Part 1 基于深度学习的微表情识别介绍


相对与macro-expression,micro-expression更加细微,肉眼来看很难判别出来,希望通过算法来识别微表情
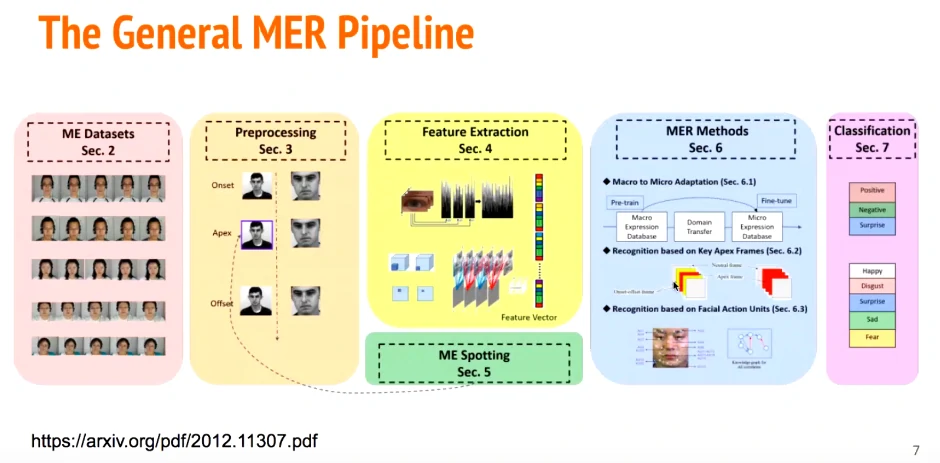
数据集->预处理->特征提取->微表情识别->分类
微表情识别:宏表情迁移到微表情、基于顶点帧、基于动作单元AU
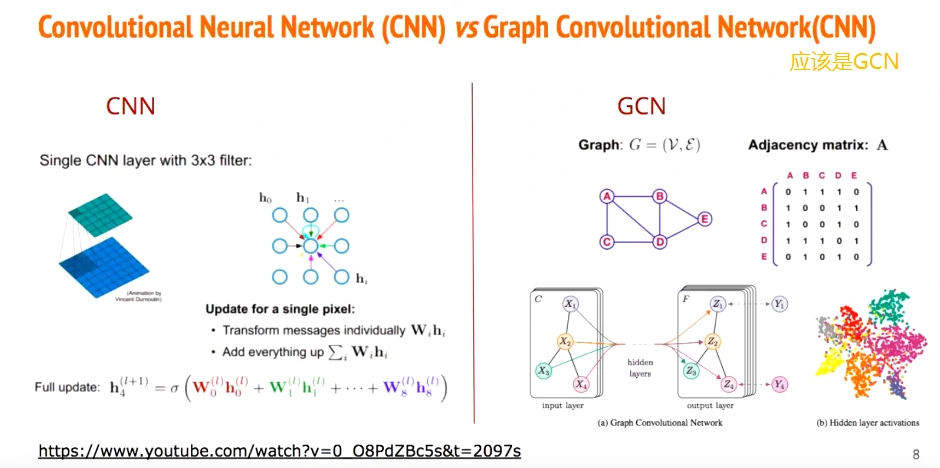

利用已有的AU关联

输入的两个维度:node feature、adjacency matrix
N代表节点的数量,d代表每个的特征维度
每个GCN layer跟CNN层有异曲同工之妙(这不就跟全连接到卷积,从全局连接到部分连接;卷积到图网络,局部连接到全局自定义连接。更加稀疏了么,而且自由度更高,消除了不必要的节点连接冗余)

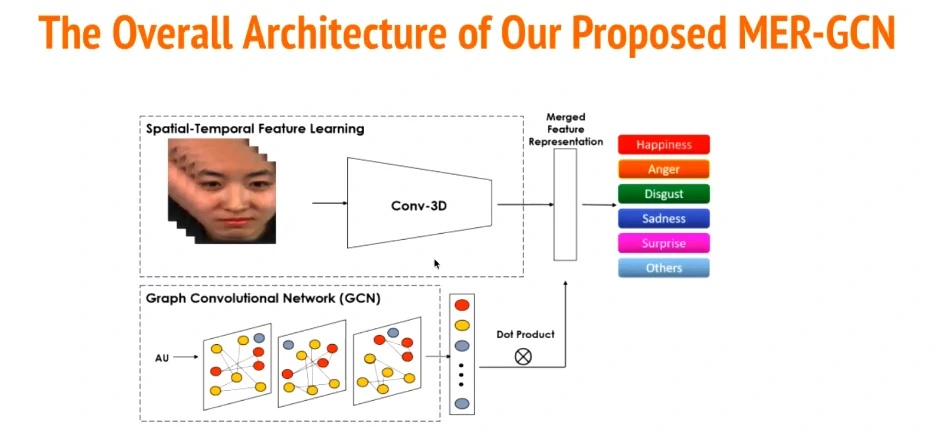
在普通的CNN提取人脸特征下,加入了一个AU检测的GCN,然后concat进行分类

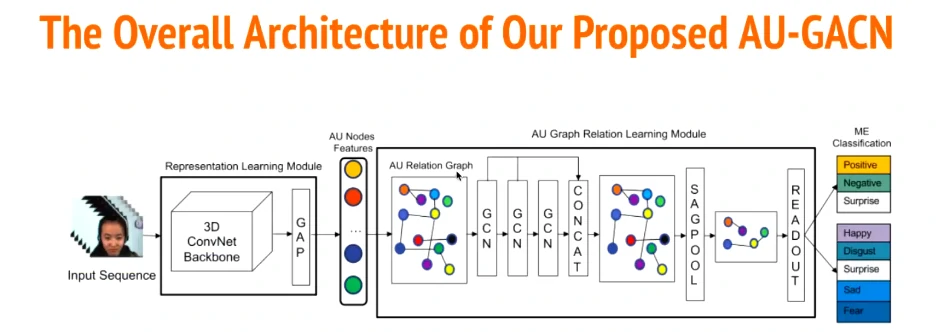
基于上一篇论文,但思路跟前面有一点点不一样。先汇入一个3D ConvNet作为Backbone,然后经过三层GCN和sagpool,得出有用的节点信息进行分类
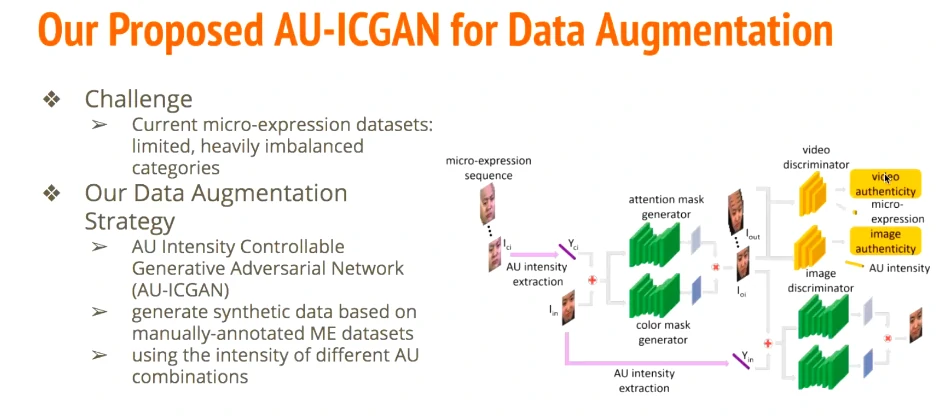
提出AU-ICGAN去生成微表情的data。attention mask是为了将注意集中在人脸而不是背景,color mask集中注意在rgb这个通道

(loss有点多看不太懂,前四个是对单张图片的,后面三个是对于视频序列的)

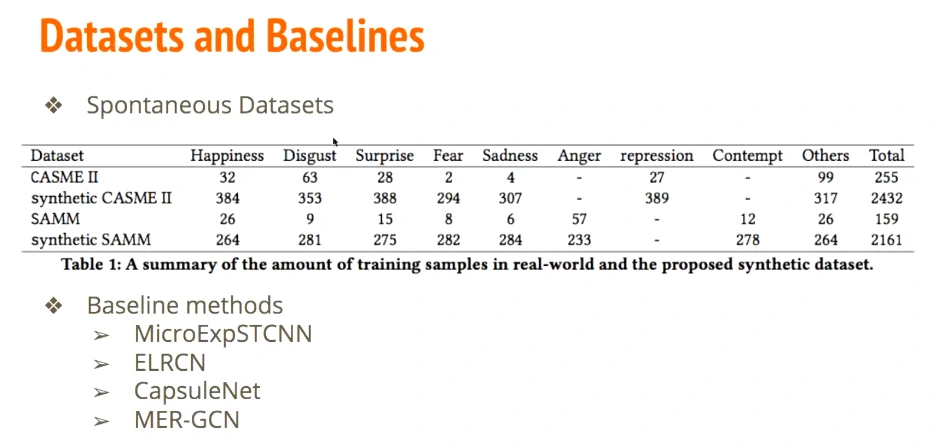
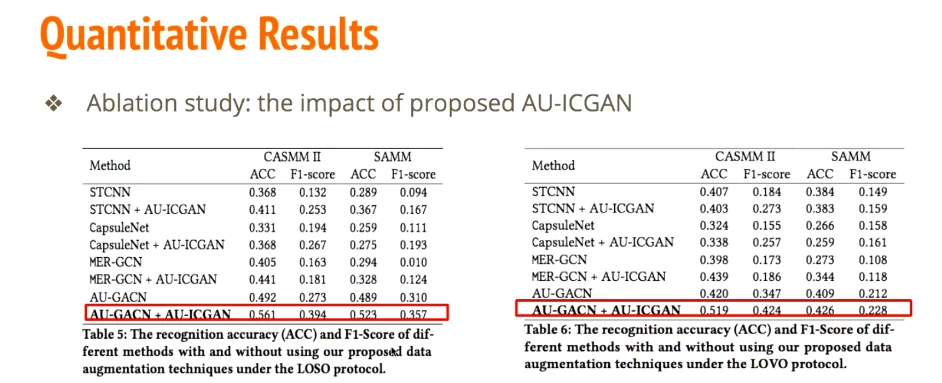
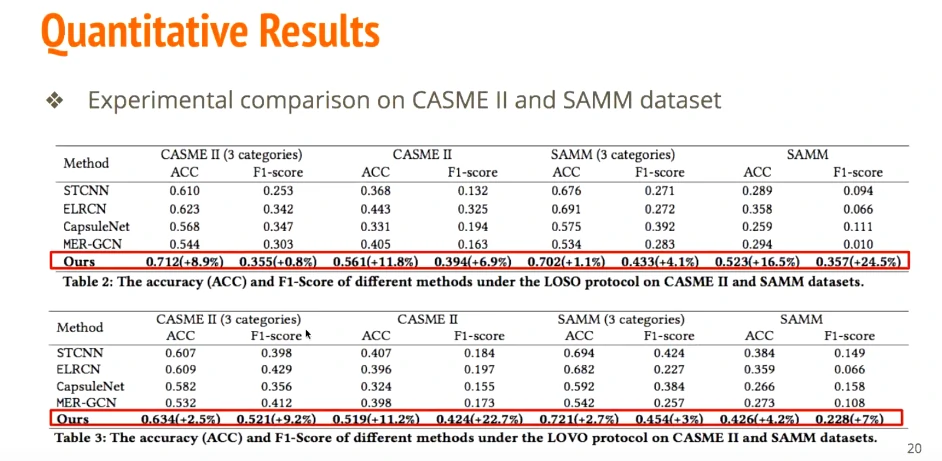

人脸存在不对称性,多模态等…看看能不能提升准确度
Part 2 Local Temporal Pattern and Data Augmentation for Micro-Expression Spotting
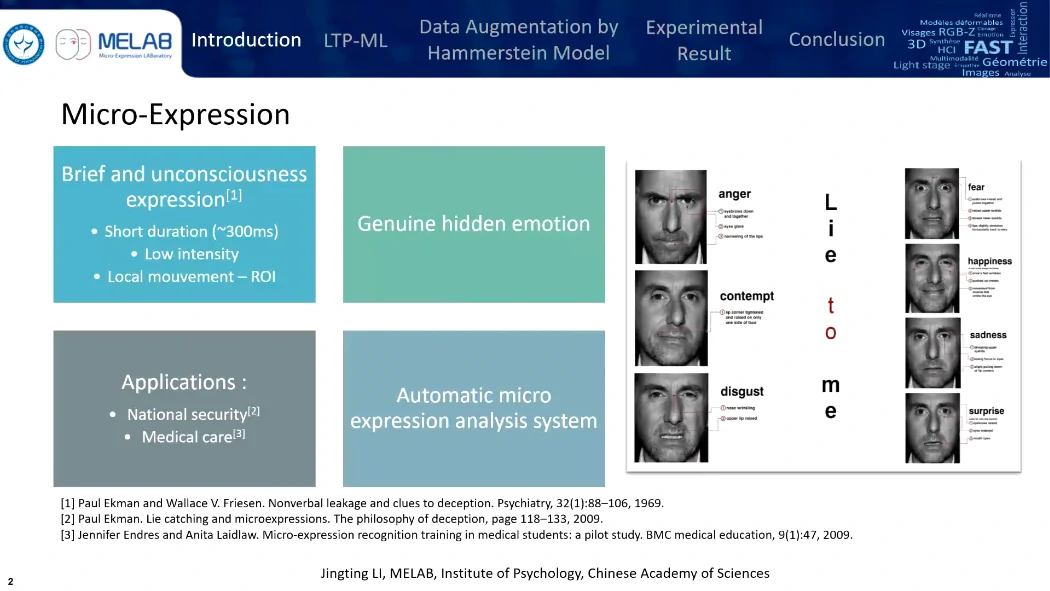

样本量很少,5个数据集加起来也就800个左右,对机器学习很有挑战性。
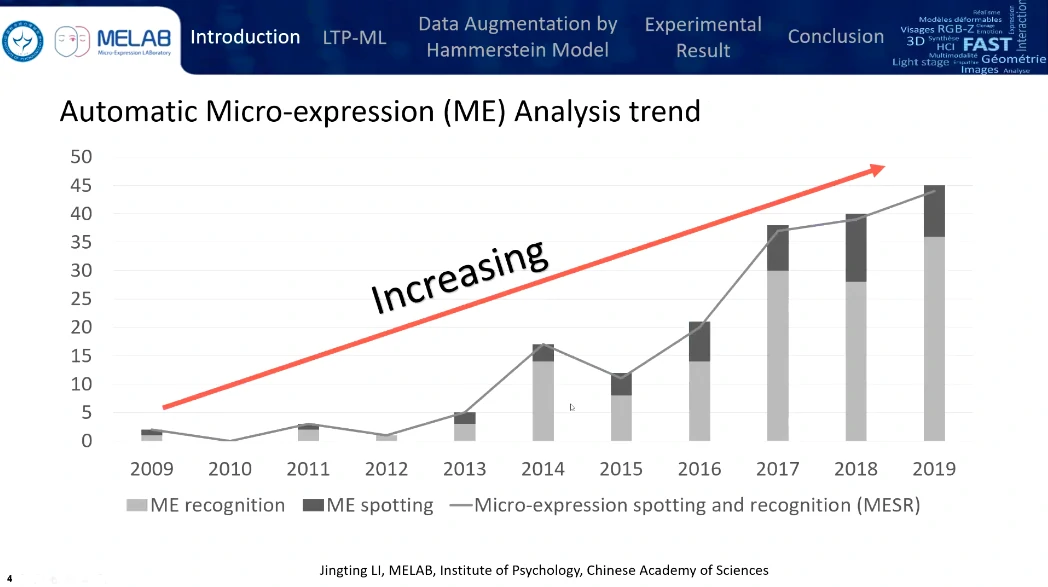
2013~2014年发布了CASME有小幅上升,微表情检测的F1-score < 0.1,对于实际应用十分有挑战性。

微表情的三个特点:持续时间短、微表情运动强度低、非常局部的面部运动。
主流的两种思路:比较峰值帧之间的特征(相当于传统的图像处理的方法 or 结合机器学习来做一个比较)、
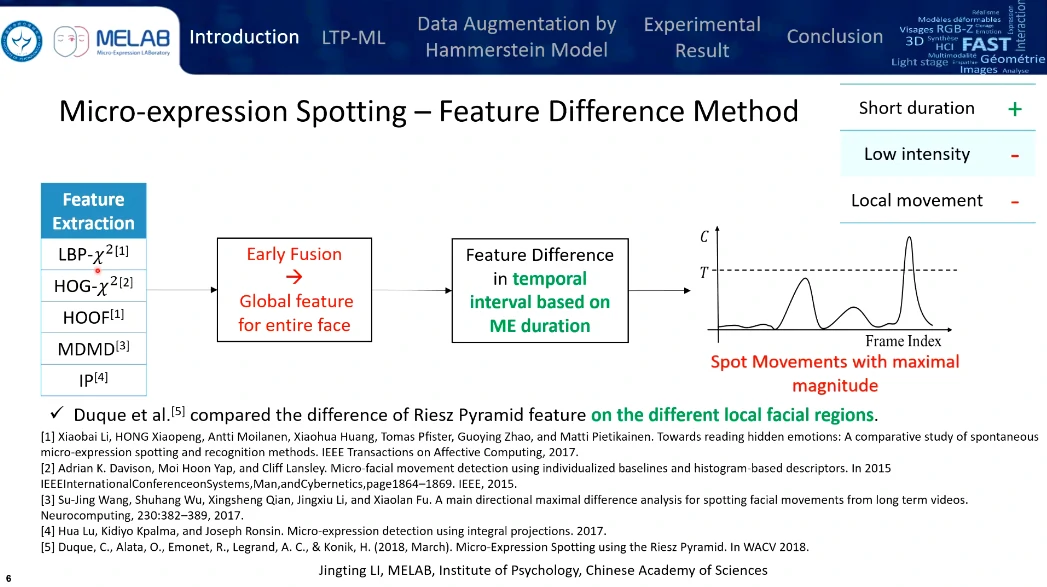
特征的局部提取、融合、时域上检测帧与帧之间的差别,检测到一段时间内最大的峰值为微表情,缺点是检测到的不一样是微表情,可能只是当前区间内一个比较显著的特征(并非微表情特征),由于先前已融合特征所以微表情的局部特征有可能已经被忽略掉了,优点是考虑到了微表情时长的变化。

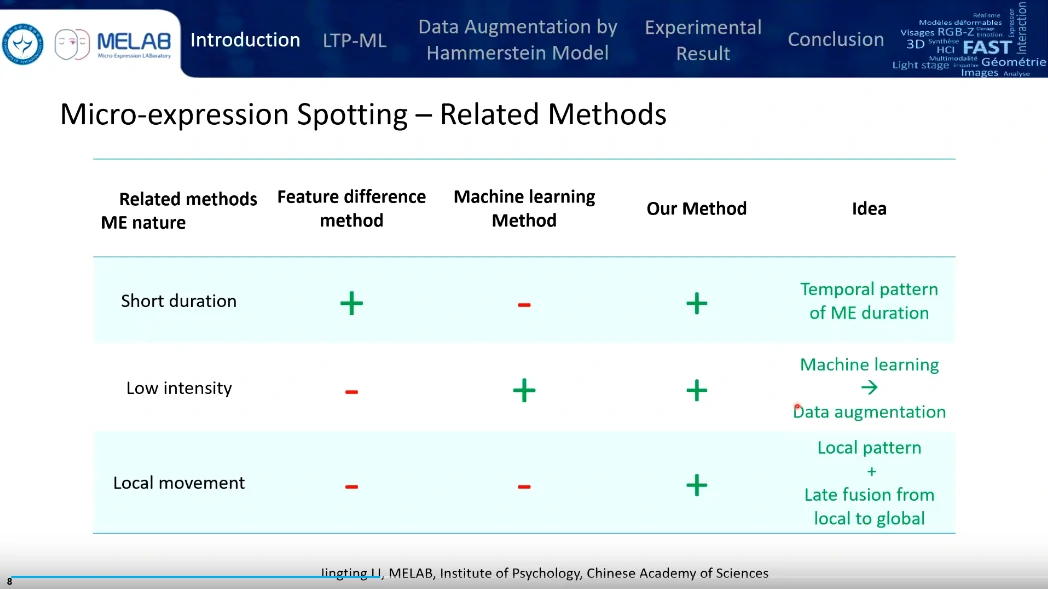
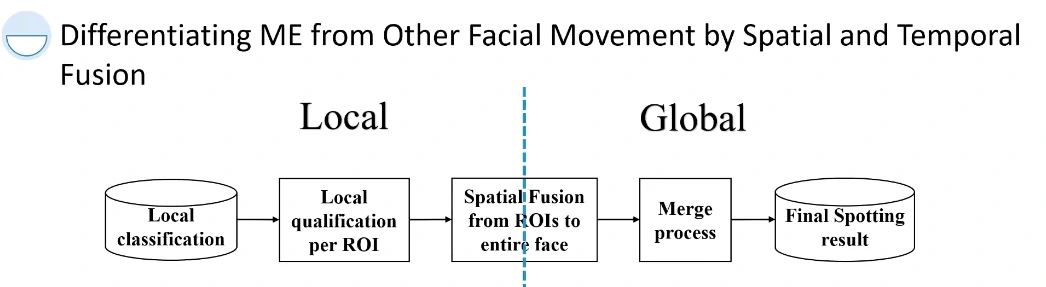
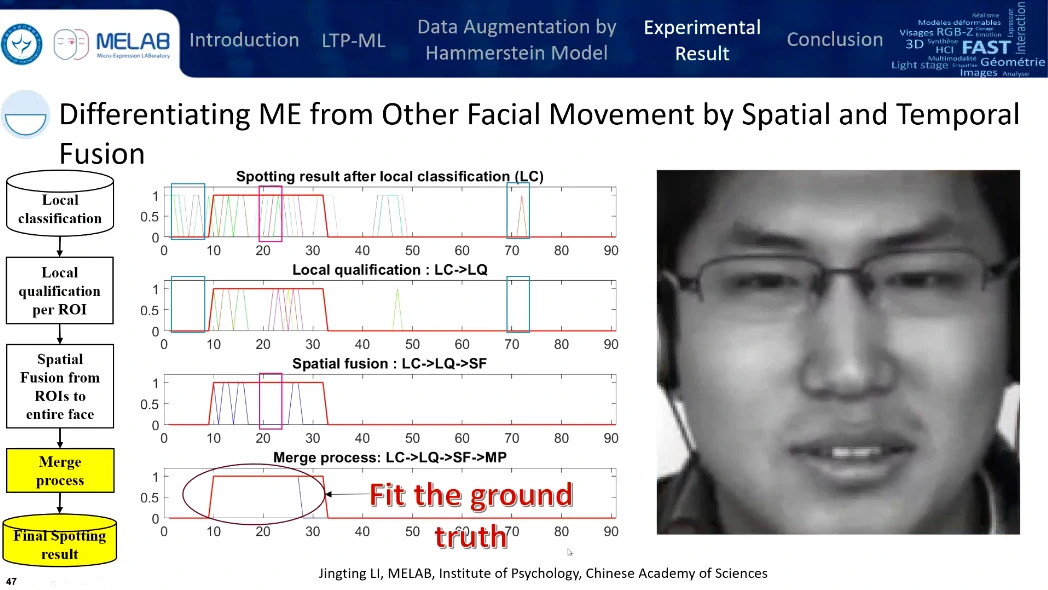
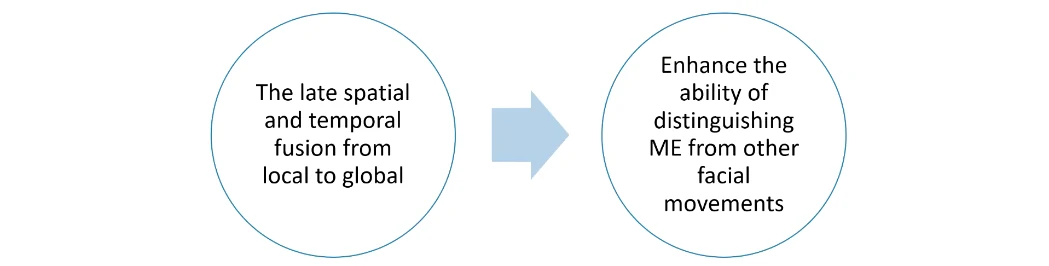
考虑时域特征、机器学习+数据扩增、提出了一个叫做晚期融合的方法(Late fusion from local to global)
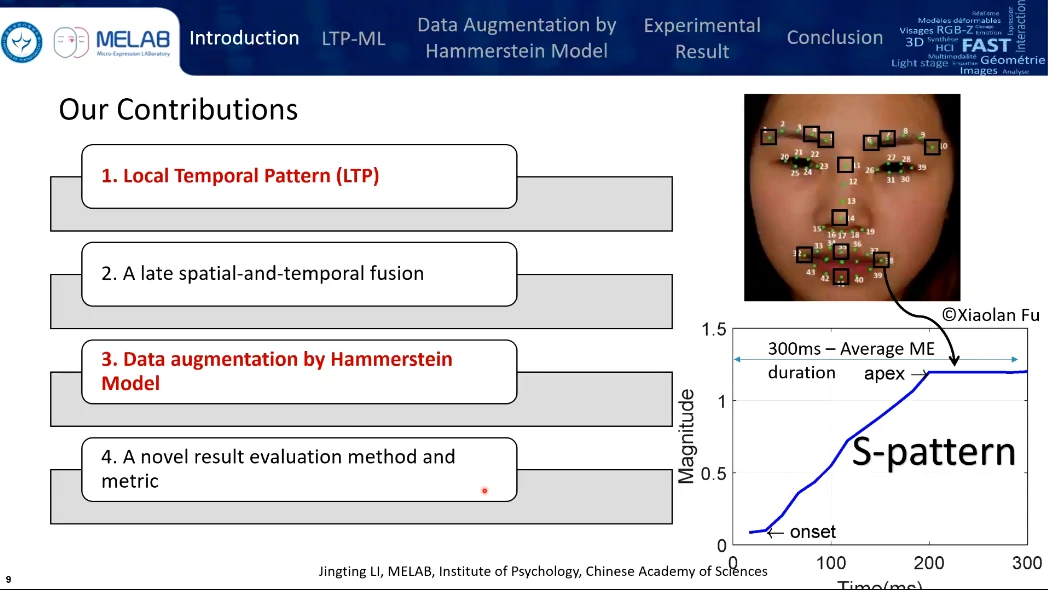
- 局部时空特征
- 晚期的时空融合
- 基于Hammerstein模型的数据扩增
- 一个新的验证方法和度量标准
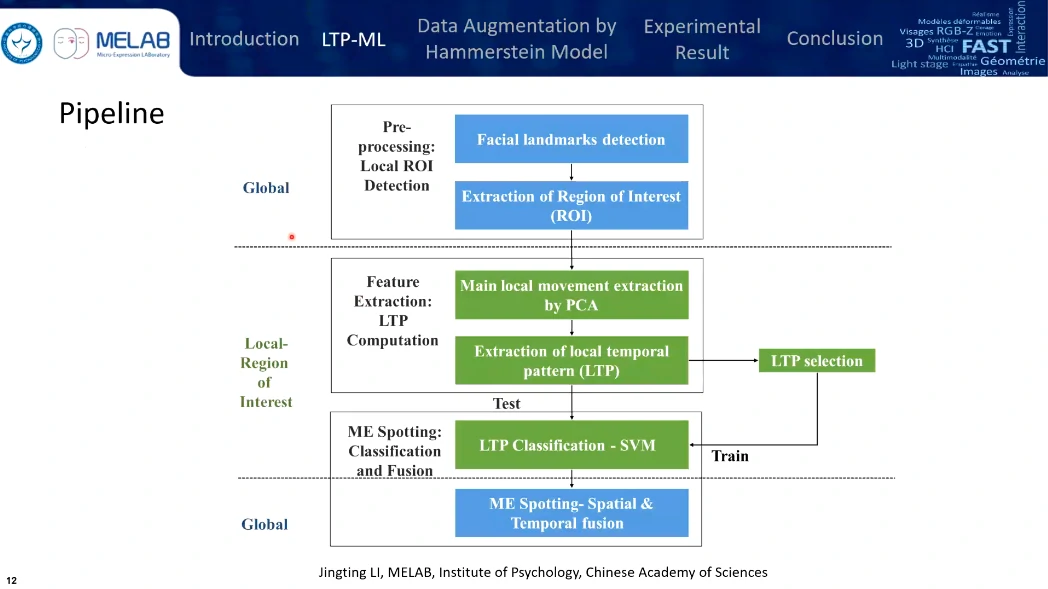
从全局到局部再到全局,预处理、特征提取、融合与检测
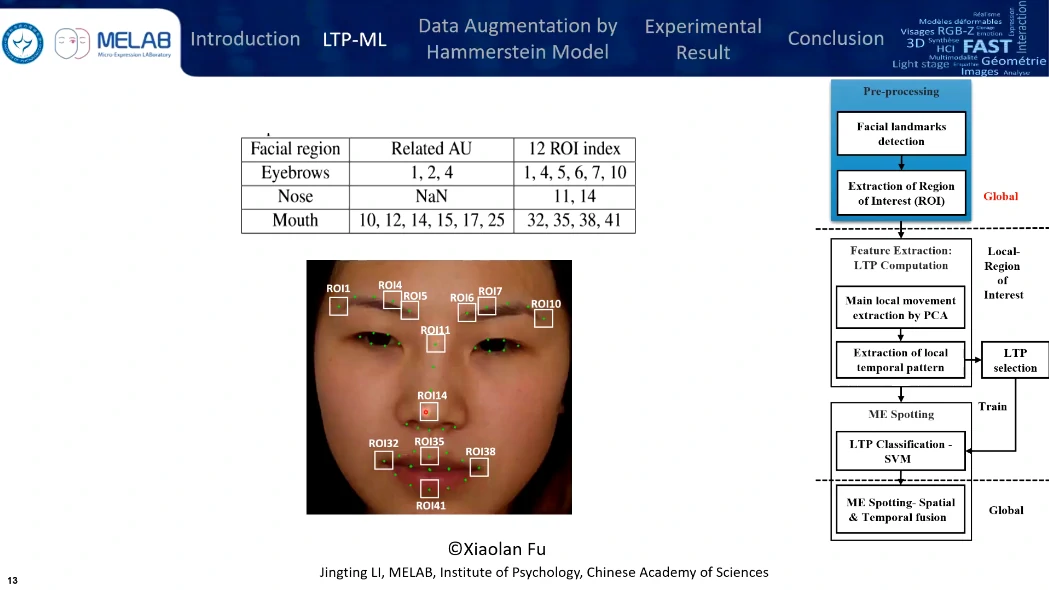
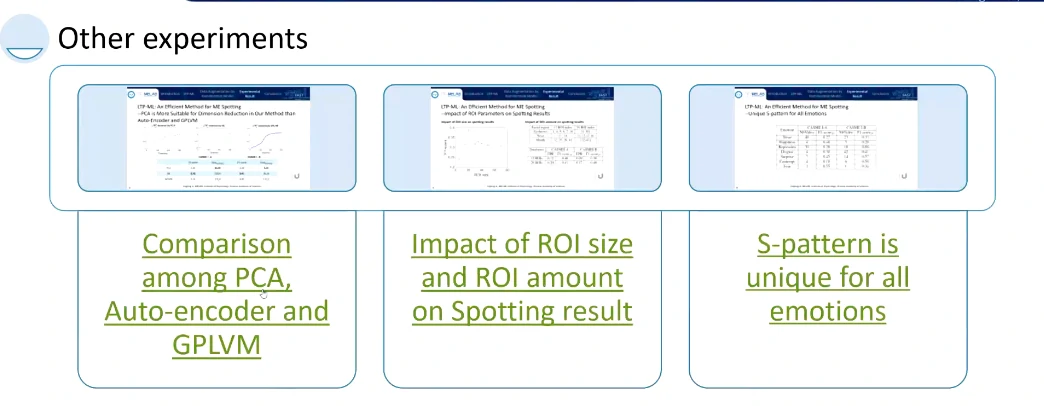
只选取了12个兴趣区域,眉毛、嘴角还有鼻子,鼻子作为头部运动的整体参考,区域的尺度选择是眼角内部距离的1/5。
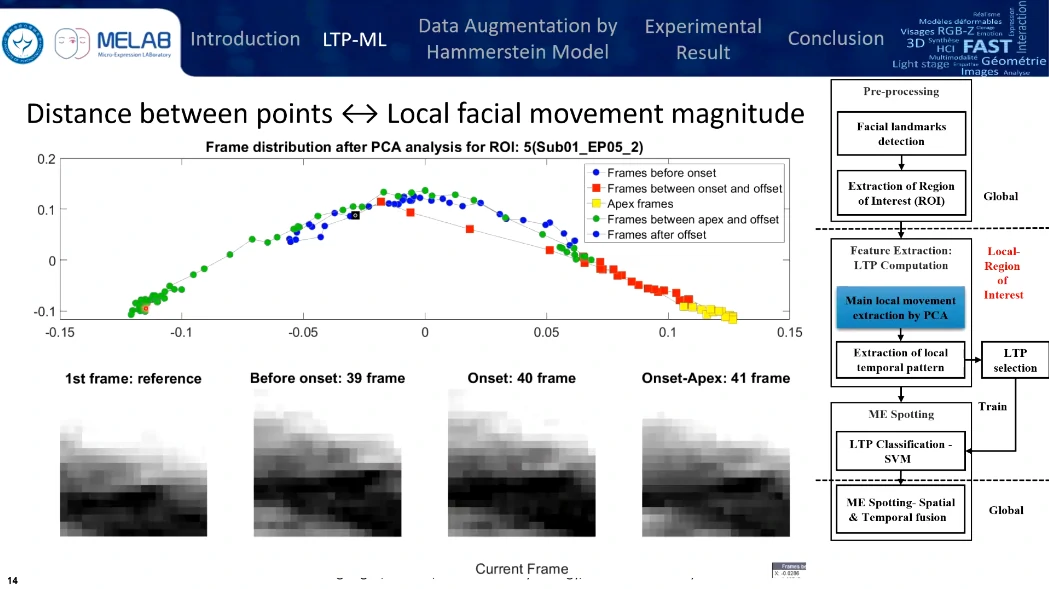
分析是基于时序的,对每一帧提取ROI,然后对这些ROI序列进行基于时序上的PCA处理,图上每个点代表一帧,点的分布代表每帧视频在时域上的分布。点与点之间的距离越长,变化得越明显;点与点之间的距离越短,变化就比较微弱。
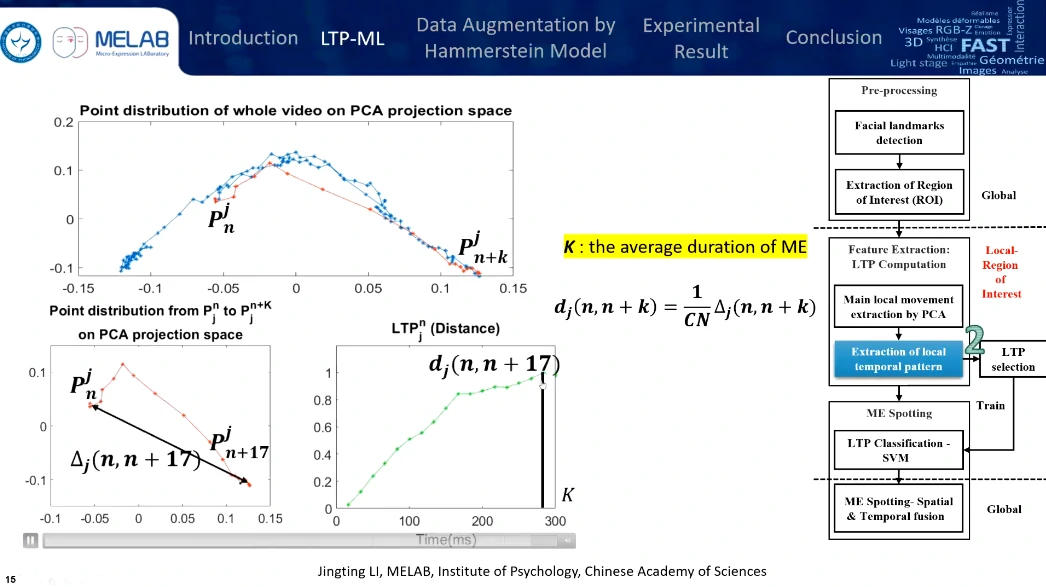
通过计算点与点之间的距离,来发现微表情的变化特征。这条曲线也就是局部时域特征
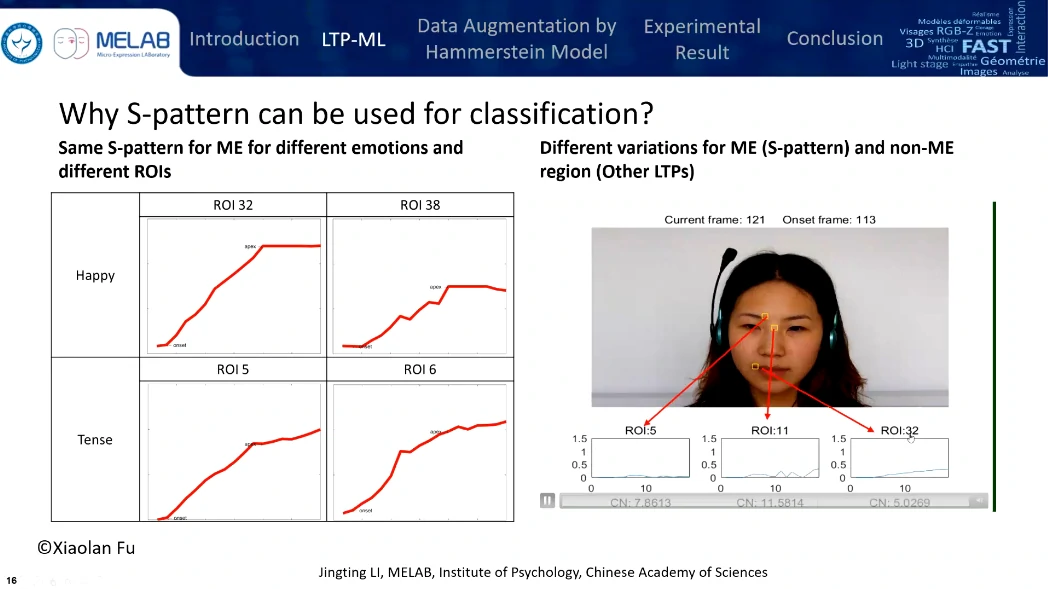
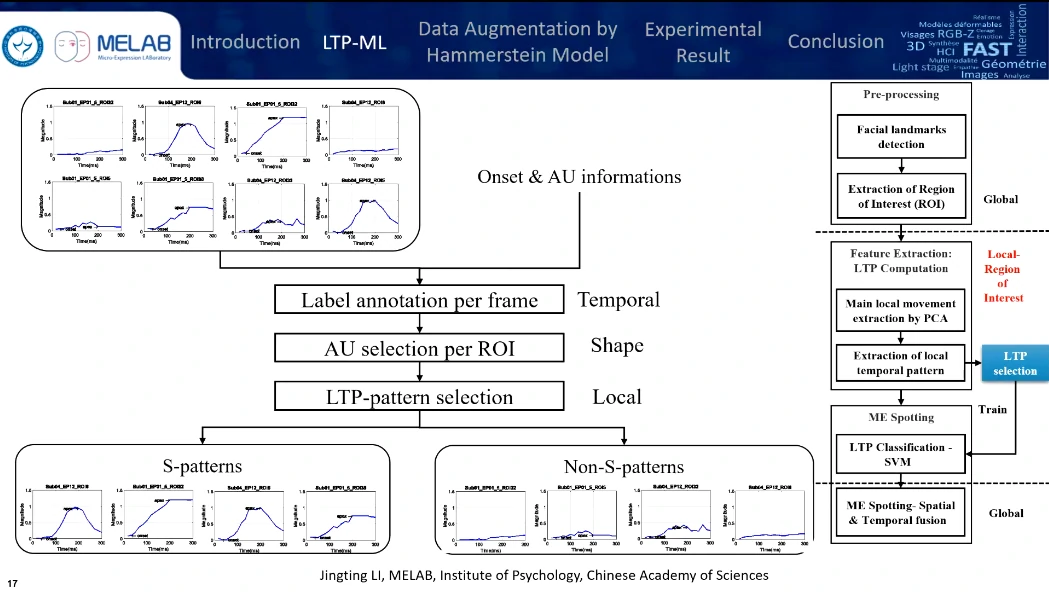
筛选一下,好的就是S-patterns,能比较好代表微表情特征,坏的就是Non-S-patterns
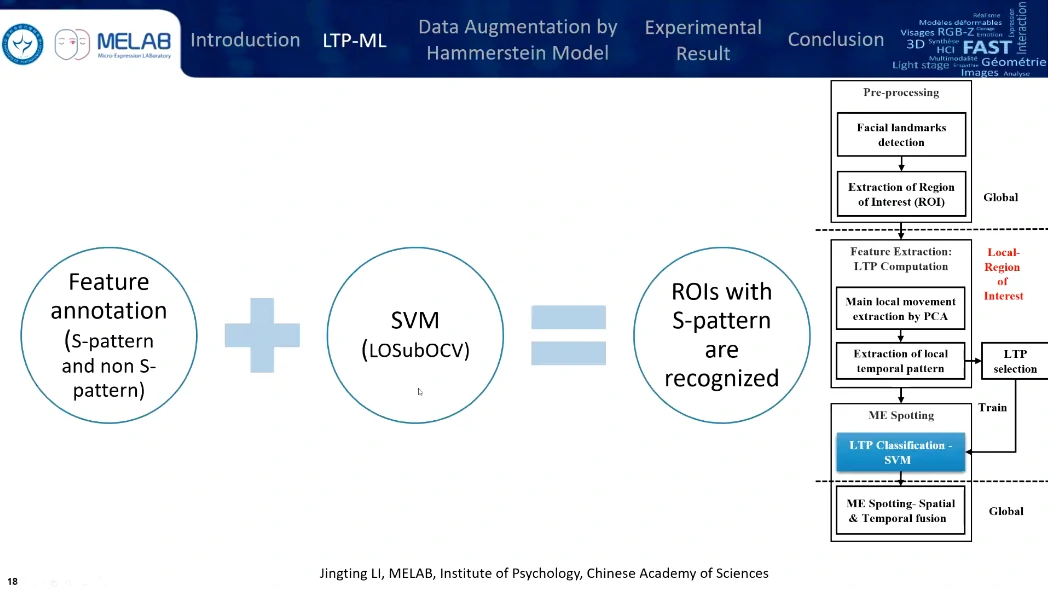
用SVM分类一下
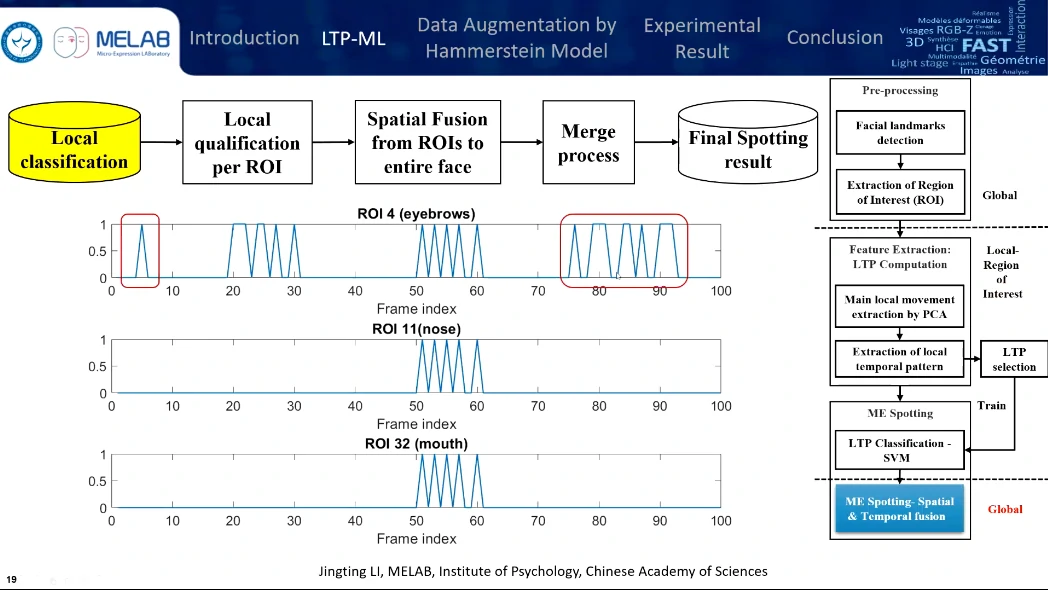
这是第二个贡献,在检测到哪些区域发生了类似微表情的活动以后,才做一个晚期的融合。将过长或过短的检测区间去除掉。
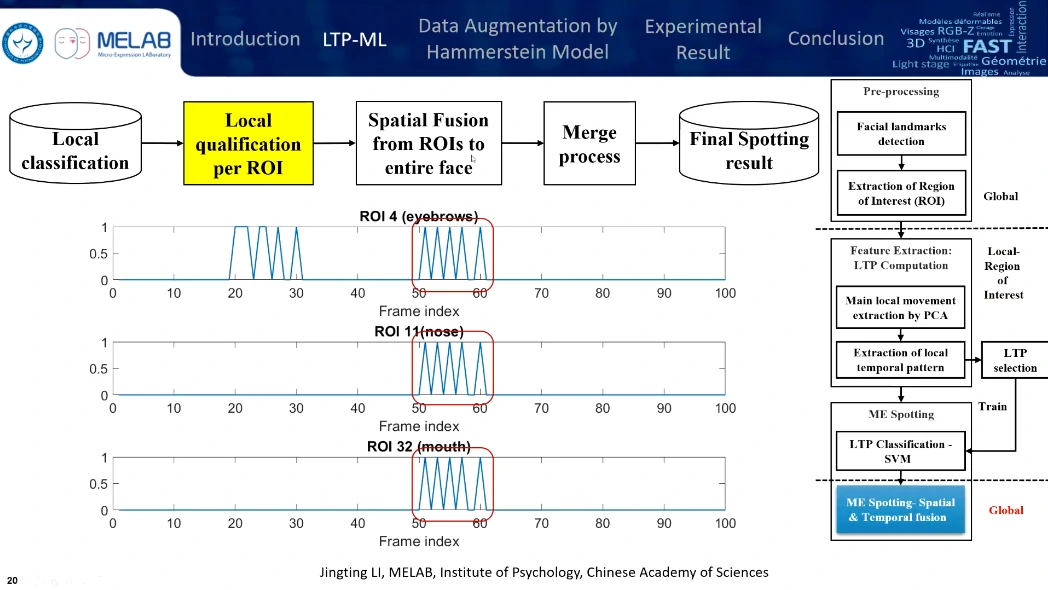
鼻子作为整体参考,可能是发生了整体的头部运动。
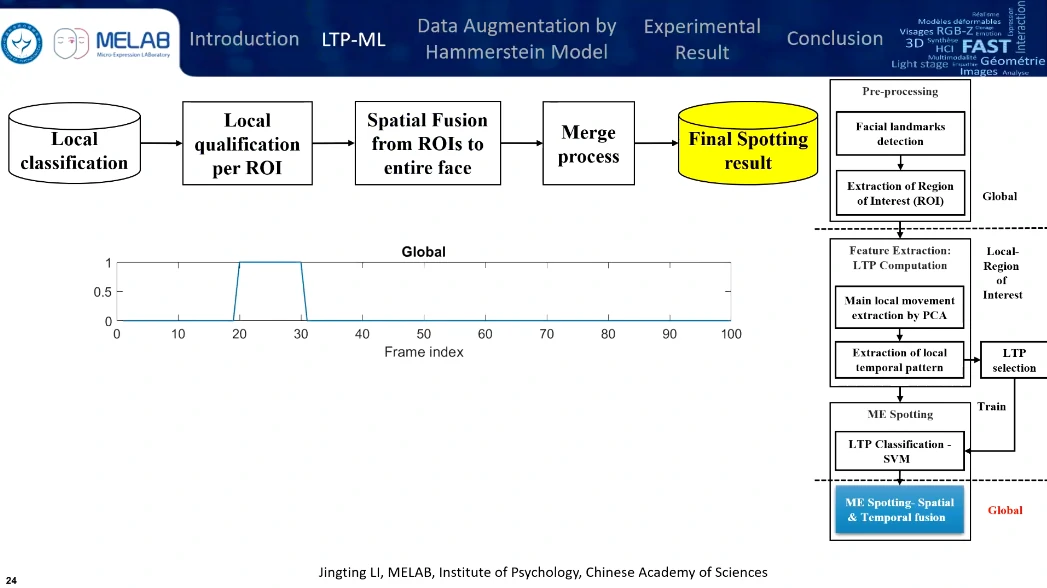

限制:使用CASME I大概只有78个LTPs被认为是S-patterns,所以需要进行数据扩增(基于Hammerstein模型)
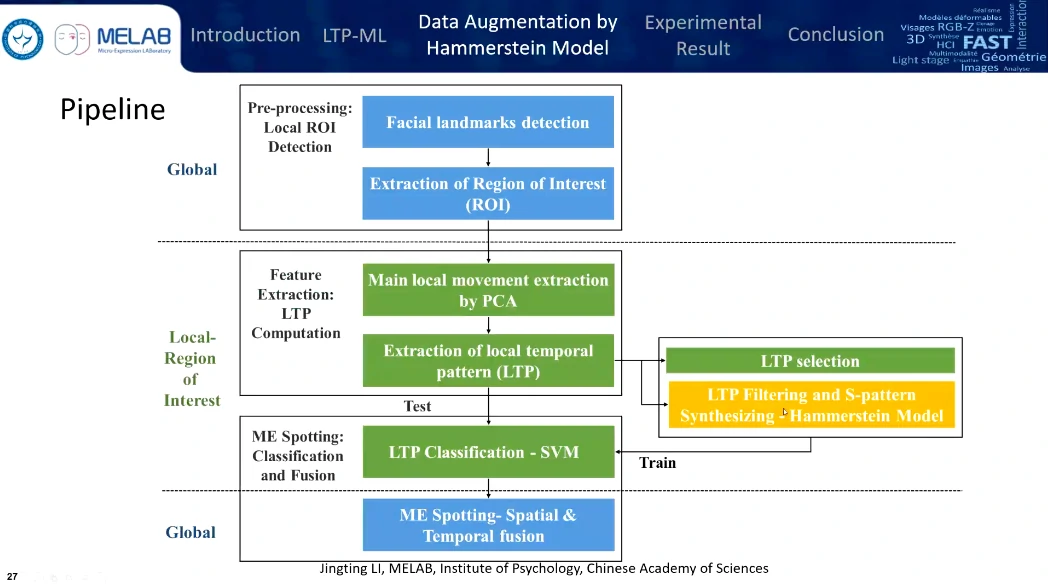
Hammerstein模型替代了LTP selection

(这玩意啥,没看懂,有点像机器学习,训练两个参数)
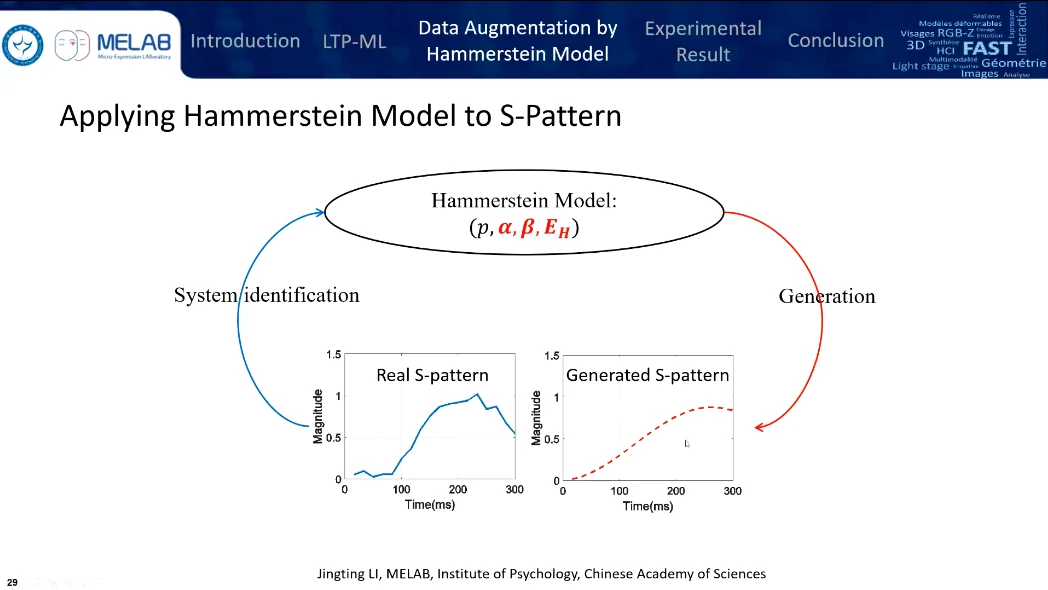
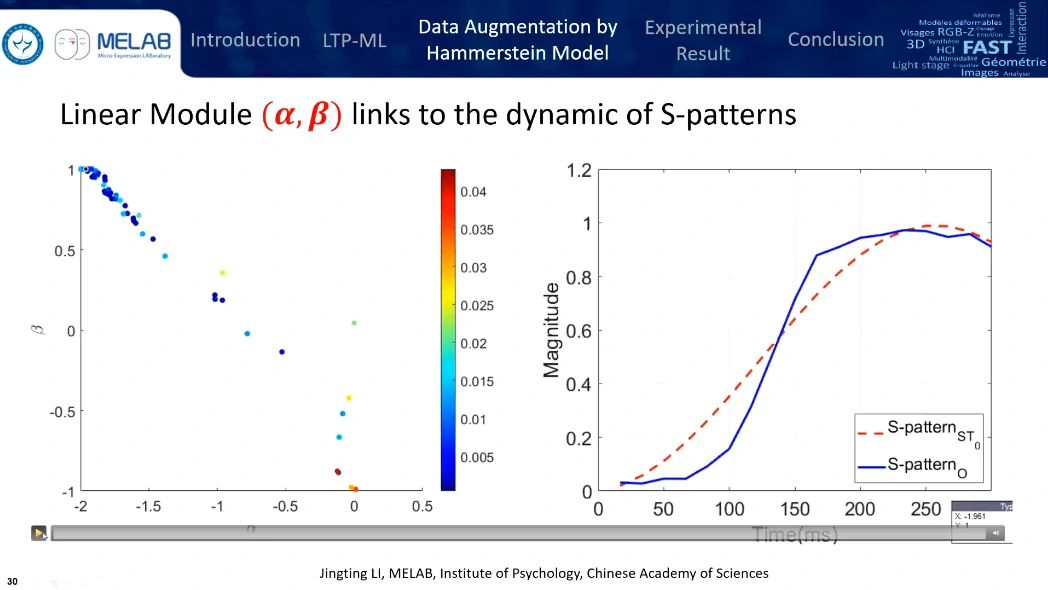

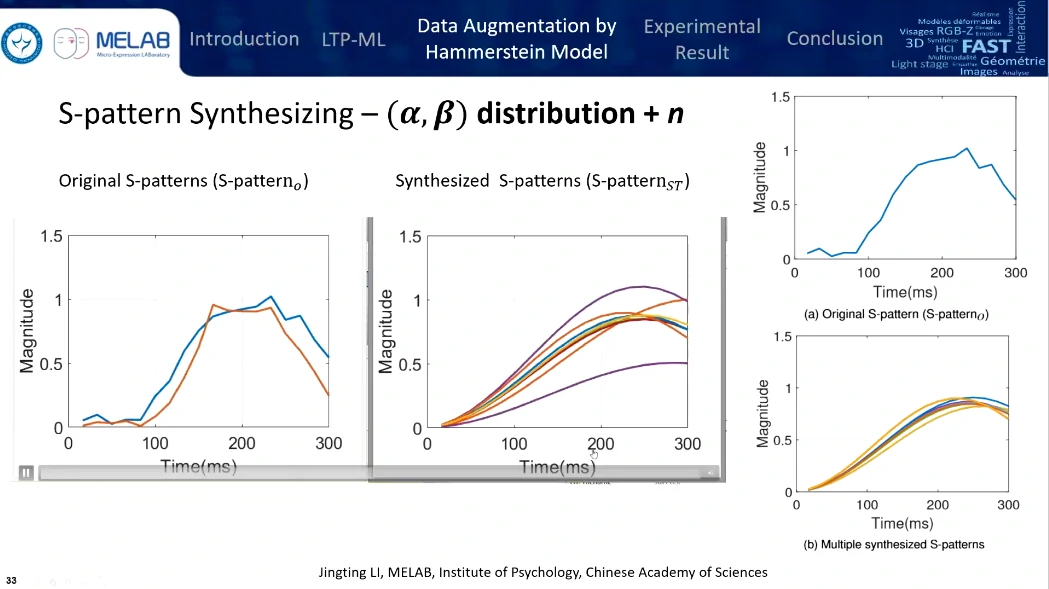
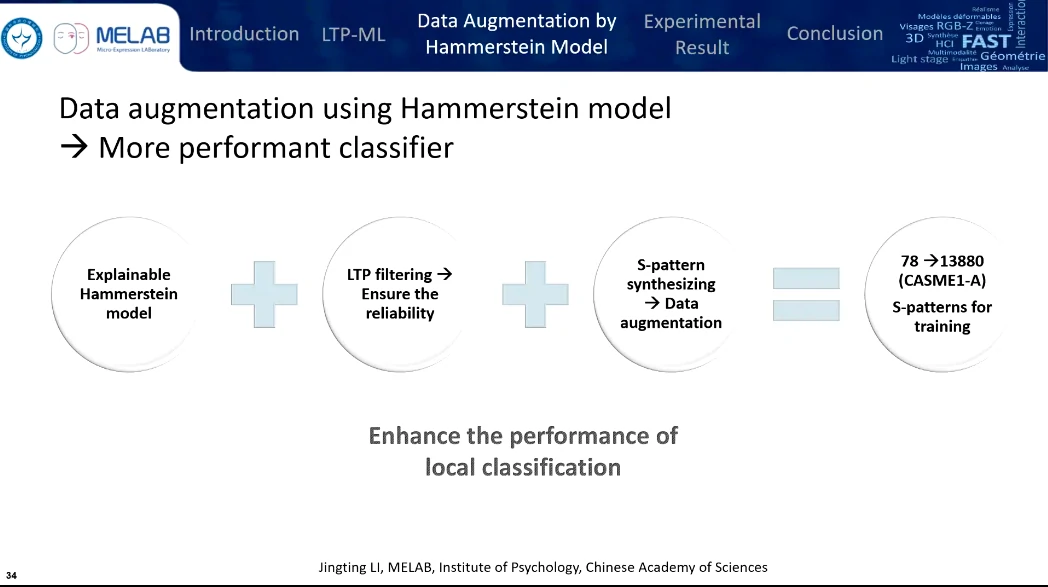
可以把 CASME I 变成 1w 多个样本

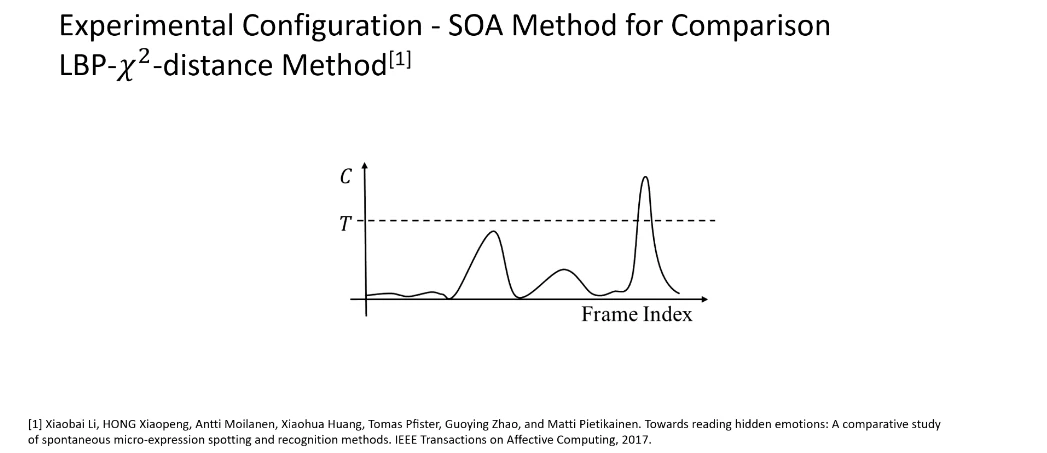
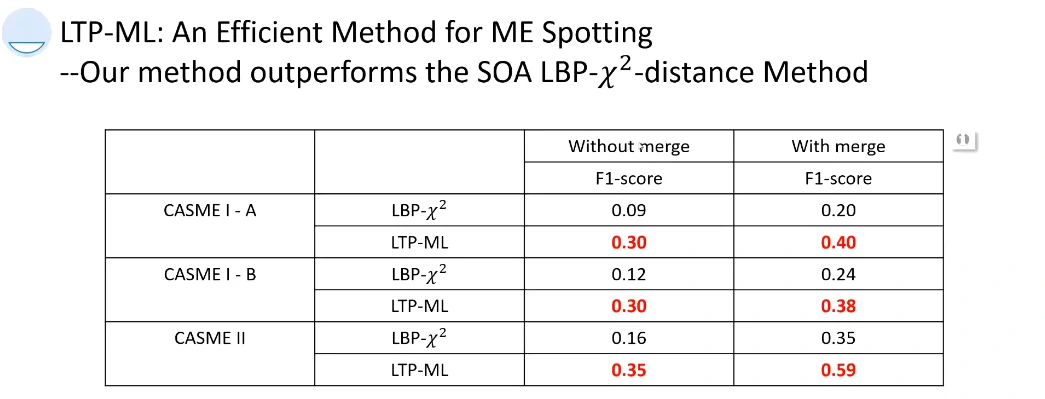
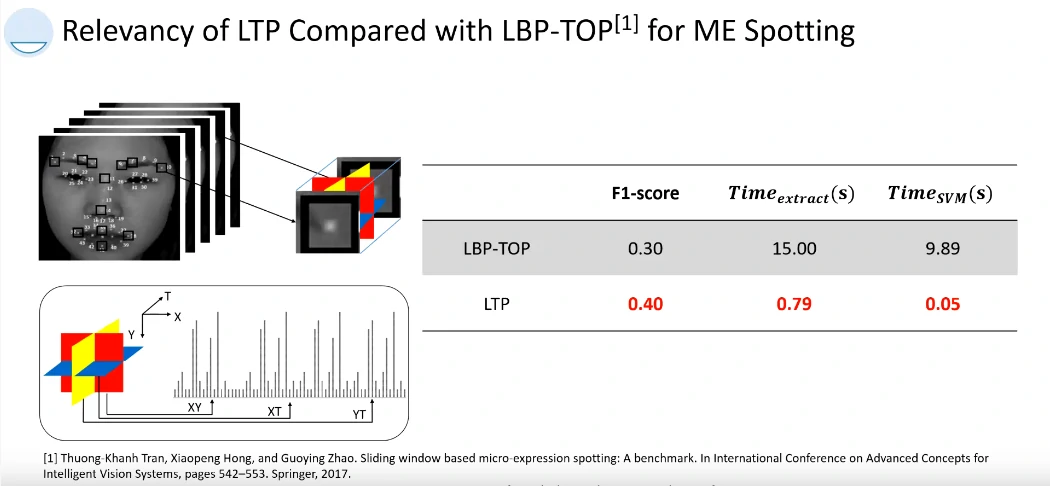
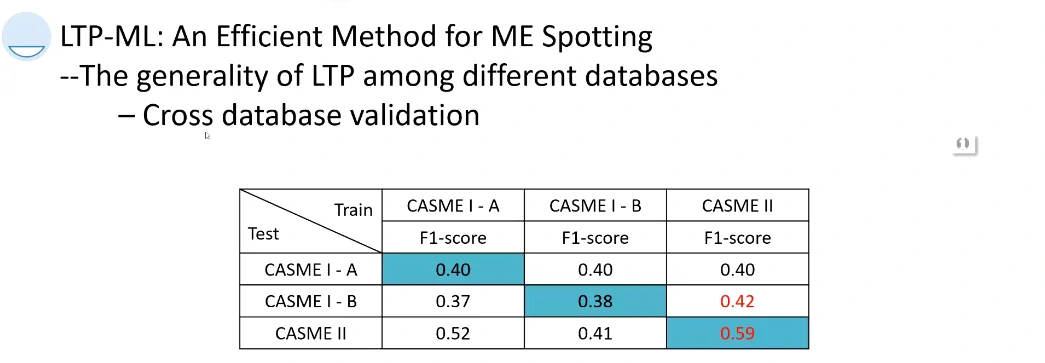
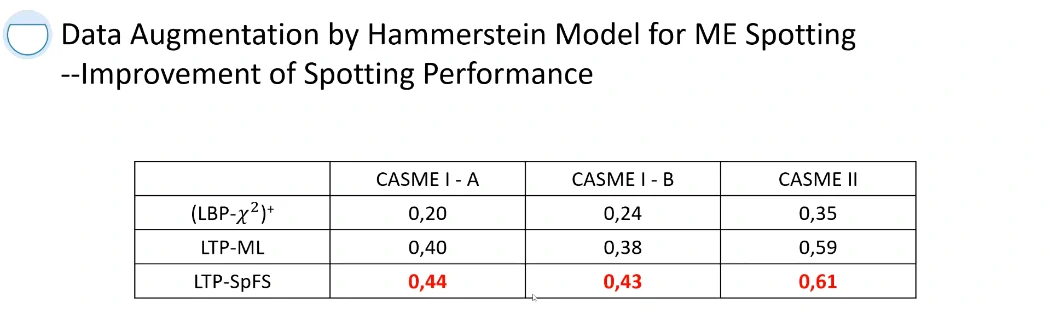
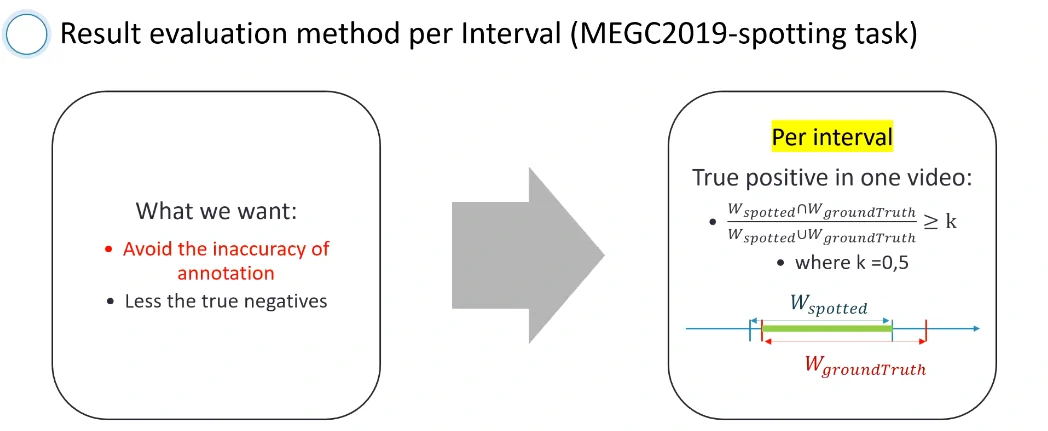
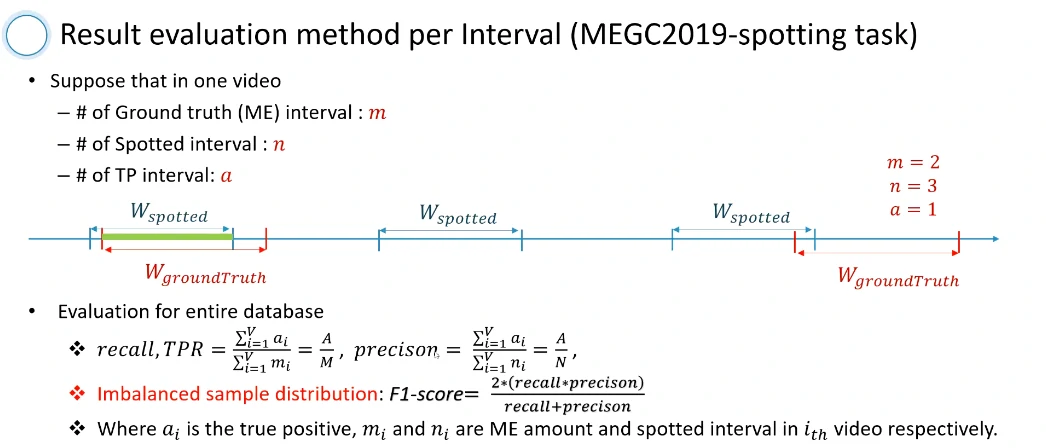
提出了一个对微表情检测的评判标准


一些对未来的展望