前几天在知乎上看到华为提出的一个VanillaNet,其中的一个设计点和我一直想实现的功能非常类似,即训练阶段的时候模型是比较深的网络,推理的时候会自动变成比较浅的网络。起初我一直想缓渐地暴力地丢掉卷积层,结果不能如愿,模型性能会在训练阶段的最后几个epoch一直退化,模型变成毫无用处的废物。整整大半年一直也没找到稳定性能的方案,这也把我后续所有的构想都否定了。本着拿来主义,本文直接采用VanillaNet的方案重新开始构建模型ReduceNet
ReduceNet和VanillaNet有以下几个区别:
- a.引入残差,提升模型性能。部署阶段,残差也可以作为特殊的卷积核融入卷积算子。b.不使用多余的非线性激活函数,不同模块可以继续融合,这也是reducenet关键设计。起源于某个偶然的发现:resnet两个3x3卷积构成的模块,去掉第二个激活函数,性能会提升,顺便提高了速度。所以reducenet模块也只采用一个激活函数,而且是在训练结束消失的激活函数。c.不使用maxpooling,用卷积代替,不同stage可以继续融合。
- 模型只有在训练阶段存在激活函数,部署阶段整个网络没有任何激活函数(最后的softmax还是需要的)。
- 根据2,backbone所有的线性层理论上可以继续融合为一个超大尺寸卷积核的卷积层,逼近一个全连接层,印证了那个传说中的“单层网络理论”。
- 利用bottleneck结构增加模块网络宽度,为训练阶段引入更多参数量,而不增加推理时候的开销。理论上我们可以在训练时让模块中间无限宽,推理时计算开销只由模块首尾的宽度决定。实际上应该会存在短板效应。我们大概只能在首尾宽度固定情况下不断压榨性能直到性能饱和。再继续增加中间网络宽度估计就变成冗余了。这时只能增加模块首尾宽度继续提升性能。用这种方式有点神经架构搜索的味道。也许神经神经架构搜索本身是很冗余的领域。渐进地调整宽高,压榨性能,试探临界才是较优解。
本文贡献如下:
- 理论说明深度非线性网络可以融合成单层网络,实验中模型也取得不错的性能。好好探索架构,取得Sota应该也没问题。
- 尝试解释了为什么单层网络规模足够大却很难获得学习能力,从优化的角度为多层非线性网络和单层网络建立了联系,并指出多层非线性网络本质上可以为”探索单层网络的权重最优值”提供更大的探索自由度, 缓解优化算法和单层网络的“不和”,从而具备更高的学习效率。
- 训练阶段,ReduceNet可以和现有的其他模型设计兼容,享有深度非线性网络的性能收益。推理阶段则变成单层网络,保持高性能的同时,获得激进的模型效率。
- ReduceNet理论上可以在训练阶段无限深和无限宽(bottleneck中间表示无限宽),推理阶段变成一个小网络,有需要的话甚至直接变成单层网络。
不排除我犯了很傻的代码错误,一切只是我的妄想(真的碰到好几次了),如果错了就删帖跑路
代码链接:https://github.com/ohmydroid/reducenet
动机
模型压缩的核心思想是先利用大网络的学习能力,最后通过各种手段(知识蒸馏,剪枝,神经架构搜索,动态推理网络等)将该能力转移到较小的模型上,以减少资源开销。(目前的分类习惯并不把神经架构搜索,动态推理网络归于模型压缩,这仅仅是我个人习惯和理解)
ReduceNet的灵感来源有以下几个:
- RepVGG是比较特别的模型,训练时有多个分支,推理时可以合并成单个分支,可以看作是网络宽度这个角度的缩并。所以很容易联想到把这种设计扩展到网络深度方向,相关的工作有DepthShrinker,RMNet。严格来说,读研期间设计的静态condconv比这个更早,模块化动态卷积又被condconv先发。横向重参化的idea应该来源于condconv。
- SkipNet, 一种动态推理网络,在推理阶段通过路由网络为不同数据选择性地跳过主网络的一些网络层,以减少计算。
- Stochastic Depth,训练阶段以概率的方式激活或者不激活残差块中的卷积分支,可以提升性能,但是推理阶段没有减少网络深度,按照概率融合卷积块和残差。
- DepthShrinker, 比较接近我设想中的模型,但是条件很麻烦,需要学习mask参数,还要蒸馏,微调和融合。RMNet需要剪枝,微调,和融合。这些方式其实和华为的VanillaNet比较接近了。后者更加简洁有效。我自己想的方案暂时又粗暴且无用,打不过就加入。
- VanillaNet中Deep Training Strategy,里面的公式以及衰减策略和我设计的几乎差不多,只是VanillaNet选择了对激活函数下手,再后期融合两个串联的卷积算子。而我天真地以为idea结合了skipnet,Stochastic Depth,神经架构搜索等思想必定万无一失(不排除以后会有正确稳定的方案),从而贪心地选择最后丢弃整个卷积层。实验结果一度让我怀疑人生,模型性能会在最后阶段彻彻底地崩溃。换成VanillaNet的Deep Training Strategy后模型结果非常理想。
- 是我N年前构想的DetachNet,算是ReduceNet的雏形,希望有一个无限大的网络可以为一个小网络的每一层提供scale factor(scale的方式乘,加,卷积都可以)。这个和动态卷积非常类似了,只不过我希望大网络在训练的可以无限大,推理的时候可以摘除,将能力转移给小网络,完美的妄想的无限压缩算法。最终败于BP算法。也不是不可能。我一度相信,这种模型会让AGI时代到来,完全没想到AGI风暴是ChatGPT引起的。ReduceNet现在好像也可以在训练阶段无限大,推理阶段非常小,所以DetachNet也算后继有net。
压缩深度
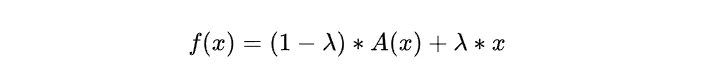
上述公式是VanillaNet减少网络深度的关键,其中 A(x) 是非线性激活函数,λ 是再训练过程中动态变化的数值,从0到1变化(随着epoch线性变化或者利用cosine函数的变化)。在训练过程中,f(x) 是一个非线性的激活函数,赋予网络更强的学习能力,在模型的最后一刻,λ 变为 1,这意味着 f(x) 变成了 x,非线性消失。
这样的设计带来的收益是巨大的。试想一下,f(x) 的前后接着两个卷积层(VanillaNet中是两个1x1卷积,包括BN层)。推理阶段,当非线消失,conv和BN本身可以融合成一个conv层,两个线性conv可以进一步合并成1个conv。用更浅的网络获得深层网络才有的收益,比一些复杂的压缩算法好用多了。
总的来说,这种设计使得模型在训练过程中借助多层卷积和非线性获得更强的学习能力;推理阶段,非线性消失则为减少网络深度提供了可能。
顺便一提,VanillaNet网络虽然浅但是非常宽,计算量,参数量,内存占用都很大,唯一的优势可能就是用更快的速度取得接近sota的准确率。然而,这速度也是有限制的。归根结底这限制来自于宽网络引发的一系列连锁反应。庞大的通道数,会带来更多的内存占用,进一步增加访存。batch size等于1的时候vanillanet还有速度优势,其远超深网络的计算开销还能忽略。如果batch size变大呢,想必速度优势不会有这么明显,甚至会逐渐慢于普通的sota模型,那其优势将荡然无存。
VanillaNet的deep training strategy足以对深度网络模型设计产生深远的影响,可能在网络架构上设计元素太多太杂,反而不能发挥整体优势。
那么为什么 A(x) 是激活函数,而不是别的什么呢?我之前的方案是把 A(x) 视为一个完整的非线性模块或者小网络。如果可以稳定性能的话,自然也就具有VanillaNet减少深度的优点,甚至不需要后期融合算子的处理。很可惜,至少目前为止,这个方案没有成功。当整个f(x)变成x的时候,模型性能会在训练的后期逐渐崩坏。也许,以后可以找到可行的方案,继续这个研究,毕竟自动压缩网络深度是个很吸引人的特性。不过目前, VanillaNet的策略已经可以足够优秀了,因此我也暂时用这个设计策略继续后续的工作。
模块设计
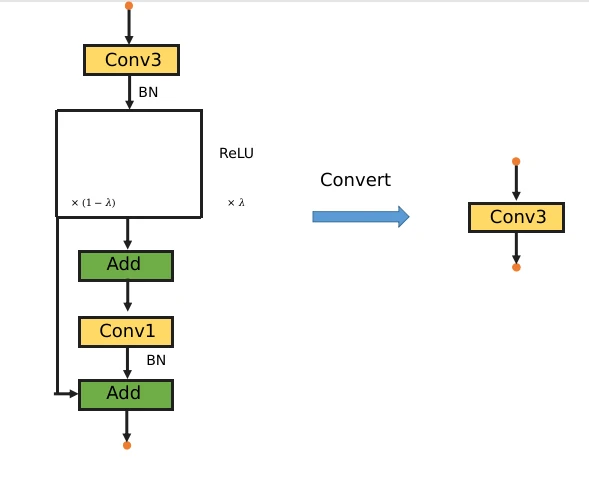
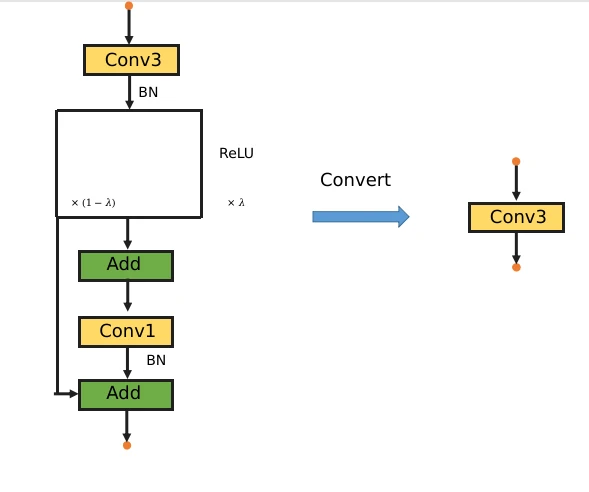
和VanillaNet不同,本文设计的基本模型由3x3 conv, 1x1 conv ,残差连接构成。下采样的话,也只要把3x3 conv的stride设置为2,并且去除收尾的残差(激活函数的残差保留)。值得注意的是整个模块只有一个激活函数,训练结束,激活函数也会消失。之所以只用一个激活函数是因为之前发现resnet的残差块中去掉一个激活函数效果会更好,速度还更快(查重发现被人发过了)。
λ 数值,我是随着iteration从1到0按照cosine的方式衰减,公式和VanillaNet的是反过来的。
训练阶段,模块如左图,推理阶段,这个模块会整合成一个纯线性的3x3 conv。能够融合的原因有以下几点:
- conv, bn可以融合成1个conv
- 一个 3x3 conv 和一个 1x1 conv 会整合成一个 3x3 conv
- 残差连接是可以看作一种特殊的卷积核,所以也可以参与线性融合
比起VanillaNet,ReduceNet的其中一个优势在于能够和现有的架构设计方式兼容。
此外,当训练结束后,所有算子完成上述的融合后,ReduceNet的网络backbone部分,只有连续的3x3 conv,这意味着这些纯线性的3x3 conv可以进一步连续融合直至变成一个更大尺寸卷积核的单层卷积。最终,整个网络会变成一个卷积层,pool, FC, 总共3层。pool是avgpool的话网络应该可以直接变成1层。
实现效果
按照resnet56 cifar的架构(训练阶段是56层),cifar10的准确率可以达到93%, 而相同架构(对比推理阶段的29层,我还没彻底融合网络成一层)浅层非线性残差网络Resnet29(每一个非线性3x3卷积加一个残差,和原版resnet不同,因为要和我的模型推理阶段的架构公平对比)是91+%(手贱,不小心把tmux退出了)。具体架构和训练代码可以参考repo的代码。虽然只是在cifar10上的实验,但是效果已经足够惊艳。
如果没错的话可以印证
- 单层网络的表达能力是足够的,只是我们目前的优化算法并不能让单层网络找到合适解。不是模型容量的问题,是目前深度学习的优化算法碰上单层线性网络的天然局限。
- 深度非线性网络最终是可以转换成单层线性网络的,多层非线性网络其实是弥补了当前单层网络优化算法的缺陷。
解释和猜想
也许,可能又是我妄想了
这么多的非线性层也许只是为单个线性层找到更好的参数。最开始,参数只是随机的,非线性的存在和BP算法机制,让整体网络的每个参数个体能够像布朗运动一样“更自由”地改变参数。更确切地说,是随机初始化让前向传播有了一定随机性,比如ReLU后的数值,随机地为0。因果循环,这种随机的失活,又让反向传播只能随机地寻找路径让梯度流动(后面会提到,这是天然的子网采样,每个子网都有机会接受数据洗礼)。
训练阶段,堆叠纯非线性等价于一层线性层,即便堆叠再多,所有参数的更新轨迹都被“限定”了,训练前的初始值给整个模型留下了深刻的烙印并且贯穿整个训练过程。因为无论怎么更新,初始值已经决定了反向传播梯度分配的比例,W这个整体权重完全散失了“随机探索超流形的自由性”。
深度非线性网络和巨大的参数量,或许只是为优化过程买更多的彩票。参数越多,拓扑路径组合的子网络越多,W就能更加细致地,发挥群体力量更加高效地探索空间,最终只是为最后的单层网络权重服务(这个过程当然也很有可能造成冗余。这种“冗余”某种程度上是有意义的,可以用计算开销换取更快的学习速度,有粒子群优化的味道)
假如深度非线性网络的存在本身就是在为单个线性层自由随机地寻找无数可能性,网络最终可以缩并成一层,那这实在是太具有暴力美学的数学哲思了。
这并不是说模型可以无限压缩,深度非线性网络足够学到东西了我们才能继续转换成单层网络,也就是说单层网络开销有多大还是得由当前的深度非线性网络所决定。所以,如何设计高效的深度网络仍然是一个重要的课题,剪枝、蒸馏、神经架构搜索,动态推理网络,这些方向或许本质上被某个共同的”规则”所左右,未来可能统一,神经架构搜索(NAS)可能会被废弃(因为实在是太浪费了,NAS本质上是一种高度浪费的压缩算法)。
NAS设置的超网搜索空间实在是太大了,打个比方,就像把食物浅尝几口就丢掉。获得超网也并不需要这么多并行的层。最简单的VGG本身就是一个超网。我的意思是说,当训练阶段仔细探索子网,整个模型本身相对来说就是一个超网。与其尝一口,嚼几下就丢掉,还不如仔细咀嚼每一口。换言之:
- 需要充分地让子网接受数据训练的洗礼
- 用有限的计算资源在最简单的网络中创造更多数量的子网。当充分训练,子网便会“自动集成”成高性能的模型。
当有了足够的子网,便意味着有了足够的学习容量。但这还不够,每一个子网(它们之间也会共享部分,难分彼此)需要“相对独立”地进行学习。每个子网地能力足够强,整体网络性能才会更高。我们并不需要额外的操作,像ReLU这种网络就是天然的子网采样器。训练完毕,网络本身就是所有子网的集成。
上面说过,当所有子网模型都可以独当一面的时候,这就意味着整体网络足够健壮。那些剪枝算法只是回过头来再选取合适的子网,使其成为更小的独立模型。
所以有时候,我们大概不能片面地评估一个剪枝算法一定比另一个算法更好。因为当训练不充分,某些剪枝算法也会因为运气好(不好)(也是随机)采样到一些优秀(糟糕)的子网,这样的比较并没有太大的意义。除非它们自己能够证明自己是“精准定位”到优秀子网的。举个例子作类比,能不能打到好的猎物取决于山林资源条件如何,猎人身手如何。在贫瘠的山林里,再强的猎人也不见得收获会比菜鸟猎人更丰。明显只有资源足够丰富的情况下,猎人的身手才能成为关键。当然也会存在一种极端情况,山林资源过于丰富,再怎么菜鸡的猎人闭着眼睛乱射都能收获满满。这也对应下文所说的,随机剪枝完全足够,不逊色任何算法。
原则上应该让随机剪枝大量采样子网,证明网络的健壮性。再让其剪枝算法进行比较(比较采样的良率,搜索时间,性能,效率等)。神经架构搜索(NAS)本身就可以看作是剪枝算法,但是大多数情况下NAS的超网太大了,不能也根本没必要充分训练。再回过头来看,如果我们已经让一个模型具备良好的健壮性了,花里胡哨的剪枝算法也就没有什么太大的意义了。这个时候,随机剪枝就足够了,考虑到模型效率,必须是按照规则形状的随机剪枝。
VGG这种超网也可以变得强大。比如引进残差,vgg的子网数量就变得更多了。比如随机深度算法,让一些更小的子网能够独立且充分地接受数据洗礼。个人认为上述两条设计原则应该可以为轻量化模型设计提供一定程度的方向性指导。