
论文题目:基于不确定因素感知的鲁棒虹膜识别
Towards more discriminative and robust iris recognition by learning uncertainty factors
论文作者:卫建泽(中国科学院大学,中科院自动化所),黄怀波(中科院自动化所),王云龙(中科院自动化所),赫然(中科院自动化所),孙哲南(中科院自动化所)
收录期刊:IEEE Transactions on Information Forensics and Security
论文DOI: 10.1109/TIFS.2022.3154240
代码链接:https://github.com/reborn20200813/uncertainty
研究动机
研究背景
在虹膜识别技术探究的过程中,研究人员已经发现多种因素会显著的影响识别性能,例如采集距离、图像分辨率、光照、设备变更等;事实上,除了这些因素外还有其他的不确定因素在不经意地改变成像效果,进而影响算法的识别性能。具体来说,虹膜图像获取实质上是对人眼、环境和采集设备三者交互过程的单次采样,而交互中的这三大因素都会涉及大量的采集因素——人眼会涉及姿态、运动和遮挡等,环境会涉及光照等,而采集设备会涉及光学镜头、传感器等。即使是人为控制的受控场景,仍无法确保这些采集因素呈不会发生改变的确定态;换而言之,采集过程会无时不刻收到不确定采集因素的作用,而不确定采集因素对于最终成像的影响被称为采集不确定性。
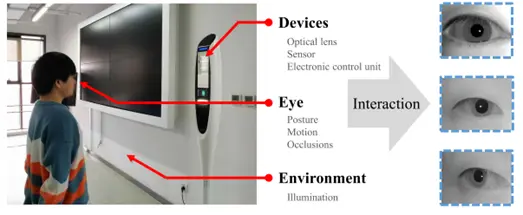
采集不确定性往往会导致每次成像结果都不尽相同,而这种成像的差异体现在特征空间上是导致不同图像的特征点无法聚焦于同一位置而是围绕某一点分布。现有的特征提取器(不论是基于特征模板还是基于特征向量的算法)采用确定点来表示虹膜图像,具体来说,特征空间中的任意一点都对于某一具体图像。当使用确定点表示方法时,采集不确定性会使得同一目标不同图像的虹膜特征呈现差异,影响最终的验证或识别结果。
方法动机
由于确定点表示方法无法规避采集不确定性带来的影响,这让我们不得不寻求一种新的表示方法来解决采集不确定性的影响。想要针对采集不确定性来设计算法,首先需要了解采集不确定性如何影响虹膜特征。虽然采集不确定性导致同一目标不同图像的虹膜特征在空间中弥散,但我们仍然可以发现一个基本的规律——同一目标的虹膜特征呈抱团分布,越相似的虹膜图像在空间的距离越近。基于该规律,本文进行了大胆但合理的假设:
(a) 根据中心极限定律,同一目标类别的虹膜图像在特征空间中围绕某一确定中心点呈高斯分布。
(b) 该确定中心点是一个不受采集不确定性影响的具有判别力的身份特征。
基于该假设,采集不确定性对虹膜特征的影响便清晰了起来。每张虹膜图像采集后包含有两类信息——用于识别的身份信息,影响识别的采集不确定性信息;确定点表示方法无法有效区分这两种信息,导致特征空间中的样本点既包含有识别所需的身份信息也包含有视为噪声的采集不确定性信息;此时,同一目标不同图像的对应样本点具有相同的身份信息,这使得他们呈抱团状,但各异的采集不确定性信息导致他们无法位于同一位置(即假设中的确定中心点);而样本点相对该确定中心点的偏移就是由采集不确定性造成的。
不确定因素感知的鲁棒虹膜识别
算法的整体框架如图二所示,在2.1-2.3将对各模块进行分别介绍。
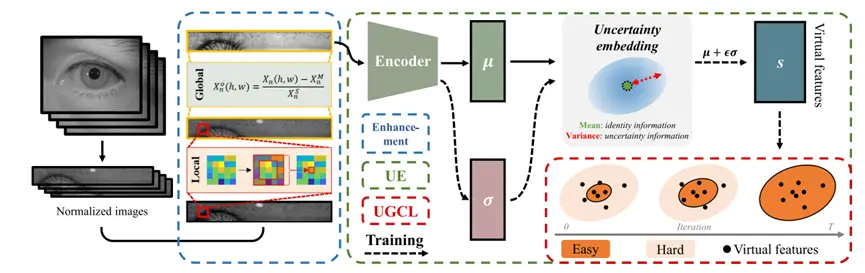
概率隐表达
为了将身份信息和采集不确定性信息加以区分,本文提出了概率隐表达,该表达方法使用多元高斯分布来表示虹膜图像。
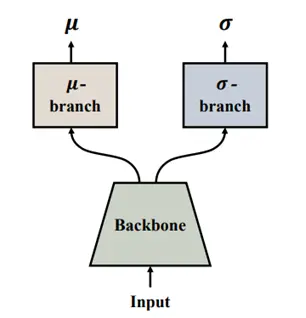
具体来说,对于一张虹膜图像,该表达方法使用如下图所示的编码器来获得其对应目标类别的特征表达z_n。编码器的主干网络首先对图像抽取虹膜特征,然后编码器中的 μ- 分支和 σ- 分支从特征中预测z_n的均值μ和方差σ。

不确定性引导的课程学习
在1.2中可知不同样本点由于收到的采集不确定性影响不同,样本点距离中心的距离也各有差异,而虚拟特征也是同理——距离均值点较近的特征受采集不确定性影响较小,对应高质量的成像结果,而距离均值点较远的特征受采集不确定性影响较大,对应降质图像。
根据之前的工作可知,使用高质量的图像有助于提升模型精度却无助于鲁棒性提升,而使用降质图像有助于提升模型的鲁棒性却影响模型收敛和精度提升,本文提出了配套概率隐表达的学习策略。
该策略的核心想法是在训练早期优先使用高质量的虚拟特征(对应论文中的容易样本,easy samples)来快速收敛模型并确保模型精度,而且在后续引入降质的虚拟特征(对应论文中的困难样本,hard sample)来提升模型鲁棒性。具体做法是根据虚拟特征的生成过程来计算样本的困难程度,在开始训练阶段使用困难程度较低的特征来优化模型,然后逐渐引入困难程度较高的特征来巩固模型优化,最终达到又准确又鲁棒的目的。
归一化图像增强
前面的内容中大量的讨论了采集不确定性,这些采集不确定性各种场景或识别设定中普遍存在,但仍有一种潜在的采集不确定性没有讨论,那就是跨库场景中的采集不确定性。
在一个识别场景中,有些采集因素被预先设定(比如采集设备的型号等),而有些采集因素则是不确定的(比如采集距离、光照、瞳孔放缩情况等);前者往往被视为确定因素,而后者被视为不确定因素。然而,确定因素并不总是确定的,在常规的库内识别设定下,由于训练数据的存在,测试数据中采集因素的确定与否是可被感知和学习的,其中采集因素的不确定性被 σ-分支所学习;而在跨库识别设定下,训练数据是缺失的,这意味测试数据中采集因素的确定与否无法感知,因为 σ-分支只能通过训练数据来建模的不确定性信息。这种不可学习的采集不确定性是概率隐表达无法建模的,因此本文提出了归一化图像增强来针对该问题来进行解决。
该增强方法分为基于局部统计量和基于全局统计量的两个增强步骤。基于局部统计量的增强步骤聚焦于图像的 3x3 局部区域,利用局部区域内的中值来平滑方法来消除图像噪声造成的采集不确定性。而基于全局统计量的增强步骤统计了图像整体的一阶和二阶统计量,并以此为参考来调整图像。这种基于局部和全局统计量的增强方法有效改善了归一化图像,解决了预训练设定中不可学习的数据不确定性的负面影响;事实上,实验表明这种增强方法对于其他阶层设定同样有效。
实验结果
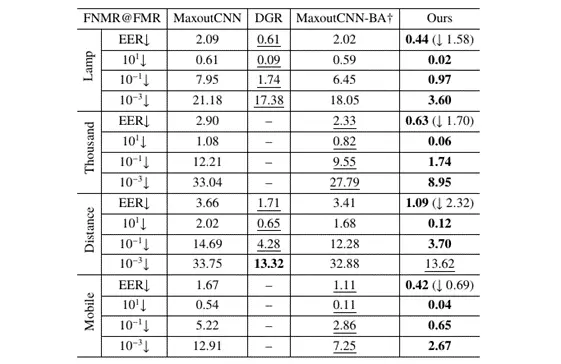
同设备识别
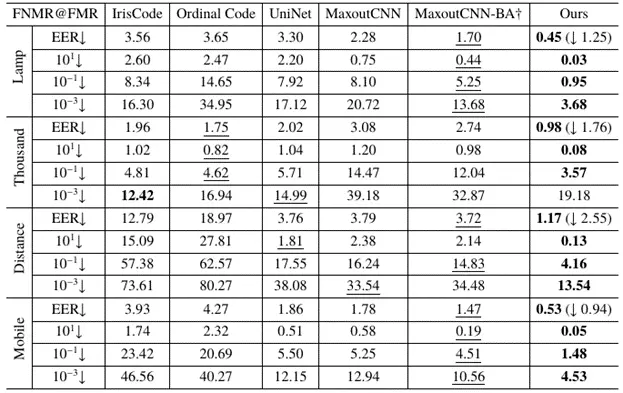
本文所提方法在CASIA-irisV4-Lamp、CASIA-irisV4-Thousand、CASIA-irisV4-Distance 和 CASIA-iris-Mobile-V1四个同设备数据集上进行了库内和跨库两种设定的测试。表一和表二分别展示了在库内和跨库两种设定下的性能对比
跨设备识别
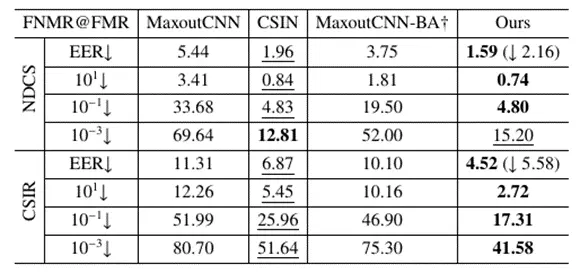
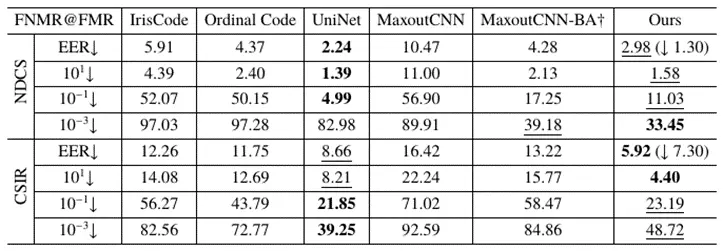
跨设备识别是相较于同设备识别更具挑战性的识别难题,该任务需要算法使用某一型号的设备来进行用户注册,然后使用另外型号的设备来进行用户识别。本文在ND-CrossSensor-Iris-2013和CASIA Cross Sensor Iris Recognition两个数据集上进行了库内和跨库两种设定的识别。表三和表四分别展示了算法在库内和跨库两种设定下的识别结果。
相关扩展
本文的工作也可以用于无监督虹膜识别,相关的工作已在IJCB 2021进行口头汇报,
论文题目为:Contrastive Uncertainty Learning for Iris Recognition with Insufficient Labeled Samples,
相关代码链接为:https://github.com/reborn20200813/CUL
致谢
本研究成果得到了中国人工智能学会-华为MindSpore学术奖励基金的资助。
MindSpore官网:https://www.mindspore.cn/