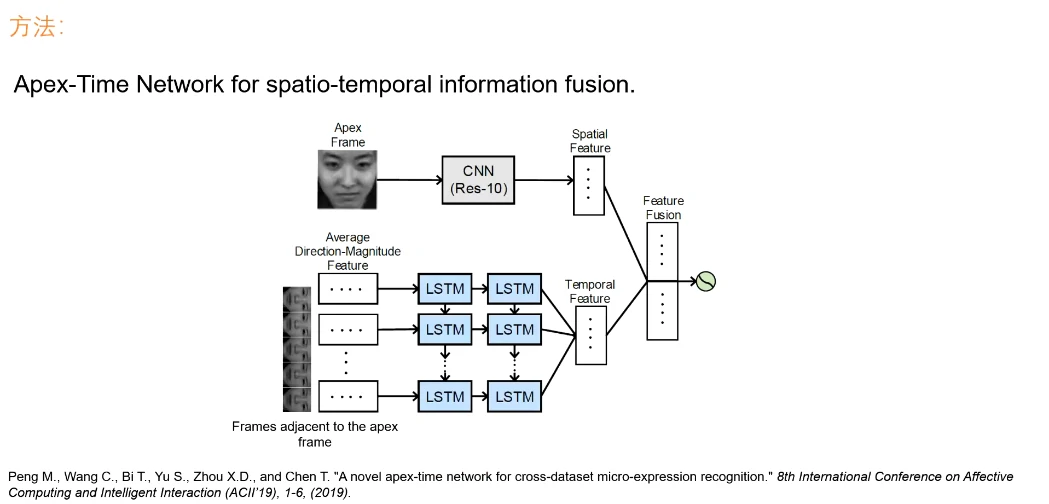
对每个视频段获取最大帧,一般是由数据采集者给定,不然假定是视频的中间帧(以及前后各32帧作为临近帧)
空间特征是单独的一个CNN,时序特征用两层的LSTM(输入前先用光流法提取更数值化的特征)
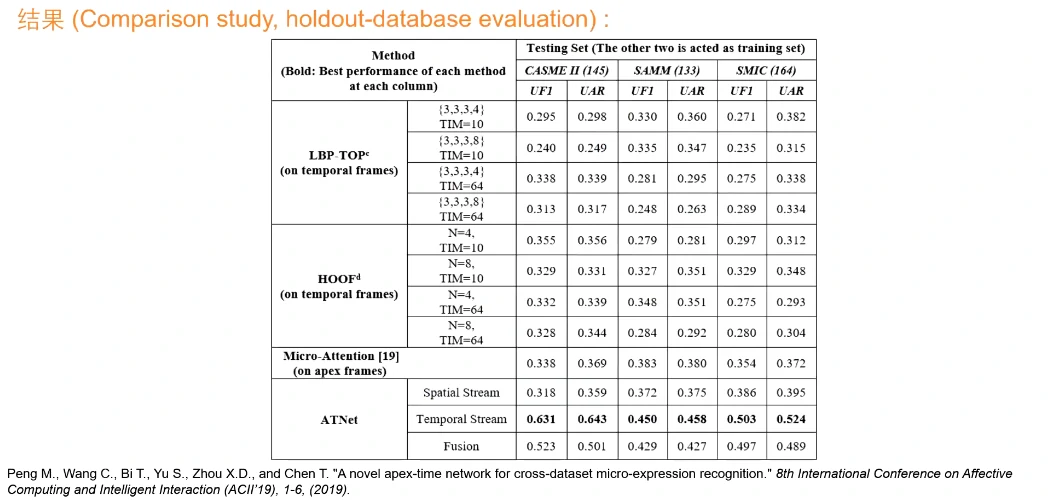
通过深度学习仅用时序是最好的,其次是融合的效果。仅用最大帧降低了很多

微表情的时序特征对于跨数据集非常重要,只用最大帧的话效果是大打折扣的,跨数据集时信息量不足。
微表情的信息是比较稀疏的,用视频的话信息量有些冗余,猜想存在一段帧集合使得识别率达到最高。
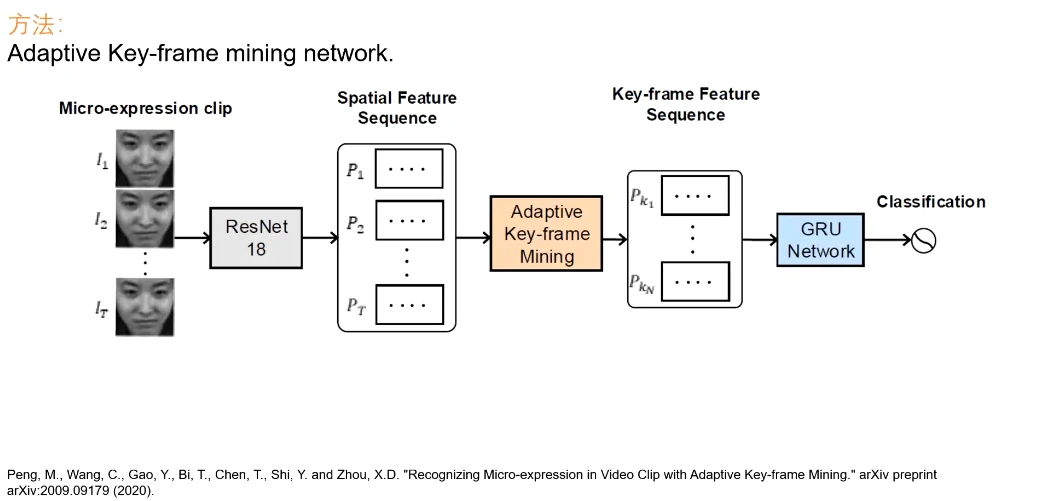
给定一个视频段,对每一帧提取空间特征,通过一个新设计的可适应性的关键帧挖掘机制,筛选出n个最有信息量、最能代表当前表情的关键帧,再用一个GRU网络进行识别。全程是端到端的,无需使用光流,即输入一个视频,就能得到结果。
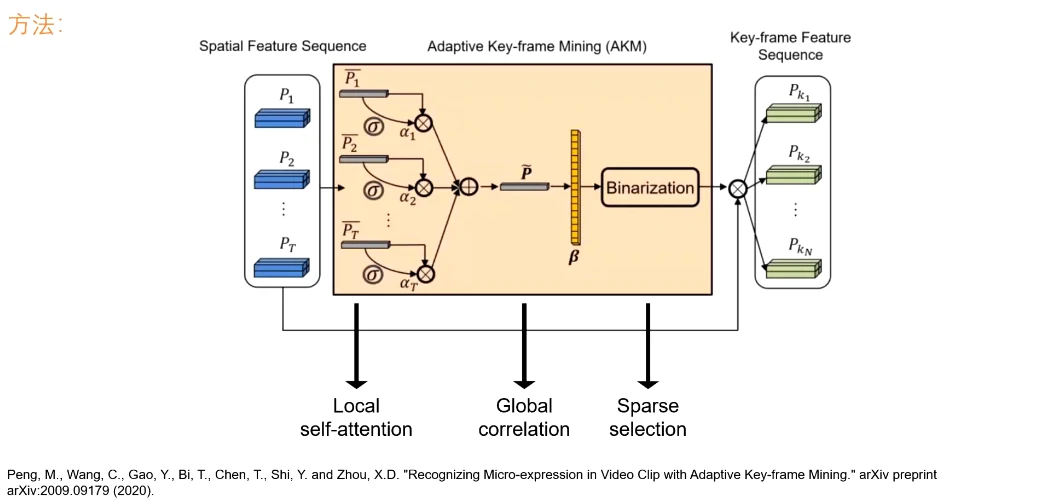
仅用时序的注意力机制的话效果并不好,所以在时序的注意力之上,提出了额外的机制
- 局部的自注意力机制的学习
- 加权之后的帧进行全局比较,得到全局关联系数(一个index的指针列表)
- 对这个指针列表进行稀疏筛选
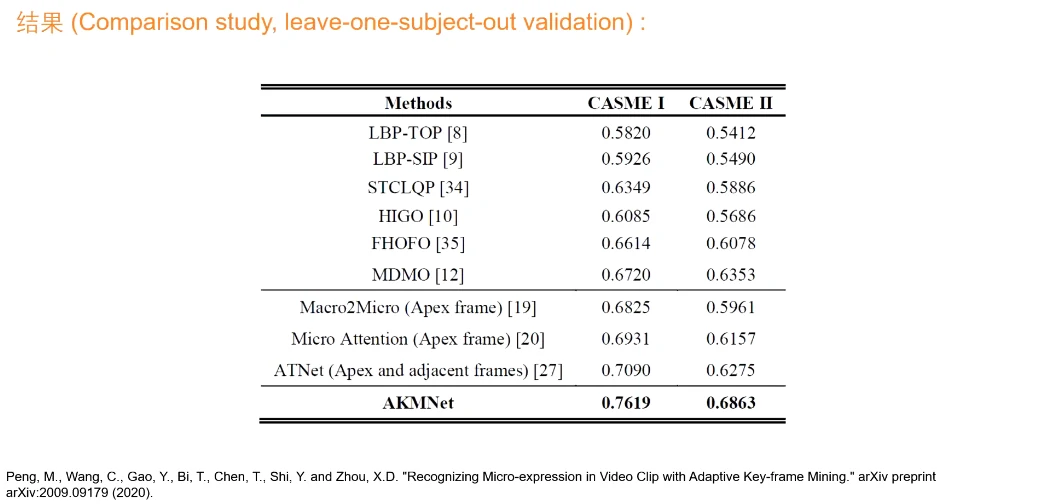
提升非常高!!
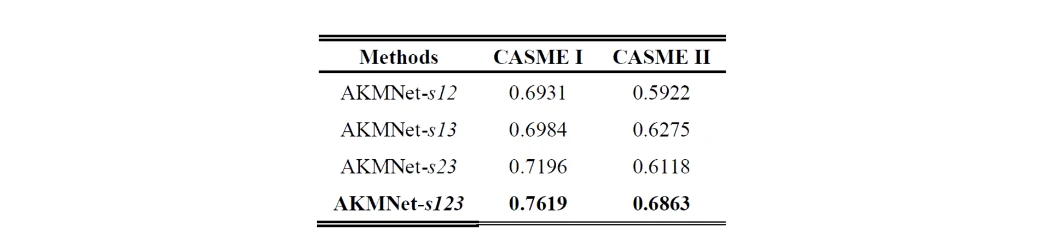
那三步的消融实验,组合起来最有效
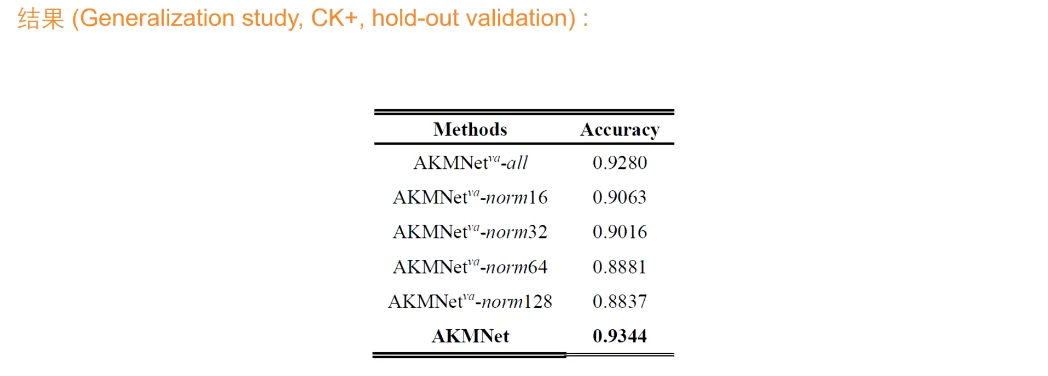
网络的设计是有一定的泛化性的,只要是输入的视频是稀疏的,想要找到特殊帧基本都有效。使用了一个宏表情的视频数据库CK+,做了一个hold-out validation,根据这个网络及其变种(输入全部帧并不筛选、进行时域插值),依然能得到很好的结果,比起同时期发表的对于CK+的paper也是很有可比性的。