本篇学习报告基于2021 CVPR的人体自由视角合成的论文:《Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans》,该论文由浙江大学CAD&CG国家重点实验室/浙大三维视觉实验室提出。
研究背景
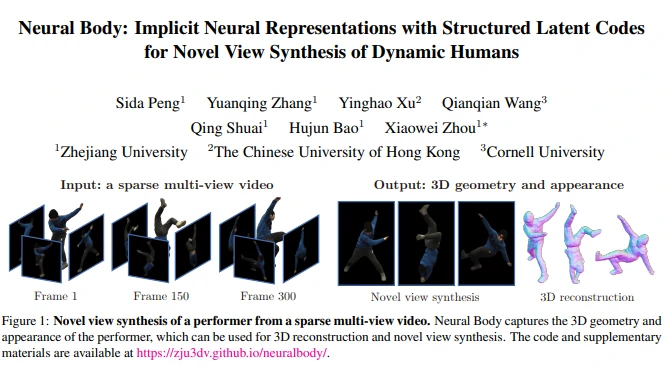
人类表演者的自由视点视频有各种各样的应用,如电影制作、体育广播。传统的自由视点视频系统大多依赖密集的摄像机阵列进行基于图像的新型视图合成,或者深度传感器进行高质量的3D重建以产生逼真的渲染,复杂硬件成本和有限的工作环境让自由视点技术难以普及。论文的工作重点是从有限数量的摄像机捕获的稀疏多视角视频中针对人类表演者的新视角合成问题,大大降低了自由视点系统的成本,并使系统更广泛地适用。
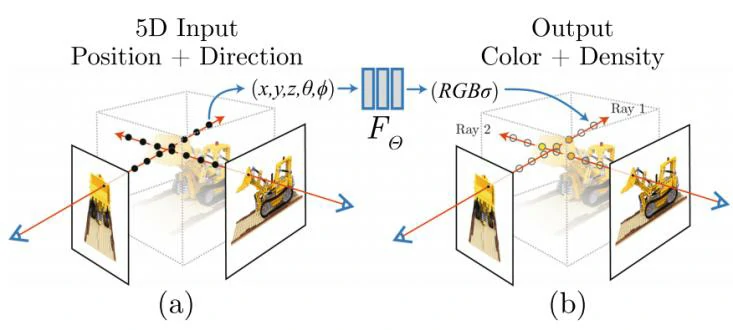
在稀疏视图中,由于自遮挡,部分人体可能不可见,传统技术往往会给出噪声和不完整的重建,导致大量的空洞伪影。最新研究NeRF[1]显示了逼真的视图合成,它通过将3D场景表示为密度和颜色的隐式场来实现,然而面临两个问题,一是需要非常稠密视角来训练视角合成网络,二则只能处理静态场景,每个静态场景训练一个网络,对于动态场景,上百帧需要训练上百个网络,成本很高。
在稀疏视角下,单帧的信息不足以恢复正确的3D 场景表示。论文的关键思想是在不同的视频帧上整合时序信息,来聚合足够多的观察结果。本文介绍了一种用于动态人的隐式神经表示方法——神经体(Neural Body),以解决稀疏视图合成新视图的难题,方法在新视图合成上展示了最先进的性能。
总的来说,这项工作有以下贡献:
- 能从稀疏的多视图视频合成动态人体的新视图,无需预先扫描人体模板;
- 提出了一种新的动态人体隐式表示,使研究人员能更有效地利用视频中所有帧的信息来学习人体的 3D 表示;
- 极大地提升了动态人体 3D 视图合成的效果。

实验内容
Neural Body的形成大致分为五步:
结构化的潜码
为了控制潜码的空间位置与人体姿态,团队将这些潜码锚定到一个可变形人体模型(SMPL)[2]。SMPL 是一个基于皮肤顶点的模型,它被定义为形状参数、姿势参数和相对于 SMPL 坐标系的刚体变换函数。
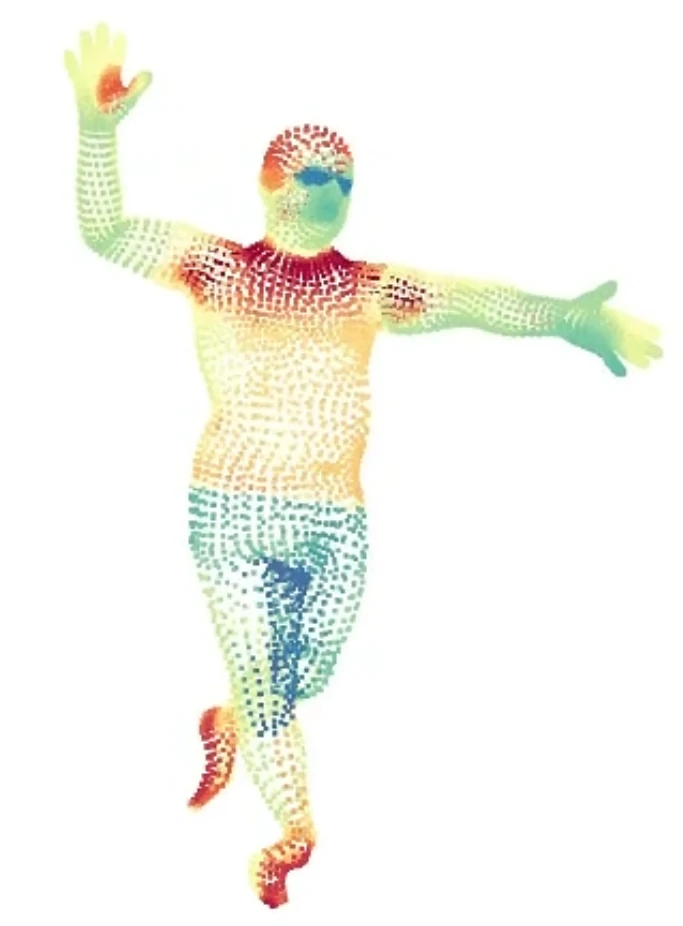
潜码与神经网络,一起用于表示人的局部几何和外观。将这些代码锚定在一个可变形的模型上,能够表示一个动态的人。通过动态人的表示,论文作者建立了一个潜在变量模型,将同一组潜码映射到不同帧的密度和颜色的隐式域中,自然地整合了观察结果。
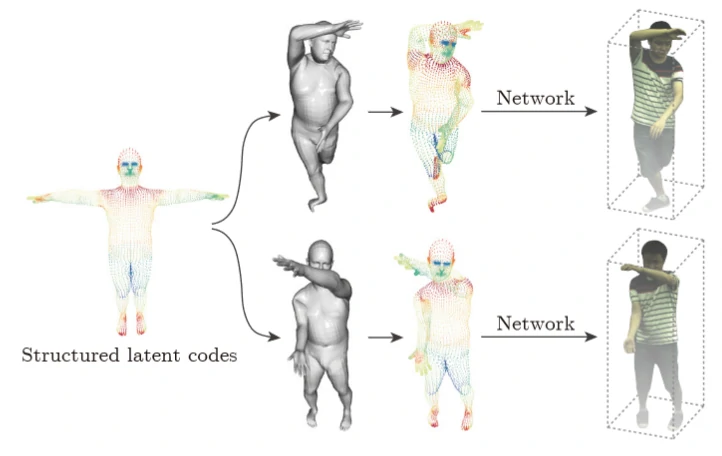
代码扩散
由于结构化的潜码在三维空间中比较稀疏,直接对潜码进行插值会导致大多数三维点的向量为零。为了解决这个问题,将表面上定义的潜码扩散到附近的三维空间。
由于代码的扩散不应该受到人在世界坐标系中的位置和方向的影响,他们将代码的位置转换为 SMPL 坐标系。
代码扩散还将结构化潜码的全局和局部信息集合起来[3],有助于学习隐式域。
密度和颜色回归
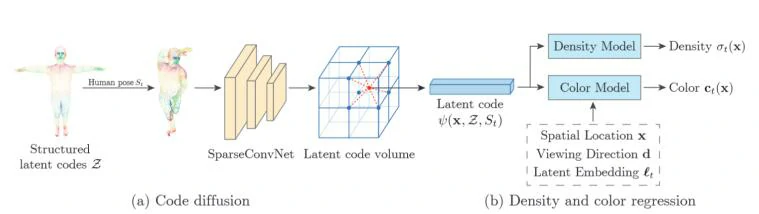
研究团队发现,时间变化因素会影响人体的外观,如二次照明和自阴影。受自动解码器的启发,他们为每个视频帧分配了一个潜在的嵌入框架 t,以编码时间变化的因素。
体绘制
在给定的视点下,团队利用经典的体绘制(volume rendering)技术,将 Neural Body 渲染成二维图像。
然后,基于 SMPL 模型估计场景边界,接着,Neural Body 会预测这些点的体积密度和颜色。
在体绘制的基础上,通过对渲染图像和观测图像的比较,对模型进行了优化。
训练
与基于帧的重建方法相比,该方法利用视频中的所有图像来优化模型,并拥有更多的信息来恢复 3D 结构。
此外,团队采用 Adam 优化器来训练 Neural Body,训练在四个 2080 Ti GPU 上进行,对于一个共 300 帧的四视图视频,训练通常需要大约 14 小时。
经过以上五个步骤,Neural Body 实现基于少量视图的自由视角视频合成,且与其他方法对比,效果明显优于前者。
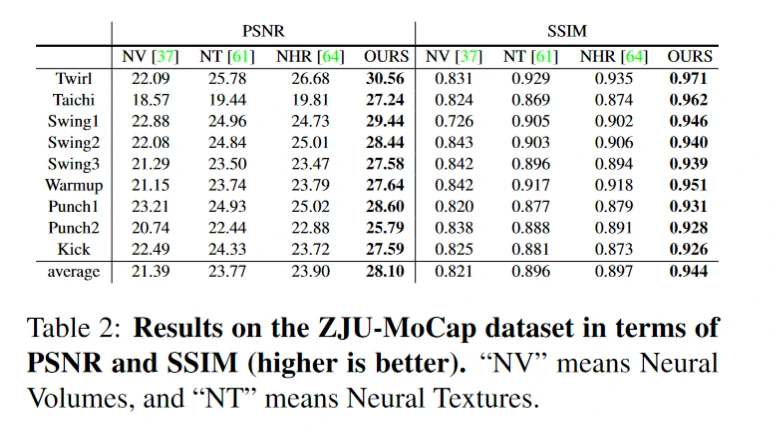
三种方法输出结果的 PSNR(峰值信噪比)对比数值越大,表明输出图像质量越好。
结果表明,当人物进行复杂的运动,包括旋转、太极、手臂摆动、跳舞、拳击和踢腿等动作时,都能实现较好的重建与视图合成。
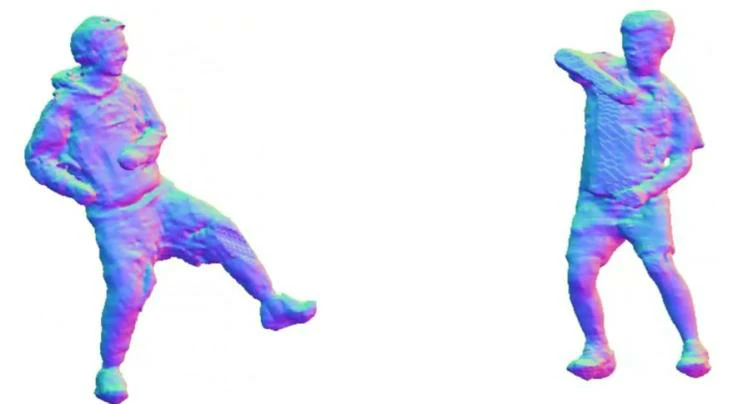
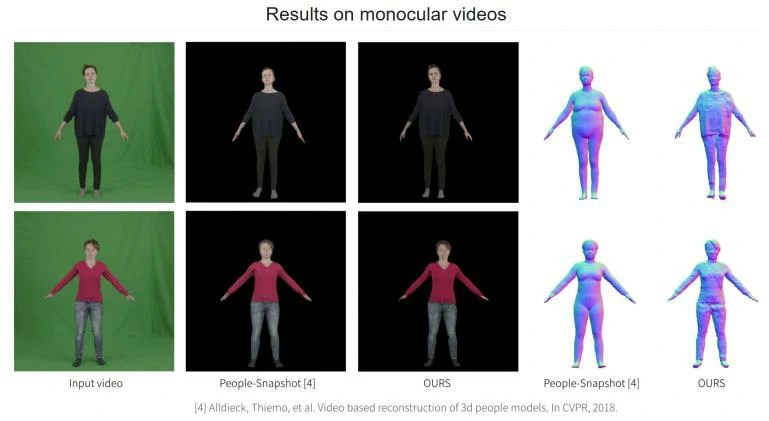
通过对比可以发现,本次方法相比其他方法,能呈现出更多人物外观细节,特别是对于穿着宽松服装的实验者来说,Neural Body 可以精确地进行渲染,以下图女士为例,使用其他方法出来的效果图,其衣服和身体紧贴,而 Neural Body 出来的效果中,可明显看出衣服的轮廓。
总结思考
Neural Body的提出完成了从一个非常稀疏的相机视图集中合成一个表演者的新视图的挑战。针对动态场景,在已有NeRF 基础上,利用统计人体模型整合时序信息,实现对动态场景多角度的渲染。
进一步可优化的地方:
- 改进计算效率;
- 生成可驱动的人体模型;
- 实现重光照。
对于未来的应用场景,论文作者周晓巍表示:“随着 3D 技术的发展,VR 产业正在迅速崛起。无论是对物品进行 360° 展示,还是体育比赛的自由视点观赛,或者说全息的沉浸式远程会议,都是 VR 将来的重要应用领域。而这些应用背后的关键技术正是视图合成。” 周晓巍认为,视图合成技术在短期内可能很快实现大规模应用领域为:电商领域、场景浏览如 VR 看房等。
从长远看,该技术的最大刚需是在“人人交互”上,如今天我们已经习以为常的语音连线和视频连线。可以想象,当 Neural Body 的技术更成熟后,开会就能以 3D 形式呈现,从而实现真正的远程零距离交流,就像坐在一起一样自然真实。
参考链接
https://www.scholat.com/teamwork/showPostMessage.html?id=10018
https://zhuanlan.zhihu.com/p/361151134
[1] Mildenhall B, Srinivasan P P, Tancik M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[C]//European Conference on Computer Vision. Springer, Cham, 2020: 405-421.
[2] Loper M, Mahmood N, Romero J, et al. SMPL: A skinned multi-person linear model[J]. ACM transactions on graphics (TOG), 2015, 34(6): 1-16.
[3] Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10529-10538.
论文链接:https://zju3dv.github.io/neuralbody/
论文代码:https://github.com/zju3dv/neuralbody