原文
ResNet
基本信息
标题:Deep Residual Learning for Image Recognition
时间:2015
论文领域:深度学习,计算机视觉
论文链接:https://arxiv.org/abs/1512.03385
pass 1
论文标题中文意思是:深度残差学习的图像识别。论文标题指出了关键词:Residual Learning,残差是数理统计中常用到的一个词。
本篇论文作者全部为中国学者,这四个人现在都很有名了。一作也是 CVPR 2009 的最佳论文获得者,目前在Facebook AI Research任研究科学家;二作、三作当时是微软亚洲研究院的实习生,目前二作在旷视工作,三作在蔚来工作,通信作者目前是旷视研究院院长。

下面是论文摘要,摘要总共11句话:
- 第1句话就提出了论文要解决的问题,更深的神经网络很难训练。
- 第2、3句介绍了论文使用的方法,提出了一个残差学习框架使深的神经网络更容易训练,网络中的层对层输入的残差函数进行学习。
- 4-7句为在ImageNet上的比赛结果,论文设计的152层网络取得了3.57%的错误率,获得了比赛第一名。
- 第8句,作者在CIFAR-10数据集上进行了100层和1000层网络的实验分析。
- 9-11句,其它比赛结果,在ILSVRC和COCO 2015比赛上获得了ImageNet检测任务,定位任务,COCO检测和分割任务的第一名。

由于CVPR2016要求提交论文正文在8页以内,从摘要可以看出,作者做的实验是比较多的,因此本篇论文没有结论部分。
pass 2
Introduction
总共9段。第一段介绍故事背景,第二段引出第一个问题:堆叠更多的层数以后网络是否学习效果更好?但是堆叠更多的层后往往会遇到梯度爆炸、梯度消失问题,会从一开始就阻止收敛。好在这个问题可以通过归一化初始化或中间层归一化来解决。第三段介绍了另一个问题:当网络开始收敛时,往往会出现退化现象。随着网络深度的增加,准确率趋近饱和,然后迅速下降。意外的是,这不是由于过拟合造成的,更深的模型反而会有更高的训练误差。
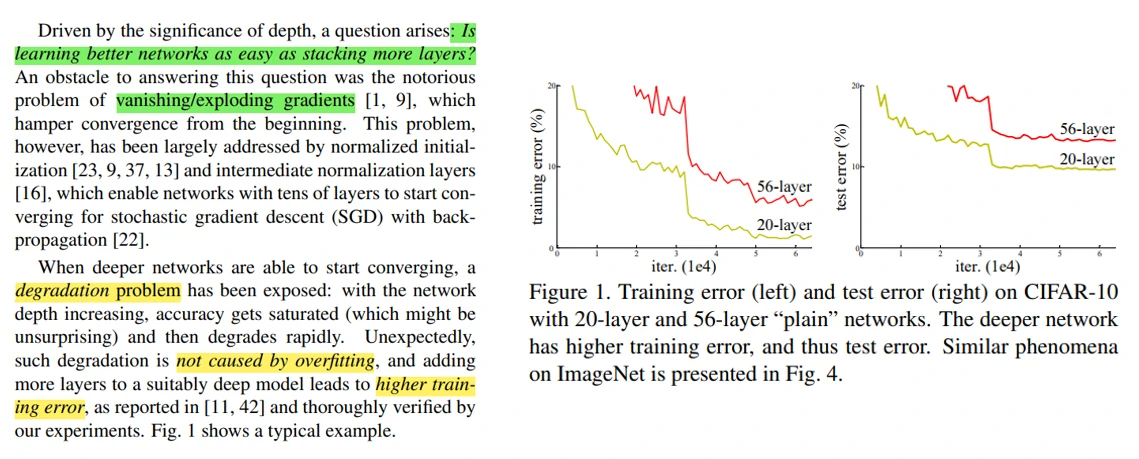
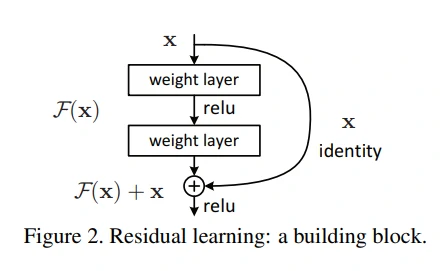
第4-6段,为了解决深度学习的退化问题,作者提出了深度残差学习框架,让网络层去拟合残差映射。如果我们想要得到的映射为 H(x),则我们让添加的非线性网络层去拟合残差映射 F(x) = H(x) − x,则原始的映射就可以写成 F(x) + x。残差映射的实现可以通过图2所示的连接块实现,跳跃连接是一个恒等映射,没有引入额外的参数和计算复杂度,整个网络很容易实现(最初ResNet是使用Caffe库实现的)。
后面三段是本文设计的网络在ImageNet、CIFAR-10、COCO数据集上的实验结果,大量的实验结果表明作者设计的残差学习框架的通用性,一方面不仅使得网络更容易优化,另一方面随着网络深度的增加,网络复杂度并没有明显增加,准确率却会提高很多。
Deep Residual Learning
这里要理解各种ResNet是如何形成的。网络设计原则为:(1)对于相同的输出特征图尺寸,卷积层具有相同数量的卷积核;(2)如果特征图尺寸减半,则卷积核数量加倍,以便保持每层的时间复杂度。通过步长为2的卷积层直接执行下采样。下面以ResNet-34为例进行介绍:
- 首先是第一个卷积层,卷积核大小为 7 × 7,卷积核个数为64,步长为2
- 然后是第二个卷积层,卷积核大小为 3 × 3,卷积核个数为64,步长为2
- 接着是三个残差连接块,每一个连接块由两层卷积网络组成,卷积核大小为 3 × 3,卷积核个数为64
- 然后是四个残差连接块,每一个连接块由两层卷积网络组成,卷积核大小为 3 × 3,卷积核个数为128
- 接着是六个残差连接块,每一个连接块由两层卷积网络组成,卷积核大小为 3 × 3,卷积核个数为256
- 然后是三个残差连接块,每一个连接块由两层卷积网络组成,卷积核大小为 3 × 3,卷积核个数为512
最后是全局平均池化层和具有softmax的1000维度的全连接层,这样整个网络包含 1 + 1 + (3 + 4 + 6 + 3) × 2 = 34 个卷积层。尽管网络深度相比VGG-19要深了许多,但是FLOPs只是VGG-19的18%左右。
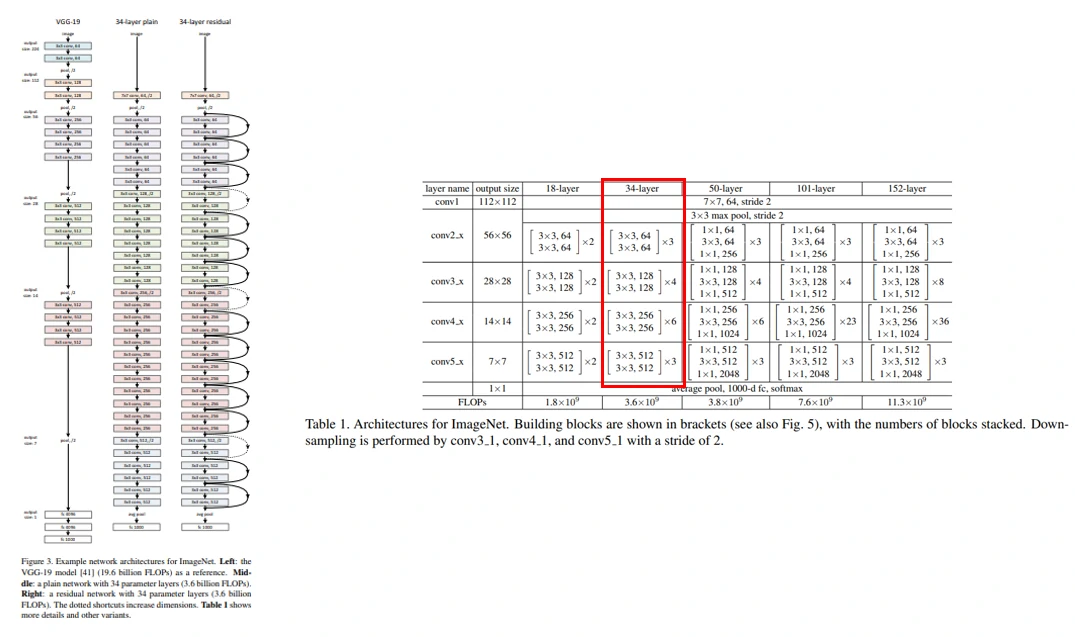
从表1可以看到,ResNet-18和ResNet-34具有相同的残差连接块,每个连接块包含两个卷积层。而ResNet-50/101/152的每个连接块包含3个卷积层。作者把这种连接块称为bottleneck,这里主要使用了1 × 1的卷积核,主要是用于匹配特征图维度以及从实践出发能够承担的起训练时间。(之前听过论文通信作者的一个报告,据说这个网络训练时间为一个月,具体一个月是指纯训练还是指训练+测试+调参就不太清楚了)。

Implementation
作者是参考AlexNet和VGG来进行训练。首先对图像的短边进行尺度扩大,扩大到[256, 480],然后和AlexNet一样,随机选择 224 × 224 大小的图案。作者在这里使用到了batch normalization(BN)技术;然后作者按照自己的另一篇文章来进行初始化并从零开始训练(如果对作者之前工作不了解的话还要再去看作者的文章了解如何对网络初始化,对第一次看到这篇文章的读者来说增加了阅读难度,不过作者可能也是因为受到篇幅影响,不想再过多介绍)。梯度下降使用了SGD,mini-batch大小为256,总共进行了 60 × 10^4 次迭代(目前很少有这样的写法了,都是介绍训练了多少个epochs)。为了得到最好的实验结果,作者在多个尺度上进行评估,然后取平均分。

Experiments
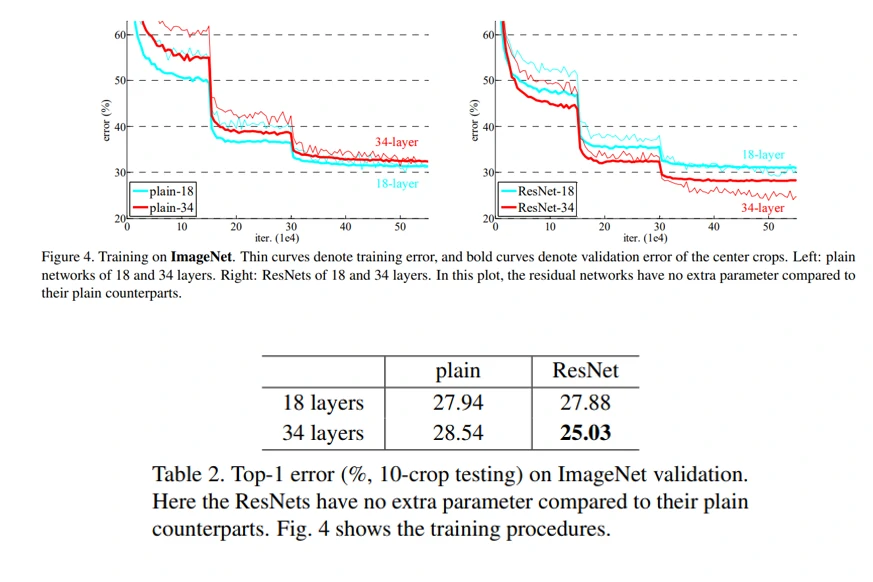
从论文中可以看到作者做了大量实验。首先是ImageNet Classification,首先评估了plain-18/34两个网络,从表2可以看到,plain-34网络比plain-18有更高的错误率,从图4左图也可以看到,在训练过程中,出现了退化现象,随着网络深度的增加,训练误差反而变大。作者在论文中解释到:退化现象应该不是梯度消失引起的,因为整个训练使用了BN来训练,也查验了反向传播时梯度幅值也是正常的,作者怀疑可能是因为更深的网络有着更低的收敛速度,影响着训练误差的减小,这个问题未来会进一步研究。
接着是ResNet-18/34两个网络的评估,从表2和图4右图可以观察到三个现象:
- 网络越深,训练误差反而越小,退化问题可以通过残差学习得到解决
- 与plain-34网络相比,训练误差下降了3.5%,随着网络深度的不断增加,网络性能进一步提高
- 与palin-18/34网络相比,残差网络收敛速度更快
然后是恒等跳跃连接和投影跳跃连接的对比,可以看到三种连接都有助于提高网络性能,但是为了不增加网络结构的复杂度,作者这里主要选择恒等跳跃连接进行后续的实验。
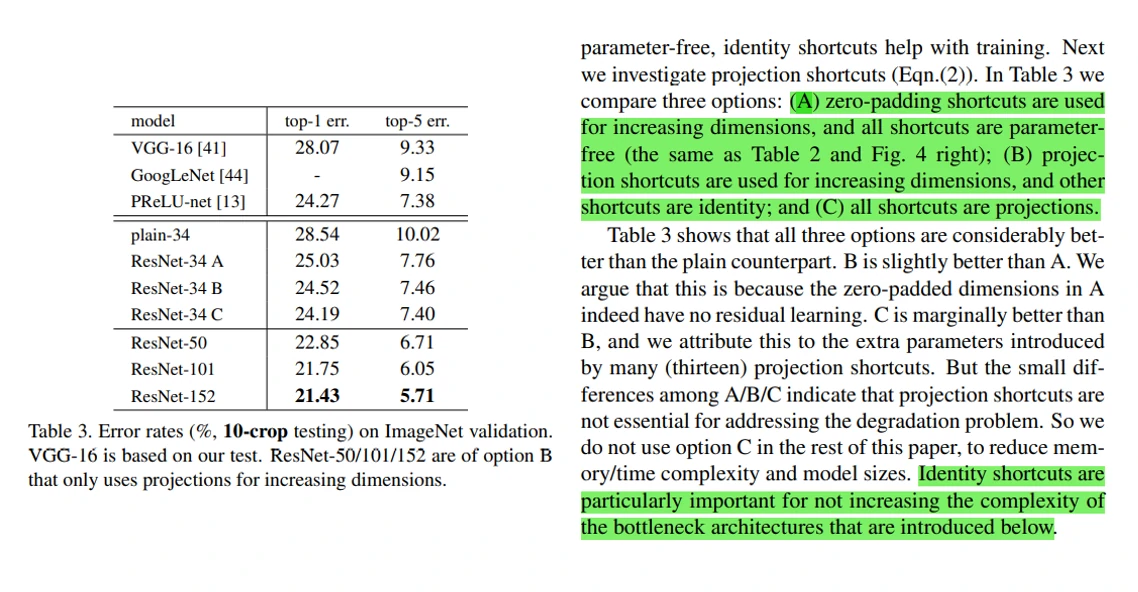
下面是ResNet-50/101/152网络的评估,首先可以看到,尽管网络深度不断增加,但是复杂度依然低于VGG-16/19。随着网络深度的不断增加,错误率不断下降,同时在训练过程中也没有出现退化现象,在单个模型上取得了4.49%的错误率,在ImageNet2015比赛上,通过集成6个不同的模型,取得了3.57%的错误率(这是一个很了不起的结果,因为ImageNet数据集在人工标注时,可能就会有1%的错误率。)
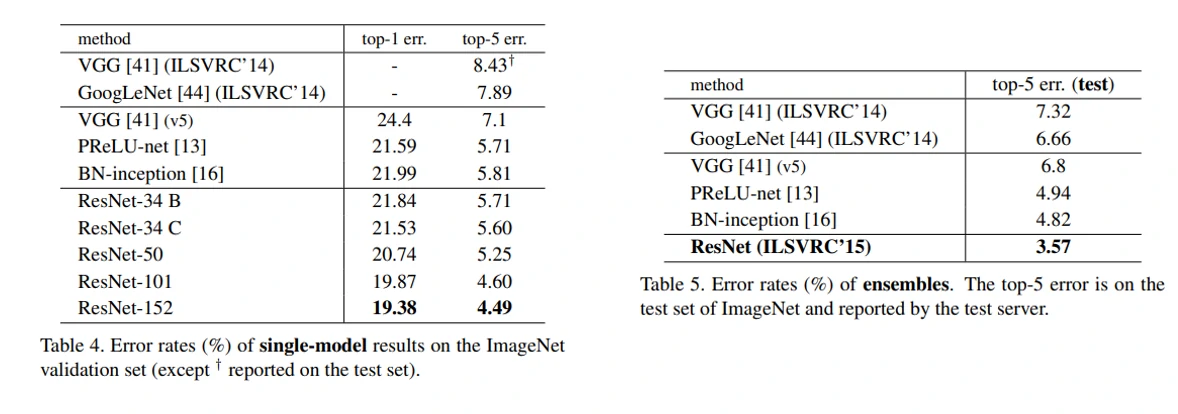
最后总结一下,ResNet解决了网络训练退化的问题,找到了可以训练更深网络的办法,目前已经成为了深度学习中最重要的一种模型。
从梯度的角度对残差学习理论进行阐述
这里使用吴恩达老师的讲义来进一步补充。
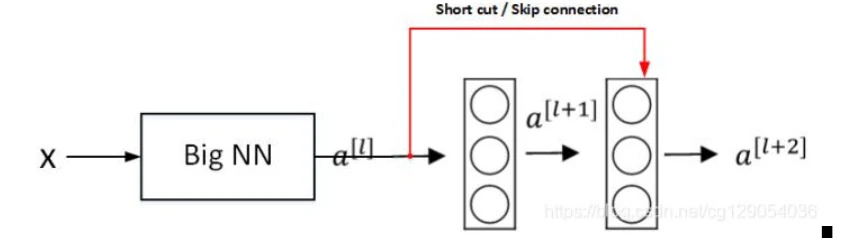
假设有一个很大的神经网络,其输入为X,输出为a[l]。为这个神经网络再添加残差块,输出为a[l+2]。假设整个网络中都选用 ReLU 作为激活函数,因此输出的所有激活值都大于等于0。a[l]与a[l+2]之间的函数关系为:
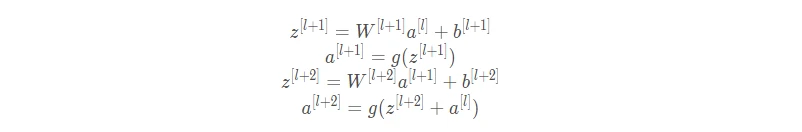
当发生梯度消失时,即残差块网络没有学到有用信息,W[l+2] ≈ 0,b[l+2] ≈ 0,则有:
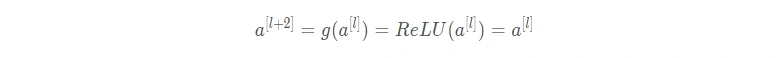
因此,残差块的使用不会降低网络性能。而如果没有发生梯度消失时,训练得到的非线性关系会使得网络性能进一步提高。(关于残差网络的理论更深解释,也有很多相关的研究,感兴趣可以查阅对应文献。)