原文
这是李沐博士论文精读的第五篇论文,这次精读的论文是 GAN。目前谷歌学术显示其被引用数已经达到了37000+。GAN 应该是机器学习过去五年上头条次数最多的工作,例如抖音里面生成人物卡通头像,人脸互换以及自动驾驶中通过传感器采集的数据生成逼真的图像数据,用于仿真测试等。这里李沐博士讲解的论文是 NeurIPS 版,与 arXiv 版稍有不同。
GAN 论文链接:https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
标题、作者、摘要
首先是论文标题,GAN 就取自于论文标题首字母,论文标题中文意思是:生成式对抗网络。机器学习里面有两大类模型:一种是分辨模型,例如 AlexNet、ResNet 对数据进行分类或预测一个实数值、另一种就是生成模型,用于生成数据本身。Adversarial 是对抗的意思,第一次读的时候可能不知道什么意思,先放在这里,接着往下读。最后是 Nets,网络的意思,不过建议大家还是写成 Networks 比较规范一些。
下面是论文作者,一作大家很熟悉了,他的另一个代表作就是深度学习经典书籍(花书):《深度学习》,通信作者是深度学习三巨头之一,2018年图灵奖的获得者。

下面是论文摘要,摘要总共七句话。
- 前三句话介绍我们提出了一个新的 framework, 通过对抗过程估计生成模型;我们同时会训练两个模型,一个是生成模型 G,生成模型用来捕获数据的分布,另一个模型是辨别模型 D,辨别模型用来判断样本是来自于训练数据还是生成模型生成的。生成模型 G 的训练过程是使辨别模型犯错概率最大化实现的,当辨别模型犯错概率越大,则生成模型生成的数据越接近于真实数据。整个framework类似于博弈论里的二人对抗游戏。
- 第四句话是说,在任意函数空间里,存在唯一解,G 能找出训练数据的真实分布,而 D 的预测概率为 1/2,此时辨别模型已经分辨不出样本的来源。
- 最后就是说生成模型和辨别模型可以通过反向传播进行训练,实验也显示了提出的框架潜能。

导言、相关工作
下面是 Introduction 部分,总共3段。
- 第一段说深度学习在判别模型取得了很大的成功,但是在生成模型进展还很缓慢,主要原因是在最大似然估计时会遇到很多棘手的近似概率计算,因此作者提出一个新的生成模型来解决这些问题。
- 第二段作者举了一个例子来解释对抗网络。生成模型好比是一个造假者,而判别模型好比是警察,警察需要能区分真币和假币,而造假者需要不断改进技术使警察不能区分真币和假币。
- 第三段说生成模型可以通过多层感知机来实现,输入为一些随机噪声,可以通过反向传播来训练。

然后是相关工作部分,这里有件有趣的事。当时 GAN 作者在投稿时,Jürgen Schmidhuber 恰好是论文审稿者,Jürgen Schmidhuber 就质问:“你这篇论文和我的 PM 论文很相似,只是方向相反了,应该叫 Inverse PM 才对”。然后Ian就在邮件中回复了,但是两人还在争论。
一直到 NIPS2016 大会,Ian 的 GAN Tutorial上,发生了尴尬的一幕。Jürgen Schmidhuber 站起来提问后,先讲自己在1992年提出了一个叫做 Predictability Minimization 的模型,它如何如何,一个网络干嘛另一个网络干嘛,接着话锋一转,直问台上的Ian:“你觉得我这个 PM 模型跟你的 GAN 有没有什么相似之处啊?” 似乎只是一个很正常的问题,可是 Ian 听完后反应却很激烈。Ian 表示:“Schmidhuber 已经不是第一次问我这个问题了,之前我和他就已经通过邮件私下交锋了几回,所以现在的情况纯粹就是要来跟我公开当面对质,顺便浪费现场几百号人听 tutorial 的时间。然后你问我 PM 模型和 GAN 模型有什么相似之处,我早就公开回应过你了,不在别的地方,就在我当年的论文中,而且后来的邮件也已经把我的意思说得很清楚了,还有什么可问的呢?”
关于Jürgen Schmidhuber 和 Ian之间争论的更多趣事可以看这篇文章:从PM到GAN——LSTM之父Schmidhuber横跨22年的怨念。
模型、理论
下面开始介绍 Adversarial nets。为了学习生成器在数据 x 上的分布 p_g,我们定义输入噪声变量 p_z(z),数据空间的映射用 G(z; θ_g) 表示,其中 G 是一个可微分函数(多层感知机),其参数为 θ_g。我们再定义第二个多层感知机 D(x; θ_d),其输出为标量。D(x) 表示数据 x 来自真实数据的概率。
下面是训练策略,我们同时训练生成模型 G 和判别模型 D。对于判别模型 D,我们通过最大化将正确标签分配给训练样本和生成器生成样本的概率来训练;对于生成模型 G GG,我们通过最小化 log(1−D(G(z))) 来训练,总结为:
- D(x) 概率越大,判别器训练越好,log D(x) 越大
- D(G(z)) 概率越小,判别器训练越好,log(1−D(G(z))) 越大
- D(G(z)) 概率越大,生成器训练越好,log(1−D(G(z))) 越小

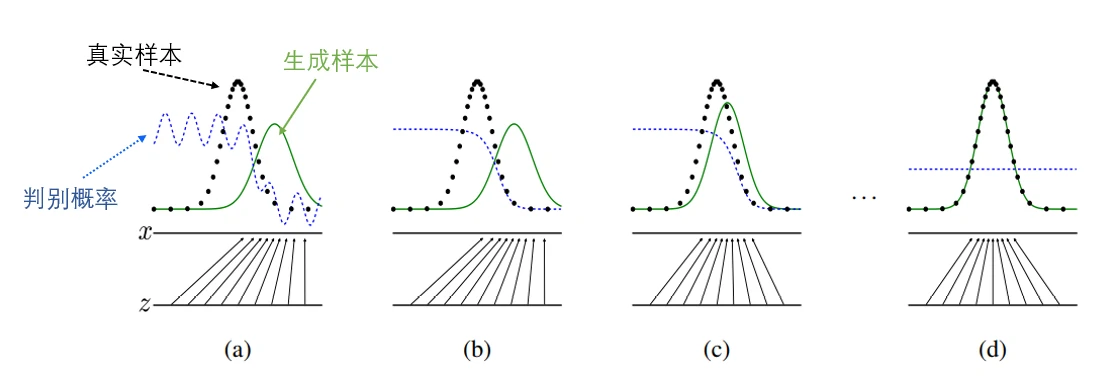
下图是对抗网络训练的直观示意图,黑色曲线是真实样本,绿色曲线为生成样本,蓝色曲线为判别概率。可以看到在(a)阶段,真实样本和生成样本分布不一致,此时判别器能够正确区分真实样本和生成样本。到(d)阶段,真实样本和生成样本分布几乎一致,此时判别器很难再区分二者,此时判别器输出概率为 1/2。
算法1是整个对抗网络的正式描述,对于判别器,我们通过梯度上升来训练;对于生成器,我们通过梯度下降来训练。

在实际训练时,公式(1)往往不能提供足够的梯度让生成器去学习。因为在学习的早期阶段,生成器 G 性能很差,判别器 D 有着很高的置信度判别数据来源。在这种情况,log(1−D(G(z))) 存在饱和现象。因此在这个时候,我们通过最大化 log D(G(z)) 来训练生成器 G。

下面是 Theoretical Results,对于任意给定的生成器 G,则最优的判别器 D 为:
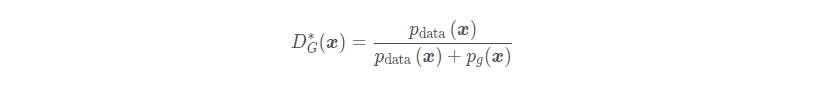
下面是证明过程,对于给定的生成器 G,判别器 D 通过最大化期望 V(G,D) 来训练,V(G,D) 为:
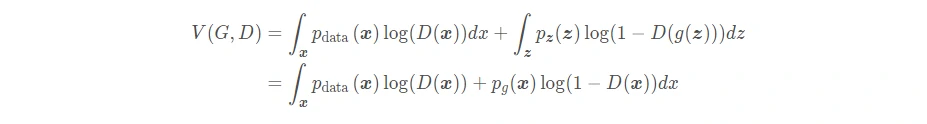
已知 (a, b)∈R^2,函数 y → a log(y) + b log(1−y) 在 a/(a+b) 处取得最大值。

根据上面的证明,在最优判别器处,则有最大期望值 −log4。

最后简单总结下,虽然在本文中,作者做的实验现在来看比较简单,但是整个工作是一个开创性的工作,GAN 属于无监督学习研究,而且作者是使用有监督学习的损失函数去训练无监督学习;而且本文的写作也是教科书级别的写作,作者的写作是很明确的,读者只看这一篇文章就能对 GAN 有足够的了解,不需要再去看其它更多的文献。