原文
论文地址:https://arxiv.org/pdf/2206.03398.pdf
代码地址:https://github.com/david-knigge/ccnn
Abstract
卷积神经网络(CNNs)的使用在深度学习中是广泛的,由于一系列理想的模型属性,这导致了一个高效和有效的机器学习框架。然而,性能CNN架构必须针对特定的任务进行定制,必须考虑诸如输入长度、分辨率和维度等因素。在这项工作中,我们通过我们的连续卷积神经网络(CCNN)克服了CNN架构的缺陷,CCNN是一个配有连续卷积核的单一CNN架构,可以用于对任意分辨率、维度和长度的数据的任务,而不需要结构变化。连续卷积核对每一层的长距离依赖进行建模,消除了当前CNN架构中需要的降采样层和任务依赖深度。通过将相同的CCNN应用于一系列序列(1D)和可视化数据(2D)上的任务,我们展示了我们方法的普遍性。我们的CCNN在所有考虑的任务上都表现得很有竞争力,并且经常超过目前最先进的技术。
Introduction
卷积神经网络 (CNNs)是一类广泛用于机器学习应用的深度学习模型。它们的流行源于其高性能和高效率,使其在跨序列、视觉和高维数据的多个应用程序中实现l了最好的性能。然而,CNN和一般的神经网络的一个重要限制是,它们的架构必须针对特定的应用进行定制,以处理不同的数据长度、分辨率和维度。这反过来又导致了大量特定于任务的CNN架构。
数据可以有许多不同的长度,例如,图像可以是32x32或1024x1024,音频可以是每秒16000个样本。标准的CNN的问题是,它们的卷积内核是局部的,这需要为每个长度定制一个步长和池化层来捕获整个上下文的自定义架构。此外,许多类型的数据本质上是连续的,在不同的分辨率下具有相同的语义意义,例如,图像可以在任意分辨率下捕获,并具有相同的语义内容,音频可以在16kHz或44.1kHz任意采样,但人耳听起来仍然是相同的。然而,由于卷积核的离散性,传统的CNN被限制在分辨率上,不能跨分辨率使用。当考虑具有相同CNN的不同维数数据时,这两个问题进一步加剧,例如序列(1D)、视觉(2D)和高维数据(3D, 4D),因为不同维数具有不同的特征长度和分辨率。
迈向通用CNN架构。在这项工作中,我们的目标是构建一个单一的CNN架构,可以用于任意分辨率、长度和维度的数据。由于其卷积核的离散性质,标准的CNNs需要特定任务的架构,这将核绑定到特定的数据分辨率,并使它们不适合建模全局上下文,因为构造大型离散卷积核需要大量的参数。因此,为了构建一个通用的CNN架构,开发一个分辨率不可知的卷积层是至关重要的,它能够以参数高效的方式建模远程依赖关系。
对连续参数化的需要。离散卷积核在每个核位置用Nout×Nin独立可学习权值定义。因此,大型卷积核需要大量的参数,而传统的CNN依赖于局部卷积核,结合任务相关的深度值和池化层来建模远程依赖。或者,我们可以通过使用一个小的神经网络来构建连续的卷积核,该网络将位置映射到这些位置的核值(图1a)。这种方法将卷积核的大小与构造它所需的参数数量解耦(解除耦合关系),从而允许以参数高效的方式构造任意长的核。此外,这种参数化克服了标准核的离散性,允许构造分辨率不可知的卷积核,它在任意分辨率的坐标上操作。因此,无论输入长度和分辨率如何,都可以使用相同的内核生成器网络——从而使用相同的CNN。此外,只需改变输入坐标的维度,同样的核生成器网络就可以构造序列D=1(图1b)、视觉D=2(图1c)和高维D≥3(图1d)任务的卷积核。总之,连续卷积核的特性允许构建一个单一的CNN架构,可以跨数据长度、分辨率和维度使用。
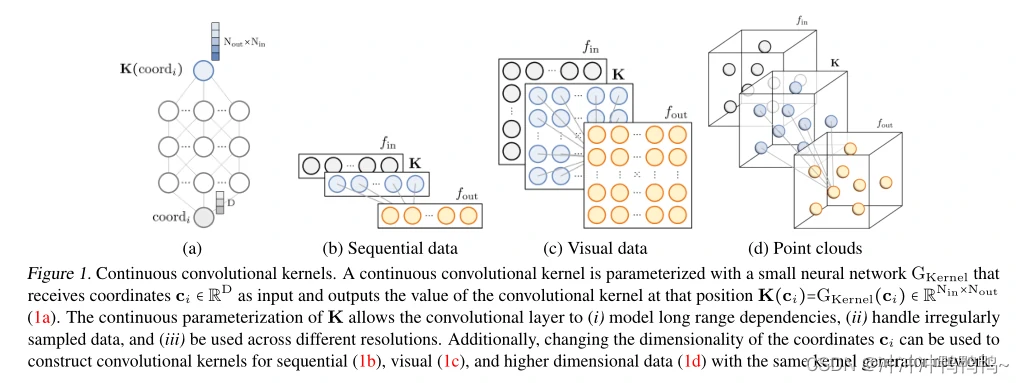
本文的贡献如下:
- 我们提出 Continuous CNN(CCNN):一种简单、通用的 CNN,可以跨数据分辨率和维度使用,而不需要结构修改。CCNN 在序列 (1D)、视觉 (2D) 任务、以及不规则采样数据和测试时间分辨率变化的任务上超过最先进的水平。
- 我们对现有的 CCNN 方法提供了几种改进,使其能够匹配当前最先进的方法,例如 S4。主要改进包括核生成器网络的初始化、卷积层修改以及 CNN 的整体结构。
Continuous Kernel Convolutions

Properties
对任意数据维度的一般操作。通过改变输入坐标c_i的维数D,可以使用核生成器网络G_Kernel构造任意维数的卷积核。因此,对于序列D=1、视觉D=2、高维D≥3的数据,可以采用相同的操作进行处理。
每一层的参数和计算高效的远程依赖建模。我们可以使用核生成器网络G_Kernel来构造与输入信号一样大的卷积核,以便对每一层的长距离依赖进行建模。G_Kernel中参数的数量与卷积核的长度无关,因此可以在固定的参数计数下构造任意大小的核。利用卷积定理可以有效地计算具有大卷积核的卷积,该定理指出,时域的卷积等于频域的点积。
无规律采样的数据。对于某些应用,输入x可能不在规律的网格上,例如医疗数据。离散卷积核不适合这种应用,因为它们的值只在某些预设位置已知,而不适合任意坐标c_i。相反,连续核在任何地方都被定义,因此可以处理无规律的数据。
不同输入分辨率的等效响应。如果输入信号x的分辨率发生变化,例如,最初观察到的音频是8KHz,现在观察到的音频是16KHz,与离散卷积核进行卷积将产生不同的响应,因为在每个分辨率下,内核将覆盖不同的输入子集。另一方面,连续内核是分辨率无关的,因此无论输入的分辨率如何,它都能够识别输入。当以不同的分辨率呈现一个输入时,例如,更高的分辨率,通过核生成器网络传递更细的坐标网格就足以构建相应分辨率的相同核。
超参数学习。连续核的一个性质是,它们可以学习参数,否则必须被视为在带有离散卷积核的CNN里的超参数。
The Continuous Convolutional Neural Network: Modelling Long Range Dependencies in ND
一种改进的连续核卷积残差块。最近的工作表明,通过改变使用的非线性和归一化层在块内的位置,残差块可以得到强有力的改善。基于这些观察结果,我们修改了FlexNet架构,使用与S4网络类似的块组成的剩余网络。CCNN架构如图2所示。
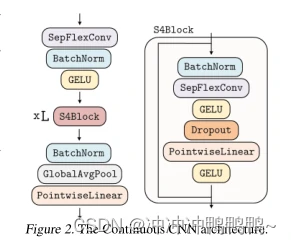
深度可分连续核卷积。可分离卷积早已被证明可以提高CNNs的参数和计算效率。最近,它们的使用在CNN中比传统卷积有了改善,这是因为空间和信道维度的分离,降低了卷积的计算和参数复杂性,允许更广泛的网络和更高的性能。
基于这些观察,我们构建了一个深度可分版本的FlexConv ,其中信道卷积由核生成器网络生成的核计算,然后从N_in到N_out进行点卷积。这一变化允许建设一个更大的CCNN,从30到110个隐藏通道而不增加网络的参数或计算复杂性。
正确初始化内核生成器网络G_Kernel。我们观察到,在之前的工作中,内核生成器网络没有为参数化卷积核而正确初始化。在初始化时,我们希望卷积层的输入和输出方差保持相等,以避免梯度爆炸和梯度消失,即Var(x)=Var(y)。因此,卷积核的方差被初始化为Var(K)=(gain^2)/(inchannels·kernelsize),gain取决于使用的非线性。然而,神经网络的初始化使输入的单位方差保留在输出。因此,当用作核生成器网络时,标准的初始化方法会导致核存在单位方差,即Var(K)=1。结果表明,使用神经网络作为核生成网络的CNN的特征表示方差逐层增长,与in_channels·kernel_size成正比。例如,我们观察到CKCNNs和FlexNets在初始化时的 logits 大约为 e^19。这是不可取的,因为它会导致不稳定的训练和需要较低的学习率。
为了解决这个问题,我们要求G_Kernel输出的方差等于(gain^2)/(inchannels·kernelsize),而不是1。为此,我们用gain/sqrt(inchannels·kernelsize)重新加权内核生成器网络的最后一层。因此,核生成器网络输出处的方差跟随传统卷积核的初始化,而CCNN的logits在初始化时呈现单位方差。
Experiments and discussion
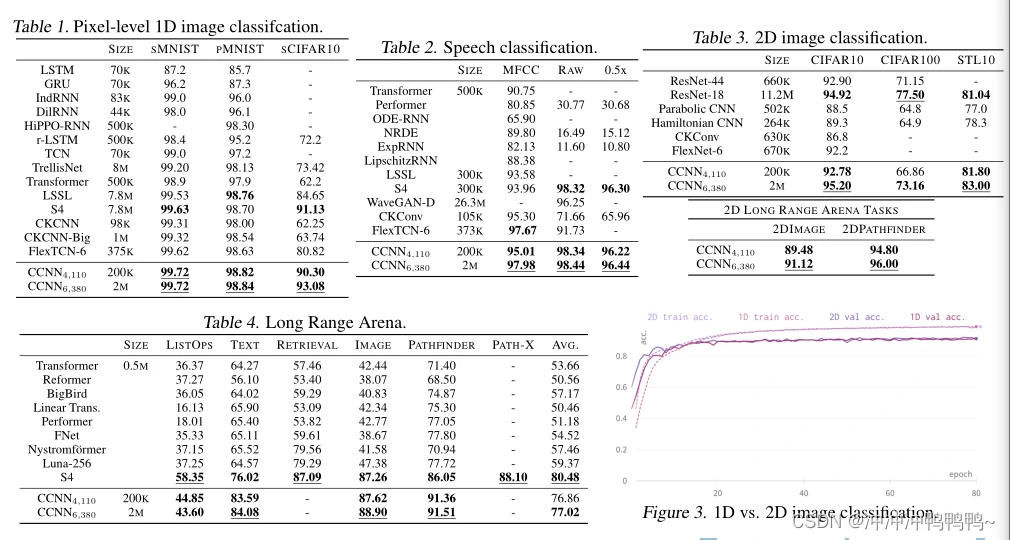
结果如表1-4所示,我们的CCNN模型在所有考虑的任务中都表现良好。事实上,ccnn在多个LRA任务以及语音命令上的1D CIFAR10像素分类和原始语音分类上设置了一个新的艺术状态,而通常比竞争方法(远)小。
对ND进行远程依赖建模的重要性。原则上,我们可以把所有的任务看作一个不考虑二维结构的顺序任务。这是由于在多维空间中定义状态空间的复杂性而实现的。然而,这是以丢弃有关数据性质的重要信息为代价的。相反,只需改变进入内核生成器网络的坐标的维数,就可以很容易地在多维空间上定义CCNN。有趣的是,我们观察到,通过考虑LRA基准中的Image和Pathfinder任务的2D性质,可以获得更好的结果(表3)。在带有2D图像的Pathfinder中,我们最大的CCNN获得了96.00的精度,比之前的技术状态高出近10%的百分点,并且在平坦图像上的CCNN表现得非常好。此外,我们观察到,在原始2D数据上训练的模型比它们的顺序对应的模型显示出更快的收敛速度(图3)。
我们注意到,由于中间池化层导致缺乏细粒度的全局上下文建模,具有小卷积核(如ResNet-18)的2D CNN无法解决Pathfinder。
【细粒度(fine-grained):粒度似乎根据项目模块划分的细致程度区分的,一个项目模块(或子模块)分得越多,每个模块(或子模块)越小,负责的工作越细,就说是细粒度。】
Conclusion
我们提出了连续卷积神经网络:一个单一的CNN架构能够对任意长度、分辨率和维度的数据进行长距离依赖建模。这一发展的关键是用连续卷积核替换标准CNN中使用的离散卷积核。凭借单一的架构,我们的CCNN在各种序列和视觉任务上的表现具有竞争力,通常优于当前的技术水平。
原文链接
https://blog.csdn.net/weixin_45922730/article/details/126212332