
论文题目:
Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring
作者信息:
骆正权(中国科学技术大学,中科院自动化所),王云龙(中科院自动化所),王子磊(中国科学技术大学),孙哲南(中科院自动化所),谭铁牛(中科院自动化所)
收录会议:
39th International Conference on Machine Learning(ICML2022, to appear)
文章概要:
本文针对目前制约联邦学习发展的节点数据非独立同分布问题中较为复杂的属性倾斜因素,提出了共识表征提取和多样性传播的解构联邦学习框架(Disentangled Federated Learning,DFL)。
会议网址:
https://icml.cc/Conferences/2022
研究动机
研究背景
联邦学习作为目前最为火热的基于隐私安全保护的分布式架构收到了广泛关注,但是随着研究的深入,实际场景中节点数据分布之间往往存在巨大的非独立同分布性质(Non-iid),这一分布偏差给模型在联邦训练中带来了性能损失,收敛不稳定等一系列问题。
通过深入分析,我们对Non-iid因素做了细致的拆解,相比于较为明显的由类别不均衡造成的分布偏差而言,节点数据分布之间的属性偏差更加隐蔽同时也更难以克服。为了直观的体现出属性偏差所造成的性能损害,我们构建了一个属性倾斜的简单样例,首先对手写数字分类数据集MNIST按照节点进行均匀的划分,之后人工地针对不同节点的前景或背景进行染色,最后分别进行相同的联邦训练。实验结果可视化如图一所示,其表明即使是颜色属性这一原则上不应对数字分类造成影响的属性,当在节点数据分布中存在倾斜时实际上给模型分类准确性和收敛稳定性都带来了巨大的伤害。
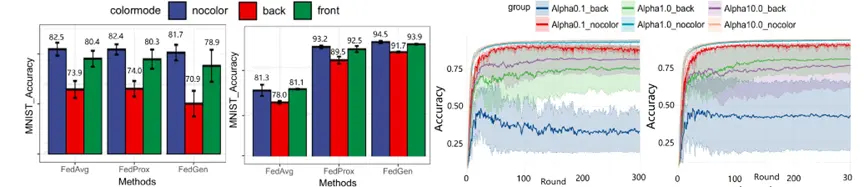
在实际场景中,由于数据采集场景、设备、对象的差异性,属性倾斜是普遍存在的且严重阻碍了联邦学习的进一步发展与实际应用,为了解决这些问题,我们必须深入理解分布差异性造成问题的本质,并相应提出克制之法。
联邦学习领域先前的研究将收敛不稳定和性能损失归因为节点间优化方向偏差,具体而言,由于不同节点数据分布差异造成节点模型在优化过程中梯度下降方向不一致,导致了聚合模型优化过程的不稳定,同时也无法最终收敛至全局最优点。根据这一直观理解提出的相应解决方法可粗略划分为以下三类:
第一类通过增加节点优化约束项强行矫正梯度下降方向朝向统一方向;第二类使用个性化节点模型自适应各自的数据分布;第三类全局加权聚合通过挑选合适的聚合节点或者根据相似性分配不同的权重进行模型聚合。
这些方法虽然在实验中取得了不错的结果,但是我们认为对于节点优化方向偏差这一问题的认知依旧不够深刻,核心问题依旧存在,本文对此进行了深入剖析。
方法动机
数据分布异质性会之所以会导致优化偏差的本质原因在于:特定节点数据的特有属性不可避免地被节点模型提取并混合到全局聚合中。这些属性能被成功学习说明其与决策相关,但可惜不是因果关系,也仅在局部有效。举个鸟类分类的例子,节点通过本地模型同时抽取到鸟本身和蓝天的属性,这两者都有助于飞鸟数据的分类决策。不幸的是,蓝天作为飞行鸟类图片所特有的属性会通过模型聚合注入到全局模型中。对于数据集中鸟都在树上的节点而言,对于蓝天属性的关注会导致分类性能下降,因为这个数据域没有蓝天这一概念。而实际中这种属性倾斜的现象非常普遍,进而引发了人们对联邦学习系统的鲁棒性和可信赖性的担忧。
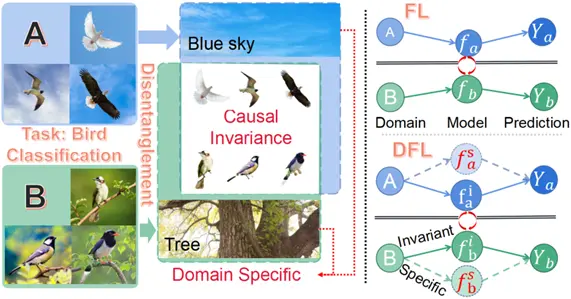
我们根据以上的观察提出了解构联邦学习(DFL)框架,其动机就是要从聚合模型中剥离节点特有的属性。但是,传统联邦学习框架通常基于单分支模型无法支撑DFL,其主要原因在于单分支模型会同时提取到高度纠缠的特有和共识表征属性。虽然这两个属性都有助于局部的任务决策,但其差异在于1)共识表征属性是内在的和因果的,是跨域通用的;2)特定属性仅在本地有效,可能会给其他域带来性能下降。因此,DFL 首度采用了两个互补分支的节点模型,引入互信息(MI)约束解开纠缠的属性,并分别汇聚到不同的分支上:1)特定领域的分支只在本地训练。2)域共识表征分支应用于全局聚合。除了重新设计局部节点模型外,为了有效实现DFL架构,我们提出了共识表征提取和多样性传播两种新技术,将在下文中进行详细叙述。
解构联邦学习框架
解构联邦学习框架理论
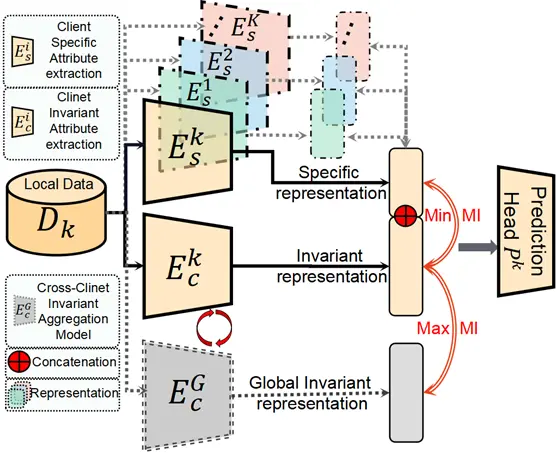

互信息最大化驱动局部共识表征提取分支专注于跨域不变属性,最后将最优的局部共识表征提取参数发送到服务器进行下一轮共识表征提取聚合。整体优化过程伪代码表示如下。交替优化的优点在于:1)更容易找到具有良好泛化性的最优全局共识表征提取模型。2)节点特有分支在节点本地进行优化,提供个性化适配。3)通过交替局部-全局优化有效的增强了收敛的稳定性。


表征解构、共识表征提取和多样性传播
为了支撑DFL架构,我们引入了表征解耦方法,并首次提出了共识表征提取和多样性传播技术,下面进行具体介绍。
表征解耦:为了有效地解耦属性,我们引入了基于互信息约束的表征解耦技术,如图三所示主要用于两个方面:1) 局部共识表征提取分支和全局共识表征提取分支之间的互信息最大化增强了跨域不变性。2) 局部共识表征提取分支和局部特有分支之间的互信息最小化解耦节点属性纠缠。
共识表征提取:服务器仅对各节点共识表征提取分支模型进行加权平均,并将聚合模型分发至各节点用于下一轮次共识表征提取分支更新,共识表征提取分支聚合公式为:

收敛性分析
我们在工作中对所提出的DFL进行了详细的收敛性分析,我们的理论证明了在基于局部特有分支模型梯度有界的前提下,可以保证共识表征提取分支的双阶段全局优化是收敛的。这一收敛性证明有力的支撑了DFL框架的可行性。具体的分析过程详见原文和附录。
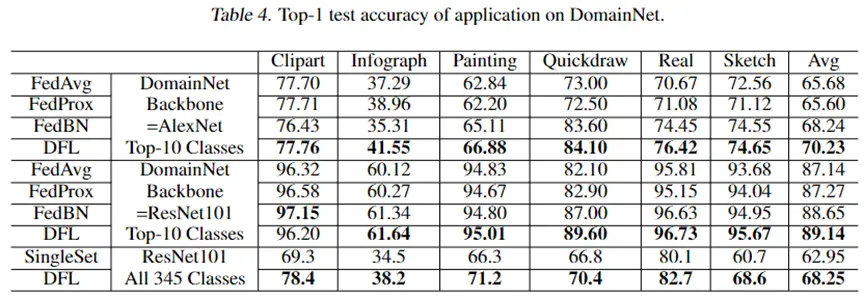
实验结果及可视化
我们从两个方面验证DFL有效性,验证实验侧重于人工合成的属性倾斜,旨在验证 DFL 与其他相关工作相比的有效性、损失收敛和性能改进。应用实验关注DFL在具有现实属性倾斜的数据集中的表现,试图证明 DFL 能够适应实际场景。
人工合成数据
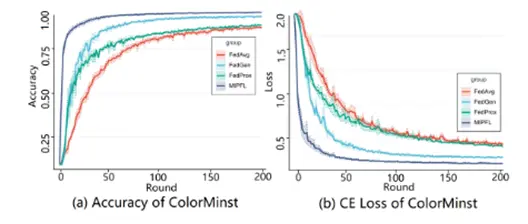
在人工合成属性倾斜的数据集上进行了实验,结果不仅表明了DFL对于分类准确性的提升,损失曲线更表明了DFL在收敛速率和稳定性上的优越性。
真实数据
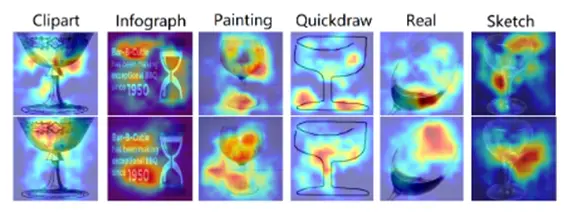
同时我们也在具备真实属性倾斜的数据集上进行了实验,除性能提升之外,可视化结果也表明了DFL确实有效的对节点特有和共识表征属性进行了有效的解构,如图五所示,第一行共识表征提取分支主要关注于对象的形状,也即杯子形状,这是分类的核心决策原因;而第二行特有分支则分别关注不同的属性,例如杯中液体、文字描述和颜色,这些属性有助于最终决策但特定于不同的数据节点,这一可视化结果说明了DFL确实提升了联邦学习的可解释性。
更多实验结果详见论文。
总结
为了抵抗属性倾斜这一非独立同分布性质的重要组成因素给联邦学习带来的困扰,我们深度挖掘了其问题背后的本质,通过表征解耦技术的引入和双阶段交替优化方案的突破,在基于可靠的收敛性分析的指导下,我们提出了解构联邦学习(DFL)框架,可解释地增强了联邦学习应对节点数据分布异质性的能力。
当然目前的研究依旧存在大量值得深入探讨的部分,基于可解释的联邦学习和联邦泛化学习将是我们未来研究的重点,同时欢迎感兴趣的研究者共同参与。
致谢
本研究成果得到了中国人工智能学会-华为MindSpore学术奖励基金的资助。
MindSpore官网:https://www.mindspore.cn/