本篇学习报告基于2021年发表在《Automation in Construction》上的论文《Effects of dataset characteristics on the performance of fatigue detection for crane operators using hybrid deep neural networks》。此论文旨在探索和分析适用于起重机操作员疲劳检测的数据集特征和相应的数据采集方法,进一步为起重机操作员数据集的收集提供指导。针对疲劳检测,论文提出了一种结合**卷积神经网络(Convolutional Neural Network, CNN)和长短期记忆网络(Long Short-Term Memory, LSTM)[1]的混合深度神经网络结构。为了建立统一的评估标准,作者重新标记了三个公开的车辆驾驶员数据集NTHU-DDD[2]、UTA-RLDD[3]和YawDD[4]**,并分别训练相应的疲劳检测模型。训练的模型用于评估起重机操作员在模拟起重机操作场景下的面部视频疲劳状态。结果表明,为起重机操作员建立大型公开疲劳数据集时,需要考虑不同的影响因素。
研究背景和内容
尽管疲劳或嗜睡检测是一个重要的研究课题,并且成功的解决方案已经应用于车辆驾驶等领域,但很少有研究开发出起重机操作员的疲劳检测和报警系统。如今,疲劳检测有几种技术:量表测量、车辆性能测量、生理测量和行为测量。对于量表测量,疲劳程度根据驾驶员的自我评估进行评估,这种方式依赖于受试者在特定时间提供的答案,不能准确及时地测量疲劳的轻微变化。对于车辆性能测量,它们受外部因素和操作员操作习惯的影响很大。对于生理测量,虽然生理信号对疲劳状态是敏感的,但这些方法具有侵入性(即需操作员佩戴传感器),在起重机操作场景下不易实现。而行为测量使用非侵入式设备(如照相机),基于计算机视觉技术识别眨眼、打哈欠和点头等面部表情分析特征,从而进行疲劳检测,不会影响操作员的工作,且随着深度神经网络的发展使之能够获得较高的精度。
由于起重机操作员和车辆驾驶员之间面部特征和头部运动模式的差异,公开的驾驶员疲劳检测方法很难直接用于起重机操作场景下的疲劳检测。其次,公开的驾驶员疲劳数据集之间的收集、测试和标记方式不同,难以比较多源数据集的综合准确性。此外,没有关于起重机操作员的大型、公开和真实的数据集。目前面临的挑战是确定哪些可用数据集的特征和收集方法最适合起重机操作员的疲劳检测。
因此,该论文的研究目的是:
- 对比真实疲劳表情和假装疲劳表情对疲劳检测性能的影响;
- 对比以不同分段级别(帧级别或分钟级别)作为单位的手工标签对疲劳检测性能的影响;
- 对比不同面部姿势变化和摄像头位置(侧视图或前视图)对疲劳检测性能的影响;
- 探索和分析哪种数据集特征和相应的数据采集场景适合起重机操作员的疲劳检测;
- 为起重机操作员(尤其是塔式起重机操作人员)建立大型公开真实疲劳数据集提供指导。
疲劳检测方法框架
该论文提出了一种混合深度神经网络架构,以探索和分析哪些数据集的特征和相应的数据采集方法适合起重机操作员的疲劳检测。它是结合CNN和LSTM进行疲劳检测而设计的。首先,采用这种混合深度神经网络架构对重新标记的三个数据集进行训练:NTHU-DDD、UTA-RLDD和YawDD。然后,使用训练后的模型评估起重机操作员在模拟起重机操作过程中捕获的面部视频的疲劳程度。
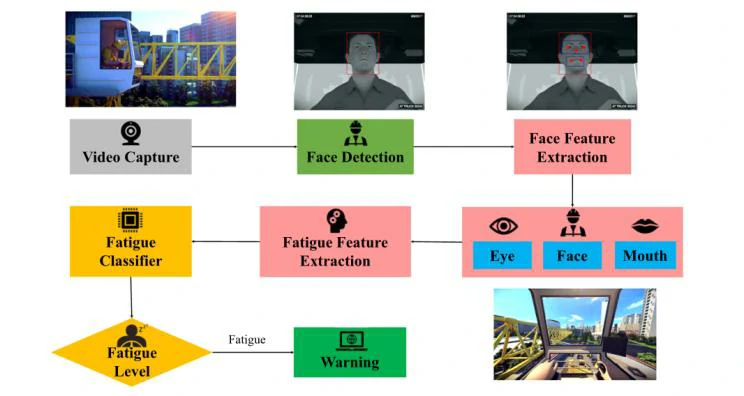
论文提出的混合深度神经网络的工作流程如图1所示。工作流程包括以下几个步骤:
- 采集视频并对视频进行处理,检测操作员的人脸。同时通过检测获得相应的眼睛、嘴巴和头部区域的相应关键点坐标。
- 提取这些区域中包含的操作员有关疲劳的特征,用于训练疲劳分类器,以实现疲劳水平估计。
- 分析这些提取的信息,以评估是否需要在早期阶段发出疲劳警告。
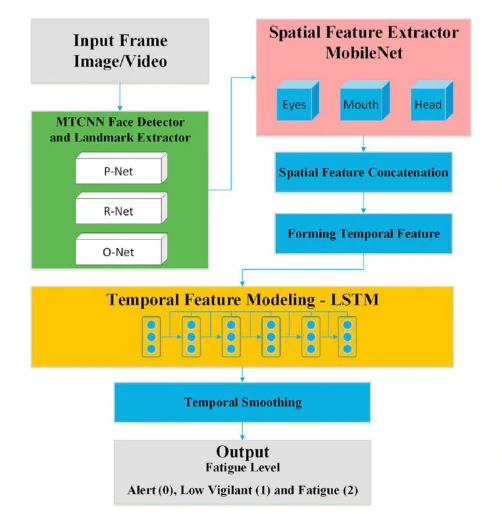
提出的混合深度神经网络结构如图2所示,主要由3个主要模块组成:
(1)人脸检测器
文章中,作者使用多任务级联卷积神经网络(Multi-Task Cascaded Convolutional Neural Networks, MTCNNs)[5]在视频的每一帧中获取人脸区域的边界框和相应的人脸关键点坐标。进一步从面部区域提取眼睛、嘴巴和头部区域。
(2)空间特征提取模块
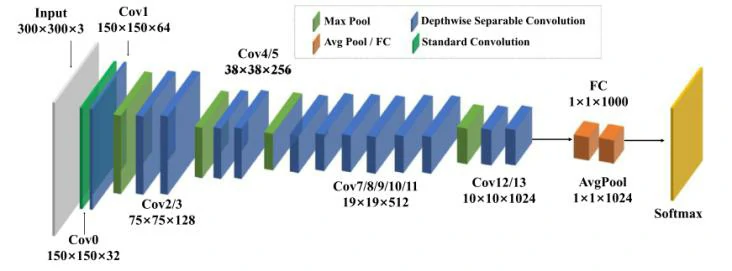
空间特征提取的方法是学习一个基于CNN的模型,用于从各个帧的图像中提取人脸特征。文章中采用MobileNet[6]作为主要网络来生成特征提取模型。MobileNet及其变体的引入能够解决速度优化问题,因为这类网络的主要组成部分是深度可分离卷积,该卷积比标准卷积具有更少的参数和计算成本。图3展示了改进的MobileNet架构,其中包括13个卷积层、5个最大池化层、1个平均池化层和一个完全连接的前馈网络层。
(3)时间特征建模模块
虽然特征提取器可以根据空间特征预测每帧图像的疲劳程度,但仍然难以区分具有高度时间依赖性的轻微动态变化,比如打哈欠和说话。因此,在时序帧中考虑时间信息是有必要的。为此,作者采用LSTM对时间特征进行建模。LSTM是一种特殊的递归神经网络,可用于分析时间和空间序列数据中的隐藏序列模式。由于其独特的输入、输出和遗忘门结构,它能够学习长期依赖关系,以控制长期序列模式识别。文章提出的混合网络中使用的LSTM通过门的组成来控制在每个时间帧中给出的信息量,以避免长期依赖。
方法实现
疲劳数据集描述

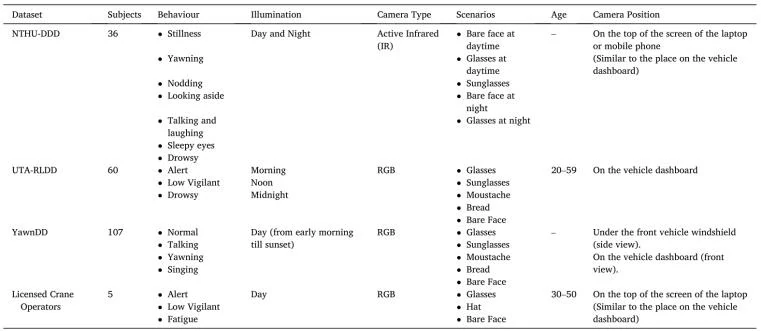
在该论文工作中,采用了3个车辆驾驶员数据集作为训练数据集和验证集用于疲劳检测,分别是UTA-RLDD、NTHU-DDD和YawDD,如图4所示。每个数据集有自己的收集方法和场景、标签模式、数据集大小以及疲劳是否“起作用(active)”的面部表情。作者使用他们来寻找适合起重机操作员疲劳检测的数据集特征。此外,由于缺少真实的起重机操作员疲劳数据集,作者利用Unity3D游戏环境创建起重机模拟操作场景,并邀请持有执照的起重机操作员拍摄视频,以获得起重机操作员的疲劳数据作为测试集。各数据集的详细信息如表1所示。
重新标记工作流程与标记原则
由于现有的数据集标签的详细程度无法在时间维度上以高精度识别疲劳状态。其次,多个数据集之间也没有统一的评价标准和标记原则。为了解决该问题,作者对3个公开数据集进行重新标记,分别以每帧和每分钟作为分段单位,并提出了重新标记工作流程和统一的重新标记原则。
数据集重新标记工作流程包括以下步骤:
- 视频变换:通过Python脚本将视频转换为帧序列,以在帧级别中重新标记数据集。
- 状态和行为描述:根据帧索引,在每个帧中手动标记不同的面部状态和行为。它们的具体状态和行为由人工记录。
- 疲劳程度标记:将经过状态和行为描述的图像转化为三个疲劳水平,即警惕、低警惕和疲劳。
为了建立统一的重新标记原则,作者在现有标记方法基础上开发了一种改进的方法。将疲劳程度分为三个不同的级别,其定义如下:
- 警惕(标记为0):受试者没有困倦的迹象。
- 低警觉(标记为1):受试者出现一些困倦迹象或困倦迹象的微妙情况,但无需努力保持警惕。
- 疲劳(标记为2):受试者出现困倦甚至极度困倦的情况,需要尝试不主动入睡。
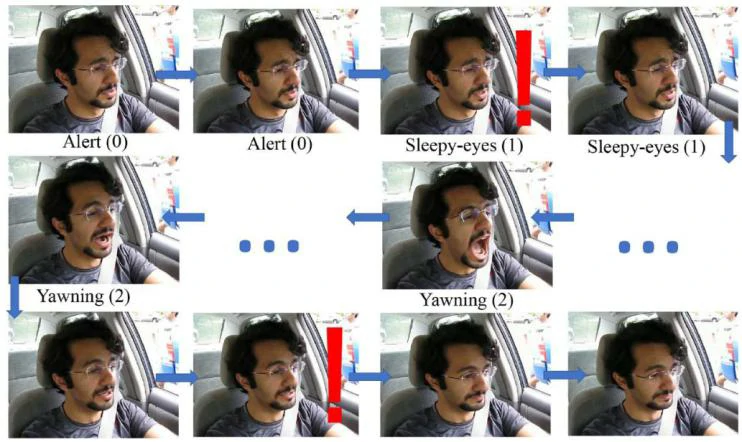
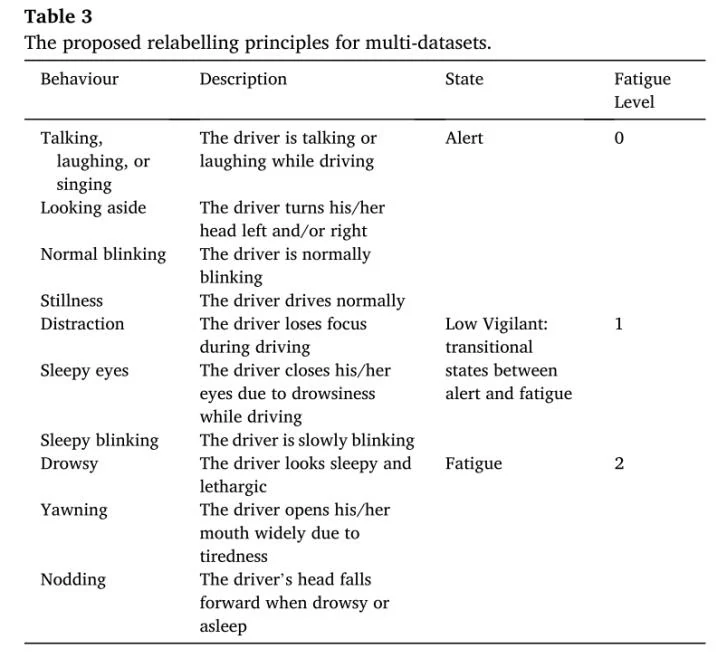
图5展示了重新标记序列帧的示例。将视频转换成序列帧图像后,每个帧通过特定行为进行描述,如警惕、睡眼、打哈欠,如表2所示。描述进一步转化为三个疲劳等级,用于进一步的疲劳检测训练过程。采用相同的方法在分钟级别重新标记视频剪辑的帧。
训练与测试
在实验中,作者分别对所提出的两个模块,即空间特征提取模块(MobileNet)和时间特征建模模块(LSTM)进行训练和评估。然后,结合两个经过训练的模块对整个体系结构进行测试。3个公开数据集中的所有视频都被剪辑成固定长度的视频片段,然后随机选择70%作为训练集,30%作为验证集。
评价指标
论文中,从准确度(Accuracy)和损失(Loss)两个方面对提出的疲劳检测方法进行定量评估。其中,准确度是指正确分类的整个视频(而不是单个视频片段)的百分比;损失计算中,使用平均绝对误差(Mean Absolute Error, MAE)作为损失度量。
实验结果与讨论
提出的方法在数据集上的性能评估
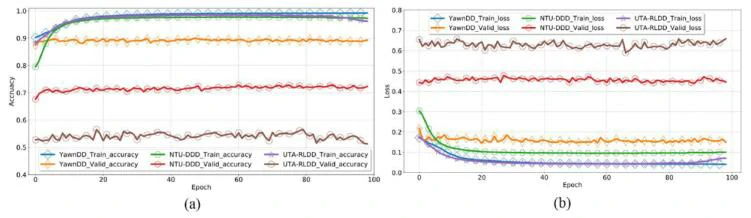
图6展示了3个数据集的训练集和验证集的总体准确度和损失。提出的混合深度神经网络结构分别在UTA-RLDD、NTHU-DDD和YawDD的验证集上达到了54.71%、72.76%和87.52%的准确率。结果表明,如果训练需要最大限度地提高检测性能,那么针对每个数据集的学习体系结构的微调是不可避免的。不过,提出的混合深度神经网络为比较设定了基线,以有效提取疲劳检测的重要特征。
LSTM中窗口大小和层结构的影响
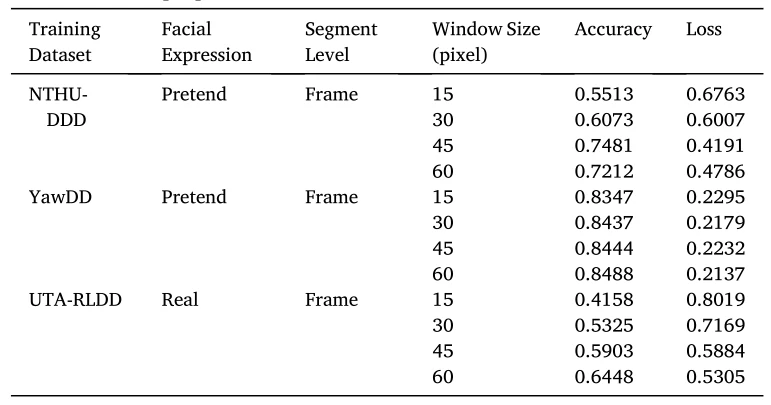
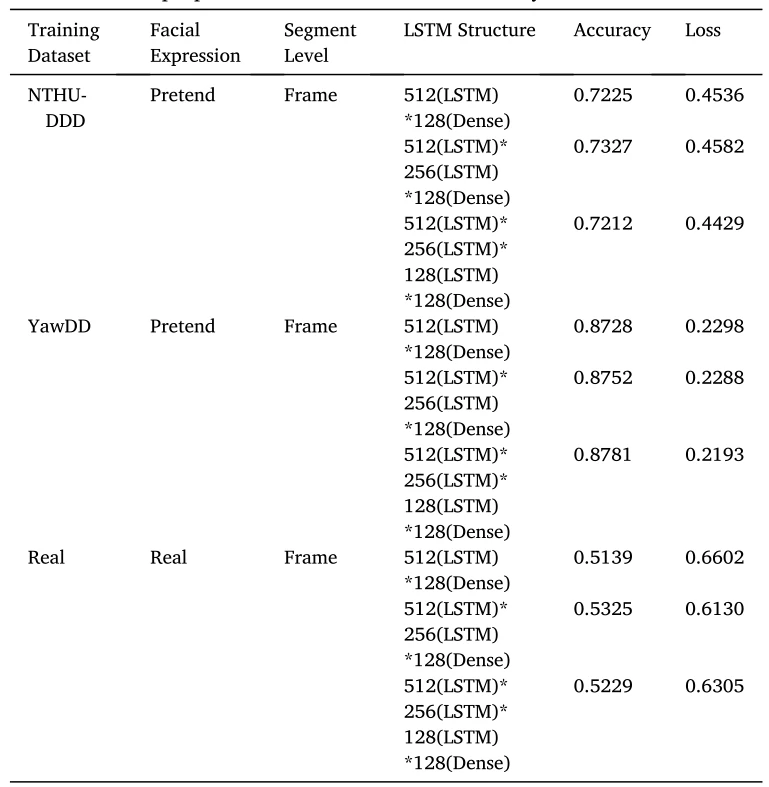
表3显示了在3个数据集上采用不同输入窗口大小的网络结构对网络性能的影响。在NTHU-DDD和UTA-RLDD中,如果LSTM的窗口增大,则检测结果的准确度将显著提升,但会减慢训练速度。相反,输入窗口减小,准确定降低,但是网络训练速度加快。而对于YawDD,所提出的网络结构性能没有显著提高。表4展示了具有不同LSTM层结构的网络对网络性能的影响。由此可见,在3个数据集中,简单地增加或减少LSTM中的层数并不能有效影响性能。综上所述,为了提高疲劳检测的性能,扩大LSTM的窗口大小能够获得更高的准确度。
不同分段级别的标签以及真实(或假装)表情的影响


表5展示了3个数据集在不同分段级别(帧级别或分钟级别)和面部表情方法下的平均损失和准确度。针对不同的分段级别,训练模型在NTHU-DDD(帧级别准确度为72.76%,分钟级别为67.54%)和YawDD(帧级别准确度为87.52%,分钟级别为72.63%)上的效果更好。这两个数据集都包含真实或模拟驾驶环境中假装的面部表情情况。而训练模型在UTA-RLDD上的效果较差(帧级别准确度为54.71%,分钟级别为48.05%)。该数据集包含日常生活中细微的面部特征,轻微的疲劳表情和行为在训练过程中表现出较少的显著特征,这可能是导致准确度较低的原因。针对不同的分段级别,3个数据集的结果都表明,帧级别的标签比分钟级别的标签具有更高的准确度。
进一步,作者将由帧级别标签训练的模型进行交叉验证,即将训练模型放在另外两个数据集上进行测试,以比较模型的适用性,结果如表6所示。值得一提的是,通过UTA-RLDD训练的模型在YawDD上的测试准确度高达80.27%,高于UTA-RLDD的原始验证集。结果表明,在真实场景下捕捉到的细微表情仍然是必要的,因为细微的面部特征对检测疲劳迹象更为敏感。
摄像机位置的影响

YawDD包含由不同摄像机位置捕获的两组视频,第一组为驾驶员的前视图;第二组为驾驶员的侧视图。可用于测试,以确定合适的面部视频捕获角度。如表7所示,从驾驶员前视图中捕获的视频中进行疲劳检测的准确度为89.34%,高于侧视图中的检测准确度(82.23%)。结果符合自然期望,即捕捉的面部越多,检测的特征越多,则能够提高疲劳检测准确度。尽管如此,在本实验中,经过训练的模型针对侧视图的检测性能仍然达到了较高的准确度。
光照条件的影响

NTHU-DDD包含来自白天和夜间不同光照条件的同一人的视频。视频通过红外摄像机捕获。使用提出的网络框架对该数据集进行疲劳检测的部分结果如图7所示。论文提出的方法对于白天的视频检测效果良好(如图7(a)和(c)所示),而在夜间会出现无法正确检测疲劳水平的情况(如图7(b)和(d)所示)。尽管如此,在许多情况下,使用红外摄像机捕捉面部视频仍然可以成功地进行疲劳检测。
起重机操作员在模拟起重机操作场景下的评估
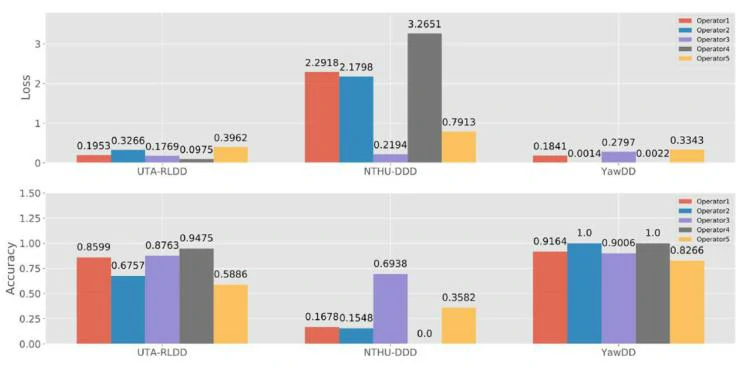
作者邀请了5位持有执照的起重机操作员在模拟的起重机操作场景中进行测试,以验证提出的疲劳检测模型的性能。图8显示了起重机操作员进行疲劳检测的平均准确度和损失。总体来说,由具有明显面部特征的YawDD训练的模型达到了最佳的检测准确度和最低的损失。同时,具有细微面部特征的UTA-RLDD训练的模型效果也相对较好。而NTHU-DDD训练的模型准确度较低且损失较大的原因可能是该数据集中包含部分低光照条件下的视频,从而导致偏差的出现。这表明,可能需要在不同的光照条件下(白天和夜间)进行单独的训练,或收集更多视频进行训练和评估。
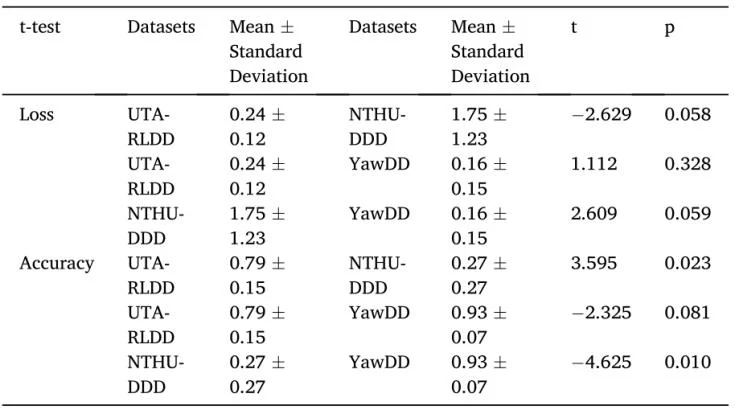
为了进一步确定起重机运行场景下3个训练模型的检测性能是都存在显著差异,作者使用配对样本t检验确定损失和准确度方面的显著性,如表8所示。对于损失,NTHU-DDD和UTA-RLDD以及NTHU-DDD和YawDD的训练模型性能之间的p值为0.058和0.059,这意味着NTHU-DDD和另外两个数据集之间的偏差很大。同样地,对于准确度,NTHU-DDD和UTA-RLDD以及NTHU-DDD和YawDD的p值都小于0.05,这显示了它们之间的显著差异。结果表明,NTHU-DDD的训练模型确实会导致起重机操作员的疲劳检测性能降低。此外,虽然结果显示UTA-RLDD和YawDD之间的准确度和损失在性能方面没有显著差异,但进一步证实了细微面部特征(UTA-RLDD中的特征)在起重机操作场景下的重要性。
总结
该论文基于3个公开数据集NTHU-DDD、UTA-RLDD和YawDD的车辆驾驶员的面部视频,提出了一种混合深度网络结构,将CNN和LSTM结合起来检测疲劳状态。为了确定起重机操作员疲劳检测所需数据集的特征和合适的数据收集方法,在3个数据集上进行了对比实验,并通过模拟起重机操作环境对起重机操作员的面部视频进行了疲劳检测测试。
实验结果表明,所提出的学习结构对起重机操作员的疲劳检测是有效的。在数据集中,实际或模拟驾驶环境下具有明显疲劳面部特征的数据集比在室内环境中具有细微疲劳面部特征的数据集更易于检测。然而,细微的疲劳面部特征仍对准确度有积极作用。此外,不同分段级别的标签显著影响检测性能。在检测操作员疲劳时,通过帧级别手工标记的训练模型比分钟级别手工标记的模型检测准确性更高。对于面部姿势的变化,面部侧视图比前视图更难准确检测受试者的疲劳程度。为了避免复杂照明的影响,作者建议红外摄像机与RGB摄像机一起用于夜间场景,并在不同照明条件(白天和夜晚)下分开训练模型。
该论文研究中也存在一些局限性。首先,对比的结果是基于模拟的起重机操作场景。起重机操作员在实际操作场景下的疲劳数据集可能还有其他影响因素,应通过进一步评估确定。其次,由于在重新标记过程中需要投入大量的精力,因此3个数据集中仍有小部分的数据未被重新标记。数据集应在帧级别完成完整的重新标记,以实现统一的评估标准。第三,由于现有数据集提供的信息有限,研究中未考虑参与者的特征,如年龄、驾驶经验年限和性别。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10862
[1] Greff K, Srivastava R K, Koutník J, 等. LSTM: A Search Space Odyssey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(10): 2222–2232.
[2] Weng C-H, Lai Y-H, Lai S-H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network[A]. 见: C.-S. Chen, J. Lu, K.-K. Ma. Computer Vision – ACCV 2016 Workshops[M]. Cham: Springer International Publishing, 2017, 10118: 117–133.
[3] Ghoddoosian R, Galib M, Athitsos V. A Realistic Dataset and Baseline Temporal Model for Early Drowsiness Detection[A]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)[C]. Long Beach, CA, USA: IEEE, 2019: 178–187.
[4] Abtahi S, Omidyeganeh M, Shirmohammadi S, 等. YawDD: a yawning detection dataset[A]. Proceedings of the 5th ACM Multimedia Systems Conference on - MMSys ’14[C]. Singapore, Singapore: ACM Press, 2014: 24–28.
[5] Zhang K, Zhang Z, Li Z, 等. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499–1503.
[6] Howard A G, Zhu M, Chen B, 等. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. arXiv:1704.04861 [cs], 2017.