原文
FCN 论文链接:https://arxiv.org/pdf/1411.4038.pdf
这篇文章是关于将全卷积网络端到端(End-to-End)地训练,并将其用于语义分割。
摘要
作者提出了使用全卷积神经网络来接受任意大小的输入,并产生与之相匹配的输出,这样的一个网络在训练和推理的环节效率都很高。作者将这样的密集预测网络与之前的典型的卷积神经网络进行联系,将这些模型的优秀表征能力迁移到语义分割任务中来。进一步地,作者提出了一种用于语义分割的新架构,它可以将网络中提取的深层次的、粗略的语义信息与较浅层次的、较为精准的表征信息进行结合,提高了语义分割的准确性。此模型在多个标准数据集上都达到了 SOTA。
引言
卷积神经网络在图像分类,目标检测方面都有广泛的应用,进一步地就产生了需要为图像中的每一个像素进行分类——语义分割的需求。先前的基于卷积网络的语义分割方法都有着自己的局限性,这也是本文工作所要解决的。
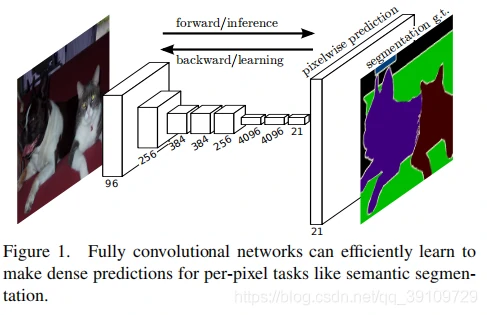
作者提出的基于 FCN 进行端到端、像素到像素的训练可以在图像语义分割任务中达到 SOTA,且不需要多余的约束机制。本文的工作是首次端到端地训练 FCN 网络用于逐像素预测。模型的训练和推理都是基于整个图像的,在网络中由于上采样层 upsampling 的存在,允许进行下采样的 pooling 操作。
在本文的工作之前,对图像逐 Patch 进行训练是主流,但是这样的方式相比于 FCN 效率大大降低。同时,本文的方法并没有使用预处理或者后处理,比如:超像素、候选区域等。本文的方法将近来主流的卷积神经网络转换为密集预测,在迁移它们的表征能力的同时进行 fine-tuning.
语义分割任务具有它固有的内在矛盾:全局的信息决定了是图像中的目标什么,但是局部的信息表示了该目标在哪里。在本文中,作者定义了一种新的跨越连接(Skip connection)来整合深层次的、粗粒度的语义信息与浅层次的、细粒度的表征信息。
相关工作
作者介绍了关于全卷积神经网络、密集预测的相关研究工作以及它们在图像语义分割中的应用,并总结出这些方法的相似之处:
- 模型较小,限制了模型能力及感受野;
- 使用patchwise进行训练
- 在模型中加入了后处理,例如:超像素投影、随机正则化、局部分类等;
- 输入移位和输出交错以实现密集输出
- 多尺度金字塔处理
- 使用了饱和的非线性函数tanh
- 模型集成
本文所提出的基于 FCN 的语义分割方法并没有使用上述的各种机制,但在文章中作者进行了 patchwise 训练的对比,同时进行了网络内部上采样的讨论。
全卷积神经网络
采用分类器进行稠密预测
典型的识别网络、包括 LeNet、AlexNet 以及更深的卷积模型都是接受固定大小的输入,得到非空间的输出。因为全连接层的存在使得这些网路丢弃了特征图的空间信息。然而,全连接层也可以看成是一种特殊的卷积层,相当于这些“卷积层”的卷积核覆盖整个特征空间。所以可以将 FC 层转化为 Conv 层使得它们可以接受任意尺寸的输入、并输出对每个像素的分类结果。这种转换如 Fig02 所示:
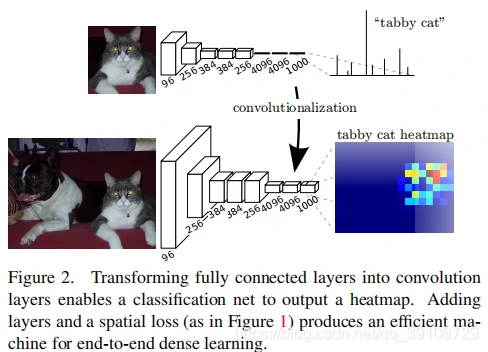
空间性的输出非常适合于进行语义分割任务,因为在语义分割中每一个输出单元的 ground truth(标签)都是已知的,前向及后向处理都变得很简单,也能够利用卷积层固有的计算效率与优化。
Shift-and-stitch 是一种滤波器稀疏
在这一节当中作者阐释了 Shitf-and-stitch 这样一种上采样(upsampling)的方式。这个方法首先出现在 Overfeat 论文中,关于 Shift-and-stitch 的详细解析,可以参考文章:Shift-and-stitch理解 在本文的模型中,作者并没有使用这种方式,这种方式等同于使用了卷积进行上采样。
上采样是一种步幅卷积的反向形式
作者提到,另一种可以用于在粗粒度的深层次输出和密集像素之间构建联系的方法是插值,比如通过双线性插值。可以通过某个像素周边的四个像素来决定当前像素的值。另外,上采样的过程同样可以看成 stride 为上采样因子倒数的“微步长卷积”。一般就是对 output 进行填充,然后再卷积。反卷积的前向后向过程与卷积类似,从某种程度上可以看成“互逆”的过程。所以它很方便地在原有的卷积网络架构中进行拓展。
逐Patch训练是一种有损失的抽样
作者提到,全图像的训练与逐 Patch 训练在某些条件下是一致的,这要求对于每一个 batch 由当损失下的所有感知域组成。然而,在一幅图像中随机随着 patch 进行 patch-wise 训练损失限制为其空间项的随机抽样子集,这样做是有损失的。作者在后面做了逐 patch 训练,与 FCN 方式相比发现并没有促进收敛或者性能上的提升,这说明这说明全图像训练是有效且高效的。
分割架构
作者将应用于大规模图像分类的卷积模型进行迁移,对它们进行了密集预测以及上采样方式的优化,同时基于之前的模型进行 fine-tuning。随后,作者提出了一种新的跨层次连接的架构。在 PASCAL VOC2011 数据集上训练了一个多项式回归模型用以做对比,同时以图像语义分割的标准指标 mIoU 进行评价。
从分类器到密集FCN
作者首先选用了在大规模图像分类上被证明有较好性能的 AlexNet、VGG-16 以及 GoogleNet 作为改进目标,在 GoogleNet 中仅使用最后一个 loss layer(去除辅助分类器),同时抛弃了最后的平均池化层以提高性能。对于所有的 CNN 模型,将最后的 FC 层都转换为 Conv 层。同时对所有的上采样输出进行通道数为 21(classess + background)的 1 x 1 卷积进行密集预测。表 1 是三个改进模型在 PASCAL VOC2011 数据集上的表现:
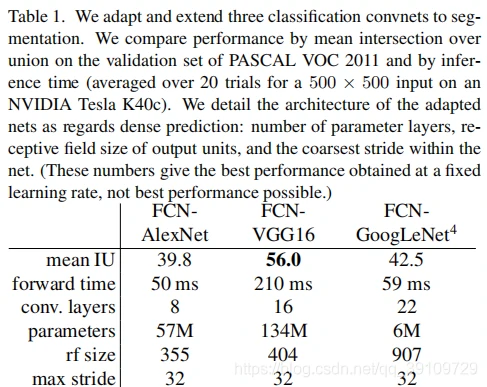
可以看到在平均交并比上,VGG-16 为 Base 的模型效果更好。
结合分类与位置信息
定义一种新的全卷积网络用作语义分割任务,通过调整用于分类的卷积分类器可以在语义分割任务上达到较好的性能。本文基于 VGG-16 模型提出了基础的 FCN-32s、跨层信息融合的 FCN-16s 以及 FCN-8s,模型原理如图 3 所示:
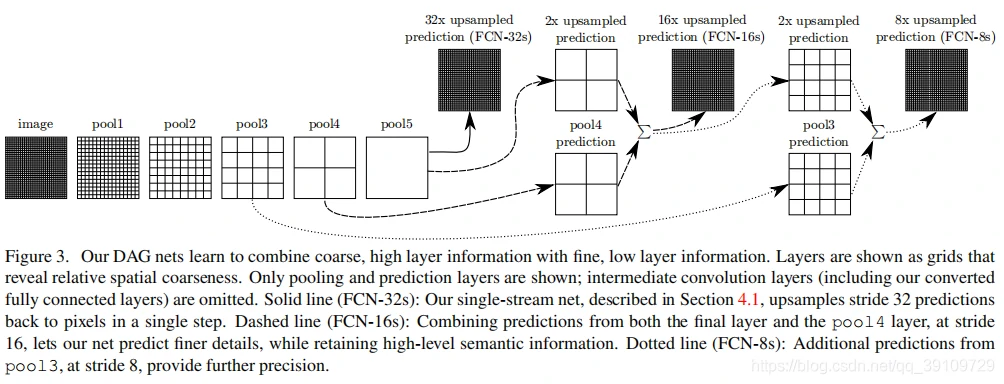
由图 3 可以看出,FCN-32s 模型就是在 VGG16 模型的 5 次下采样之后得到的得分输出直接进行 32x 上采样,恢复到原图尺寸。而 FCN-16s 则是将 pool5 的得分输出进行 2x 上采样,恢复到原始图像的 1/16,然后再与 pool4 的得分输出直接相加。(注:这里的得分输出是指经过 1 x 1 卷积进行通道拓展,n_channels = 21)。最后,FCN-8s 是在 FCN-16s 的基础上将输出 2x 上采样,再直接加上 pool3 的得分输出得到 1/8 尺度的 output,最后再进行 8x 采样恢复尺寸。本文提出的基于 VGG-16 模型的 FCN-32s、FCN-16s,以及 FCN-8 在语义分割中的实际效果如图 4 所示:

实验框架
Optimizeation 在优化过程中,作者对对所有的 score-layer(即进行 1 x 1 卷积的层)进行 0 初始化,作者通过实验发现,随机初始化对于模型性能和训练没有益处。同时,本文提出的 FCN 系列的模型中都保留了 VGG-16 中的 Dropout 层。
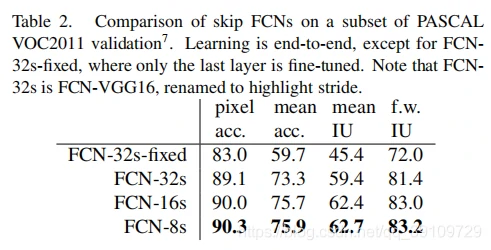
Fine-tuning 训练时,每个模型都进行了端到端的 fine-tuning,如果只是在原 VGG-16 分类器的层上进行 fine-tuning 只能达到最好性能的 70%,各模型的实验结果如表 2 所示:
Patch Sampling 同时,作者还进行了 patch-wise training 的对比试验。之前的文献表明,patch-wise 的训练中由于进行随机采样,数据的方差较大,这有利于加速模型收敛。(???)在研究这种 trade-off 的过程中,作者通过空间上的损失采样来进行,同时为每种训练方式(full image training VS patch-wise training)独立地选定一个概率 p,以这个概率保留掉最后一层的神经元,同时为每个 batch 中的图像数量乘上一个因子 1/p(0 < p < 1)以扩大 batch_size。对比实验结果如图 5 所示:
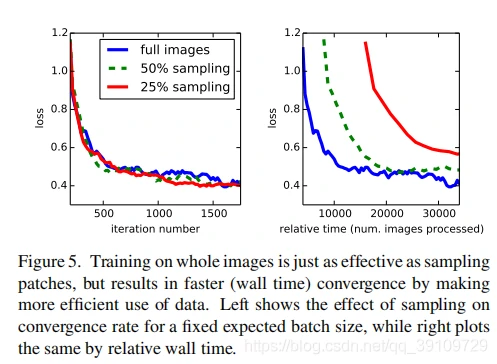
同时进行了全图像训练、50% 采样训练、25% 采样训练三种方式,通过实验结果可以看出,patch-wise 的训练方式在促进模型收敛上并没有显著的优势(左图)。同时,右图显示了模型收敛的相对时间,可以发现由于 patch-wise 方式在每个 batch 中需要训练的图像数量更多,速度更慢。所以本文并没有采用这种训练方式。
Class Balancing 在面对类别不平衡的问题时,全卷积网络的训练可以对最后的损失进行类别的加权。
Dense Prediction 最后一个反卷积层的卷积核的参数被固定为双线性插值,但是中间各层的反卷积被初始化为双线性上采样,在训练的过程中不断学习。
Augmentation 通过镜像“mirror”和抖动“jittering”(在最粗略的预测尺度上,向每个方向拓展 32 个 pixel)但这并没有实际的性能提升
结果
评价指标:

- pixel accuracy 指的是像素准确性,n_ij 表示原本属于类别 i 的像素被分类到类别 j 中的像素个数,t_i = ∑_j n_ij 表示类别 i 中所有的像素个数。pixel accuracy 是把所有正确预测类别的像素数量求和再除以所有的像素数量。
- mean accuracy 是指平均准确率,对每个类别的 accuracy 取平均。
- mean IU 平均交并比,将每个类别的正确预测像素数量 n_ii 除以本类别像素数量 t_i 除以本类别像素数量 i
的像素的并集 (t_i + ∑_j n_ij - n_ii),再除以类别 n_cl。 - 按类别频率加权的IU
下面的表 3 显示了 FCN-8s 模型与之前的 SOTA 模型 SDS 以及 R-CNN 在 PASCAL VOC 2011、2012 数据集上的性能比较:

可以看到本文提出的 FCN-8s 模型在常用的 mean IU 指标上有着较大的提升,同时也大幅度降低了模型的推理时间。图 6 显示了 FCN-8s 模型与 SDS 语义分割的效果:

可以发现 FCN-8s 在精细的结构修复、区分相近且相邻的目标的能力以及对应于目标遮挡的鲁棒性上都更胜一筹。
结论
将用于图像分类的卷积模型扩展到语义分割,并用多分辨率层组合改进体系结构,极大地提高了架构的能力,同时简化和加快了学习和推理。
FCN模型的不足
- 对于目标的边缘分割仍旧很平滑,对细节的处理不敏感。
- 采用基于 CNN 的密集预测,在给每个像素点分类时没有考虑到像素点之间的关系,即没有利用好这种上下文的关系。
参考资料
https://zhuanlan.zhihu.com/p/56035377
https://blog.csdn.net/qq_39109729/article/details/109557050
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
https://github.com/wkentaro/pytorch-fcn/tree/master/torchfcn/models