
论文题目:NeRF-Supervised Deep Stereo
作者:Fabio Tosi ;Alessio Tonioni; Daniele De Gregorio等人
作者机构:University of Bologna(博洛尼亚大学);Google Inc(全球最大的搜索引擎之一);Eyecan.ai(韩国专注于开发眼动追踪技术的公司)
项目代码:https://github.com/fabiotosi92/NeRF
项目主页:https://nerfstereo.github.io/
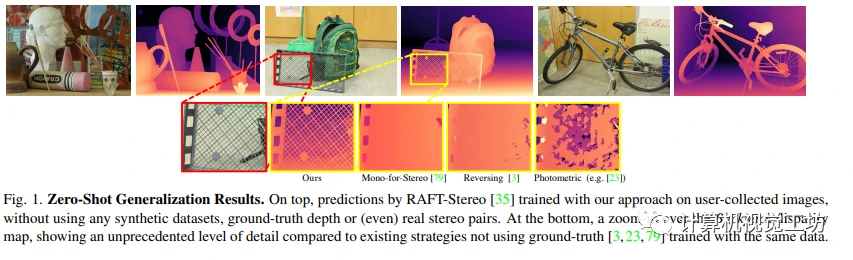
本文提出了一种新的深度立体网络训练框架,可以从使用单个手持相机拍摄的图像序列中生成立体训练数据。这种方法利用了神经渲染解决方案提供的立体图像,跳过了基于ground-truth的训练,使用三元组来补偿遮挡和深度图像作为代理标签进行NeRF监督训练。实验结果表明,训练模型的效果比现有的自我监督方法提高了30-40%,在Middlebury数据集中达到了受监督模型的效果,而且大多数情况下在零拍摄泛化方面表现出色。
前言
本文介绍了神经渲染用于构建灵活可扩展训练数据的新范式,该方法可以轻松地训练深度立体网络且无需任何基础知识。该方法使用标准单手持相机在野外收集稀疏的图像序列,并在其上训练NeRF模型。通过NeRF模型,可以从任意视点合成立体对以自我监督的方式训练任何立体网络,其中通过渲染每个对的第三个视图来有效地解决遮挡问题。此外,NeRF渲染的深度作为代理监督完善了我们的NeRF监督训练方法。实验结果表明,相对于现有的自我监督方法和合成数据集方法,所提出的方法在零拍摄泛化方面表现更出色。
本文的主要贡献可以总结为以下几点:
- 创新的方法来使用神经渲染和一系列用户收集的图像序列来收集和生成立体训练数据。
- 一个 NeRF-Supervised 训练协议,结合渲染图像三元组和深度图来解决遮挡和增强细节。
- 在具有挑战性的立体数据集上实现了最先进的零样本泛化结果,且没有利用任何真实立体对或基准。
相关背景
本文这部分介绍了立体匹配、无监督立体、零样本泛化和神经辐射场等方面的相关工作。在立体匹配中,介绍了近几年深度学习成为该领域主导技术的情况。然而,这些方法严格要求密集的真实地面实况。在无监督立体中,使用光度损失的策略是常见的,但根据作者的说法,这些策略只适用于单个领域的专业化或适应。在零样本泛化中,将视差估算视为制作立体算法的问题进行改进是一条研究思路。在神经辐射场中,NeRF是主要的方法,其模型可以解决多种问题。作者提出的方法是通过从单个图像生成立体对来学习,不需要在数百万图像上预先训练任何模型或有实况标签,但仍然能取得更好的结果。
方法
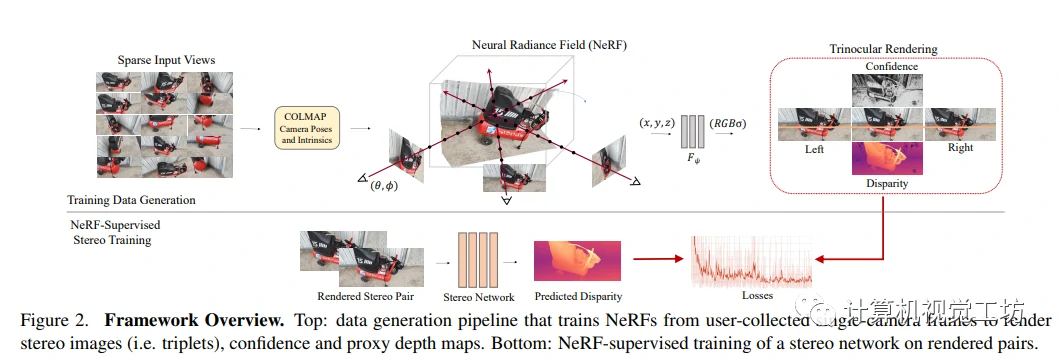
本文提出了NeRF-Supervised(NS)学习框架,用于训练立体匹配网络。该框架的步骤主要包括:从多个静态场景中收集多视角图像,适配NeRF以渲染立体三元组和深度信息,最后使用渲染的数据训练立体匹配网络。
Background: Neural Radiance Field (NeRF) - NeRF背景
神经放射场(NeRF)是一种将场景中点的 3D 坐标和捕捉该点的相机的视角作为输入,映射到颜色-密度输出的模型。为了渲染 2D 图像,该模型通过将相机光线分成预定义的采样点,并使用 MLP 估计每个采样点的密度和颜色,最终使用体渲染合成 2D 图像。显式表示例如体素网格可以存储其他特征,以加速模型训练和计算。
NeRF as a Data Factory - NeRF作为数据工厂
这部分作者介绍了如何使用NeRF作为数据工厂生成立体图像对以训练深度立体网络。首先,作者通过COLMAP对图像进行预处理,然后为每个场景拟合独立的NeRF,并使用渲染损失进行优化。最后,通过虚拟立体相机参数渲染两个新视图和一个第二个目标帧,创建完美校正的立体三元组。在这个过程中,我作者从渲染深度中提取位移,并用它来辅助训练深度立体网络。
NeRF-Supervised Training Regime - NeRF监督训练机制
作者提出了一个NeRF-Supervised训练方案,其中利用一个图像三元组通过光度损失和渲染位移损失对深度立体模型进行监督。三元组光度损失通过使用图像重建来对遮挡问题进行补偿。渲染位移损失被过滤以去除不可靠的像素。最终,两个损失被加权平衡后,用于训练任何深度立体网络。
实验
实施细节
作者使用移动设备捕获的高分辨率场景进行深度估计的方法。通过收集270个静态场景和渲染三元组来生成训练数据,并使用Instant-NGP作为NeRF engine实现,以实现精确深度估计。此外,还引入了一个提议来提高现有立体算法的性能,并利用普通的相机进行实现。其中,作者采用了准确性和快速收敛的RAFT-Stereo作为主要架构,并使用PSMNet和CFNet进行评估,提高了这些算法的性能。
评估数据集与协议
作者使用KITTI、Middlebury和ETH3D数据集进行评估,计算视差误差指标,并按照立体匹配领域的协议定义验证和测试集。评估采用固定的阈值τ,分别为KITTI固定τ = 3,Middlebury固定τ = 2,ETH3D固定τ = 1。在评估期间,考虑遮挡和非遮挡区域并具有有效的基准视差。
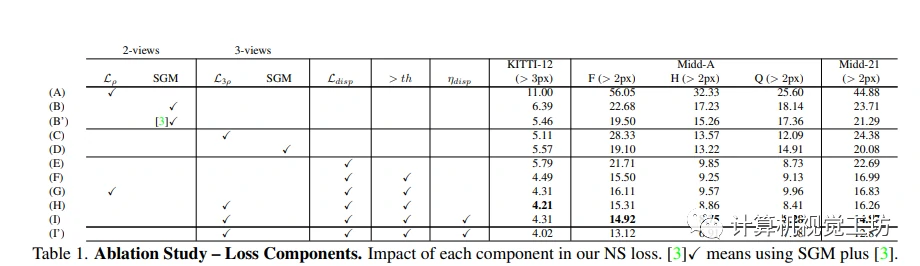
消融研究
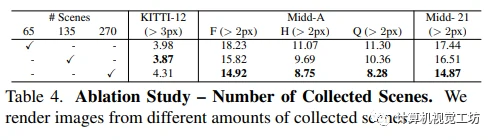
作者使用渲染视频生成大规模立体训练数据集的方法,涉及渲染参数选择,标签生成和代理损失的选择方法等。在进行降板研究时,作者发现在他们的数据集上使用L3ρ损失是最佳的,这利用了他们的渲染三重组合产生的三角形几何形状的自监督。本文还介绍了使用虚拟基线对视差分布的影响,评估了渲染图像的分辨率以及收集的场景数量在训练过程中的影响。作者发现,更多的图像及更小的虚拟基线可以提高模型的性能。在最具挑战性的数据集上使用更多场景可以显著提高模型的准确性。

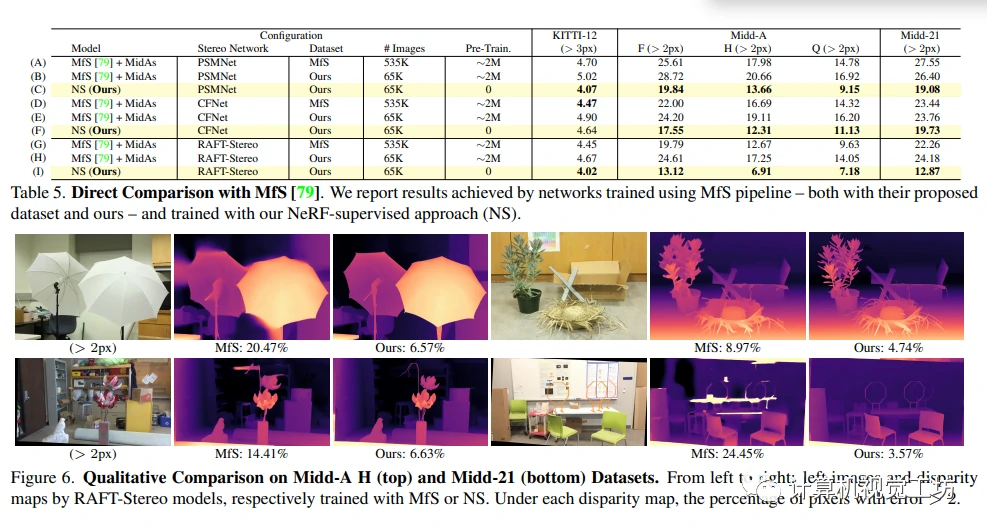
与MFS对比
作者比较了本文的方法和最新的从单一图像生成立体图对方法MfS,并通过训练三种立体网络得出。研究表明,在使用MfS生成方法和使用MfS数据集上训练时,MfS表现较好(A,D和G)。然而,本文的方法在不需要使用大量训练数据的情况下,通过NS范式提供的监督训练的立体网络在大多数情况下表现更好,证明了我们的NS范式实现了更好的性能和更高的预测质量。
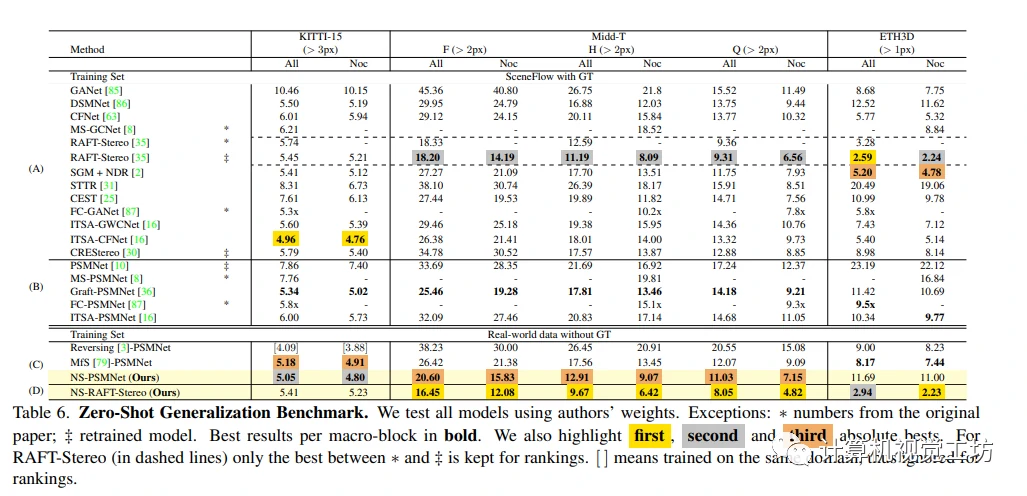
零样本泛化基准测试
作者针对立体视觉领域的零样本泛化问题,在NS-PSMNet模型的基础上进行了实验评估并与其它先进方法进行了比较。针对不同论文中关于Middlebury数据集评估协议的不一致性问题,本文重新评估了相关方法并建立了一个公共评估协议。通过对比实验结果,本文发现组合使用泛化能力较强的RAFT-Stereo和NS的方法可以在Middlebury数据集上获得最佳结果。同时,在使用全部数据集作为评估标准时,NS-PSMNet模型的表现优于除了PSMNet的其他先进方法。
总结
NeRF-Supervised Deep Stereo提出了一种新的学习框架,可以轻松地训练立体匹配网络,而不需要任何ground-truth数据,该论文还提出了一种NeRF-Supervised训练协议,该协议结合了渲染图像三元组和深度图,以解决遮挡问题并增强细节,实验结果表明,该模型在挑战性的立体数据集上取得了最先进的零样本泛化结果。
本文提出了一种利用NeRF训练深度立体网络的创新流程,通过单个低成本手持相机捕捉图像进行训练,产生了最先进的零样本泛化,超越了自我监督和监督方法。虽然局限于小规模、静态的场景,而且仍无法处理具有挑战性的条件,但是作者的工作是数据民主化的显著进步,将成功的关键置于用户手中。