Kullback-Leibler 散度是计算机科学领域内的一个重要概念。数据科学家 Will Kurt 通过一篇博客文章对这一概念进行了介绍,机器之心技术分析师在此基础上进行了解读和扩充。本文为该解读文章的译文。
原博文:https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
引言
这篇博文将介绍 KL 散度,即相对熵。这篇博文给出了一个理解相对熵的简单例子,因此这里不会试图重写原作者的内容。除了阅读原博客文章之外,这里还会根据我的知识给出一些基于原博文的额外信息。
定义:熵(Entropy)
这篇博文介绍了与“概率分布”有关的熵。我想说的是,理解熵的更好方式是将其看作是随机变量的“不确定度”的度量,而不是其概率分布。原博文本身也给出了原因:我们可以将熵看作是“编码我们的信息所需的最小比特数”。概率并不包含信息,原博文解释称被编码的概率的信息必须来自某个字母表(在这里即是一个随机变量),其概率分布根据 p(x_i) 确定。包含信息的是这个随机变量,而非概率分布。
此外,根据原博文,熵能为我们提供“编码我们的信息所需的最小比特数”。我认为有一点需要提及,即实际上这里说的是以无损的方式编码我们的信息所需的最小比特数。
定义:相对熵(Relative Entropy)
相对熵是两个分布之间的“距离”的度量。从统计学上看,即为似然比的期望对数。相对熵 D(p||q) 衡量了假设当前分布为 q,而真实分布是 p 时的非效率(inefficiency)。
这不是两个分布之间的真实“距离”度量,因为它不是对称的,即 D(p||q) ≠ D(q||p),而且它也不满足三角不等式。原博文没有提到三角不等式,尽管这可能与理解该博文没有直接关联。在这里,三角不等式即意味着 D(p||q) ≤ D(p||u) + D(u||q)。而实际上这并不总是成立。
相对熵的一个重要性质是非负性,即 D(p||q) ≥ 0。下面给出了证明:
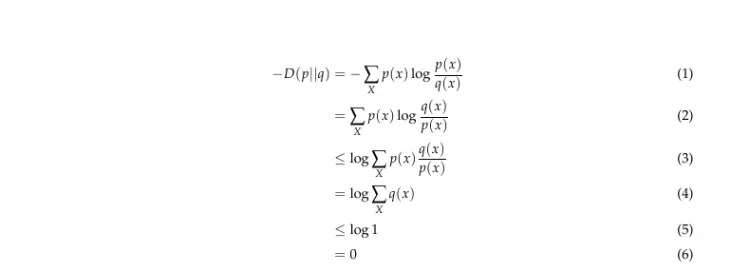
其中 (2) 到 (3) 遵循 Jensen 不等式。
为什么要优化 KL 散度?
除了原博文中给出的优化二项分布匹配的案例,我会给出另一个可能需要散度优化的案例。先简单介绍一下原博文的内容,其中本质上是想求解以下问题:
p_optimal = argmin_{p} D(q||p)
其中 q 是根据观察得到的分布,p 是二项分布。从下图可以看到,当 D(q||p) 取最小值时,你应该得到你应该近似求取的二项分布的 p。
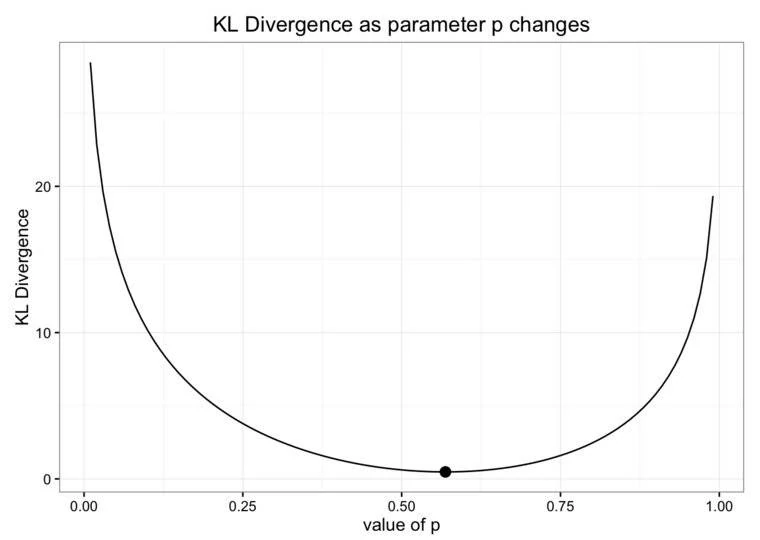
- 原博文是想用一个二项分布来近似观察数据,所以使用了 D(q||p)。
- 这不是使用散度的传统方式,因为原博文基本上是把观察数据看作是“真实”分布,这显然不对。作者在此的意图是使用一个更简单、更容易理解的分布来近似观察数据,因此按这种方式使用 KL 散度可能是合理的。
- 在这个 (q,p) 对中,散度是凸的,因此在执行优化时会有很好的图形。
从信息论的角度看,散度是无损地编码信息所需的额外比特。让我用以下例子说明一下:
假设问题定义如下:
- X 是采样自某个有限集 X = x1,x2,…,xn 的一个随机变量
- p 是 X 的真实分布,其中 p(x_i) 是 x_i ∈ X, i = 1,…,N 的概率,且 0 ≤ p(x_i) ≤ 1, ∀i
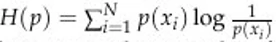 上式是随机变量 X 的熵,是无损编码信息所需的最小比特数
上式是随机变量 X 的熵,是无损编码信息所需的最小比特数- l_i 是用于编码 x_i 时使用的比特数或比特长度,而 x_i 则是随机变量 X 的一个实例
- 所有对数的基数都假定为 2
为了得到编码给定概率分布 p 的最优 H(p) 比特数,我们必须将每个码字的长度 l_i 设计成与 log 1/p(x) 成正比。因此,我们按以下方式计算编码 X 的期望长度:
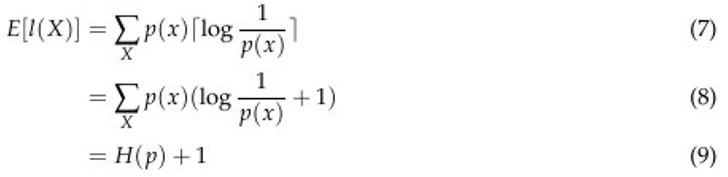
这里的 ceiling 函数负责处理不是 2 的幂的码字长度。这是因为我们只能为任意码字的比特数分配一个整数值。
现在,让我们假设我们之前不正确地假设了分布 p 为 q,然后看看会怎样。类似地,我们按以下方式计算期望:
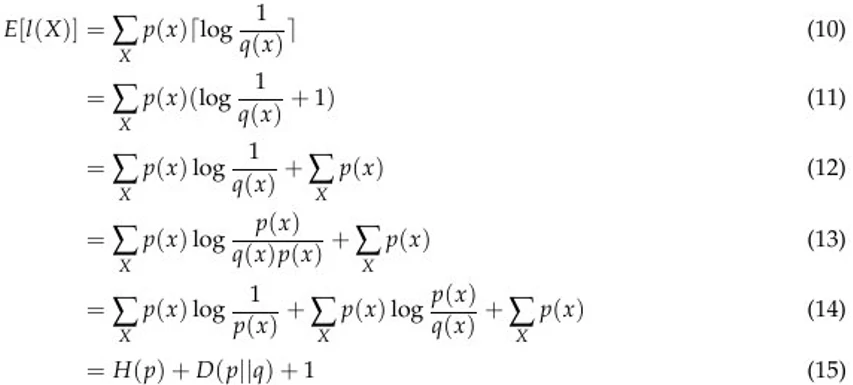
可以看到,只要执行减法操作 (15)-(9),就能得到两个期望长度之间的差为 D(p||q)。因为散度是非负的,所以这就是编码该信息平均所需的额外比特。
在机器学习相关应用上的应用
原博文提到两个优化散度的应用:变分自动编码器(VAE)和变分贝叶斯方法。原博文没有解释这些应用,但提供了扩展阅读链接:
- 变分自动编码器:https://arxiv.org/pdf/1606.05908.pdf
- 变分贝叶斯方法:https://www.countbayesie.com/blog/2015/3/3/6-amazing-trick-with-monte-carlo-simulations
我将简要描述最小化机器学习应用中散度的直观理解。机器学习领域中的生成模型往往涉及到生成尽可能反映真实情况的分布模型。比如,生成对抗网络(GAN)在图片上的应用往往执行的是类似基于黑白图片生成看起来尽量真实的彩色图片这样的任务。在这类似的应用中,输入往往是图像或像素。网络会学习这些像素之间的依赖关系(比如临近像素通常有相似的颜色),然后使用它来创建看起来尽量真实的图像。因此,生成器的目标就是最小化所学到的像素分布于真实图像像素分布之间的散度。
最后,我想说的是,KL 散度最小化可被看作是似然比最大化,这出现在了很多应用中。下面给出了一个看待这一问题的简单方法:
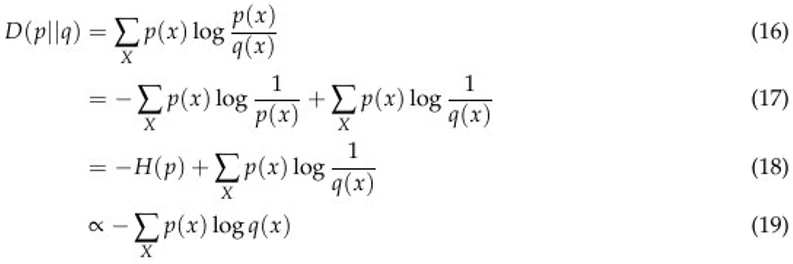
从 (18) 到 (19),我们丢弃了 -H(p),因为这是一个常数。可以看到,如果我们最小化等式左侧,我们就是在分布 p 上最大化 log q(x) 的期望。因此,最小化 LHS 即是最大化 RHS,即最大化数据的对数似然。
总结和扩展阅读
在本文中,在原博文的基础上,我提供了一些有关 KL 散度(相对熵)的补充材料。我认为 KL 散度的重要性在于其量化你的分布估计与真实分布的可能距离的能力。在这篇博文的案例中,如果我们假设观察数据取自根据某个参数集参数化的分布,那么这些参数应该怎样取值才最能代表观察数据。
最后,如果你还有兴趣了解 KL 散度的变体,我推荐你了解 Jesen-Shannon 散度,这是一种对称的散度,衡量的是两个分布的相似性。另外还有 Renyi 散度,这是 KL 散度的推广,主要用在量子物理学应用中。