FAIR于近日(2022年1月13日)提出了仅依靠卷积神经网络构建的ConvNeXt[1],这个依靠CNN且以传统ResNet为出发点搭建的模型在ImageNet的舞台上超过了Swin-Transfromer而引起广泛关注。(ConvNeXt与Swin-Transfromer基于ImageNet1K/22K数据集的对比如在下图1[1]。)
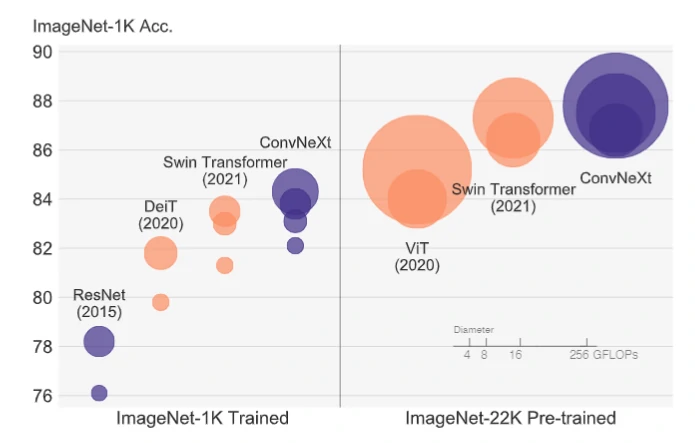
图1 在ImageNet上各网络准确率对比
ConvNeXt的主要设计思路是模仿Swin-Transfromer的设计策略,同时“取其精华,去其糟粕“,整个优化方案可参考下图2[1]。
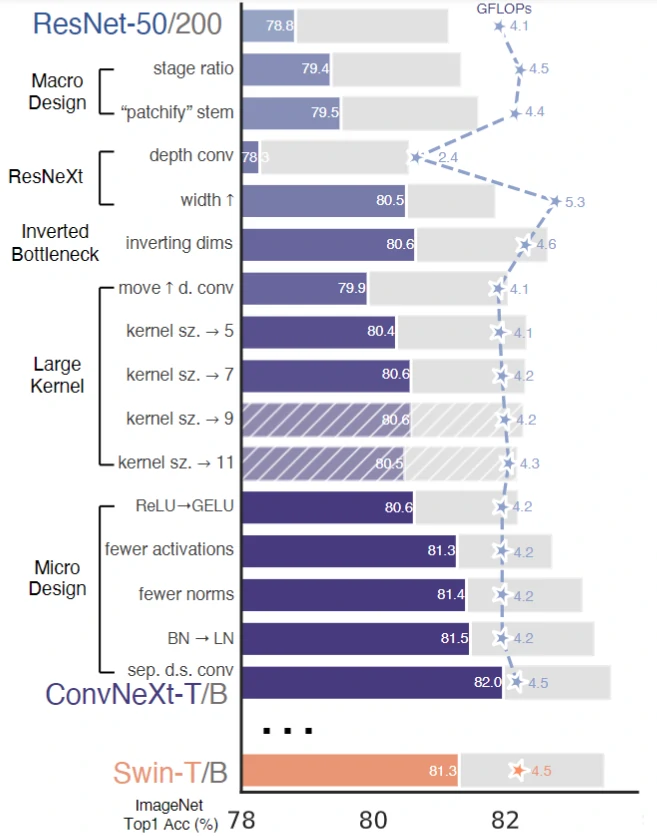
图2 基于ResNet的ConvNeXt优化流程
根据图2,我们展开描述优化方案。
训练方式优化
效仿Swin-Transformer,使用以下优化策略:
将训练Epoch数从90增加到300;
优化器从SGD改为AdamW;
更多的数据增强策略,包括Mixup,CutMix,RandAugment,Random Erasing等;
更多正则策略,包括随机深度,标签平滑,EMA等。
宏观设计优化
改变各个阶段的计算占比
我们知道传统ResNet的骨干网络分为4个Stage,每个Stage包含若干个Block,其中4个Stage的Block数量比例为3:4:6:3。而ConvNeXt则使用和Swin-Transfromer的相同Block数量比例,调整为3:3:9:3,结果ResNet-50的准确率从78.8%提升至79.4%。
Patch化的Stem
改变ResNet的Stem层卷积核参数,设计新的Stem层,思路是模仿Transfromer处理图像的方式,即先把图像以栅格的方式划分成一个个单独的patch再进行处理。在ConvNeXt中具体做法是使用stride=4, size=4的卷积核进行卷积,这样滑窗之间不再交集,效果就类似于Transfromer的patch划分,这一操作将准确率获得了0.1%的提升,准确率来到79.5%,更大的stride也降低了计算成本,GFLOPs从4.5降到4.4。
分组卷积(ResNeXt化)
使用与MobileNet的深度可分离卷积类似的卷积策略,不同的是MobileNet是每个通道单独进行卷积,再通过点卷积融合通道间的信息,ConvNeXt的分组卷积则是把所有通道分为若干组,以组为单位进行卷积,以上卷积思路来自于作者的另一个作品ResNeXt。得益于分离卷积卷积核通道数低的优势,分组卷积GFLOPs从4.4降到了2.4,但准确率降到了78.3%。为了使准确率回升,ConvNeXt把ResNet-50的基础通道数从64增加至96。理所当然的GFLOPs再次增加到了5.3,不过准确率提升到了80.5%。
使用逆瓶颈层
使用了类似于MobileNetv2中的逆瓶颈层,即按升维-深度卷积-降维的顺序进行卷积操作,值得一说的是ConvNeXt还额外提供了一种不同的逆瓶颈结构,它把深度卷积的顺序提到了首位,这样做是为了后面使用与Swin-Transfromer同样大小的卷积,方便对比的同时防止参数量上升。瓶颈/逆瓶颈的结构可参考下图3[1]。
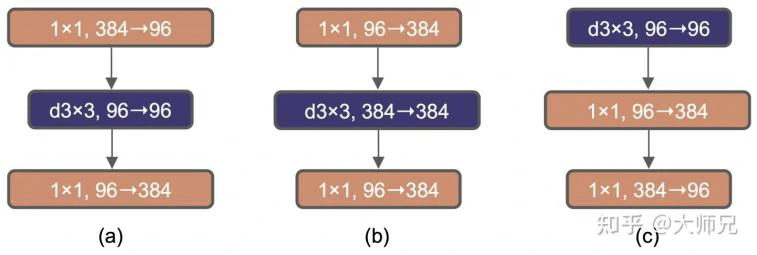
图3. (a) ResNeXt的瓶颈层架构,(b) ConvNeXt的逆瓶颈层架构,(c)ConvNeXt逆瓶颈结构2
使用逆瓶颈结构的Block后,准确率获得了0.1%的提升,达到80.6%。
更大卷积核
主要用于对齐Swin-Transfromer、方便比较,在深度卷积中使用同样是7x7的卷积核,无提升。
微观优化
ReLU替换为GELU
主要为了对齐Swin-Transfromer,方便对比,作者论文指出效果几乎一样(Swin-Transfromer使用GELU)。
更少的激活函数
Swin-Transfromer的MLP Block中只有一个激活函数,效仿这种设计ConvNeXt也只在逆瓶颈Block中的两个1x1卷积之间使用一层激活层,其他位置删除,有趣的是,这反而带来了0.7个点的提升,准确率来到了81.3%。作者认为可能是过多的非线性计算干扰了特征信息的传递
更少的归一化层以及BN替换为LN
前者原理同1.4.2。准确率提高了0.1%,达到81.4%。后者则是模仿Transfromer,不过通常来说CNN仅在BN由于样本少出现问题的时候会使用LN,因为LN可能带来性能的下降。出乎意料的是,在ConvNext中(即通过上面的优化后),LN直接替换BN反而带来了0.1%的提升,模型的准确率提升至81.5%。
分离降采样层
模仿Swin-Transfromer使用与其他运算分离的单独降采样层,具体做法是使用一个stride=2的 size=2的卷积插入到4个Stage之间。为保持模型稳定性,在采样前后街进行归一化操作,这项优化带来了0.5%的提升,模型的准确率提升至82.0% 。
最后整合以上的优化,ConvNeXt的Block的结构如下图4[1](b)。
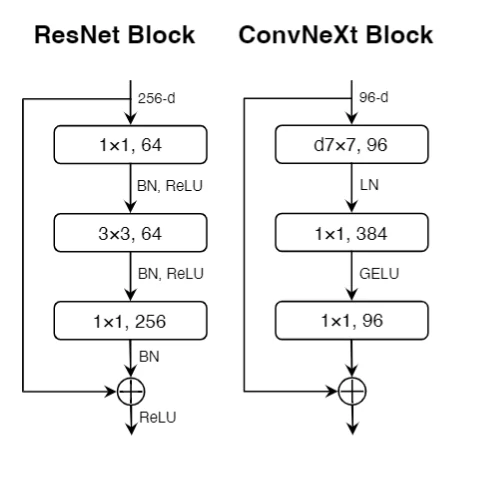
图4: (a)ResNet单个Block (b)ConvNeXt单个Block
总结
ViT(Vision Transfromer)是近来CV领域的研究热门方向之一,对传统的CNN研究产生了一定的冲击,ConvNeXt的提出可以说为CNN打了一次“漂亮的反击战”,然而ConvNext更值得一说的是论文中的模型调参思路,精妙的思路使得整篇论文更像是一个“手把手的模型调参教学”,令读者赏心悦目,深受启发。
ConvNeXt代码:GitHub - facebookresearch/ConvNeXt: Code release for ConvNeXt model
参考文章
[1] Liu, Zhuang, et al. “A ConvNet for the 2020s.” arXiv preprint arXiv:2201.03545 (2022).
原文链接
https://www.scholat.com/teamwork/showPostMessage.html?id=11174