2021年已经成为脑机接口(BCI)融资创纪录的一年。BCI将人类的脑电波转换成机器可以理解的指令,允许人们可以用他们的大脑来操作计算机。就在最近,埃隆·马斯克(Elon Musk)的BCI公司Neuralink宣布获得2.05亿美元的C轮融资,而几天前,另一家BCI公司Paradromics宣布获得2000万美元的种子轮融资。几乎在同一时间,Neuralink的竞争对手 Synchron宣布已获得FDA的突破性批准,可以对其旗舰产品 Stentrode 进行人类患者的临床试验。

然而,许多人对Neuralink 的进展以及 BCI 即将到来的说法持怀疑态度。我建议从不同的角度来理解另一个领域的突破如何使 BCI 的承诺比以前更加切实可行。为此我们要先明白BCI的核心在于扩展我们人类的能力或补偿失去的能力,例如对于瘫痪的人。这一领域的公司通过两种形式的BCI来实现这一目标—侵入式和非侵入式。在这两种情况下,大脑活动都被记录下来,以将神经信号转换成指令,如用机械臂移动物品、头脑打字或通过意念说话等。这些强大翻译背后的引擎是机器学习,它从大脑数据中识别模式,并能够在许多人类大脑中归纳这些模式。
模式识别与迁移学习
早在几十年前就已经实现了将大脑活动转化为行动的能力。如今,私营企业面临的主要挑战是为大众打造商业产品,让它们能够在不同的大脑中找到共同的信号,并转化为类似的动作,比如表示“移动我的右臂”的脑电波模式。
想要实现这一点,可能微调才能做到。幸运的是,人工智能在模式识别方面的研究取得了巨大进步,特别是在视觉、音频和文本领域,产生了更强大的技术和架构,使人工智能应用程序能够泛化。
开创性的论文《Attentionis all you need》提出的“Transformer”架构激发了许多其他激动人心的论文。它于 2017 年底发布,带来了跨领域和模式的多项突破,例如谷歌的 ViT、DeepMind 的多模式感知器和 Facebook 的 wav2vec 2.0。每一个都在各自的基准测试中取得了最先进的结果。
基于Transformer模型的Encoder-Decoder模型示意图
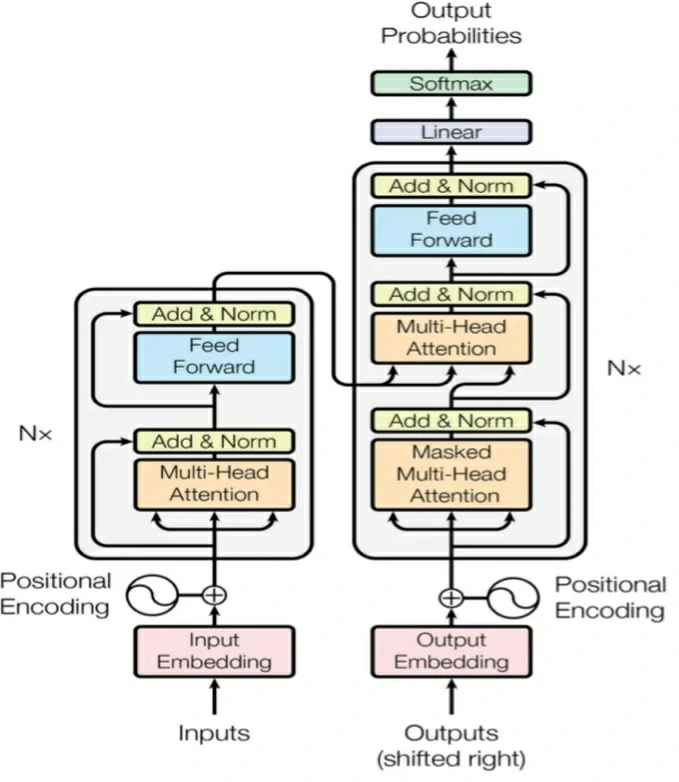
Transformer 架构的一个关键特征是其零样本和少样本学习能力,这使得 AI 模型可以泛化。
丰富的数据
最先进的深度学习模型,如上述Google、DeepMind 和 Facebook的模型,需要大量的数据。而在线数据是推动计算机生成的自然语言应用程序最近爆炸式增长的主要催化剂之一。当然,脑电图(EEG)数据不像维基百科(Wikipedia)页面那么容易获得,但这种情况正在发生改变。
世界各地的研究机构正在发布越来越多的BCI相关数据集,使研究人员可以在彼此的学习基础上进行研究。例如,多伦多大学的研究人员使用了天普大学医院脑电图语料库(TUEG)数据集,该数据集包含了超过10000人的临床记录。
研究实验室收集的数据是一个很好的开始,但在现实世界的应用中可能还不够。如果BCI要加速发展,我们需要看到人们可以在日常生活中使用的商业产品出现。随着OpenBCI这样的项目使人们可以买得起硬件,以及其他商业公司现在向公众推出他们的非侵入性产品,数据可能很快就会变得更容易获取。
硬件和边缘计算
BCI应用程序具有实时操作的限制,比如打字或玩游戏。如果从想法到行动的延迟超过1秒,那么用户体验就会变得难以接受,因为交互将会变得迟缓且不一致(比如:想想一款延迟1秒的第一人称射击游戏)。将原始EEG数据发送到远程推理服务器,然后将其解码为具体的动作,并将响应返回给BCI设备,就会引入这种延迟。
最近AI芯片的发展可以解决这些问题。像英伟达和谷歌这样的巨头都在打造更小、功能更强大的芯片,并在边缘进行了优化。这进而可以使BCI设备脱机运行,避免发送数据,消除与之相关的延迟问题。
最后的想法
几千年来,人类的大脑并没有太大的进化,而我们周围的世界在过去的十年里发生了巨大的变化。人类已经达到了一个转折点,它必须增强其大脑能力,以跟上我们周围的技术创新。
BCI仍处于起步阶段,有许多挑战需要解决,还有许多障碍需要克服。然而,对于一些人来说,这应该已经足够令人兴奋,可以放下一切并开始构建。
参考资料
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10344