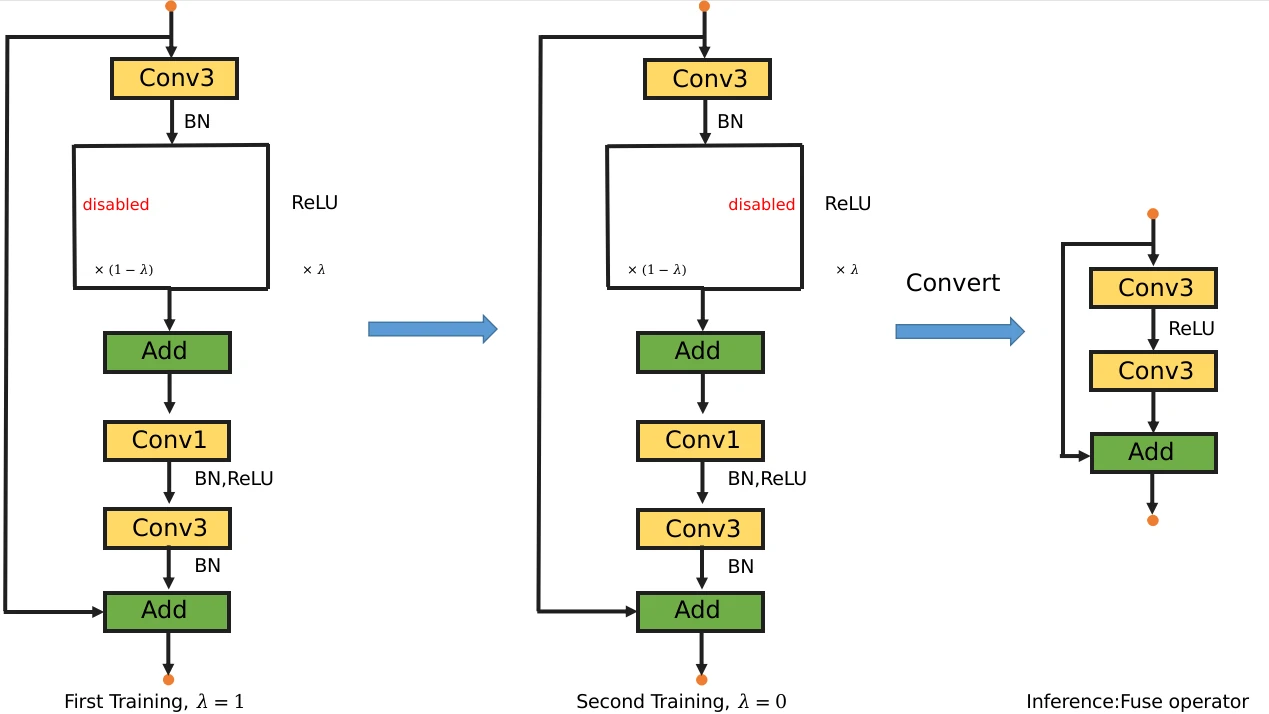
ReduceNet修正
由于之前对VanillaNet中可消解的激活函数错误解读,加上线性残差的结合让我上头,以及代码实现的错误,导致我陷入了一系列不切实际的妄想。
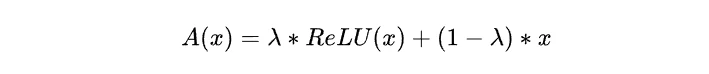
重新思考了一下实在没有必要用上述的LambdaReLU,毕竟无法保证它能有多少性能收益。Bottleneck 形式的conv+LambdaReLU+conv最终是要化做线性卷积的,目前我精力和时间非常有限,设备也只有笔记本的3060实在承担不了这种idea的不确定性。而且这种方式实际上和RepVGG,RepOPT似乎没有本质区别。它们的形式很像,作用我认为也是差不多的,即增加了一种精细调整学习率的设计维度(因为我们目前调整学习率的方式实在有点呆板和无可奈何)。类似引入了“多个随机种子”(精细调整部分结构的lr,scaling因子分配梯度,以及混合初始化),和普通的模型训练相比,多抽了几次彩票,这当然概率上会比较强。但是多抽几次彩票不代表就行一定比别的更优的随机种子(中奖面值更大的彩票)更强。这也部分解释为什么重参技术有几率提升性能,但是有时候又没有用。
于是改版的ReduceNet直接转向对depth shrinker的精简。这种转变的设计逻辑如下:
- 之前已经验证过了,bottleneck模块中间非线性的层增加宽度,模型性能100%提升。(很惭愧,之前把非线性的作用归于了LambdaReLU)。
- 既然lambda参数可以控制线性和非线性,那就先直接训练一个纯非线性的大网络好了。我们可以直接用bottleneck结构,直接实例化一个大网络。那小网络来自哪里呢,直接用lambda让原先的激活函数直接变成线性的identity mapping(就是直接暴力移除ReLU),线性融合两个卷积层就可以了。这样的好处是大网络和小网络在训练阶段直接共享相同的网络结构(除了那个由Lambda控制的激活函数)。小网络直接由相同的大网络转化而来,这本身就是极具价值的形式特点。让蒸馏过程和代码形式地都变得非常简洁优雅。上述方案再不济也能为最朴素的蒸馏提供一个简单的方案。当然,depth shrinker本身就具有类似的特点,论文并没有特别强调,虽然形式也稍微复杂一点,需要学习0和1 mask向量,甄别激活重要性。
新版本的ReduceNet追求更简洁的压缩,而不是像depth shrinker一样需要学习如何甄别激活重要性(通过引入一个mask参数,0或1),增加激活函数,并用自蒸馏的方式恢复性能。顺便帮助depth shrinker验证这些复杂的操作流程是否是必要的。
ReduceNet训练流程
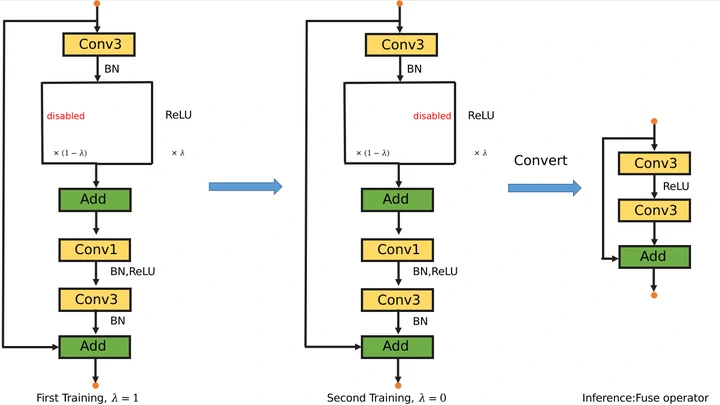
ReduceNet训练将分为两个阶段:
- 第一阶段scaler为1.0, LambdaReLU为纯粹的ReLU,利用前两层卷积bottleneck结构的expansion参数来增加模型规模以得到一个大模型的精度。
- 第二阶段scaler为0.,冻结分类层的权重(将来会继续冻结basic block中conv3,bn2,bn3的权重,或者直接采用蒸馏的方式)LambdaReLU为纯粹的identity mapping。这个时候,该网络相当于是第一阶段的大网络退化而来的小网络。我们通过冻结大网络的分类层权重,希望能够引导小网络得到较高的模型性能。
这里解释一下为什么要复用第一阶段的分类层(FC)。我们把分类看作是一个特征检索的过程,backbone用来学习特征,分类层用来匹配特征。分类层FC layer的权重矩阵的学习相当于为数据集的类别找到了一个中心向量或者类别向量(class vector)(当然其实还有bias权重,或许bias可以抛弃)。分类的过程相当于backbone生成的特征在和这些class vector进行匹配(计算相似度),最后经过softmax得到类别概率。
因此,这样设计基于一个直觉性的假设,即更大的模型往往能训练出更好的分类层。那么第二阶段就直接复用第一阶段分类层的权重就可以了,我们希望这些class vector可以引导第二阶段的小网络得到比较好的精度,简化蒸馏过程,不需要soft labels 和特征对齐(不需要再次使用大模型)。
我说可能哈,FC的重用已经相当于一种隐晦的dark knowledge了,后续会继续复用第一阶段的某些BN层,以继承一些信息。根据BN层的作用,这相当于某种程度上的特征对齐了。如果效果不行,就直接复用分类层并加入直接的特征对齐和soft labels。
ReduceNet继续精简pipeline
ReduceNet再不济,也可以采用原始的蒸馏方式,直接充当Depth Shrinker的阉割版本。再继续结合复用分类层和部分conv,bn可以在现有蒸馏框架的基础上大幅度减少训练成本。另外由于,大网络和小网络是结构相似的,完全可以对标通道剪枝算法,避开剪枝碰到的一些琐碎问题。
毕竟,大网络和小网络共享相同的结构,这样的设计形式对于一个简洁优雅的pipeline来说是非常诱人的,这一点已经足够有价值了。
图1的pipeline其实仍然有很大的冗余设计。第二阶段似乎没有必要保留两个线性卷积,因为直接用新的一层卷积直接代替就可以了(新的一层卷积形状和bottleneck的两层线性卷积融合后的样子相同)。这样子和VanillaNet,depth shrinker都有了非常大的区别,变成完全不同的东西了。最终设计如下图
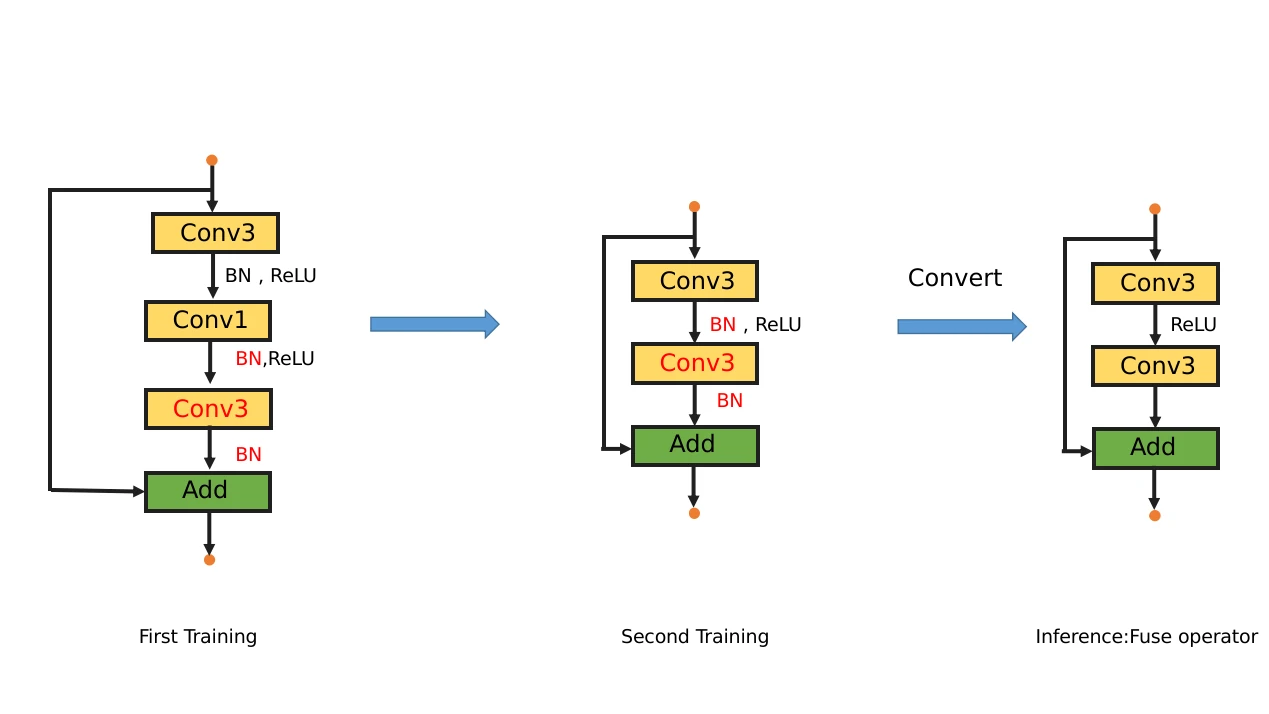
第二次训练红色的两个BN和Conv3继承自第一次训练的结果,参数冻结,仍然复用分类层。第二次训练新的小网络只需要更新第一层的conv3就可以了。比起图1,训练的时候不需要更大的网络,也不需要融合两个线性卷积算子(直接new一个)。因为直接引入一个卷积层比融合算子更简单,而且直接用小网络,大幅度降低了训练成本。但是最终小网络和大网络仍然是非常类似的,可以共享一个模型文件。
ReduceNet继续进化
考虑到在训练中增加一层卷积比较麻烦,新的方案改用类似LORA的结构,只不过是非线性的,并非用于微调。第二个conv3之前有两个分支,左分支是conv3和conv1的非线性bottleneck结构,右分支是一层比较窄的非线性conv3。示意图有时间再补上,或者结合这部分文字和上面的图自行脑补。
代码如下:
1 | class BasicBlock(nn.Module): |
在第二次训练的时候将self.scaler设置为0.,将bottleneck直接丢弃接可以了。这个和神经架构有点像了,训练用大网络,再“慢慢减少搜索范围精细训练小网络”。关键是怎么把大网络的知识转移给小网络。稳妥点的话可以直接使用成熟的各种蒸馏方案。ReduceNet增加的功能可能是:
- 复用Linear和Conv3权重和一些BN层以减少蒸馏成本和现有蒸馏框架兼容。
- 采用结构相似的大小网络,用expansion参数控制bottleneck结构进而控制大网络规模,小网络则是丢弃这部分bottleneck分支。
目前为止,ReduceNet和Depth Shrinker可以基本脱钩了。这个方案可以直接在一个网络实例上操作,不必加入各种琐碎的精细控制(比如,突然在网络中额外加入一层卷积,融合两个线性卷积等)
ReduceNet拥抱LORA进行蒸馏微调
当丢弃非线性bottleneck分支的时候,大网络就会退化成小网络,需要继续训练,通过某种方式恢复模型性能。这又何尝不是一种微调呢?上一个方案并没有实际引入LORA(bottleneck结构的两个线性卷积),其实当第二次训练小网络完全可以引入LORA分支来增加学习能力,事后融合就可以了。即冻结直接所谓的全部小网络,用LORA分支来进行微调学习。这种微调学习可以结合大网络进行正常的蒸馏,将非线性的“知识”转移到LORA分支里。注意,LORA分支的后面是带有relu的,所以并不是在用线性函数逼近非线性函数,这样的效果大概率是不好的。此时本质上是一层非线性(LORA两层卷积可以融合为一层)在逼近两层bottleneck的非线性卷积。
这其实又将LORA,ControlNet,RepVGG的思想又联系在一起了,不能保证有很大的效果,至少可以”抽更多的彩票”来增加中奖的几率。最后,这个LORA分支又可以视情况引入华为VanillaNet中的LambdaReLU(deep training strategy),训练过程中由非线性逐渐转为线性,不影响最后的融合过程。
另外,这里的LORA其实稍微有点不同,我们是要增加参数,而不是减少参数,所以可以稍微肆无忌惮地采用通道先增加后减少(原版LORA相反)的bottleneck结构。
代码链接
[repo] GitHub - ohmydroid/reducenet
一直在改进方案,一天换了4个思路。代码功能还没有完全实现,只能文字记录一下。目前只冻结了分类层和 BN 层,还需要继续调参和修正细节的设计。
新版本ReduceNet和VanillaNet基本没什么关系了,和depth shrinker貌似也变得截然不同。文章刚开始的思路有点冗余,但是我都保留下来,以方便理解思路的转换过程。
ReduceNet目前整体是框架设计,可行性是建立在现有成熟方案基础上的。只不过我们在形式进行了精简和整合。
而且,现在的方案把蒸馏和神经架构搜索桥接起来了。大模型相当于神经架构的超网,小模型相当于子网。我们通过蒸馏,用结构相似的大模型把性能转移到小模型,目标很明确。而神经架构搜索的痛点是根本没有训练整个网络,而是不断采样子网,如何找到一个有效的子网也主要靠算力搜索,资源约束,运气以及某些复杂的预测评估算法,相对显得有点漫无目的。最重要的完全不知道要花费多少资源才能得到期望的性能。ReduceNet则完美解决了性能,资源边界(用expansion控制bottleneck得到大模型性能)和目标导向的问题(让大模型的性能转移给小模型,权重复用,soft labels,特征对齐等手段可以一一用上,直到小模型性能“饱和”)。
最近太累了,我又鸡血一天。这还不是最终的设计版本,得闲待续。仍然不排除会有弱智的代码错误。