本文将分 2 期进行连载,共介绍 16 个在图像生成任务上曾取得 SOTA 的经典模型。
- 第 1 期:ProGAN、StyleGAN、StyleGAN2、StyleGAN3、VDVAE、NCP-VAE、StyleGAN-xl、Diffusion GAN
- 第 2 期:WGAN、SAGAN、BIG-GAN、CSGAN、LOGAN、UNet-GAN、IC-GAN、ADC-GAN
现在正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| ProGAN | https://sota.jiqizhixin.com/project/0190e1fa-5643-4043-8b75-9b863a6d20db | Progressive Growing of GANs for Improved Quality, Stability, and Variation |
| StyleGAN | https://sota.jiqizhixin.com/project/e072cfc0-26c3-40e7-a979-60df61170c7a | A Style-Based Generator Architecture for Generative Adversarial Networks |
| StyleGAN2 | https://sota.jiqizhixin.com/project/a07f5a80-bf97-4a33-a2a8-4ff938b1b82f | Analyzing and Improving the Image Quality of StyleGAN |
| StyleGAN3 | https://sota.jiqizhixin.com/project/6f7d3d51-762a-4d23-a572-3ea79ab49b4f | Alias-Free Generative Adversarial Networks |
| VDVAE | https://sota.jiqizhixin.com/project/0ed2229c-722b-47fb-b6aa-d22dedf87f1b | Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images |
| NCP-VAE | https://sota.jiqizhixin.com/project/74d15cbe-7f75-434a-a1cf-a69ae303eec6 | A Contrastive Learning Approach for Training Variational Autoencoder Priors |
| StyleGAN-xl | https://sota.jiqizhixin.com/project/01d16b00-e79f-4527-a7e3-08354b5d9b47 | StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets |
| Diffusion GAN | https://sota.jiqizhixin.com/project/9aa9b499-adec-46a3-aef9-4cd73e1c13ec | Diffusion-GAN: Training GANs with Diffusion |
生成模型是一种训练模型进行无监督学习的模型,即,给模型一组数据,希望从数据中学习到信息后的模型能够生成一组和训练集尽可能相近的数据。图像生成(Image generation,IG)则是指从现有数据集生成新的图像的任务。图像生成模型包括无条件生成和条件性生成两类,其中,无条件生成是指从数据集中无条件地生成样本,即p(y);条件性图像生成是指根据标签有条件地从数据集中生成样本,即p(y|x)。
图像生成也是深度学习模型应用比较广泛、研究程度比较深的一个主题,大量的图像库也为SOTA模型的训练和公布奠定了良好的基础。在几个著名的图像生成库中,例如CIFAR-10、ImageNet64、ImageNet32、STL-10、CelebA 256、CelebA64等等,目前公布出的最好的无条件生成模型有StyleGAN-XL、Diffusion ProjectedGAN;在ImageNet128、TinyImageNet、CIFAR10、CIFAR100等库中,效果最好的条件性生成模型则是LOGAN、ADC-GAN、StyleGAN2等。
我们在这篇文章中介绍图像生成必备的TOP模型,从无条件生成模型和条件性生成模型两个类别分别介绍。图像生成模型的发展非常快,所以与其它几个topic不同,图像生成中必备的TOP模型介绍主要以近两年的SOTA模型为主。
无条件生成模型
ProGAN
生成性对抗网络(GAN)是机器学习中一个相对较新的概念,于2014年首次引入。GAN的目标是合成与真实图像无法区分的人工样本,如图像。GAN的基本组成部分是两个神经网络:一个新样本的生成器(G),一个从训练数据和生成器输出中提取样本并预测它们是“真”还是“假”的鉴别器(D)。生成器的输入是一个随机向量(噪声),因此其初始输出也是噪声。随着训练的进行,当它收到鉴别器的反馈时,会学习合成更“真实”的图像。鉴别器还通过将生成的样本与真实样本进行比较,随着训练的进行不断改进,使得生成器更难欺骗它。
ProGAN是NVIDIA投稿ICLR 2018的一篇文章,ProGAN关键创新在于渐进式训练,它在经典GAN的基础上首先通过学习在低分辨率图像中也可以显示的基本特征,来创建图像的基本部分,并且随着分辨率的提高和时间的推移,学习越来越多的细节。低分辨率图像的训练不仅简单、快速,而且有助于更高级别的训练,因此,整体的训练也就更快。ProGAN被认为是后来大热的StyleGAN的前身。
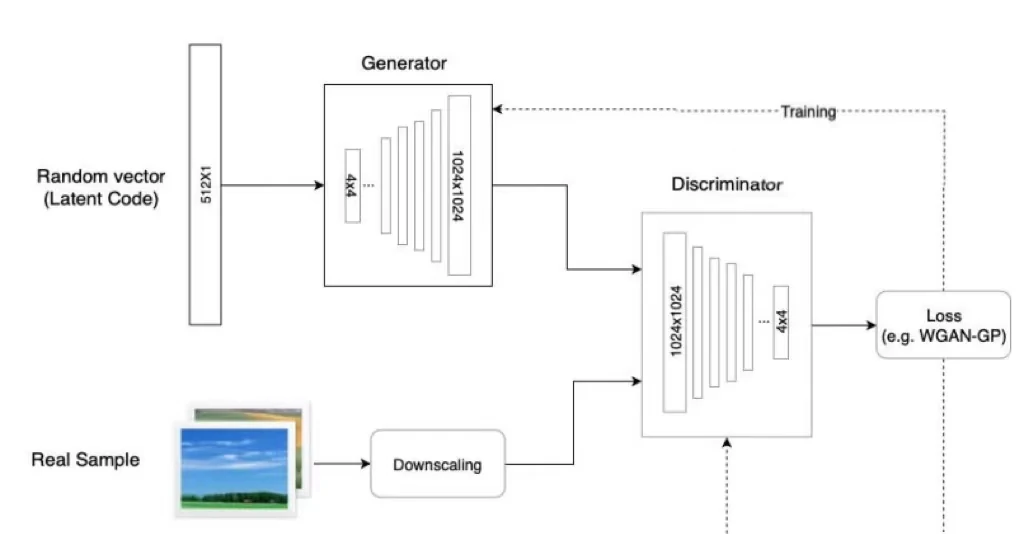
图1 ProGAN架构
ProGAN的训练部分,从低分辨率的图像开始,通过向网络添加层来逐步提高分辨率,如图2所示。这种递增的性质允许训练首先发现图像分布的大规模结构,然后将注意力转移到越来越精细的细节上,而不是同时学习所有的尺度。使用生成器和鉴别器网络,它们是彼此的镜像,并且总是同步增长。在整个训练过程中,两个网络中的所有现有层都是可训练的。当新的层被添加到网络中时,平稳地将它们淡化,如图3所示。这就避免了对已经训练好的小分辨率层的突然冲击。
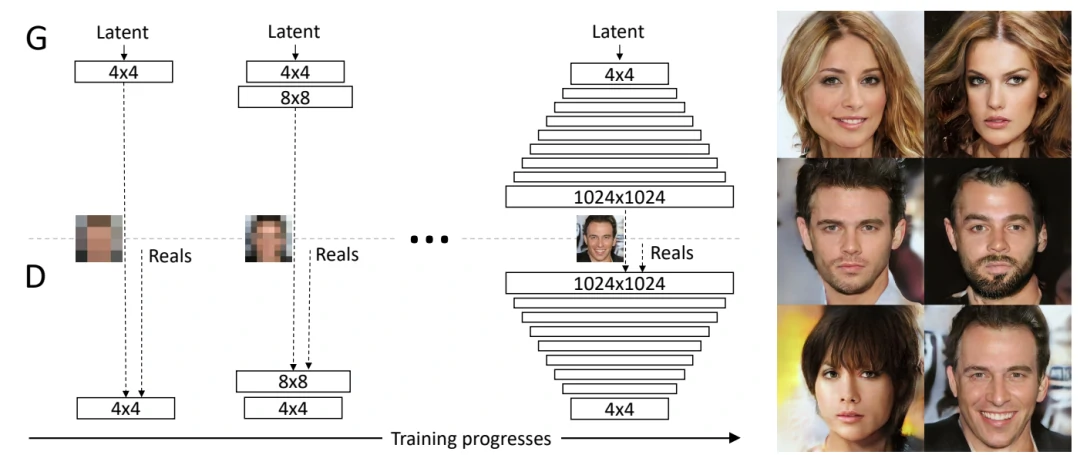
图2 训练开始时,生成器(G)和鉴别器(D)的空间分辨率都很低,只有4×4像素。随着训练的进行,逐步增加G和D的层数,从而提高生成图像的空间分辨率
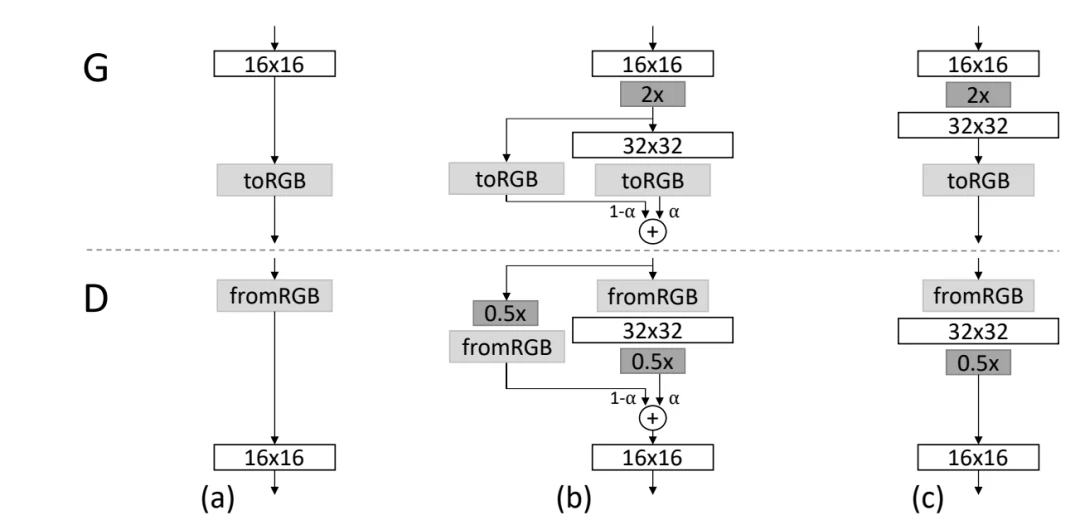
图3 当生成器(G)和鉴别器(D)的分辨率翻倍时,顺利地淡化新层。这个例子说明了从16×16图像(a)到32×32图像(c)的过渡。在过渡期间(b),把在更高的分辨率上操作的层当作一个残差块,其权重α从0到1线性增加
GAN还有一个问题是只捕捉训练数据中发现的变化的一个子集,mini-batch就是为了解决这个问题提出的,它是通过在鉴别器的末尾添加一个minibatch层来实现的,该层学习一个大的张量,将输入激活投射到一个统计数组。mini-batch中的每个样本都会产生一组单独的统计数据,并将其串联到该层的输出中,这样鉴别器就可以在内部使用这些统计数据。
ProGAN的简化方案既没有可学习的参数,也没有新的超参数,而是引入了特征的标准差作为衡量标准。首先计算每个特征在每个空间位置上的标准偏差。然后,在所有特征和空间位置上平均这些估计值,得到一个单一的值。复制这个值并将其连接到所有的空间位置和minibatch上,产生一个额外的(恒定)特征图。这一层可以插入鉴别器的任何地方,将其在最后插入效果最好。这个特征图中包含了不同样本之间的差异性信息,送入鉴别器后,经过训练,生成样本的差异性也会与训练样本的相似。
此外,ProGAN还对生成器和鉴别器进行了归一化处理,归一化主要是用来控制信号幅度,从而减少G与D之间的不正常竞争,沿channel维度对每个像素的特征长度归一化。minibatch statistic layer沿着batch维度求标准差,而它沿着channel维度求norm。
当前 SOTA!平台收录ProGAN共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| ProGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/0190e1fa-5643-4043-8b75-9b863a6d20db |
StyleGAN
StyleGAN是一种开创性的工作,不仅可以生成高质量和逼真的图像,还可以对生成的图像进行更好的控制和理解,从而比以前更容易生成可信的假图像。StyleGAN是ProGAN图像生成器的升级版本,重点关注生成器网络(G)。
StyleGAN的重点就是“Style”,在提出StyleGAN的论文中具体是指人脸的风格,包括人脸表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等。进一步对这些Style进行细分为:1)粗-分辨率高达8 * 8-影响姿势、一般发型、人脸形状等;2)中等-分辨率16 * 16到32 * 32-影响更精细的人脸特征、发型、睁眼/闭眼等;3)精细-分辨率为64 * 64到1024 * 1024-影响配色方案(眼睛、头发和皮肤)和微观特征。
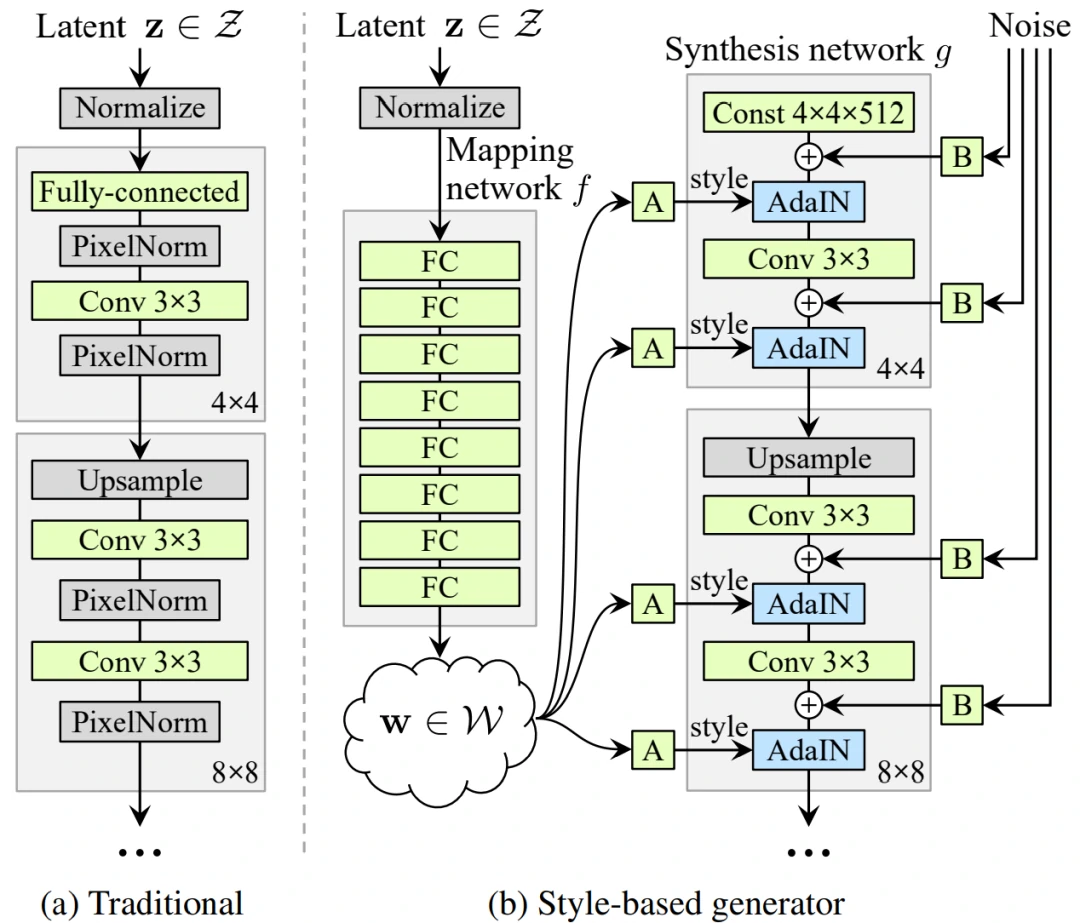
图4 StyleGAN结构
StyleGAN 的网络结构包含两个部分,第一个是Mapping network,即图 4(b)的左部分,由潜在变量 z 生成中间潜在变量 w的过程,w用来控制生成图像的style。第二个是Synthesis network,它的作用是生成图像,创新之处在于给每一层子网络都输入A 和 B,A 是由 w 转换得到的仿射变换,用于控制生成图像的style,B 是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整”style”。整个网络结构还是保持了 ProGAN 的结构。经典GAN的随机变量或者潜在变量 z是通过输入层,即前馈网络的第一层提供给生成器的(图4a)。而StyleGAN完全省略了输入层,直接从一个学习的常数开始(图4b,右),即将 z 单独用 mapping网络变换成w,再将w输入给 Synthesis network的每一层。
Mapping network 要做的事就是对潜在空间(latent space)进行解耦,Mapping network由8个全连接层组成,其输出与输入层的大小相同。通过一系列仿射变换,由 z 得到 w,这个 w 转换成风格y=(ys,yb) ,结合 AdaIN (adaptive instance normalization) 风格变换方法:
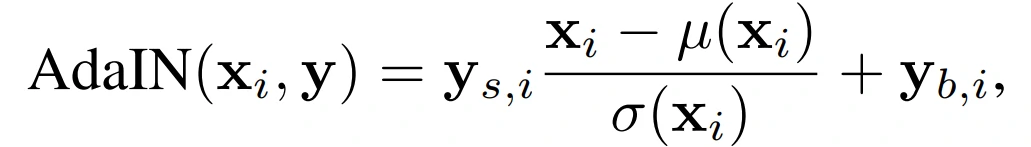
使用输入向量控制视觉特征的能力是有限的,因为它必须遵循训练数据的概率密度。例如,如果黑发人的图像在数据集中更常见,则更多输入值将映射到该特征。因此,该模型无法将部分输入(向量中的元素)映射到特征,这种现象称为特征纠缠。然而,Mapping network通过使用另一个神经网络,可以生成一个不必遵循训练数据分布的向量,并且可以减少特征之间的相关性。
具体到AdaIN(也称为Style模块),该模块被添加到生成网络的每个分辨率级别,并定义该级别中特征的视觉表达:首先对卷积层输出的每个通道进行正则归一化,以确保缩放和移位达到预期效果;然后,使用另一个全连接层转换为每个通道的比例和偏差;最后,将尺度变化和偏置移动作用于卷积输出的每个通道,从而定义卷积中每个滤波器的重要性。利用AdaIN实现了将信息从潜在变量转化为一种视觉表现。在StyleGAN中,可以省略初始随机噪声输入,用常量值替换。这种操作减少了特征纠缠,因为网络不再依赖于互相纠缠的输入向量。AdaIN 层的含义同BN层类似,其目的是对网络中间层的输出结果进行scale和shift,以增加网络的学习效果,避免梯度消失。相对于BN是学习当前batch数据的mean和variance,Instance Norm则是采用了单张图片。AdaIN则是使用learnable的scale和shift参数去对齐特征图中的不同位置。
具体到人脸图像生成任务,人脸有很多的特征都很小且可以看作是随机的,例如雀斑、头发的精确位置、皱纹等,这些可以使图像更逼真,并增加输出的多样性。将这些小特征插入GAN图像的常用方法是向输入向量添加随机噪声。然而,在许多情况下,由于上述特征纠缠现象,很难控制噪声效果,这会导致图像的其他特征受到影响。StyleGAN中的噪声以与AdaIN机制类似的方式添加,即在AdaIN模块之前向每个通道添加控制缩放的噪声,并稍微改变其操作分辨率级别特征的视觉表达。
为了进一步定位Style,引入混合正则化的处理方式,即在训练过程中,一定比例的图像是使用两个随机潜在变量而不是一个潜在变量生成的。在生成这样的图像时,只需在生成网络中随机选择一个点,从一个潜在变量切换到另一个潜在变量即Style mix。具体的,通过mapping network运行两个潜在变量z1、z2,并让相应的w1、w2控制style,使w1在crossover point之前适用,w2在crossover point之后适用。这种正则化技术可以防止网络假设相邻的风格是相关的。
最后,针对特征解纠缠(disentanglement)问题,对于disentanglement各种定义的共同的目标是由线性子空间组成的隐藏空间,每个子空间控制一个变化因素。然而,Z中每个因素组合的采样概率需要与训练数据中的相应密度相匹配。如图5所示,因素无法与典型的数据集和输入的潜在分布完全分离。
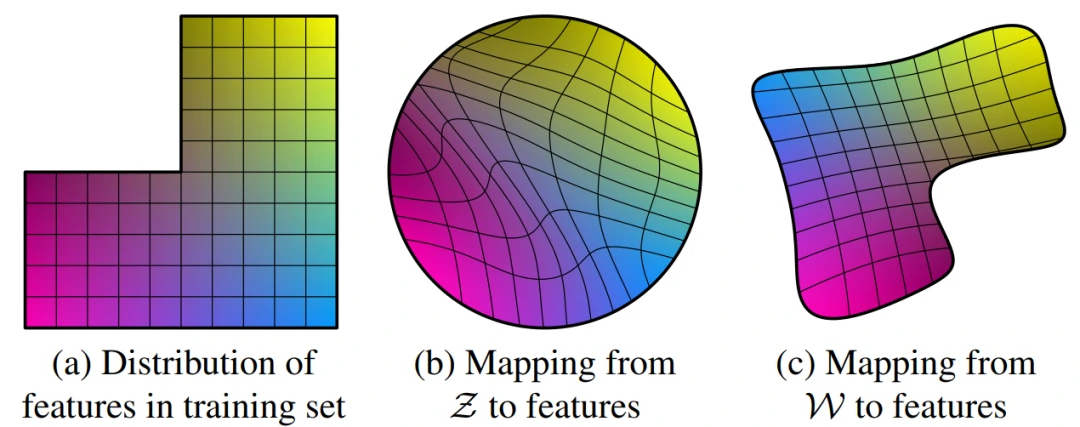
图5. 有两个变化因素(图像特征,如男性化和头发长度)的说明性示例。(a) 一个样本训练集,其中一些组合(如长发男性)是缺失的。(b) 这迫使从Z到图像特征的映射变得弯曲,以便被禁止的组合在Z中消失,以防止无效组合的采样。(c) 从Z到W的学习映射能够 “撤销 “大部分的弯曲
为了量化特征分离的表现,本文提出了量化两种特征分离的新方法:
- 感知路径长度:在两个随机输入之间插值时,测量连续图像之间的差异。剧烈的变化意味着多个功能一起发生了变化,它们可能会相互纠缠。
- 线性可分性:将输入分类为二元类的能力,如男性和女性。分类越好,特征越可分离。
当前 SOTA!平台收录StyleGAN共 75 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| StyleGAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/e072cfc0-26c3-40e7-a979-60df61170c7a |
StyleGAN2
StyleGAN2是为了应对StyleGAN的问题而提出的:少量生成的图片有明显的水珠(water-droplet artifacts),这个水珠也存在于feature map上。导致水珠的原因是 AdaIN,AdaIN对每个feature map进行归一化,因此有可能会破坏掉feature之间的信息。作者认为出现droplet artifact的原因是生成器有意将信号强度信息隐藏再实例归一化后的结果中:通过创建一个强大的、局部的尖峰来控制统计数据,生成器可以有效地缩放信号。

图6 StyleGAN存在的水珠问题
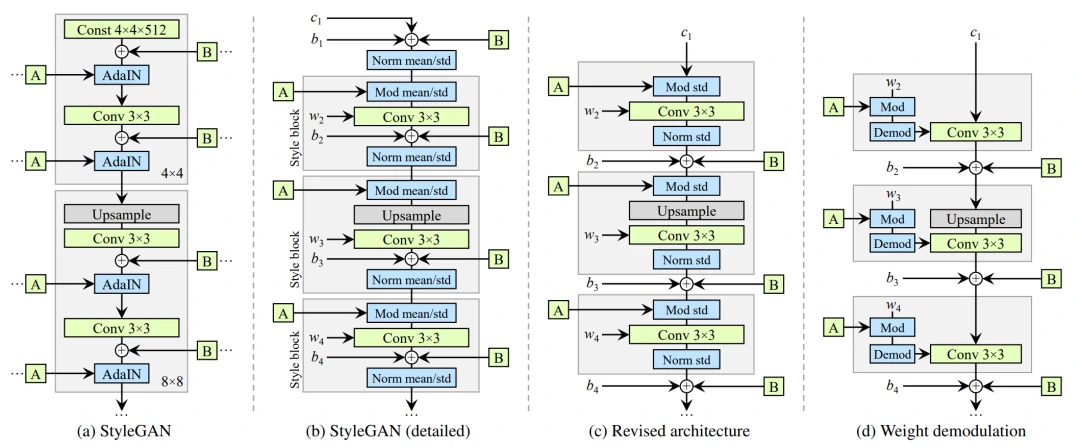
图7 重新设计StyleGAN synthesis network 。(a) StyleGAN,A表征生成style的学习映射变换,B为噪声广播操作;(b) StyleGAN的详细表述,其中,将AdaIN拆分以更加明确归一化操作,两者均基于每个特征图的平均值和标准偏差;(c)StyleGAN2架构,在开始时删除了一些冗余操作,将b和B的添加移动到style的活动区域之外,并仅调整每个特征映射的标准偏差;(d) 将实例归一化替换为“demodulation”操作,将其应用于与每个卷积层相关联的权重
修改StyleGAN的生成器。首先,StyleGAN2将AdaIN重构为Weight Demodulation。如图7(d)所示,modulation根据传入的style对卷积的每个输入特征图进行缩放,也可以通过缩放卷积权重来实现:
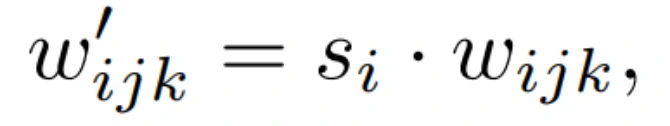
其中,w和w’分别表征原始的和modulated的权重,s_i为对应第i个输入特征图的尺度,j和k分别表示生成输出特征图和卷积的空间分布图。接着对卷积层的权重进行demod:
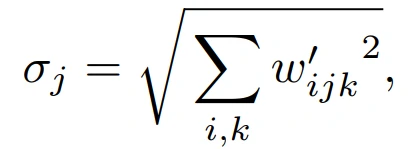
从而得到新的卷积层权重为:
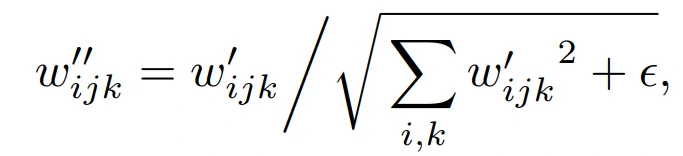
加一个小的ϵ是为了避免分母为0,保证数值稳定性。尽管这种方式与Instance Norm并非在数学上完全等价,但是weight demodulation同其它normalization 方法一样,使得输出特征图有着standard的unit和deviation。此外,将scaling参数挪为卷积层的权重使得计算路径可以更好的并行化。这种方式使得训练加速了约40%。
第二,虽然诸如FID或精确率和召回率(Precision and Recall,P&R)等GAN指标成功地捕获了生成器的许多方面,但它们在图像质量方面仍然有一些盲点。感知图像质量和感知路径长度(perceptual path length,PPL)之间的相关性指标最初是用来量化从潜在空间到输出图像的映射的平滑度,通过测量潜在空间的小扰动下生成的图像之间的平均LPIPS距离来实现。更小的PPL(更平滑的发生器映射)似乎与更高的整体图像质量相关,而其他指标则对此并不敏感。为什么低PPL会与图像质量相关,这一点尚不明确。作者假设,在训练过程中,由于鉴别器对broken image进行惩罚,则改进生成器的最直接方式是有效地拉伸能够产生良好图像的潜在空间区域。
作者通过引入regularization的方式实现上述目标。StyleGAN2使用lazy regularization的策略,即对数据分布开始跑偏的时候才使用R1 regularization,其它时候不使用。Path Length Regularization的意义是使得latent space的插值变得更加平滑和线性。简单来说,当在latent space中对latent vector进行插值操作时,我们希望对latent vector的等比例的变化直接反映到图像中去。即:“在latent space和image space应该有同样的变化幅度(线性的latent space)”(比如说,当你对某一组latent vector进行了5个degree的偏移,那么反映在最后的生成图像中,应该是同样的效果)。
最后,与StyleGAN第一代使用progressive growing的策略不同,StyleGAN2开始寻求其它的设计以便于让网络更深,并有着更好的训练稳定性。progressive growing的关键问题是,逐渐演进的生成器会对细节有着强烈的位置偏好;当像牙齿或眼睛这样的特征应该在图像上平滑移动时,它们反而可能在跳到下一个首选位置之前停留在原地。如图8所示。
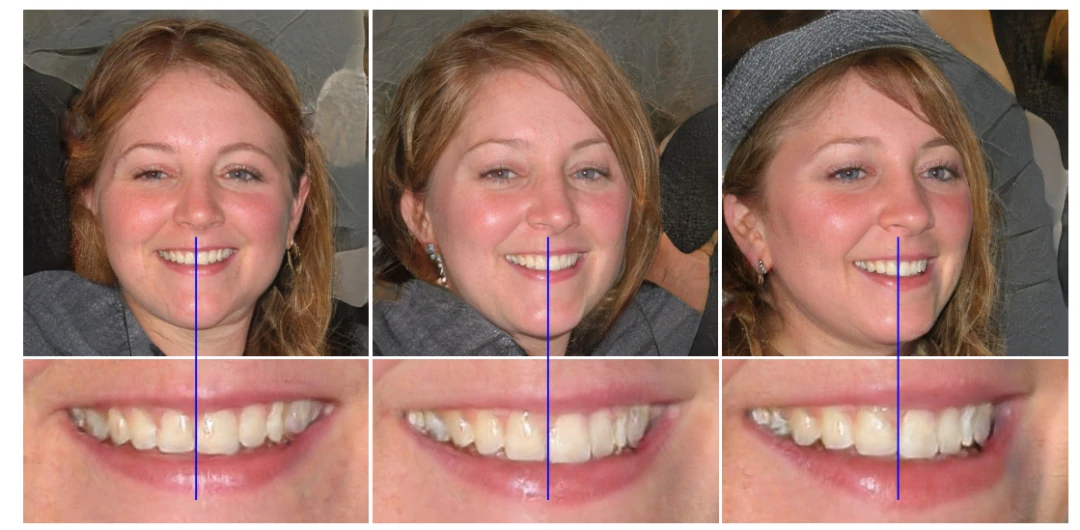
图8. progressive growing会导致 “相位 “伪影。在这个例子中,牙齿没有跟随姿势,而是与相机保持一致,如蓝线所示
为此,作者重新评估了StyleGAN的网络设计,并寻找一种能生成高质量图像而又不会逐渐增长的架构。如图9所示,作者对比了MSG-GAN、对不同分辨率的RGB输出的贡献进行上采样和求和、残差连接。StyleGAN2采用了类似ResNet的残差连接结构(residual block),使用双线性滤波对前一层进行上/下采样,并尝试学习下一层的残差值(residual value)。通过一个resnet风格的skip connection在低分辨率的特征映射到最终生成的图像(图9(c)的绿色block)。
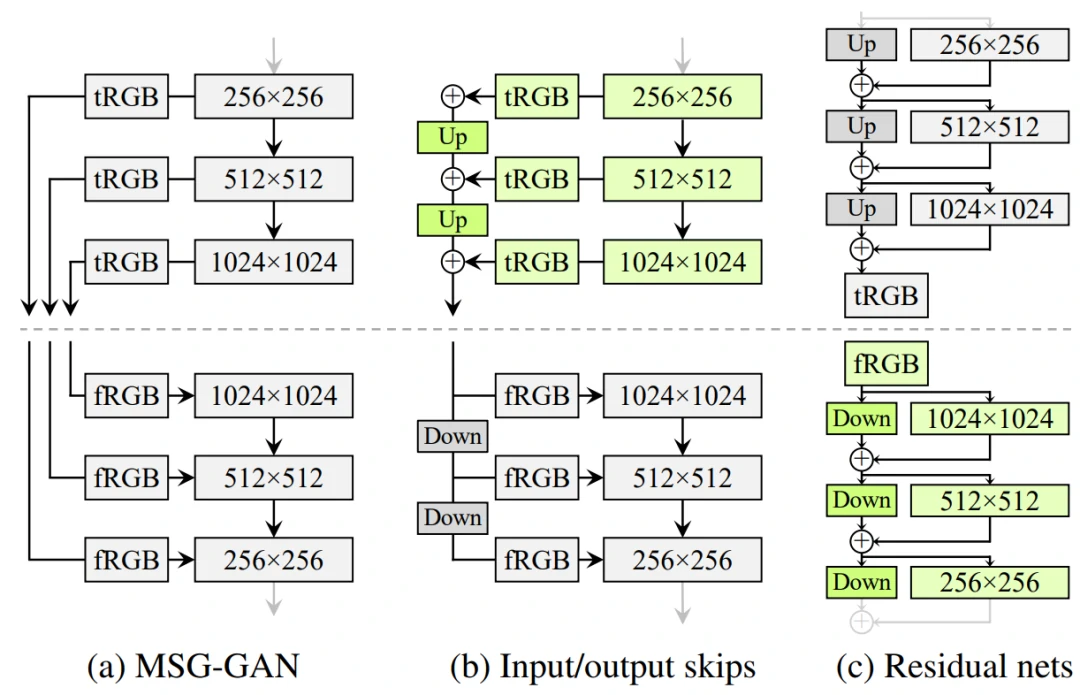
图9. 三个生成器(虚线以上)和鉴别器的结构。上面和下面分别表示双线性上采样和下采样。在残差网络中,这些还包括一个1×1的卷积,以调整特征图的数量
当前 SOTA!平台收录 StyleGAN2 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| StyleGAN2 | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/a07f5a80-bf97-4a33-a2a8-4ff938b1b82f |
StyleGAN3
对于StyleGAN系列来说,生成网络是整体训练的,深层网络特征的空间位置并不是由浅层网络特征很强的控制,而是还受到监督信息(如对抗损失、重构损失等)的决定性的影响,粗糙特征(GAN的浅层网络的输出特征)主要控制了精细特征(GAN的深层网络的输出特征)的存在与否,没有严格控制他们出现的精确位置。按照作者所说:“画面上的细节似乎被粘在了图像坐标上,而不是被描述的物体表面。”作者认为,其根本原因是信号处理导致了生成网络的aliasing。StyleGAN3主要是为了解决这一问题提出的,即实现高质量的 Equivariance(等变性)。所以,StyleGAN3的标题为 Alias-Free GAN。
StyleGAN2生成器由两部分组成。首先,一个映射网络将初始的、正常分布的latent转换为 intermediate latent code w∼W。然后,一个synthesis网络G从学习的4×4×512常数Z0开始,应用N层处理—包括卷积、非线性、上采样和per-pixel噪声—以生成输出图像Z_N=G(Z0;w)。intermediate latent code w控制G中卷积核的调制。各层遵循严格的2×上采样,在每个分辨率下执行两个层,每次上采样后特征图的数量减半。此外,StyleGAN2采用了skip connection、 mixing regularization和 path length regularization 。StyleGAN3目标是使G的每一层对连续信号都是Equivariance的,这样所有较细的细节就会与局部邻域的较粗的特征一起转化。如果这成功了,整个网络也会变得类似于Equivariance。换句话说,目标是使synthesis网络的连续操作g对应用于连续输入z0的变换t(平移和旋转)具有Equivariance:
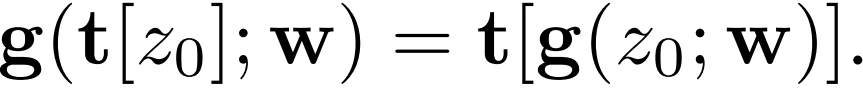
其中 t 是一种变换(平移或旋转),上式表明生成器对特征信号的连续运算应该对于平移和旋转操作是等变的。改进后的生成器网络结构图见图10。
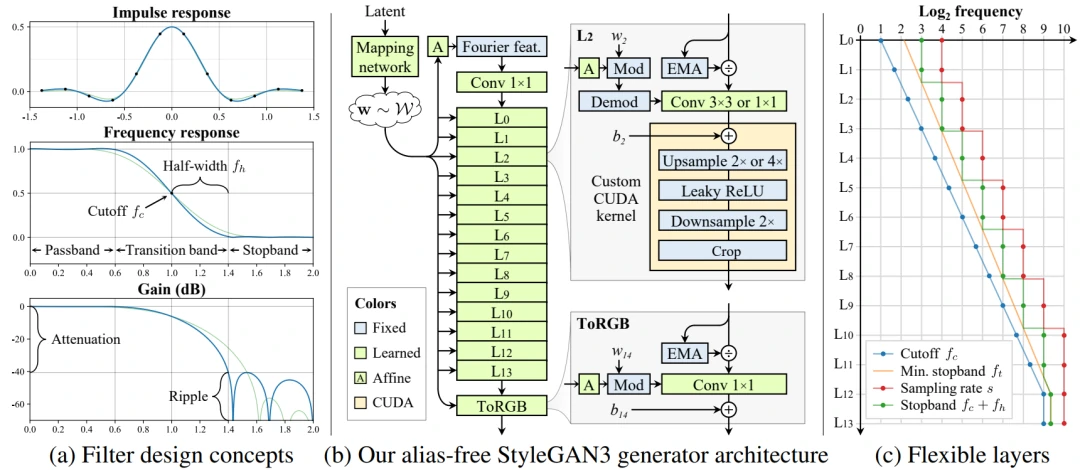
图10 (a) 2×上采样滤波器的一维例子,n = 6, s = 2, fc = 1, fh = 0.4(蓝色)。设置fh=0.6使得过渡带更宽(绿色),这减少了不需要的阻带纹波,从而导致更强的衰减。(b) alias-free生成器,对应于配置T和R。主要的数据路径包括傅里叶特征和归一化,调制卷积和过滤非线性。(c) Flexible layer specification(配置T),N=14,sN=1024。截止点fc(蓝色)和最小可接受的阻带频率ft(橙色)服从各层的几何级数;采样率s(红色)和实际阻带fc+fh(绿色)是根据设计约束计算出来的
首先是将StyleGAN2的生成器的常数输入替换为Fourier特征,删除噪声输入,降低映射网络深度并禁用 mixing regularization 和 path length regularization, 在每次卷积前使用简单的归一化。(B,C,D改进步骤)。
通过在目标空间周围保持一个固定大小的边界来进行近似,在每一层之后都要crop到这个扩展的空间上。用理想低通滤波器的一个更好的近似来代替双线性上采样:带有较大Kaiser窗口(n=6)的 sinc 滤波器,Kaiser窗口的好处是提供了对过渡带和衰减的明确控制。改进的边界和上采样得到了更好的平移Equivariance,但是FID变差了。(E改进步骤)。
由于信号是有带限的,所以可以切换上采样和卷积的顺序,允许将常规的2×上采样和随后与非线性相关的m×上采样融合到一个2m×上采样中,并将整个upsample-LReLU-downsample过程写到一个自定义的CUDA内核中。(F改进步骤)。
为了抑制aliasing,可以简单地将截止频率降低到fc = s/2 - fh,这样可以确保所有的alias频率(高于s/2)都在阻带中。作者又额外加了一些trick使得FID低于了StyleGAN2。(G改进步骤)。
引入一个学习型仿射层,为输入的傅里叶特征输出全局平移和旋转参数。该层被初始化为 identity transformation 。但随着时间的推移,在有利的情况下会学习使用该机制。(H改进步骤)。
作者还设计了新的层规范化操作再次提高平移的Equivariance,目的是增强衰减来完全消除alias。(T改进步骤)。
生成一个有两个变体的rotated equivalence网络。首先,将所有层的3×3卷积改为1×1,并通过将特征图的数量增加一倍来弥补容量的减少。在这个配置中,只有上采样和下采样操作在像素之间传播信息。其次,用一个径向对称的jinc-based的滤波器取代sinc-based的下采样滤波器,用同样的Kaiser方案来构建这个滤波器。对所有的层都是这样做的,除了两个关键的采样层。这两个采样层最重要的是要与训练数据的potential non-radiometric spectrum相匹配。(R改进步骤)。
当前 SOTA!平台收录 StyleGAN3 共 2 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| StyleGAN3 | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/6f7d3d51-762a-4d23-a572-3ea79ab49b4f |
VDVAE
VDVAE是一个层次化的VAE,它能快速生成样本,并在所有自然图像基准上的 log-likelihood 方面优于PixelCNN。文章论证了增加 VAE 的层数能够在保证生成速度的情况下,实现超过自回归模型 (AR) 的 NLL (negative log-likelihood)。VDVAE的基本假设就是:我们可以通过增加 VAE 的层数获得更好的 VAE。首先,本文采用类似 LVAE 的并行化生成,示意图如下:
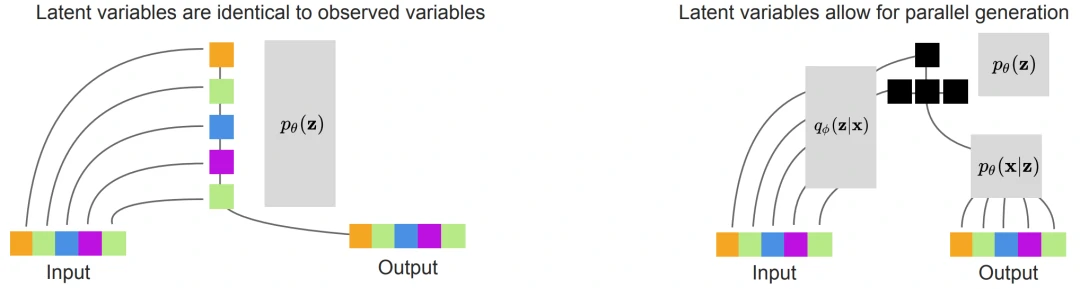
图11 在VAE中可能学到的不同生成模型。左图:一个层次化的VAE可以通过使用确定性的identity functions作为编码器来学习自回归模型,并在先验中学习自回归。右图:学习编码器可以导致潜在变量的有效分层(黑色)。如果最下面的三组潜在变量是有条件地独立于第一组潜在变量的,那么它们可以在一个单层内平行生成,可能会导致更快的采样
当然了,只是单纯的增加VAE的层数并不可行,作者对VAE进行了一些改进,包括减少 residual block 的维度,将残差乘以一个常数,去掉 weight normalization, 使用 nearest-neighbour upsampling, skip 较大的 gradient 等。如图12所示。它类似于ResNet VAE,但有bottleneck ResNet块。对于每个随机层,先验和后验是对角线高斯分布。作为权重归一化和依赖数据的初始化的替代方案,采用默认的PyTorch权重归一化。唯一的例外是对每个剩余bottleneck ResNet块中的最后一个卷积层,将其按1/sqrt(N)进行扩展,其中N是深度。此外,对 “unpool “层使用了最近邻的上采样,当与ResNet架构配对时,可以完全消除相关工作中出现的 “free bits “和KL “warming up “。当上采样通过转置卷积层进行时,网络可能会忽略低分辨率的层(例如,1x1或4x4层)。
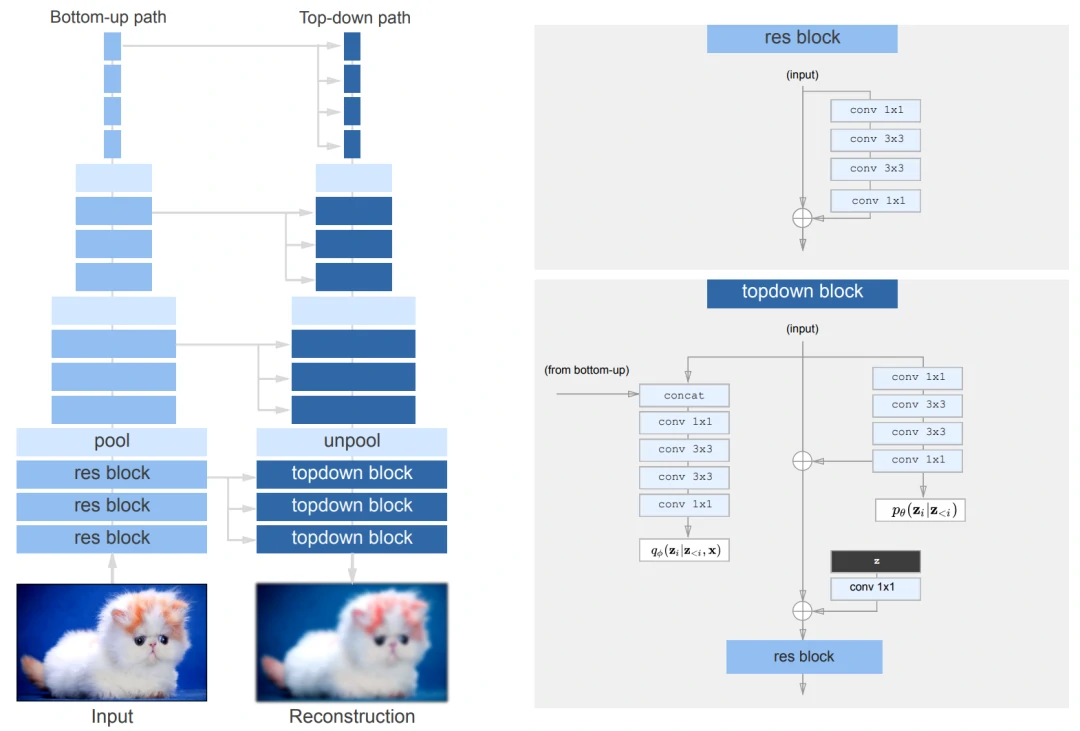
图12. 自上而下的VAE架构的图示。残差块类似于bottleneck ResNet块。q_φ(.)和p_θ(.)是对角线高斯分布。使用平均池化和最近邻上采样来进行池化和非池化层的处理
当前 SOTA!平台收录 VDVAE 共1个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| VDVAE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/0ed2229c-722b-47fb-b6aa-d22dedf87f1b |
NCP-VAE
VAE是强大的基于似然的生成模型之一,在许多领域的应用都取得了很好的效果。然而,它们很难生成高质量的图像,特别是当从先验中获得的样本没有任何调节时。对VAEs生成质量差的一个解释是 prior hole 问题:先验分布不能与总的近似后验相匹配。由于这种不匹配,潜在空间中存在着在先验下具有高密度的区域,而这些区域并不对应于任何编码的图像。来自这些区域的样本被解码为损坏的图像。为了解决这个问题,作者提出了一个基于能量的先验,其定义是基数先验分布与reweighting factor的乘积,目的是使基数更接近总后验。通过噪声对比估计来训练reweighting factor,并将其推广到具有许多潜在变量组的分层VAEs。
这项工作的关键点在于,作为训练VAE的结果,可训练的先验被尽可能地接近 aggregate posterior。先验和 aggregate posterior 之间的不匹配可以通过重新加权来减少,在与 aggregate posterior 不匹配的地方重新调整其可能性。为了表示这种加权机制,使用EBM( Energy-based Models )来确定先验,EBM是由一个 reweighting factor 和一个基础可训练先验的乘积来定义的,如图13所示。用神经网络表示 reweighting factor ,用正态分布表示基本先验。
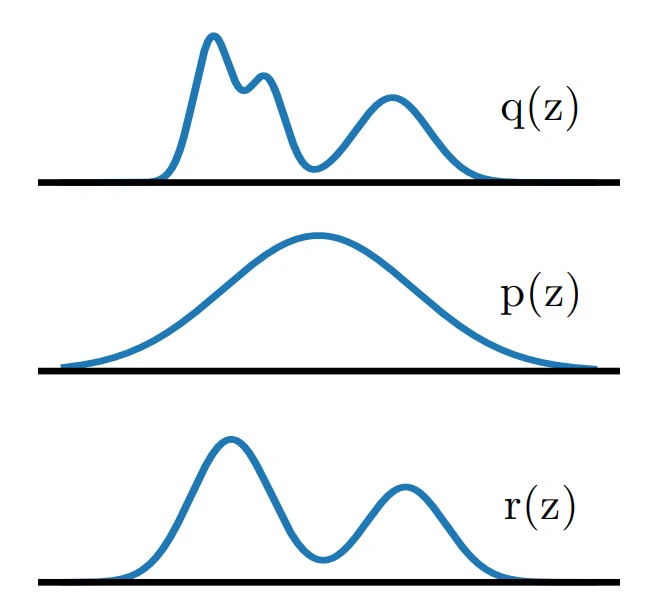
图13 提出了一种EBM先验,使用基础先验p(z)和 reweighting factor r(z)的乘积,旨在使p(z)更接近aggregate posterior q(z)
基于EBM,引入NCP( the noise contrastive prior )计算基础先验:
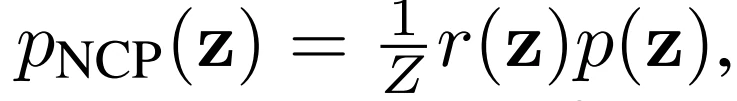
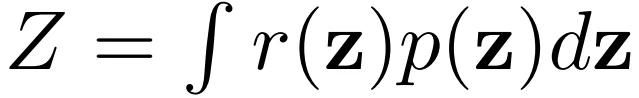
使用两阶段训练方法训练NCP,如图14。在第一阶段,使用原始VAE目标训练VAE。在第二阶段,使用噪声对比估计(noise contrast estimation,NCE)来训练重新加权因子r(z)。NCE训练一个分类器来区分来自先验的样本和来自aggregate posterior的样本。NCP是由基础先验和reweighting factor的乘积构建的,通过分类器形成。在测试时,使用采样-重要性-采样( sampling-importance-resampling ,SIR)或LD(Langevin dynamics )从NCP中采样。然后,这些样本被传递给解码器以产生输出样本。
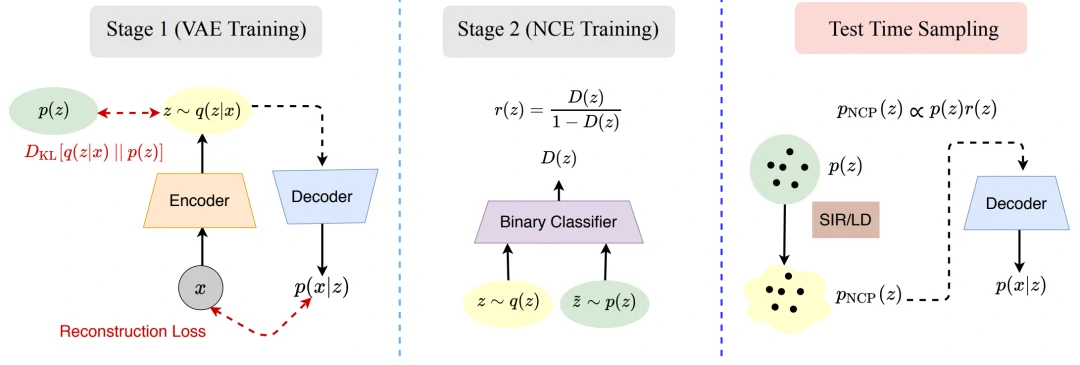
图14. NCP-VAE的训练分为两个阶段
最后,作者还将NCP-VAE扩展到了Hierarchical VAEs
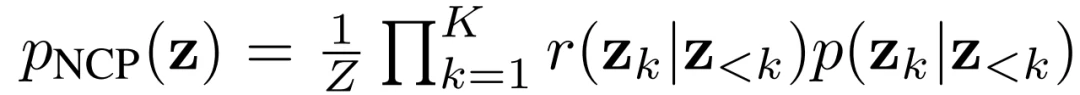
其中,每个因子都是EBM。pNCP(z)类似于具有自回归结构的组间EBM。在第一阶段,以先验的方式训练HVAE:
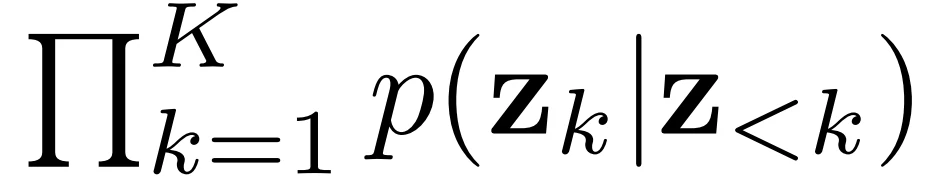
在第二阶段,我们使用K个二进制分类器,每个分类器用于一个分层组。通过以下方式训练每个分类器
| 项目 | SOTA!平台项目详情页 |
|---|---|
| NCP-VAE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/74d15cbe-7f75-434a-a1cf-a69ae303eec6 |
StyleGAN-xl
StyleGAN-XL 是第一个在 ImageNet-scale 上演示 1024^2 分辨率图像合成的模型。实验表明,即使是最新的 StyleGAN3 也不能很好地扩展到 ImageNet 上,特别是在高分辨率时,训练会变得不稳定。StyleGAN为关于图像质量和可控性的生成建模设定了一种标杆方法。但StyleGAN在 ImageNet 等大型非结构化数据集上表现不好,它更适合人脸数据方面的生成。
研究者首先修改了StyleGAN的生成器及其正则化损失,调整了潜在空间以适应 Projected GAN (Config-B) 和类条件设置 (Config-C);然后重新讨论了渐进式增长,以提高训练速度和性能 (Config-D);接下来研究了用于 Projected GAN 训练的特征网络,以找到一个非常适合的配置 (Config-E);最后,提出了分类器引导,以便 GAN 通过一个预训练的分类器 (Config-F) 提供类别信息。这样一来,就能够训练一个比以前大得多的模型,同时需要比现有技术更少的计算量。StyleGAN-XL 在深度和参数计数方面比标准的 StyleGAN3 大三倍。
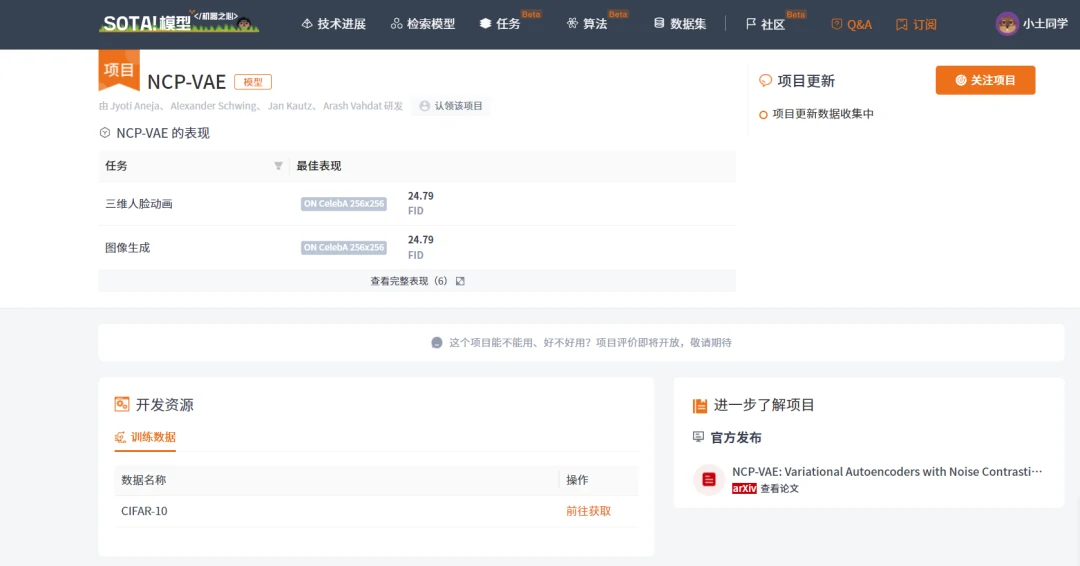
图15. StyleGAN-XL训练。将潜在编码z和类别标签c送入预训练的嵌入和映射网络G𝑚,以生成 style code w,这些code调制synthesis网络G𝑠的卷积。在训练过程中,逐渐增加层数,使渐进式增长的每个阶段的输出分辨率增加一倍。只训练最新的层,而保持其他层的固定。G𝑚只在最初的162阶段进行训练,在更高的分辨率阶段保持固定。合成的图像在小于2242时被放大,并通过一个CNN和一个ViT( Vision Transformer)以及各自的特征混合块(CCM+CSM)。在更高的分辨率下,CNN接收未经修改的图像,而ViT接收降频输入,以保持低内存要求,但仍利用其全局反馈。最后,在得到的多尺度特征图上应用八个独立的鉴别器。图像也被送入分类器CLF,用于分类器指导
此外,还可以进一步细化所得到的重构结果,StyleGAN-xl可以在肖像或特定对象类的应用领域完成逆映射、编辑等扩展任务,将 PTI 和 StyleGAN-XL 相结合,几乎可以精确地反演域内 (ImageNet 验证集) 和域外图像。同时生成器的输出保持平滑。
当前 SOTA!平台收录 StyleGAN-XL 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| StyleGAN-XL | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/01d16b00-e79f-4527-a7e3-08354b5d9b47 |
Diffusion GAN
Diffusion-GAN主要关注的是 stabilize GAN training 的问题。为了实现GAN的稳定训练,将实例噪声注入鉴别器的输入理论上可行但缺少实践的验证。本文介绍了Diffusion-GAN,它采用了高斯混合分布,在前向扩散链条中的所有扩散步骤中引入实例噪声。将观察到的或生成的数据中扩散出的混合物的随机样本作为输入送入鉴别器。生成器通过前向扩散链反向传播其梯度进行更新,其长度是自适应调整的,以控制每个训练步骤中允许的最大噪声与数据比率。
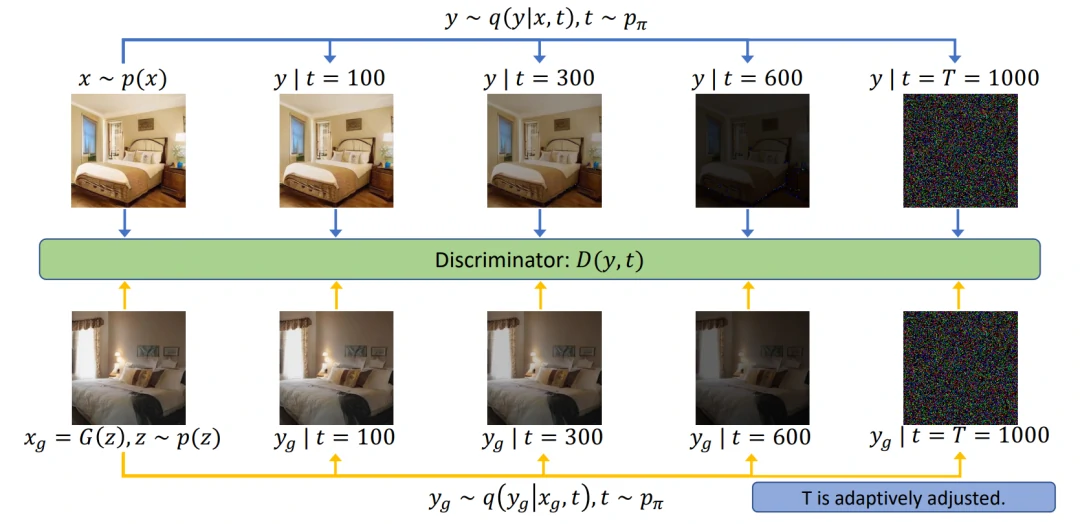
图16. Diffusion-GAN的流程图。上排图像代表真实图像的前向扩散过程,而下排图像代表生成的假图像的前向扩散过程。鉴别器学会在所有扩散步骤中区分扩散的真图像和扩散的假图像
Diffusion-GAN的对应目标是vanilla GAN的最小-最大目标,定义为
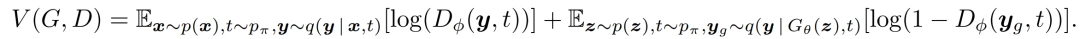
鉴别器D学习区分扩散的生成样本y_g和扩散的真实观测值y,时间为∀t∈{1, . . . , T},具体的优先级由π_t的值决定。生成器G学习将潜在变量z映射到它的输出x_g=G_θ(z),它可以在扩散链的任何一步骗过鉴别器。y_g∼q(y | G_θ(z), t)可以被重新参数化为
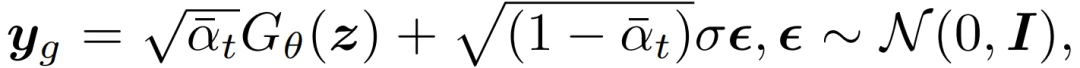
梯度可以直接反向传播到生成器。随着t的增加,y和y_g中的噪声与数据之比也在增加,从而使鉴别器D的任务越来越难。作者设计了一个扩散强度的自适应控制,以便更好地训练鉴别器。作者通过适应性地修改T来实现这一目标。我们为T设计了一个基于度量r_d的 self-paced schedule,这个schedule评估了鉴别器的过拟合度
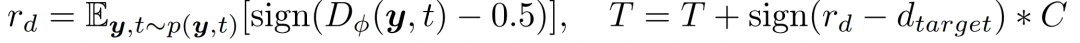
为了更好地防止鉴别器过拟合,定义t作为一个不对称的离散分布,鼓励鉴别器在T增加时观察新增加的扩散样本。
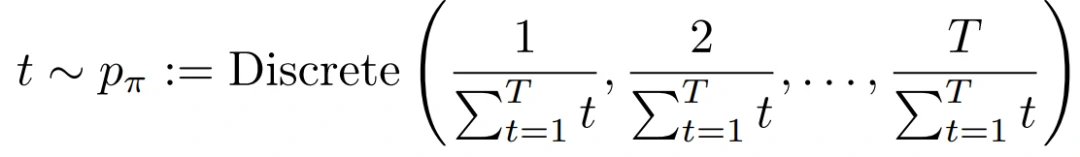
当T开始增加时,鉴别器对所看到的样本已经很有信心,所以我们希望它探索更多的新样本,以抵消鉴别器的过度拟合。
当前 SOTA!平台收录 Diffusion-GAN 共 1 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| Diffusion-GAN | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/9aa9b499-adec-46a3-aef9-4cd73e1c13ec |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。